你真的会用AI编译工具吗?——Trae的玩法实测
·
也是看到一个大佬的开源项目受到启发,于是我便将其应用到我自己本地电脑的Trae当中,因为我自己是一个重度字节产品的体验者。这一尝试就一发的不可收拾了。直接大大的提高了我一整个AI开发的体验和体验效果。
灵感来源:https://github.com/mattpocock/skills
一、效果展示
这里我会用实际的测试结果来进行效果的展示
测试一、测试场景:需求不清楚;预期调用skill为grill-with-docs
测试输入:我想给当前项目加一个用户权限控制功能,但我还没想清楚具体怎么设计。先不要写代码,帮我把需求边界梳理清楚。
测试结果输出:
测试二、测试场景:报错排查;预期调用skill为diagnose
测试输入:项目启动失败了,控制台报错:Cannot find module ‘xxx’。帮我排查一下原因。
测试结果输出:
其他测试效果就不过多展示,接下来进入正题,如何配置达到我这样的效果
二、配置步骤
2.1 拉取项目到本地
git clone https://github.com/mattpocock/skills.git
解压以后通过trae的后台配置进行skill的配置
2.2 进行Trae的skill全局配置
选择你刚刚拉下的文件夹中对应技能的SKILL.md文档,Trae能够自动识别并进行配置。需要安装的skill清单列表如下:
| Skill 名称 | Matt Pocock 仓库中的目录路径 |
|---|---|
| diagnose | skills/engineering/diagnose/ |
| grill-with-docs | skills/engineering/grill-with-docs/ |
| improve-codebase-architecture | skills/engineering/improve-codebase-architecture/ |
| prototype | skills/engineering/prototype/ |
| setup-matt-pocock-skills | skills/engineering/setup-matt-pocock-skills/ |
| tdd | skills/engineering/tdd/ |
| to-issues | skills/engineering/to-issues/ |
| to-prd | skills/engineering/to-prd/ |
| triage | skills/engineering/triage/ |
| caveman | skills/productivity/caveman/ |
| grill-me | skills/productivity/grill-me/ |
| write-a-skill | skills/productivity/write-a-skill/ |
2.3 配置skill调用Router
配置这个是为了能够针对你的需求精准的调用对应的skill
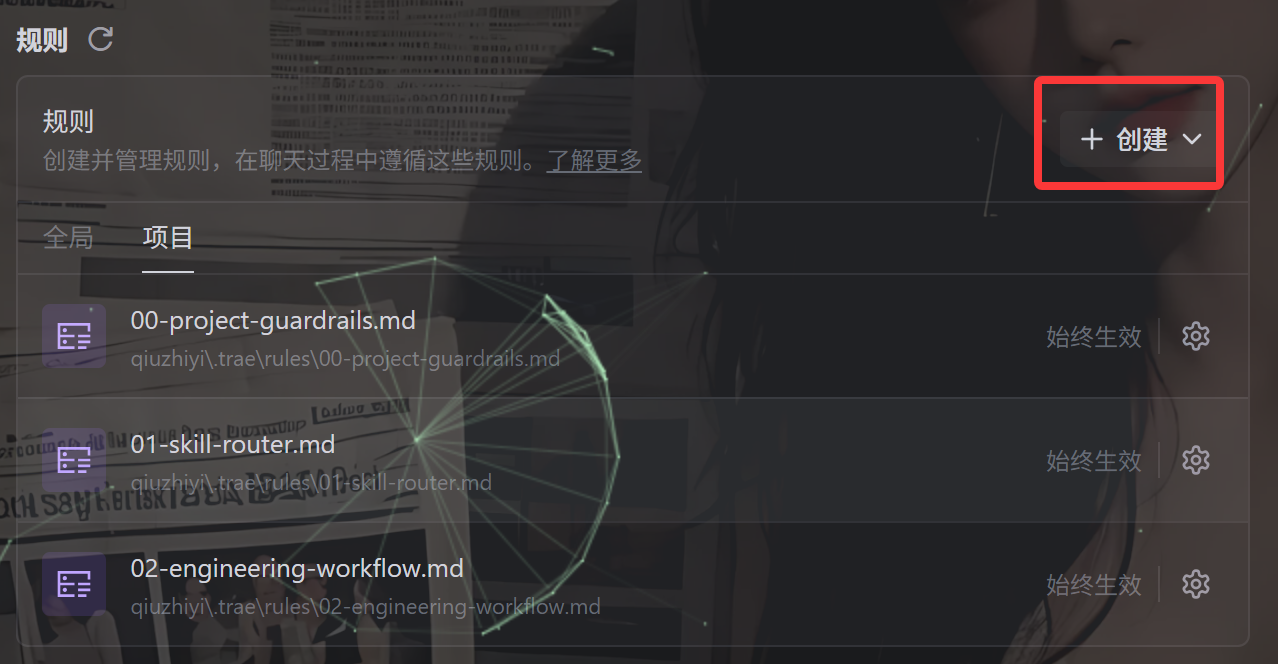
在这儿创建一个项目规则:然后命名为:01-skill-router.md
里面放的规则直接复制下面这段内容
# Skill Router
本规则只负责根据用户请求选择合适的 skill,不负责展开具体执行流程。
## 基本原则
- 用户不需要记住 skill 名称。
- 默认根据用户意图自动选择 skill。
- 用户明确指定 skill 时,优先使用用户指定的 skill。
- 如果普通回答足够,不要强行使用 skill。
- 开始任务前只需简短说明:采用哪个 skill,以及原因。
## Skill 路由表
| 用户意图 / 场景 | 使用 skill |
|---|---|
| 需求不清楚、方案没想明白、需要先追问 | `grill-with-docs` |
| 非项目强相关的想法评审、方案追问 | `grill-me` |
| 新功能开发、复杂逻辑、原因已明确的 bug 修复 | `tdd` |
| 报错、启动失败、接口失败、日志异常、性能问题 | `diagnose` |
| 想理解代码、模块关系、项目结构 | `zoom-out` |
| 架构混乱、模块边界不清、想找重构点 | `improve-codebase-architecture` |
| 快速验证技术方案、先做可丢弃原型 | `prototype` |
| 整理需求、生成 PRD | `to-prd` |
| 拆开发任务、拆 issue、生成任务清单 | `to-issues` |
| 判断任务类型、状态、是否适合交给 AI | `triage` |
| 创建新 skill、优化已有 skill | `write-a-skill` |
| 用户要求简洁、少废话、直接给命令 | `caveman` |
| 初始化、检查、验证 skills 配置 | `setup-matt-pocock-skills` |
## 优先级规则
当多个 skill 都可能适用时,按以下顺序判断:
1. 用户明确指定 skill → 使用用户指定的 skill。
2. 报错、失败、异常、日志、性能问题 → `diagnose`。
3. 需求不清楚、方案不明确 → `grill-with-docs`。
4. 想理解代码或项目结构 → `zoom-out`。
5. 想改善架构 → `improve-codebase-architecture`。
6. 想快速验证方案 → `prototype`。
7. 明确要开发且适合测试保障 → `tdd`。
8. 想整理需求文档 → `to-prd`。
9. 想拆开发任务 → `to-issues`。
10. 想判断任务状态或是否适合 AI → `triage`。
11. 想创建或优化 skill → `write-a-skill`。
12. 想初始化或验证 skills 配置 → `setup-matt-pocock-skills`。
13. 用户要求极简输出 → `caveman` 作为输出风格叠加使用。
## 常见组合
| 场景 | 推荐顺序 |
|---|---|
| 未知原因的 bug | `diagnose` → `tdd` |
| 模糊的新功能 | `grill-with-docs` → `to-prd` → `to-issues` → `tdd` |
| 大型架构改造 | `zoom-out` → `improve-codebase-architecture` → `prototype` → `tdd` |
| 配置体系检查 | `setup-matt-pocock-skills` → `triage` → `to-issues` |
## 开场格式
自动选择 skill 后,使用极简格式说明:
```text
采用:xxx
原因:xxx
2.4、配置其他项目配置文件,以保证Router文件生效和提升AI整体的使用效果
i.00-project-guardrails.md
# 项目开发底线规则
你是当前项目的 AI 编程助手。处理本项目时必须遵守以下规则。
## 基本原则
- 先理解项目结构,再修改代码。
- 先确认需求边界,再生成实现方案。
- 优先小步修改,避免一次性大规模重构。
- 不引入无必要的新依赖。
- 不覆盖用户已有业务逻辑。
- 不凭空假设业务规则。
- 涉及配置、鉴权、环境变量、数据库迁移、构建脚本时必须额外谨慎。
## 修改代码前
在修改前先说明:
- 准备使用哪个 skill
- 准备阅读哪些文件
- 预计修改哪些文件
- 准备用什么方式验证
## 修改代码后
完成后必须说明:
- 改了什么
- 改了哪些文件
- 如何验证
- 验证结果
- 是否存在风险或未完成项
ii.02-engineering-workflow.md
# 工程开发默认工作流
处理当前项目的开发任务时,默认遵循以下流程。
## 1. 理解
- 阅读相关文件。
- 识别技术栈、目录结构、已有约定。
- 如果存在 `CONTEXT.md`,优先读取项目术语和业务上下文。
- 如果存在 `docs/adr/`,涉及架构时读取相关 ADR。
## 2. 计划
输出简短计划,包括:
- 目标
- 预计修改文件
- 验证方式
- 可能风险
## 3. 实现
- 一次只解决一个明确问题。
- 优先改最小必要范围。
- 复杂任务拆成垂直切片。
- 不提前实现用户没要求的能力。
- 不做无关重构。
## 4. 验证
优先运行以下验证:
- 类型检查
- 单元测试
- 集成测试
- lint
- 构建
- 本地启动
- 最小复现脚本
如果无法运行验证,必须说明原因,并给出用户可手动执行的命令。
## 5. 总结
最终回复包含:
- 本次使用的 skill
- 完成内容
- 修改文件
- 验证结果
- 风险点
- 后续建议
2.5 按照以下目录结构完善相关架构(保证后面相关skill的使用效果更稳定)
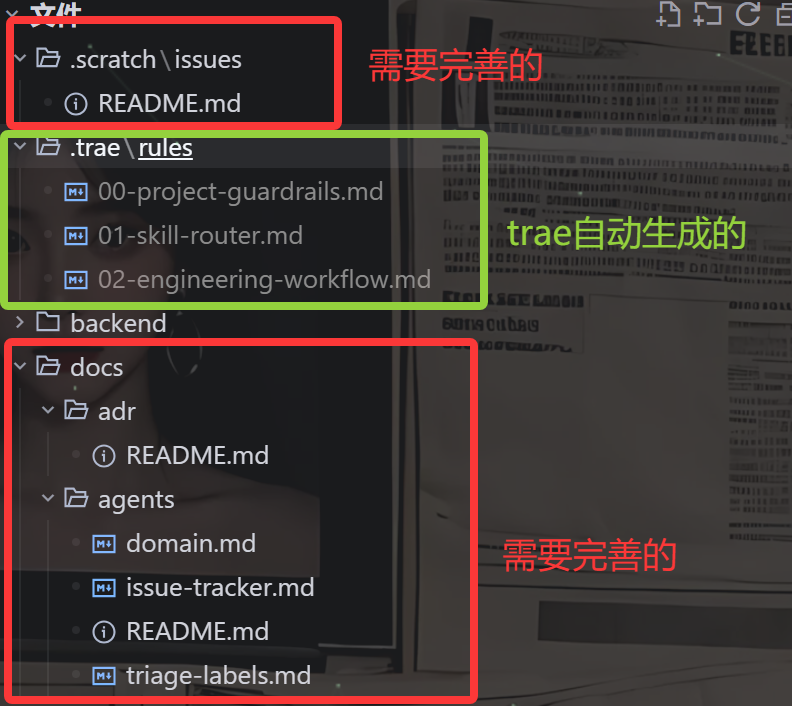
2.6 相关文档的用途和示例内容按照以下内容进行填写
.scratch\issues\README.md
# 本地 Issues
本目录用于存放当前项目的本地 Markdown issue。
这些 issue 主要供开发者和 AI Agent 使用,用于承接:
- PRD 拆分后的开发任务;
- Bug 修复任务;
- 技术债任务;
- 架构优化任务;
- 可交给 AI Agent 执行的独立任务。
## 使用原则
- 每个 issue 一个 Markdown 文件。
- 文件名建议使用日期 + 简短标题。
- 一个 issue 应该可以独立理解、独立执行、独立验证。
- 不要把长期业务上下文写在这里,长期上下文应写入 `CONTEXT.md`。
- 不要把架构决策写在这里,架构决策应写入 `docs/adr/`。
## 文件命名建议
文件名建议使用:
`YYYYMMDD-short-title.md`
示例:
`20260509-role-based-menu-permission.md`
## Issue 模板
复制下面模板创建新的 issue:
# 任务标题
## 类型
bug / enhancement / refactor / docs / chore
## 状态
needs-triage / needs-info / ready-for-agent / ready-for-human / wontfix
## 背景
TODO
## 目标
TODO
## 非目标
TODO
## 涉及范围
TODO
## 实现要点
TODO
## 验证方式
TODO
## 完成标准
TODO
## 风险与依赖
TODO
docs\adr\README.md
# ADR:架构决策记录
本目录用于记录当前项目中重要的架构决策。
ADR 是 Architecture Decision Record 的缩写,用来解释:
- 当时遇到了什么问题;
- 有哪些可选方案;
- 最终选择了什么方案;
- 为什么这样选择;
- 这个选择会带来什么影响。
## 什么时候需要创建 ADR
只有满足以下条件之一时,才建议创建 ADR:
- 这个决策未来修改成本较高;
- 这个决策会影响多个模块;
- 这个决策涉及技术选型;
- 这个决策涉及目录结构、模块边界、数据流、权限模型等核心设计;
- 如果不记录,未来维护者会困惑为什么这样设计。
## 什么时候不需要创建 ADR
以下内容不建议写成 ADR:
- 普通 Bug 修复;
- 临时排障过程;
- 一次性脚本;
- 简单 UI 调整;
- 纯实现细节;
- 尚未确认的想法。
## 文件命名建议
文件名建议使用:
`YYYYMMDD-short-title.md`
示例:
`20260509-use-role-based-menu-permission.md`
## ADR 模板
复制下面模板创建新的 ADR:
# ADR-YYYYMMDD:决策标题
## 状态
提议中 / 已接受 / 已废弃 / 已替代
## 背景
说明为什么需要做这个决策。
## 决策
说明最终选择了什么方案。
## 备选方案
### 方案 A
- 优点:
- 缺点:
### 方案 B
- 优点:
- 缺点:
## 影响
说明这个决策对代码结构、开发流程、部署、测试、维护的影响。
## 后续动作
- TODO
docs\agents\domain.md
# Domain Docs 配置
本文档用于说明当前项目的领域上下文文档结构。
AI 在使用 `grill-with-docs`、`tdd`、`diagnose`、`zoom-out`、`improve-codebase-architecture` 等技能时,应优先参考这里定义的上下文来源。
## 当前项目上下文模式
当前项目默认使用:
`单上下文模式`
主上下文文件:
`CONTEXT.md`
架构决策目录:
`docs/adr/`
## 文件职责
| 文件 / 目录 | 职责 |
|---|---|
| `CONTEXT.md` | 项目长期有效的业务术语、技术栈、核心流程、模块边界 |
| `docs/adr/` | 重要架构决策和技术取舍 |
| `docs/agents/` | AI Agent 工作流和任务管理约定 |
| `.scratch/issues/` | 本地任务池和待办 issue |
## CONTEXT.md 应该记录什么
适合记录:
- 项目一句话说明;
- 核心用户;
- 核心业务对象;
- 核心业务流程;
- 领域术语;
- 模块边界;
- 长期有效的项目约定;
- 已知限制。
不适合记录:
- 临时任务进展;
- 一次性排障过程;
- 尚未确认的猜测;
- 纯实现细节;
- 每次对话的中间过程。
## docs/adr/ 应该记录什么
适合记录:
- 重要技术选型;
- 架构边界调整;
- 模块拆分策略;
- 数据流设计;
- 权限模型设计;
- 未来难以回滚的决策。
不适合记录:
- 普通 Bug 修复;
- 小型 UI 调整;
- 一次性脚本;
- 临时测试方案。
## 多上下文模式
如果未来项目变成 monorepo 或多子系统项目,可以引入:
`CONTEXT-MAP.md`
`CONTEXT-MAP.md` 用于说明不同子系统应该读取哪个上下文文件。
示例:
- `apps/admin/` → `apps/admin/CONTEXT.md`
- `apps/mobile/` → `apps/mobile/CONTEXT.md`
- `packages/core/` → `packages/core/CONTEXT.md`
当前项目暂不启用多上下文模式。
docs\agents\issue-tracker.md
# Issue Tracker 配置
本文档用于说明当前项目的任务、需求、Bug、优化项应该如何被记录和管理。
AI 在使用 `to-prd`、`to-issues`、`triage` 等技能时,应优先参考本文档。
## 当前项目的 Issue 管理方式
当前项目默认使用:
`本地 Markdown Issue Tracker`
Issue 存放目录:
`.scratch/issues/`
## 适用场景
适合记录:
- 待开发功能;
- Bug 修复任务;
- 架构优化任务;
- 技术债任务;
- 从 PRD 拆分出的开发任务;
- AI Agent 可以独立执行的任务。
不适合记录:
- 长期业务上下文;
- 架构决策;
- 临时聊天记录;
- 一次性排障日志;
- 无需后续行动的想法。
## 文件命名建议
文件名建议使用:
`YYYYMMDD-short-title.md`
示例:
`20260509-role-based-menu-permission.md`
## Issue 内容模板
复制下面模板创建新的 issue:
# 任务标题
## 类型
bug / enhancement / chore / refactor / docs
## 状态
needs-triage / needs-info / ready-for-agent / ready-for-human / wontfix
## 背景
说明为什么需要做这个任务。
## 目标
说明这个任务完成后应该达到什么效果。
## 非目标
说明本次不做什么,避免范围膨胀。
## 涉及范围
- 文件:
- 模块:
- 接口:
- 页面:
## 实现要点
- TODO
## 验证方式
- TODO
## 完成标准
- TODO
## 风险与依赖
- TODO
docs\agents\README.md
# AI Agent 工作流配置说明
本目录用于记录当前项目中 AI Agent、Trae Skills、Matt Pocock Skills 相关的工程协作配置。
这些文档不是业务代码,也不是普通需求文档,而是告诉 AI 和开发者:
- 当前项目的任务如何管理;
- issue 状态如何流转;
- triage 标签如何使用;
- 项目上下文文档在哪里;
- AI 在执行任务时应该遵守哪些项目级约定。
## 目录文件说明
| 文件 | 用途 |
|---|---|
| `issue-tracker.md` | 说明当前项目的任务 / issue 写在哪里 |
| `triage-labels.md` | 说明任务分类和状态标签 |
| `domain.md` | 说明项目领域文档结构和上下文来源 |
## 使用原则
- 本目录记录 AI 工作流的项目级约定。
- 不记录具体业务需求。
- 不记录临时任务过程。
- 不存放正式代码。
- 如果规则发生变化,应同步更新相关文件。
docs\agents\triage-labels.md
# Triage Labels 配置
本文档用于说明当前项目中任务分类和任务状态的标准。
AI 在使用 `triage`、`to-issues` 等技能时,应优先参考本文档。
## 任务类型
| 标签 | 含义 |
|---|---|
| `bug` | 已有功能出现错误、异常、失败或行为不符合预期 |
| `enhancement` | 新功能、功能增强、体验优化或能力扩展 |
| `refactor` | 不改变外部行为的代码结构调整 |
| `docs` | 文档补充或说明更新 |
| `chore` | 工程配置、依赖、脚本、构建等维护任务 |
## 任务状态
| 标签 | 含义 |
|---|---|
| `needs-triage` | 需要先判断类型、优先级、范围和处理方式 |
| `needs-info` | 信息不足,需要用户或业务方补充 |
| `ready-for-agent` | 信息足够,AI Agent 可以开始执行 |
| `ready-for-human` | 需要人工处理、确认、授权或决策 |
| `wontfix` | 明确不处理,或暂不纳入当前范围 |
## 默认判断规则
### 标记为 `needs-info`
当任务缺少以下信息时:
- 目标不明确;
- 验收标准不明确;
- 复现步骤缺失;
- 业务规则不清楚;
- 涉及权限、数据、安全但没有明确边界。
### 标记为 `ready-for-agent`
当任务满足以下条件时:
- 目标明确;
- 范围清楚;
- 有可验证结果;
- 不需要访问敏感资源;
- 不需要人工业务判断;
- 不涉及高风险生产操作。
### 标记为 `ready-for-human`
当任务包含以下情况时:
- 需要业务方决策;
- 需要产品确认;
- 需要权限审批;
- 涉及生产环境;
- 涉及密钥、账号、资金、合同、法律等高风险事项。
## 使用原则
- 优先使用英文标签,保持和 Matt Pocock Skills 原始语义一致。
- 如果需要展示给中文团队,可以在说明中附中文解释。
- 不要随意新增标签,除非项目长期需要。
完成以上配置,即可开启你的快乐AI代码开发
有需要的粉丝可以私信我索要一键配置教程

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)