SpringAI实用-MCP
目录
4.2、在 Spring AI 应用中使用 MCP Client
4.2.3、将 MCP 工具注入 ChatClient来调用
1、概论
MCP(Model Context Protocol,模型上下文协议),标准化协议,解决大模型与外部世界连接的标准化问题,让大模型以结构化的方式与外部工具和资源进行交互。
MCP Java SDK提供了模型上下文协议的Java实现,通过同步和异步通信模式,实现了与AI模型和工具的标准化交互。
Spring AI通过专用的引导启动器和MCP Java注解为MCP提供全面支持,使得构建能够无缝连接到外部系统的复杂AI驱动应用程序更简单。在Spring AI 中集成 MCP,可以将 Spring Boot 应用打造成一个标准的 MCP 服务器,或者让AI 应用通过 MCP 客户端去调用各种外部服务。开发人员可以参与到MCP生态系统的两个方面——构建使用MCP服务器的AI应用程序,以及创建向更广泛的AI社区提供基于Spring的服务的MCP服务器。
在没有 MCP 之前,如果想让 AI 读取本地文件、查询数据库或调用 API,开发者需要为每一个模型(如 Claude、GPT)和每一个工具(如文件系统、PostgreSQL)编写专门的连接代码,这导致了 N个模型 × M个工具 的接口爆炸问题。
现在,工具开发者只需按照 MCP 标准实现一个“服务器”,任何支持 MCP 的 AI 应用(如 Cursor、Claude Desktop)都可以通过“客户端”即插即用地调用它。
2、MCP核心架构:三大角色
MCP 采用客户端-服务器(Client-Server)架构,主要包含三个核心角色:
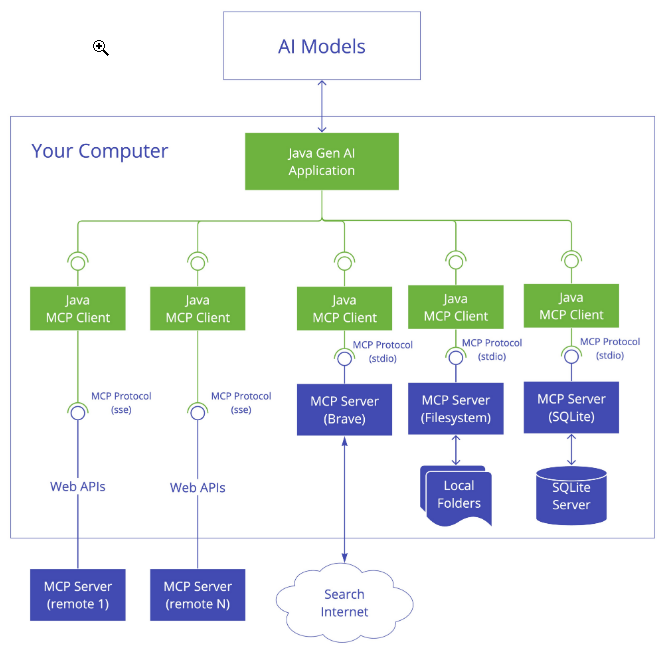
2.1、Host (主机)-直接面向用户的AI应用
是用户直接交互的界面。比方:Cursor 编辑器、Claude Desktop、Cherry Studio 等。负责发起连接、管理会话、展示结果。
2.2、Client (客户端)
内置于 Host 中的通信中间件,是模型的“翻译官”。
职责:将模型的意图转换为标准的 JSON-RPC 请求,发送给 Server;再将 Server 的响应返回给模型。
2.3、Server (服务器)
外部能力和数据的提供者。比方:一个能操作文件系统的程序、一个能查询天气的 API 服务。
职责:封装并暴露具体的功能,等待 Client 的调用。
有两种模式:
远程 SSE 模式(推荐用于生产环境、微服务架构、多客户端共享,支持负载均衡、服务解耦)。
本地 Stdio 模式(推荐用于本地开发、单用户工具)。
3、MCP核心能力
MCP可以向 AI 暴露三种标准化的能力:
| 原语 | 控制权 | 能力 | 典型场景 |
|---|---|---|---|
| Resources (资源) | 应用/服务器 | 提供只读数据 | 读取本地文件、查询数据库表结构、获取知识库内容 |
| Tools (工具) | 模型 | 执行可写/可操作的函数 | 发送邮件、运行代码、调用第三方 API、控制设备 |
| Prompts (提示) | 用户 | 提供预定义的工作流模板 | 代码生成模板、报告撰写模板、客服话术 |
4、在 Spring AI 中集成 MCP
在 Spring AI 中,MCP 的集成主要分为两种模式:
- 作为 MCP Server:将Spring Boot 应用变成一个 MCP 服务器,对外暴露工具和数据。
- 作为 MCP Client:让Spring AI 应用通过 MCP 协议去调用外部的 MCP 服务器。
4.1、构建MCP Server
将 Spring Boot 应用打造为 MCP Server,将现有的业务逻辑封装成 MCP 工具,供任何 MCP 客户端调用。
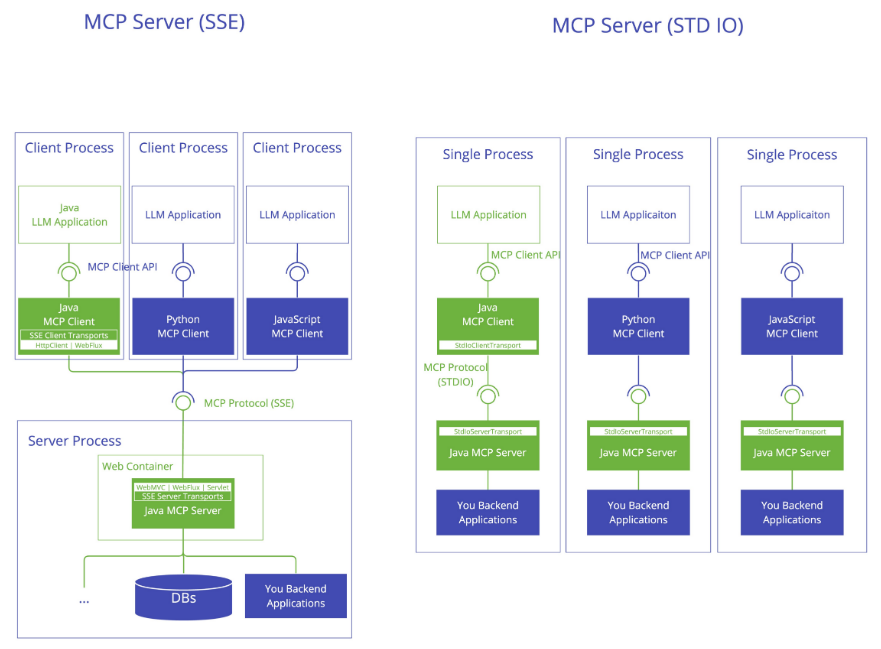
STDIO(本地模式):用于本地开发调试,Client 将 Server 作为子进程启动。
远程模式又分为WebMVC和WebFlux (Reactive)两种:用于生产环境,支持跨服务、跨机器调用。
4.1.1、添加 MCP 依赖和配置
4.1.1.1、STDIO(本地模式)
Client 将 Server 作为子进程启动。Server 端需要打包成可执行 JAR,并配置为 Stdio 模式(禁用 Web 容器)。
<dependencies>
<!-- Spring AI MCP Server Starter -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-server</artifactId>
</dependency>
</dependencies>配置属性:spring.ai.mcp.server.stdio=true
spring:
main:
web-application-type: none # 禁用 Web 容器,纯控制台应用
ai:
mcp:
server:
stdio: true # 启用 Stdio 模式注意:打包后,需要能通过 java -jar xxx.jar 命令在命令行启动它。
4.1.1.2、WebMVC或WebFlux
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-server-webmvc</artifactId>
</dependency> <dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-server-webflux</artifactId>
</dependency>属性:
spring.ai.mcp.server.protocol=SSEor empty- spring.ai.mcp.server.protocol=STREAMABLE(流式)
- spring.ai.mcp.server.protocol=STATELESS(无状态)
server:
port: 8081 # Server 独立端口
spring:
ai:
mcp:
server:
name: order-service
version: 1.0.0
# 协议选择:SSE (推荐) 或 STREAMABLE
protocol: SSE 4.1.2、定义 MCP 工具
创建一个 Spring 组件,并使用 @Tool 注解来标记想要暴露的方法。
import org.springframework.ai.tool.annotation.Tool;
import org.springframework.ai.tool.annotation.ToolParam;
import org.springframework.stereotype.Component;
@Component
public class MyBusinessTools {
/**
* 暴露一个查询订单状态的工具
*/
@Tool(description = "根据订单ID查询订单的当前状态")
public String getOrderStatus(@ToolParam(description = "订单的唯一标识符") String orderId) {
// 这里是你真实的业务逻辑,例如查询数据库
return "订单 " + orderId + " 的状态是:已发货";
}
}4.1.3、配置 MCP Server
创建一个配置类,将工具注册到 MCP Server 中。
import org.springframework.ai.tool.ToolCallbackProvider;
import org.springframework.ai.tool.method.MethodToolCallbackProvider;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class McpServerConfig {
@Bean
public ToolCallbackProvider myToolsProvider(MyBusinessTools myBusinessTools) {
// 使用 MethodToolCallbackProvider 自动扫描 @Tool 注解的方法
return MethodToolCallbackProvider.builder()
.toolObjects(myBusinessTools)
.build();
}
}远程模式完成以上配置后,启动Spring Boot 应用,确保它在 http://your-server-ip:8081 可访问。它现在就是一个标准的 MCP Server,默认会通过sse (Server-Sent Events) 暴露 getOrderStatus 工具。
4.2、在 Spring AI 应用中使用 MCP Client
这个模式允许Spring AI 应用去调用外部的 MCP 服务,例如百度的地图服务或一个本地的文件系统服务。
4.2.1、添加 MCP Client 依赖
<dependencies>
<!-- Spring AI MCP Client Starter -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-client</artifactId>
</dependency>
</dependencies> <dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-client-webflux</artifactId>
</dependency>4.2.2、配置外部 MCP Server
在 application.yml 中声明要连接的外部 MCP 服务。
4.2.2.1、远程
使用 streamable-http 或 sse 配置块来连接远程地址。
spring:
ai:
mcp:
client:
enabled: true
# 对应服务端的协议,这里使用 streamable-http 兼容 SSE
streamable-http:
connections:
weather-server: # 连接别名
url: http://localhost:8082 # 服务端地址
order-server: # 连接别名
url: http://localhost:8081 # 服务端地址
4.2.2.2、本地Stdio
Client 会将 Server 作为一个子进程启动,通过标准输入/输出流通信。适合单机开发调试。
Client 需要知道如何启动 Server 进程。
spring:
ai:
mcp:
client:
enabled: true
stdio:
connections:
my-local-server:
# 启动命令
command: java
# 启动参数,指向你的 MCP Server JAR 包
args:
- -jar
- /absolute/path/to/your/mcp-server.jar或
spring:
ai:
mcp:
client:
enabled: true
# 配置要连接的 MCP Server
stdio:
# 使用 JSON 配置文件定义服务器
servers-configuration: classpath:/mcp-servers.json然后,在 src/main/resources/mcp-servers.json 文件中定义服务器配置。
注意:路径必须是绝对路径。Windows 用户如果使用 npx 等脚本,需要用 cmd.exe /c 包裹命令。
{
"mcpServers": {
"local-weather": {
"command": "java",
"args": [
"-jar",
"/absolute/path/to/your/mcp-server.jar"
]
}
}
}或者连接一个本地的文件系统 MCP 服务器:
[
{
"name": "filesystem",
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-filesystem",
"/path/to/your/allowed/directory"
]
}
]4.2.3、将 MCP 工具注入 ChatClient来调用
本地Stdio和远程调用代码完全一致,Spring AI 会自动处理进程间通信。
Spring AI会自动发现配置的MCP客户端,并将其提供的工具注册为一个 ToolCallbackProvider。我们只需要将其注入到 ChatClient 中即可。
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.tool.ToolCallbackProvider;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class AiClientConfig {
@Bean
public ChatClient chatClient(ChatClient.Builder builder, ToolCallbackProvider tools) {
// 将 MCP 发现的工具注册到 ChatClient
// 模型现在就可以自动调用 filesystem 服务器的工具了
return builder
.defaultToolCallbacks(tools)
.build();
}
}现在,当使用这个 chatClient 提问时,“查询订单状态”就会调用远程服务。
例如“帮我列出 /path/to/your/allowed/directory 目录下的所有文件”,模型会自动判断需要调用 MCP 工具,Spring AI 会通过 MCP 协议与外部服务器通信,执行操作,并最终将结果整合后返回。
5、服务注册、发现、负载均衡
目前,原生的 Spring AI 框架本身并不具备服务注册、发现和负载均衡的能力。是 Spring AI Alibaba 项目特有的,并且需要与 Nacos 注册中心(3.1.0 及以上版本,因为该版本才正式引入了面向 AI Agent 的 A2A (Agent-to-Agent) 注册中心功能)配合使用。
核心是:MCP Server 将自身信息(包括工具元数据)注册到 Nacos,MCP Client 则从 Nacos 获取服务列表,并基于此实现智能路由和负载均衡调用。
如前面目录所写,原生的需配置固定的地址,不具备服务发现、动态感知上下线或负载均衡的能力。
另外Alibaba还支持高可用(当某个 Server 实例宕机,Client 会自动感知并切换到其他健康实例。),智能路由(通过 Nacos MCP Router 组件,可根据工具描述进行智能路由,而不仅是简单的负载均衡。)
5.1、服务注册
整个流程的起点,由 MCP Server 端主动完成。
- 启动与收集:当基于 Spring AI Alibaba 开发的 MCP Server 应用启动时,框架会自动收集当前实例的信息。不仅包括常规的 IP、端口、协议类型(SSE),最关键的是会收集该实例提供的所有 MCP 工具(Tools)的定义和描述。
- 注册到 Nacos:随后,
NacosMcpRegister组件会将这些服务器元数据和工具列表一并注册到 Nacos 注册中心。 - 动态更新:如果 Server 的工具发生变更(例如新增或修改了工具),它会自动将最新的工具元数据同步到 Nacos,确保注册中心的信息是最新的。
这一步将传统的“服务实例注册”升级为“服务能力(工具)注册”,为后续的智能发现奠定了基础。
5.2、服务发现
服务发现由 MCP Client 端驱动,它不再需要硬编码 Server 的地址,而是从 Nacos 动态获取。
- 订阅服务:MCP Client 在启动时,会连接到 Nacos,并订阅它所依赖的 MCP 服务。
- 获取实例列表:Nacos 会将当前可用的、符合要求的 MCP Server 实例列表推送给 Client。Client 会在本地维护一个可用的 Server 实例连接池。
- 感知变更:当有新的 MCP Server 实例上线或旧实例下线时,Nacos 会实时通知 Client。Client 会自动更新其内部的连接池,实现了对服务实例变更的动态感知。
5.3、负载均衡
负载均衡发生在 MCP Client 调用工具的时刻。
- 选择实例:当 AI 模型决定调用某个 MCP 工具时,请求会交给 Spring AI MCP Client 处理。Client 会从它维护的可用 Server 实例连接池中,根据内置的负载均衡策略(通常是轮询)选择一个具体的实例。
- 发起调用:Client 通过选中的 Server 实例的 SSE 端点,发起工具调用请求。
- 故障转移:如果调用失败(例如目标实例宕机),Client 会自动重试,并选择另一个健康的实例进行调用,从而实现高可用。
5.4、Nacos MCP Router 的智能路由
除了基础的负载均衡,Spring AI Alibaba 还提供了更高级的 Nacos MCP Router 组件,它作为一个智能代理层,能实现更复杂的调度。
- 工具聚合:Router 本身也是一个 MCP Server,它从 Nacos 注册中心获取所有后端 MCP Server 的工具信息,并将它们聚合成一个统一的工具列表暴露给上层的 AI Agent。
- 智能筛选:当 AI Agent 发起一个任务时,Router 可以根据任务描述,智能地筛选出最相关的几个 MCP Server,而不是简单地进行轮询。
- 代理调用:AI Agent 只需与 Router 交互,Router 会负责将工具调用请求代理到最终选定的后端 MCP Server 上,并将结果返回。
这种方式不仅实现了负载均衡,还引入了基于语义的智能路由,大大提升了 AI 调用工具的效率和准确性。
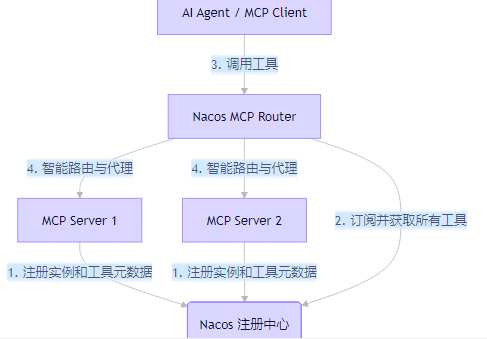
流程解析:
- 注册:多个 MCP Server 实例启动后,各自将自己的信息和提供的工具列表注册到 Nacos。
- 发现:Nacos MCP Router 从 Nacos 中拉取并订阅所有 MCP Server 的工具信息。
- 调用:AI Agent 只需连接 Router,并向其发起工具调用请求。
- 路由:Router 根据请求内容,智能地从后端 Server 池中选择一个最合适的实例,代理完成调用。
通过这套机制,MCP 应用获得了与微服务架构同等的弹性伸缩、高可用和动态治理能力。
6、WebMvc 和 WebFlux
Spring WebMvc 和 Spring WebFlux 都是 Spring 框架用于构建 Web 应用的模块,但它们的设计理念和适用场景有显著区别。WebMvc 是经典的同步阻塞模型,而 WebFlux 是为高并发设计的异步非阻塞响应式模型。
WebMvc 理解为传统的“一对一服务”模式,而 WebFlux 则是高效的“一对多服务”模式。
| 对比维度 | Spring WebMvc | Spring WebFlux |
|---|---|---|
| I/O 模型 | 同步阻塞 | 异步非阻塞 |
| 线程模型 | 每个请求占用一个独立线程 (Thread-per-Request) | 少量固定线程处理海量请求 (Event-Loop) |
| 编程模型 | 命令式 (Imperative) | 响应式 (Reactive) |
| 数据返回类型 | 直接返回对象或集合 | 返回 Mono<T> (0-1个元素) 或 Flux<T> (0-N个元素) |
| 底层依赖 | 必须依赖 Servlet 容器 (如 Tomcat, Jetty) | 默认使用 Netty,也可兼容 Servlet 容器 |
| 背压支持 | 不支持 | 支持,可防止快速生产者压垮慢速消费者 |
线程模型与I/O处理,是两者最根本的区别,决定了它们在不同场景下的性能表现。
6.1、Spring WebMvc:同步阻塞模型
- 工作原理:当一个 HTTP 请求到达时,服务器会从线程池中分配一个专门的线程来处理它。这个线程会一直“阻塞”并等待整个请求处理流程完成,包括业务逻辑、数据库查询、外部 API 调用等 I/O 操作。在此期间,该线程无法处理其他任何请求。
- 类比:就像餐厅里的一位服务员,从点餐、下单、等菜到上菜,全程只服务于一桌客人。如果厨房出菜慢,服务员就只能干等着,无法去接待新来的客人。
- 缺点:在高并发场景下,大量的 I/O 等待会迅速耗尽线程池资源,导致系统吞吐量下降。
6.1.1、适合使用 Spring WebMvc 的场景
- CPU 密集型应用:应用主要进行大量计算(如图像处理、复杂算法),而非 I/O 等待,WebMvc 的线程模型能更好地利用 CPU 资源。
- 传统的 CRUD 应用:对于业务逻辑简单、并发量不高的企业后台、管理系统等,WebMvc 开发效率高,生态成熟,是更简单直接的选择。
- 依赖阻塞式库:如果项目重度依赖传统的 JDBC、JPA 或 MyBatis 等阻塞式数据访问框架,使用 WebFlux 无法发挥其非阻塞优势,反而会增加复杂度。
6.2、Spring WebFlux:异步非阻塞模型
- 工作原理:当一个请求到达时,WebFlux 会用一个事件循环线程快速处理,一旦遇到 I/O 操作(如查询数据库),它会立即将 I/O 任务提交出去,然后释放当前线程去处理下一个请求。当 I/O 操作完成后,会通过回调机制通知系统,再由事件循环线程回来处理剩余逻辑并返回响应。
- 类比:就像一位高效的服务员,为客人点完餐后,立刻将单子交给厨房,然后马上去服务下一桌客人。当厨房的菜准备好后,会按铃通知,服务员再过来上菜。一个服务员可以轻松服务多桌客人。
- 优点:用极少的线程就能处理海量并发连接,尤其适合 I/O 密集型应用,资源利用率极高。
6.2.1、适合使用 Spring WebFlux 的场景
- I/O 密集型高并发应用:当应用需要处理大量并发请求,且大部分时间花在等待数据库、调用第三方 API 或读写文件时,WebFlux 能显著提升系统吞吐量和性能。
- 微服务 API 网关:网关需要聚合多个下游服务的调用结果。WebFlux 可以轻松地并行发起多个非阻塞请求,总耗时约等于最慢的那个服务耗时,效率远高于串行调用。
- 实时数据流处理:对于需要推送实时数据的应用,如股票行情、即时通讯、Server-Sent Events (SSE) 等,WebFlux 的响应式流模型是天然的选择。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)