RAG-Lite、FTS5 与多 Agent 记忆互联,才是 Hermes 的长期解法

前面我们从病根讲到配置,从 Provider 选型讲到接入实战。
今天我们将最后一点内容说完。
我们前面说了,记忆不是把 MEMORY.md 写得更大。
也不是把所有聊天记录塞进一个向量库。
真正稳定的记忆系统,必须同时解决四个问题:
-
什么内容常驻。
-
什么内容检索。
-
什么内容归档。
-
什么内容必须被治理。
一句话:长期稳定不是靠模型记性,而是靠记忆分层和召回治理。
一、为什么单一记忆方案一定不够
只靠热记忆,会话一长就压缩。
只靠 MEMORY.md,容量太小。
只靠 FTS5,关键词不准就搜不到。
只靠向量库,语义相近但事实未必精确。
只靠 Provider,旧事实也可能污染新任务。
所以终局方案一定是混合的。
它应该长这样:
热记忆:当前任务连续性
温记忆:稳定规则和偏好
冷记忆:SQLite FTS5 历史会话
外挂记忆:语义检索 / 图谱 / 知识树
项目文档:硬规则与可审计事实
每层只干自己的事。
不要互相抢活。
二、RAG-Lite:先从轻量混合检索开始
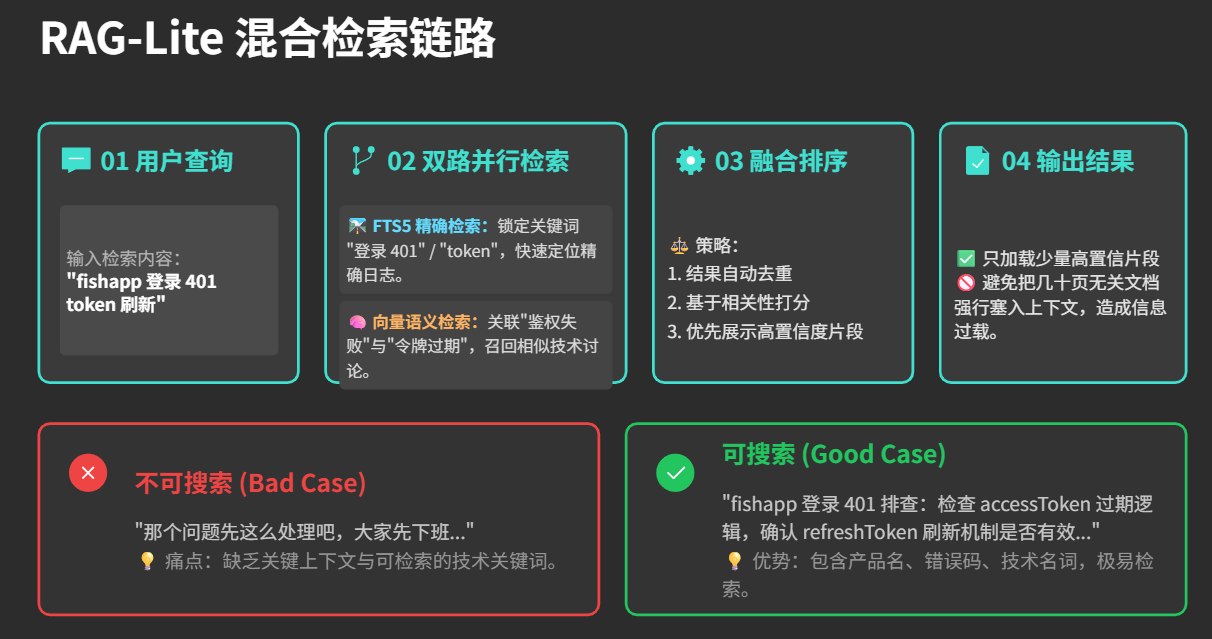
RAG-Lite 不是一个固定产品名。
这里说的是一种轻量思路:不一上来搞重型知识库,而是用 SQLite / FTS5 / 向量检索做一个够用的本地召回层。
核心是混合检索:
-
FTS5 擅长精确关键词。
-
向量检索擅长语义相似。
-
两者结合,比单一路径稳定。
例如:
关键词:fishapp 登录 401 token
语义:用户想找之前关于登录鉴权失败的排障记录
FTS5 可能找到精确日志。
向量检索可能找到相似讨论。
最后再让模型只读取少量高置信片段。
不要把几十页内容塞回上下文。
RAG 的关键不是“召回很多”,而是“少量准确”。
三、冷记忆要写得可搜索
如果你希望历史会话以后能搜回来,现在就要写得可搜索。
坏写法:
那个问题先这么处理吧。
好写法:
app 登录 401 的临时处理:先检查 accessToken 过期逻辑,再看 refreshToken 是否写入本地缓存。
关键词明确,未来才搜得到。
这也是为什么我建议在长任务结束前,让 Agent 输出交接摘要。
交接摘要不是给人看的仪式感。
它是给未来检索用的索引材料。
推荐格式:
## 任务交接摘要
- 项目:app
- 问题:登录接口 401
- 已查:token 写入、刷新逻辑、接口返回
- 结论:refreshToken 未持久化
- 下一步:运行登录回归测试
这样的内容,FTS5 和语义检索都更容易找回来。
四、多 Agent 场景:记忆必须分权
如果你有多个 Agent,比如:
-
main:总控
-
app:开发
-
article:写作
-
novel:小说
-
ppt:演示文稿
那记忆不能全部混在一起。
开发 Agent 不该长期读小说设定。
小说 Agent 也不该读 APP 调试日志。
写作 Agent 不该被代码项目里的临时错误污染。
企业场景更明显。
多 Agent 记忆治理至少要有四条规则:
-
按角色隔离记忆空间。
-
按项目隔离知识库。
-
共享稳定事实,不共享临时过程。
-
敏感内容必须有权限和审计。
五、企业版要关心审计,不只是召回率

个人用户关心:它能不能记住。
企业更关心:它记住了什么,谁能看,什么时候用过,错了怎么删。
所以企业记忆系统不能只看“准确率”。
还要看:
-
权限边界
-
数据隔离
-
写入审计
-
召回审计
-
删除与纠错机制
-
PII / API Key 防泄漏
-
多 Agent 的访问范围
如果没有这些,记忆越强,风险越大。
这也是为什么我不建议企业团队一上来就把所有会话丢进一个共享向量库。
你得到的可能不是智能,而是污染和泄漏。
六、推荐最终架构
个人版:
SOUL.md:短规则
USER.md:沟通偏好
MEMORY.md:稳定项目事实
session_search:历史会话找回
Holographic / ByteRover:本地长期记忆
项目 AGENTS.md:硬规则
团队版:
角色级 Profile:隔离 Agent 身份
项目级知识库:隔离业务上下文
Provider:负责长期语义记忆
SQLite / FTS5:负责精确历史检索
审计层:记录写入和召回
权限层:控制谁能读什么
企业版:
本地或私有化 Provider
RAG-Lite 混合检索
敏感信息扫描
写入审批
召回审计
多 Agent 权限矩阵
七、这套系列的最后结论
Hermes 的记忆问题,不该用“它怎么又忘了”来理解。
要换成一句话:
这条信息应该在哪一层被保存、检索、治理?
如果你能回答这个问题,Hermes 就不会再像一个越聊越乱的聊天机器人。
它会更像一个有工作台、有档案柜、有知识库、有权限边界的 Agent 系统。
这才是长期解法。
所以这个系列的最终建议是:
-
先分清四层记忆。
-
再清理温记忆。
-
调整压缩和工具加载。
-
接入一个外部 Provider。
-
用 FTS5 + RAG-Lite + 权限治理做长期稳定。
不要追求“让模型记住一切”。
真正专业的做法,是让它只记该记的,只查该查的,只在该用的时候用。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)