多模态大模型轻量化
MQuant: Unleashing the Inference Potential of Multimodal Large Language Models via Static Quantization
introduction
1. 研究背景:MLLM 很强,但很难落地
- 多模态大语言模型(MLLMs)能理解图文,能力很强。
- 但参数巨大、计算量极高,在手机/边缘设备等资源受限场景很难部署。
2. 现有方案:量化有用,但不适合 MLLM
- 模型量化(把 FP32 压成 INT4/INT8)是减小体积、加速推理的有效手段。
- 但现有量化方法都是给纯文本 LLM 设计的,直接用在 MLLM 上效果极差。
3. 本文发现:MLLM 量化有 3 个独特痛点(最关键)
作者明确指出 MLLM 量化的三大核心困难:
- 首token延迟(TTFT
time to first token)爆炸
图像分辨率越高,视觉 token 越多,推理延迟急剧上升;逐token动态量化计算开销巨大。 - 图文模态分布差异极大
视觉 token 激活值范围宽,文本 token 集中在 0 附近;用同一个量化 scale 会严重丢精度。 - 视觉 token 存在极端异常值
哈达玛变换(Hadamard)会引入巨大权重异常值,传统裁剪方法直接崩精度。
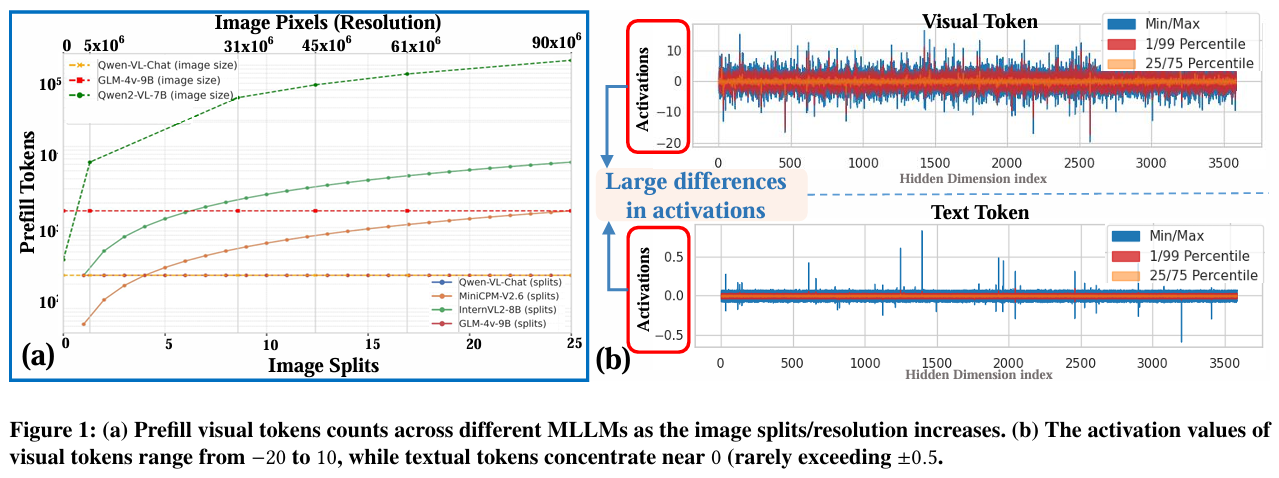
- 视觉 token 数量随分辨率剧烈增长
多模态大模型(MLLMs)通常会将输入图像切分成若干个小块(patch)或采用动态分辨率策略。以 Qwen2-VL 为例,图像分辨率越高,产生的视觉 token 数量呈超线性增长(见图 1(a) 和附录 A.6 的图 9):
- 低分辨率(如 448×448):约 256 个视觉 token
- 高分辨率(如 2240×2240):可达 数千甚至上万个 视觉 token
这些视觉 token 与文本 token 一起组成输入序列,在 prefill 阶段(首轮计算 KVCache)需要一次性完成整个序列的自注意力计算。因此:
TTFT ≈ 处理所有视觉 token 的时间 + 处理文本 token 的时间
当视觉 token 数量激增,prefill 的计算量和内存访问压力急剧上升,TTFT 也随之爆炸。
- 视觉 token 的激活分布差异加剧量化开销
论文图 1(b) 显示:
- 视觉 token 的激活值范围宽(-20 到 10)
- 文本 token 的激活值集中在 0 附近(±0.5)
如果采用常规的 逐 token 动态量化(per‑token dynamic quantization)—— 即对每个 token 独立计算量化尺度(scale),虽然能适应不同 token 的数值范围,但会带来巨大的在线计算开销:- 每 token 都需要计算 scale:需要扫描该 token 的激活值(例如 >dmodeld_{\text{model}}dmodel 维向量),求绝对最大值,再除法得到 scale
- 额外的内存访问:scale 本身也要写入和读取
- 硬件不友好:特别是对边缘设备,动态分支和细粒度操作会破坏流水线效率
在视觉 token 数量达到数千的情况下,逐 token 动态量化的额外开销与视觉 token 数成线性比例,使 TTFT 雪上加霜。
- 高动态场景进一步放大问题
- 视频任务:每帧都会产生大量视觉 token,累计数量可能达到 数万
- 多图对话:多个图像分别产生各自的视觉 token 集合,序列长度成倍增加
2. Preliminaries and Related Work
这一节分两大部分:
- MLLM 基本结构(预备知识)
- LLM/MLLM 的训练后量化 PTQ(相关工作)
一、Preliminaries:MLLM 基础架构
作者先讲多模态大模型的标准组成,让读者看懂后面的方法:
- Visual Encoder 视觉编码器
- 把图片变成紧凑的视觉特征(常用 ViT、CLIP)。
- Vision-Language Projector 视觉-语言适配器
- 把视觉特征映射到文本特征空间,让 LLM 能看懂。
- Large Language Model 大语言模型
- 接收文本 token + 视觉 token,自回归生成回答。
二、Related Work:PTQ for LLMs / MLLMs
讲量化是什么 + 纯文本LLM量化 + MLLM量化现状。
1. 量化(PTQ)基础
- PTQ:训练后量化,不用重训练,直接把高精度转低比特(如 W4A8)。
- 分两种:
- 权重量化:只量化权重,压缩好但加速有限。
- 权值+激活量化:同时量化权重与激活,速度提升大,但难点是激活异常值。
2. 纯 LLM 量化方法
- 经典方法:GPTQ、AWQ、SmoothQuant、OmniQuant、Quarot 等。
- 重点:Quarot 用哈达玛变换消除异常值,效果很强,但不能直接用在 MLLM。
3. MLLM 量化现状
- MLLM 量化研究很少。
- 现有方法(Q‑VLM、MBQ)都用 逐token动态量化,速度慢、硬件不友好。
- 它们没有专门解决图文模态差异,所以精度/速度都不行。
3 Method
3.1 Modality-Specific Static Quantization + Attention-Invariant Flexible Switching
① MSQ:模态专属静态量化
- 问题:视觉token和文本token激活分布差太大,用同一个scale量化必崩。
- 做法:
- 给视觉token一套静态scale s_v
- 给文本token一套静态scale s_t
- 离线一次性算好,推理不做任何在线计算
- 好处:
- 去掉动态量化的巨大开销
- 不压缩文本、不截断视觉,精度保住
② AIFS:注意力不变灵活切换
- 问题:MSQ虽好,但图文token混在一起,推理时要反复切片、拼接,很慢。
- 做法:
- 把所有视觉token放前面,文本token放后面
- 改因果掩码(causal mask),保证注意力计算和原来完全等价
- 位置编码也跟着重排
- 好处:
- 内存访问连续、GEMM更快
- 可直接对接 FlashAttention,几乎无开销
- 高分辨率下加速极明显
③ MSQ+AIFS一起的效果
- 静态量化 + 连续token排布
- 速度快、精度高、硬件友好
3.2 Rotation Magnitude Suppression (RMS):旋转幅值抑制
① 发现新问题:FHT会产生权重异常值
- Quarot 用在线哈达玛变换(FHT)去异常值,但在MLLM的视觉编码器里:
- FHT会让第一个通道变成通道均值的√n倍
- 只要均值大,就会出现超大异常值
- 论文验证:视觉模块100%出现,LLM部分少量出现
② RMS怎么做(极简版)
- 检测满足条件的异常通道
- 把异常通道从主GEMM里拆出来,单独用GEMV算
- 主GEMM里把这行置0,避免重复计算
- 最后把结果加回去
③ RMS优势
- 只改出问题的那一行,开销几乎为0
- 完美压制FHT带来的新异常值
- 让W4A8低比特量化稳定不崩
3.3 完整MQuant流程
- 把视觉编码器的 LayerNorm 转成 RMSNorm(让旋转能生效)
- 对LLM、视觉模块做离线+在线哈达玛旋转
- 用 GPTQ 量化权重
- 用 MSQ 给图文分别做静态激活量化
- 用 AIFS 重排token
- 用 RMS 修复FHT异常通道
- 得到最终W4A8量化MLLM
4 Experiments
4.1 总体结果 (Overall Results)
- 测试模型:5个主流 MLLMs(InternVL2-8B、Qwen-VL-9.6B、MiniCPM-V-2.6-8B、GLM-4V-9B、Qwen2-VL-7B/72B)
- 量化设置:W8A8 和 W4A8(权重4位、激活8位)
- 结论:
- W8A8 下达到近无损(与 FP 相比)
- W4A8 下依然保持与 FP 相近的精度,而其他先进量化方法(如 MBQ、Q-VLM)出现明显精度下降
- MQuant 具备良好的通用性和鲁棒性
4.2 与其他 MLLMs 量化方法的对比
对比的方法:Q-VLM、QSLAM、MBQ
- 对比维度:量化方案(weight-only / weight-activation)、GEMM 类型、额外计算开销
- MQuant 优势:唯一实现 per-modality 静态量化、直接使用 INT4 GEMM、无额外反量化或 scale 计算
- 精度对比:
- 在 LLaVA1.5-13B 的 ScienceQA 上,W4A4 的 MQuant 比 Q-VLM 高 6.4%
- 在 Qwen2VL-72B 的 T.VQA / D.VQA / OCRB / MME 上,MQuant 接近 FP,优于 MBQ
4.3 消融实验 (Ablation Study)
在 Qwen2-VL-7B 上逐步添加组件:
- Baseline(GPTQ + Hadamard + per-tensor静态量化)→ 精度较低
- + MSQ + AIFS → 精度大幅提升,延迟降低
- + RMS → 达到接近 FP 的性能(T.VQA 84.32、MME 2255)
还验证了:
- 校准集大小(128/256/512 样本)对结果影响很小
- AIFS + FlashAttention 的延迟开销 < 0.3%
- RMS 对权重分布的影响:将 FHT 放大的异常值幅度从 1.0 降低到 0.1 左右
4.4 延迟与内存分析 (Latency and Memory Analysis)
推理加速与内存节省(表11)
- 在 840×840 分辨率下,MQuant 比 PyTorch BF16 快 24.76%,内存节省 152.92%
- 即使在 5600² 高分辨率下,依然有 12.19% 的延迟提升
解码加速(表12)
- Prefill 阶段比逐token动态量化快 23%
- Decode 阶段(生成 2000 token)快 100%
多 batch 与多轮对话加速(表13、14)
- 多 batch(1-4)下,MQuant 比 BF16 快约 20%
- 多轮对话(1-3 轮)下,端到端推理加速 28.9%–38.7%
Weight-Only 量化对比(表15)
- 在 Qwen2-VL-7B 上,MQuant 的 W4-only(LLM 量化)与 GPTQ/AWQ 精度相当
- W4A8 也能保持与 weight-only 相当或更优的性能
Fine-Grained Post-Training Quantization for Large Vision Language Models with Quantization-Aware Integrated Gradients
Introduction
-
研究背景:大型视觉语言模型(LVLMs)在多种多模态任务中取得了显著成功,但其计算和内存开销巨大,限制了实际部署。后训练量化(PTQ)是一种有效的加速技术,可以降低内存占用并加速推理。
-
现有方法的不足:现有的LVLM量化方法通常从模态层面衡量token的敏感性(例如区分视觉token和文本token),但无法捕捉跨token之间的复杂交互,也缺乏对token级量化误差的定量测量。随着token在模型中的交互,不同模态之间的差异逐渐减弱,因此需要更细粒度的校准。
-
提出的方法:受机械可解释性中的公理归因启发,作者提出了一种基于量化感知积分梯度(QIG) 的细粒度量化策略。QIG能够定量评估每个token对量化误差的敏感性,将量化粒度从模态级推进到token级,同时反映模态间和模态内的动态变化。
-
主要贡献:通过大量实验,在多种LVLM和量化设置(W4A8、W3A16)下,该方法在多个基准测试上提升了精度,且延迟开销可忽略。例如,在3位仅权重量化下,LLaVA-onevision-7B的平均准确率提高了1.60%,与全精度模型的差距缩小到仅1.33%,代码已开源。
2. Related Work
2.1 Large Vision Language Models (大型视觉语言模型)
简要介绍了LVLMs(如LLaVA、InternVL、Qwen-VL)的基本架构:通常用Vision Transformer或CLIP编码图像为视觉patch token,再与文本token及特殊token(如<bos>、<eos>等)拼接成统一序列,供大语言模型进行多模态推理。作者指出,本文关注的不是设计新架构来改进模态对齐,而是对LVLMs进行高效加速。
2.2 Post-Training Quantization (后训练量化)
回顾了PTQ在LLMs中的常用方法:RTN(四舍五入)、AWQ(激活感知权重量化)、GPTQ(基于二阶近似的层重建)、SmoothQuant(平衡激活与权重的范围)。这些方法主要针对纯文本LLM。最近PTQ被扩展到LVLMs以降低多模态推理成本,但现有工作主要关注跨模态或跨层的平衡量化,而层内token级的非均匀敏感性仍鲜有探索。
2.3 Interpretability and Token Sensitivity (可解释性与Token敏感性)
介绍了可解释性研究中分析token敏感度的两类方法:
- 干预法:如遮挡敏感度(Occlusion Sensitivity)、激活修补(Activation Patching),通过修改输入或中间激活来测量token影响。
- 梯度法:如积分梯度(Integrated Gradients)、SmoothGrad,利用梯度估计特征重要性。
作者指出,这些方法大多停留在模型分析和可视化层面,很少直接利用可解释性信号来指导模型优化(如量化)。这为本文利用积分梯度进行token级量化敏感性估计提供了动机。
3. Method
3.1 Preliminaries
- 量化目标: 现有PTQ方法通常在校准过程中,通过最小化每个Transformer块的重建误差来搜索最优的量化超参数。
- 通道均衡(CWE): 为了缓解激活异常值带来的巨大量化误差,权重-激活(WA)量化方法会对权重和激活矩阵进行通道均衡。
- 数学公式:
- 设 X∈Rd×TX \in \mathbb{R}^{d \times T}X∈Rd×T 为激活矩阵,W∈Rm×dW \in \mathbb{R}^{m \times d}W∈Rm×d 为权重矩阵,EEE 为通道缩放因子。
- 优化的目标是寻找最优的 EEE,使得全精度输出与量化输出之间的均方误差(MSE)最小,公式如下:
E∗=argminE∥QW(W∗E)QX(E−1∗X)−WX∥22E^* = \arg\min_E \| Q_W(W * E) Q_X(E^{-1} * X) - WX \|_2^2E∗=argEmin∥QW(W∗E)QX(E−1∗X)−WX∥22
- 符号说明: 论文使用 WxAyWxAyWxAy 表示量化格式,例如 W4A8W4A8W4A8 表示权重量化为4比特,激活量化为8比特。
通道均衡(Channel-wise Equalization, CWE) 是一种用于减少量化误差的预处理技术,主要解决权重和激活中异常值(outliers) 导致量化范围过大、精度下降的问题。其核心思想是:通过逐通道(per-channel)的缩放变换,将难以量化的分布转移到更均衡的范围,同时保持原始输出的数学等价性。
在 Transformer 的线性层中,计算为 Y = W · X。CWE 引入一个可学习的对角缩放矩阵 E(沿隐藏维度 (d)),并执行:
W′=W∗E,X′=E−1∗X\mathbf{W}' = \mathbf{W} * \mathbf{E}, \quad \mathbf{X}' = \mathbf{E}^{-1} * \mathbf{X}W′=W∗E,X′=E−1∗X
从而保证:
W′⋅X′=(WE)⋅(E−1X)=W⋅X \mathbf{W}' \cdot \mathbf{X}' = (\mathbf{W} \mathbf{E}) \cdot (\mathbf{E}^{-1} \mathbf{X}) = \mathbf{W} \cdot \mathbf{X} W′⋅X′=(WE)⋅(E−1X)=W⋅X
即数学上完全等价,但分布被重新调节。优化目标是最小化量化后输出的均方误差(MSE):
minE∥QW(W∗E)⋅QX(E−1∗X)−WX∥22 \min_{\mathbf{E}} \| Q_W(\mathbf{W} * \mathbf{E}) \cdot Q_X(\mathbf{E}^{-1} * \mathbf{X}) - \mathbf{W} \mathbf{X} \|_2^2 Emin∥QW(W∗E)⋅QX(E−1∗X)−WX∥22
- 将激活中的大值“转移”一部分到权重中,使两者都更容易量化。
- 论文中 Figure 2 显示:不同层、子层、token 的激活分布差异极大,CWE 可作为前置步骤,为后续 token 级精细化量化提供更稳定的初始分布。
3.2 模态与Token之间的敏感性差异
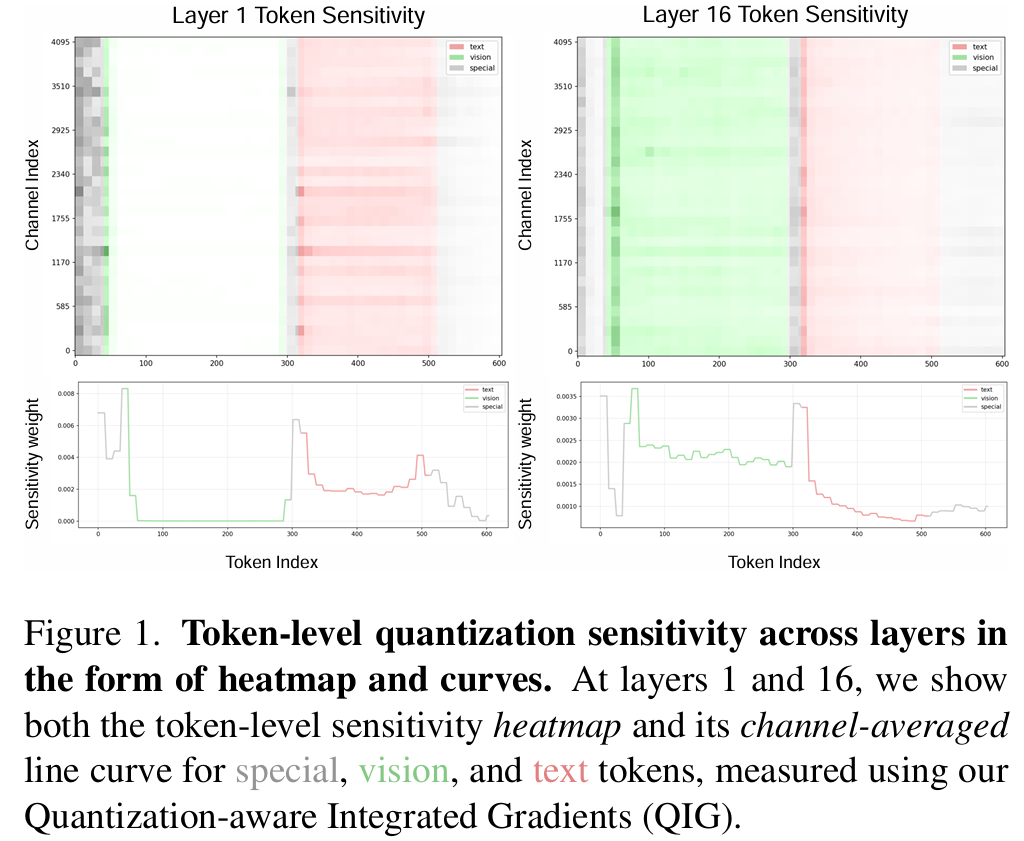
这一节通过可视化和对照实验,论证了现有基于“模态”级别的粗粒度量化是不够的,必须深入到“Token”级别的细粒度。
- 激活分布分析(Figure 2):
作者观察了InternVL2-8B在量化过程中的激活分布,发现了四个现象:- 大量异常值: 大的激活异常值在各层持续存在。
- 层异质性: 不同的Transformer层表现出不同的激活行为。
- 子层分歧: 同一个Transformer块内(如Attention Out与MLP Up),激活特征也不同。
- Token多变性: 在同一个子层内,不同Token的激活差异巨大。
这表明量化敏感性不仅依赖于模态(视觉vs语言),更高度依赖于具体的Token。然而现有方法(如MBQ)仅在模态级别赋权,忽略了Token间的差异。
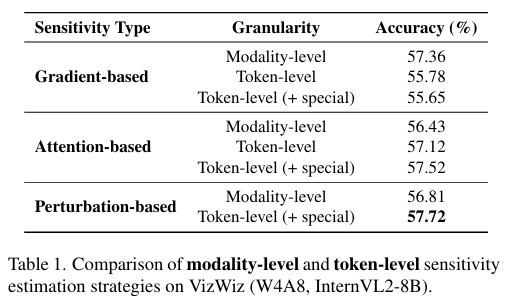
- 敏感性估计策略对比(Table 1):
作者在InternVL2-8B上进行了对照实验,固定其他条件,仅改变敏感性的计算策略(包括基于梯度、基于注意力、基于扰动),分别测试模态级别和Token级别的效果:- 基于梯度(Gradient-based): 直接用SFT损失梯度的Token级别表现反而比模态级别差。原因是一旦引入量化噪声,梯度分布会改变,导致误差累积。
在训练(或微调)一个模型时,我们可以计算 损失函数对输入的梯度 —— 梯度越大,说明改变这个 token 对模型输出的影响越大,也就是越“敏感” - 基于注意力: 仅带来微弱且不稳定的提升。这是因为存在“注意力下沉”现象,部分Token获得了虚假的高注意力分数。
- 基于扰动: Token级别表现最好,因为它直接测量模型对量化噪声的响应。但其计算成本极高(需要重复前向传播)。
采用 留一法(leave‑one‑out) —— 每次只扰动 一个 token(例如:把它替换成量化后的版本或直接置零),保持其他 token 不变,测量输出变化。然后逐个 token 重复这个过程
结论: Token级别的敏感性确实能提升量化效果,但现有的代理指标(梯度、注意力)与量化误差不对齐,而直接测量(扰动)又太昂贵。这促使作者提出一种新的Token级敏感性评估方法。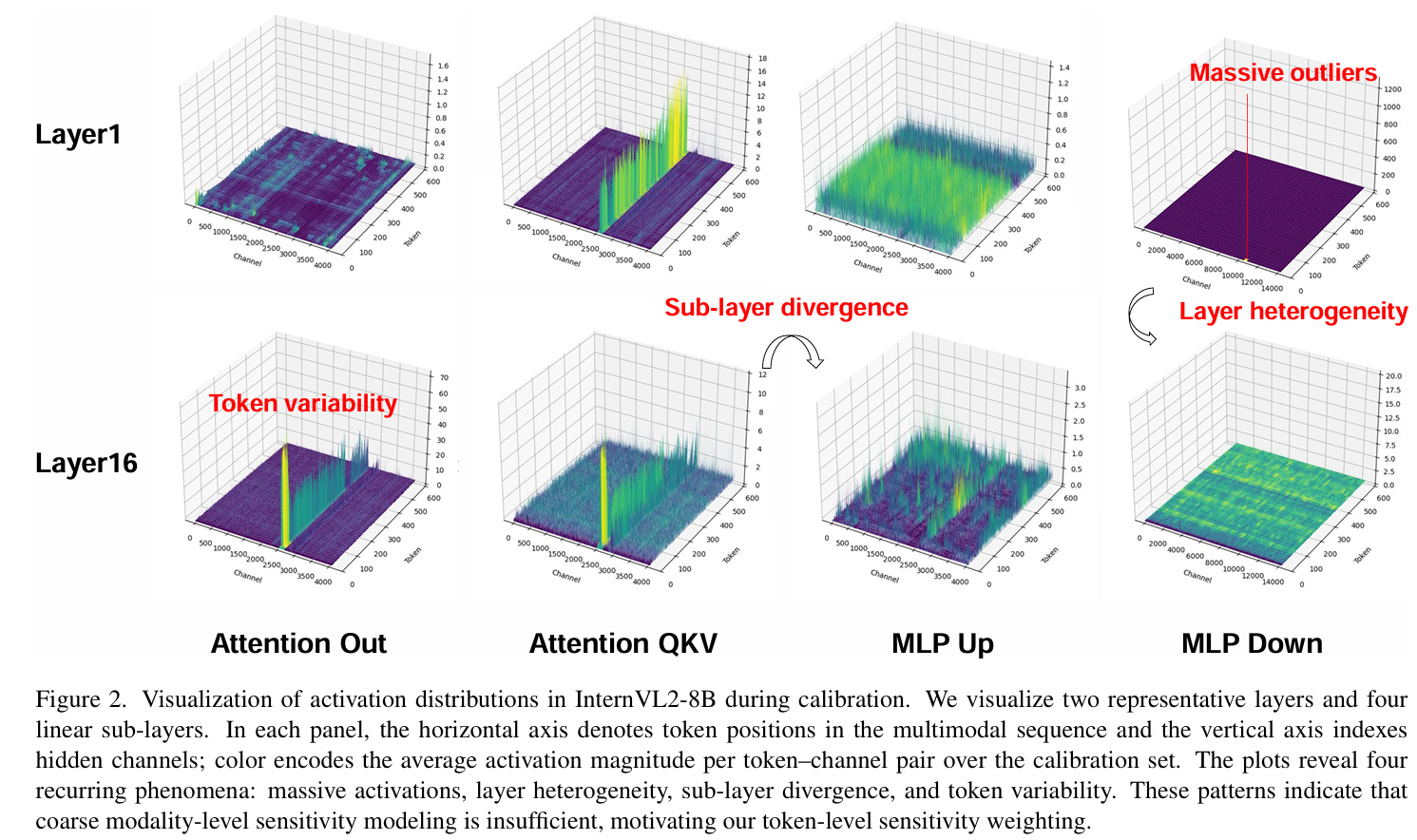
- 基于梯度(Gradient-based): 直接用SFT损失梯度的Token级别表现反而比模态级别差。原因是一旦引入量化噪声,梯度分布会改变,导致误差累积。
3.3 细粒度量化
这一节正式提出了本文的核心方法:基于量化感知积分梯度的细粒度量化。
- 核心思想:
借鉴机械可解释性中的“公理归因”概念,利用积分梯度来量化每个Token对量化误差的贡献程度。不再是粗略地给“视觉模态”或“文本模态”赋权,而是给每一个具体的Token赋予一个重要性权重。 - 量化感知积分梯度(QIG):
- 传统IG的局限: 经典的积分梯度(IG)衡量的是每个Token对全精度模型输出的贡献(公式2),但这并不能反映该Token对量化误差的敏感性。
- QIG的创新: 作者将解释目标从“模型预测”转变为“量化误差(全精度输出与量化输出之差)”。
- 基准输入: 传统的IG基准通常设为0或无输入。作者将其修改为量化后的输入 xqx_qxq(对应量化后的权重 wqw_qwq)。这样积分的路径是从量化状态到全精度状态。
- 数学定义(公式3):
QIG(x)=(x−xq)∫01∂(f(xα,w)−f(xα,wq))∂xαdαQIG(x) = (x - x_q) \int_0^1 \frac{\partial (f(x_\alpha, w) - f(x_\alpha, w_q))}{\partial x_\alpha} d\alphaQIG(x)=(x−xq)∫01∂xα∂(f(xα,w)−f(xα,wq))dα
其中 xα=xq+α(x−xq)x_\alpha = x_q + \alpha(x - x_q)xα=xq+α(x−xq)。 - 物理意义: QIGi(x)QIG_i(x)QIGi(x) 的值越大,说明恢复第 iii 个Token的表示能越大程度地减少量化带来的误差,即该Token对量化越敏感。
- 鲁棒性处理(IQR Clipping & 归一化):
- 原始的QIG值往往呈长尾分布,少数极端的Token会主导优化过程。
- 为了抑制异常值,作者使用了四分位距(IQR)裁剪:
C(QIGi)=clip(QIGi,Q1−1.5⋅IQR,Q3+1.5⋅IQR)C(QIG_i) = \text{clip}(QIG_i, Q_1 - 1.5 \cdot IQR, Q_3 + 1.5 \cdot IQR)C(QIGi)=clip(QIGi,Q1−1.5⋅IQR,Q3+1.5⋅IQR) - 将裁剪后的值归一化为Token重要性系数 λi\lambda_iλi,使得 ∑λi=1\sum \lambda_i = 1∑λi=1。
- 集成到量化优化中:
将计算出的Token重要性系数 λi\lambda_iλi 作为权重,乘到每个Token的重建误差上,从而修改原本的CWE优化目标:
E∗=argminE∑i=1Tλi∥QW(W∗E)QX(E−1∗Xi)−WXi∥22E^* = \arg\min_E \sum_{i=1}^T \lambda_i \| Q_W(W * E) Q_X(E^{-1} * X_i) - WX_i \|_2^2E∗=argEmini=1∑Tλi∥QW(W∗E)QX(E−1∗Xi)−WXi∥22
这就使得尺度搜索过程倾向于保护那些对量化误差更敏感的Token。
总结: Method部分从标准量化流程出发,指出了粗粒度(模态级)量化的缺陷,进而提出利用QIG来精确评估Token级别的量化敏感性,并通过重加权重建误差的方式,在不改变整体量化框架的前提下,实现了细粒度、感知量化噪声的优化。
4. Experiment
4.1 实验设置
这一节介绍了实验的具体环境和参数配置:
- 实现细节:遵循先前研究,采用逐Token激活量化和逐通道权重量化。由于W8A8已被证明是无损的,实验主要关注更具挑战性的 W4A8(4比特权重/8比特激活)和 W3A16(3比特权重/16比特激活)设置。所有实验在单张NVIDIA A800 GPU(80GB)上进行。
- 校准数据集:使用ShareGPT4V改进的COCO Caption数据集,随机抽取128个图像-标题对进行校准,并按照目标LVLM的对话提示格式进行格式化。
- 模型:在多个领先的开源LVLM上进行了量化,包括 LLaVA-onevision-7B、Qwen2-VL-7B 和 InternVL2-8B/26B。
- 基线方法:
- 对于仅权重量化(W3A16):对比了RTN、GPTQ、AWQ和MBQ。
- 对于权重-激活联合量化(W4A8):对比了RTN、SmoothQuant (SQ)和MBQ。
- 评估数据集:遵循LMMs-Eval协议,在多个视觉-语言基准上评估,包括MMMU和ScienceQA(视觉推理)、VizWiz(真实世界感知)、ChartQA和AI2D(结构化视觉信息理解)。
4.2 主要结果
这一节通过对比实验得出了三个关键结论:
- 直接将LLM的PTQ方法用于LVLM效果不佳:
- 在3比特量化下,简单的RTN基线相比FP16已有约4%的性能下降。
- 专为LLM设计的强方法(如GPTQ和SmoothQuant)在多模态场景下表现不稳定,甚至不如RTN。例如,在W4A8下,SmoothQuant在三个模型上都比RTN差;在W3A16下,GPTQ的平均精度也常落后于RTN。这表明忽略跨模态统计特性直接套用LLM量化方法是不可行的。
- 细粒度Token级加权优于模态级量化:
- 模态感知的MBQ通过平衡视觉和语言模态的重建误差,比RTN和GPTQ平均提升了约1%。
- 然而,本文提出的细粒度Token级方法(QIG)在所有6种量化配置(3个模型×2种比特宽度)中均取得了最高的平均精度,比MBQ额外带来约0.5%的平均增益。
- 例如,在LLaVA-onevision-7B的W3A16设置下,QIG将平均精度从70.44%提升至72.04%(提升1.60%)。在VizWiz和MMMU等具有挑战性的基准上,QIG比MBQ平均高出约1%,说明Token级加权更好地保留了敏感的视觉和推理Token。
- 可扩展至更大模型:
- 在InternVL2-26B(260亿参数)上与MBQ对比,QIG在ChartQA和VizWiz上均有明显提升。
- 在W4A8下,QIG将性能下降控制在FP16的3%以内;即使在激进的W3A16下,也仅比全精度模型低2%,证明了该方法在大规模模型上的可靠性和实用性。
4.3 消融研究与进一步分析
这一节深入分析了方法各组件的贡献、泛化能力及计算效率:
- QIG配置的消融实验(表4):
- 验证了QIG中两个关键设计的必要性:参考基准 和 归因目标。
- 对比了基准设为0或量化输入xqx_qxq,以及目标是任务输出f(x)f(x)f(x)还是量化误差f(x)−f(xq)f(x)-f(x_q)f(x)−f(xq)。
- 结果表明:将目标从任务输出改为误差(f(x)−f(0)f(x)-f(0)f(x)−f(0))能带来增益;将基准从0改为xqx_qxq并配合误差目标(f(x)−f(xq)f(x)-f(x_q)f(x)−f(xq))时效果最佳。这证明结合量化输入基准和明确归因量化误差对于获取可靠的Token敏感性至关重要。
- 与GPTQ结合的泛化性验证(表5):
- 为了证明细粒度量化策略的通用性,将其集成到GPTQ框架中。具体做法是将GPTQ的Hessian矩阵修改为H′=X⊤ΛXH' = X^\top \Lambda XH′=X⊤ΛX,其中Λ\LambdaΛ是由QIG得到的Token重要性系数对角矩阵。
- 在W3A16设置下,结合了QIG的GPTQ在LLaVA-onevision-7B和InternVL2-8B上均稳定优于原始GPTQ。例如,在VizWiz上提升了2.08%,证明了细粒度量化作为即插即用模块的有效性。
- 量化效率分析(表6):
- 对比了MBQ、Leave-One-Out(留一法扰动)和本文方法的GPU耗时。
- 本文方法引入的开销极小:相比于MBQ,QIG在InternVL2-8B和26B上仅增加了约2~2.5分钟的计算时间。
- 相比之下,同样能测量Token级敏感性的Leave-One-Out方法因为需要为每个Token扰动重复前向传播,耗时是MBQ的3-4倍。
- 这验证了QIG在可解释性、精度和计算效率之间取得了出色的平衡,适合实际部署。
MASQuant: Modality-Aware Smoothing Quantization for Multimodal Large Language Models
Introduction
-
背景与动机:
后训练量化(PTQ)对于在资源受限设备上部署大语言模型(LLMs)至关重要,而多模态大语言模型(MLLMs)的需求更为迫切。基于计算不变性的通道级平滑方法(如SmoothQuant)在纯文本LLM上效果显著,但其直接应用于MLLMs尚未得到充分探索。 -
核心问题发现:
通过系统分析视觉-语言和全模态MLLM,作者发现了一个根本性问题:不同模态的激活值幅度差异巨大(视觉token通常比文本/音频token大10–100倍)。当这些模态经过同一层时,主导模态的大幅激活值会主导平滑因子的计算,导致非主导模态的激活被过度平滑(信号被压制),引发严重的量化误差。作者将此现象命名为平滑错位(Smoothing Misalignment)。 -
现有方案的局限:
简单地为每个模态计算独立的平滑因子虽然能解决问题,但会破坏计算不变性,需要为每个模态存储不同的量化权重,违背了量化减少内存占用的初衷。 -
提出的方法:
作者提出MASQuant框架,包含两个关键组件:- 模态感知平滑(MAS):为每个模态学习专门的平滑因子,避免平滑错位。
- 跨模态补偿(CMC):利用SVD白化将模态间的激活差异转换为低秩形式,仅存储一个基础量化权重(以文本模态为基准),再通过轻量低秩矩阵对其他模态进行补偿,从而保持单一权重量化结构。
-
主要贡献:
- 识别并形式化了“平滑错位”问题。
- 证明模态间激活差异具有低秩特性,并提出CMC以维持计算不变性。
- 提出MASQuant方法,在视觉-语言和全模态MLLM上均取得优异的PTQ效果。
2. Related Work
- LLMs Quantization(大语言模型量化):
- 将LLM的量化方法分为两大类:量化感知训练(QAT)和训练后量化(PTQ)。QAT是在训练过程中引入量化以适应低精度计算,而PTQ是直接使用校准数据应用量化。
- 归纳了当前PTQ方法的四种主要途径:
(1) 通过二阶梯度或低秩校正进行误差补偿;
(2) 通道平滑以缓解异常值;
(3) 基于旋转的分布重构;
(4) 混合精度策略。
- MLLMs Quantization(多模态大语言模型量化):
- 指出由于跨模态激活的差异,MLLMs的量化面临独特的挑战,并回顾了针对MLLMs特性的已有工作:
- MQuant:发现视觉token的激活值可以比文本大20倍,提出了特定模态的量化方法。
- MBQ:观察到视觉token对量化不那么敏感,引入了梯度加权的误差平衡。
- QSLAW:通过可学习的权重组缩放,解决了多模态输入带来的异常值密度增加问题。
- 指出由于跨模态激活的差异,MLLMs的量化面临独特的挑战,并回顾了针对MLLMs特性的已有工作:
- 研究动机总结:
- 尽管已有上述进展,但MLLMs中的激活量化问题仍然没有得到充分解决,这也正是本文提出“模态感知平滑量化”方法的动机所在。
3. Preliminaries
1. 3.1 Computational Invariance based PTQ(基于计算不变性的训练后量化)
- 量化基本定义:首先定义了PTQ的基本操作,即将高精度浮点张量映射为低精度整数张量,并给出了量化公式(包含缩放因子、零点和取整操作)。同时介绍了WxAy的记号(如W4A16, W8A8等)。
- 计算不变性原理:对于线性层 Y=XWY=XWY=XW,基于计算不变性,可以通过引入一个矩阵 SSS(可以是对角矩阵或正交矩阵)将其重写为 Y=(XS−1)⋅(SW)Y=(XS^{-1})\cdot(SW)Y=(XS−1)⋅(SW)。
- 平滑的作用:指出 SSS 的作用是减少激活值 XXX 中的异常值,从而获得更好的量化重建损失 L=L(Q(XS−1)⋅Q(SW),XW)L = L(Q(XS^{-1})\cdot Q(SW), XW)L=L(Q(XS−1)⋅Q(SW),XW)。
- 本文的应用:强调本文正是基于这一原理,证明了在多模态大语言模型(MLLMs)中,对不同模态应用特定的 SSS 矩阵可以实现鲁棒且有效的PTQ性能。
2. 3.2 SVD-based Whitening(基于SVD的白化)
- 白化变换的推导:介绍了先前工作中用于低秩权重压缩的SVD白化方法。通过对激活协方差矩阵进行SVD分解(PΛP⊤=SVD(X⊤X)P\Lambda P^\top = SVD(X^\top X)PΛP⊤=SVD(X⊤X)),可以得到白化矩阵 T=(PΛ1/2)⊤T=(P\Lambda^{1/2})^\topT=(PΛ1/2)⊤,该变换使得激活满足正交归一化条件。
- 低秩近似:介绍了已有研究(如SVD-LLMv2)证明,对白化后的权重 TWTWTW 进行SVD并截断至秩 rrr,可以最小化重建误差。
- 本文的创新与联系:明确指出,虽然现有方法将白化用于权重压缩,但本文是首次证明白化可以有效补偿跨模态的权重差异,从而实现跨模态的统一量化。这是后续第4节提出“跨模态补偿(CMC)”方法的数学基石。
根据参考信息,这篇论文的4. MASQuant部分详细介绍了其提出的核心框架,该框架由**模态感知平滑(MAS)和跨模态补偿(CMC)**两个关键组件构成,旨在解决多模态大语言模型(MLLMs)量化中的“平滑不对齐”和“跨模态计算不变性”问题。具体内容如下:
4.1 动机 - 重新审视平滑因子:现有方法(如SmoothQuant, AWQ)仅通过搜索超参数 β\betaβ 来计算闭式解的平滑因子,而未将其视为自由参数直接优化。受OmniQuant启发,本文提出直接优化平滑因子矩阵 SSS 以最小化量化重建误差。
- 平滑不对齐:这是MLLMs量化的根本障碍。由于不同模态的激活幅度差异巨大(如视觉token通常比文本/音频大10-100倍),使用混合模态数据校准时,统一的平滑因子会被主导模态(幅度最大的模态)支配,导致非主导模态的信号被过度平滑,产生严重的量化误差。
4.2 模态感知平滑 - 核心思想:为每个模态 mmm(如文本、图像、音频)维护独立的平滑因子 SmS_mSm,从根本上消除主导模态的支配。
- 优化过程:首先根据各模态的激活范围初始化 SmS_mSm,然后通过最小化各模态特定的MAE损失来优化 SmS_mSm,确保其捕捉特定模态的统计特性而不受其他模态干扰。
- 理论证明:提出了定理1,从数学上量化了使用统一平滑因子时,非主导模态的信号量化噪声比(SQNR)的退化程度,证明了模态感知平滑的必要性。推理时,各模态使用各自的 SmS_mSm 进行计算。
4.3 跨模态补偿 - 问题产生:虽然MAS消除了平滑不对齐,但它为每个模态生成了不同的量化权重 Q(SmW)Q(S_m W)Q(SmW),这违反了计算不变性(即PTQ要求所有模态共享单一量化权重以减少内存)。
- 核心策略:选择文本模态的量化权重 Q(StW)Q(S_t W)Q(StW) 作为共享的基础权重,对其他模态(如视觉)通过低秩校正进行补偿。
- SVD白化与低秩近似:
- 直接对权重差异 ΔW=SvW−Q(StW)\Delta W = S_v W - Q(S_t W)ΔW=SvW−Q(StW) 进行低秩近似会失败,因为其缺乏低秩结构且不能最小化输出残差 ΔY\Delta YΔY。
- 关键洞察:对激活进行白化变换可以诱导出低秩结构。通过计算白化矩阵 TTT,将白化后的残差 T(ΔW)T(\Delta W)T(ΔW) 进行截断SVD,再逆白化,即可得到低秩校正矩阵 L1L_1L1 和 L2L_2L2。
- 理论证明:定理2证明了这种基于SVD白化的低秩补偿方法能够最小化重建损失。
- 最终推理:
- 文本模态:直接使用基础量化输出 Q(XtSt−1)⋅Q(StW)Q(X_t S_t^{-1}) \cdot Q(S_t W)Q(XtSt−1)⋅Q(StW)。
- 其他模态:在基础输出上加上轻量级的低秩校正项 XvSv−1⋅L1L2X_v S_v^{-1} \cdot L_1 L_2XvSv−1⋅L1L2。
- 这在保持单一量化权重高效性的同时,保留了特定模态的准确性。
5. Experiments
5.1 实验设置
- 模型:在Qwen2.5-VL和Qwen2.5-Omni(3B和7B)上进行评估,涵盖视觉-语言双模态和视觉-音频-文本三模态。为保持通用性,仅对LLM解码器组件(Thinker)进行量化。
- 基线方法:与RTN、AWQ、SmoothQuant (SQ) 和 MBQ 等最先进的通道平滑PTQ方法进行对比。
- 基准测试:包括音频任务(Librispeech, Wenetspeech)、视觉推理(OCRBench, TextVQA, Vizwiz, ScienceQA, MMMU)和多模态推理。
5.2 视觉-语言MLLMs - 在W8A8量化下,MASQuant在两种模型尺寸上均能与FP16性能匹配,说明妥善处理模态特性后,MLLMs可无损量化至8-bit。
- 在激进的W4A8量化下,RTN完全失败,SmoothQuant严重退化,而MASQuant依然表现稳健。这揭示了模态主导地位在低比特下具有破坏性,统一平滑因子会严重损害弱势模态。
5.3 视觉-音频-语言MLLMs - 随着模态多样性增加,模态主导问题加剧。在W4A8下,SmoothQuant在3B模型上的音频性能灾难性崩溃(例如Librispeech WER从3.9飙升至77.4,Wenetspeech从7.5飙升至94.2)。
- 音频因激活幅度较小,在与视觉/文本竞争平滑资源时被完全压制。MASQuant则维持了接近FP16的音频质量,证实了按模态独立平滑能有效防止弱势模态的崩溃。
5.4 分析 - 模态主导性:视觉token的激活显著大于文本,导致统一平滑因子严重不匹配文本分布。αi分布的非均匀性验证了MAS带来的SQNR增益。
- 有效秩:白化操作显著降低了权重差异(ΔW\Delta WΔW)的有效秩,验证了CMC利用低秩结构设计的合理性。
- MAS的效果:在W4A8下,统一平滑在LibriSpeech上造成77.4的WER,而MAS仅3.8。这表明可学习的优化在无模态感知时反而会放大差距。
- 模态损失权重:消融实验表明,文本和视觉平滑权重相等(λt=λv=1.0\lambda_t = \lambda_v = 1.0λt=λv=1.0)时效果最好。降低视觉权重会损害视觉性能,降低文本权重则会全面退化。
- 训练轮数:性能在第2个epoch达到峰值,随后略有下降,因此选择2个epoch作为效率与性能的折中。
- CMC的效果:CMC在低秩机制下主导了非白化基线,将匹配MBQ所需的秩降低了4倍。
- 基础模态选择:选择文本作为基础模态可将CMC与解码过程解耦,避免额外的计算和内存开销;若选其他模态则会导致计算和内存成本增加。
5.5 推理加速 - 实现了基于Nunchaku的自定义CUDA内核,融合了投影和量化算子,并使用多模态掩码高效管理条件低秩执行。
- 在RTX 4090上,MASQuant相比FP16实现了2.5倍的加速,相比MBQ仅增加5-10%的延迟开销,且保持了相同的解码延迟。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)