从 Chain 到 Graph:LangGraph 核心架构解析
·
从 Chain 到 Graph:LangGraph 核心架构解析
一句话总结:当你的 Agent 逻辑复杂度越过临界点,从 Chain 到 Graph 的演进就不再是"要不要用"的可选题,而是"不得不做"的必答题。
一、从 Chain 到 Graph:为什么必须演进?
1.1 Chain 的本质与局限
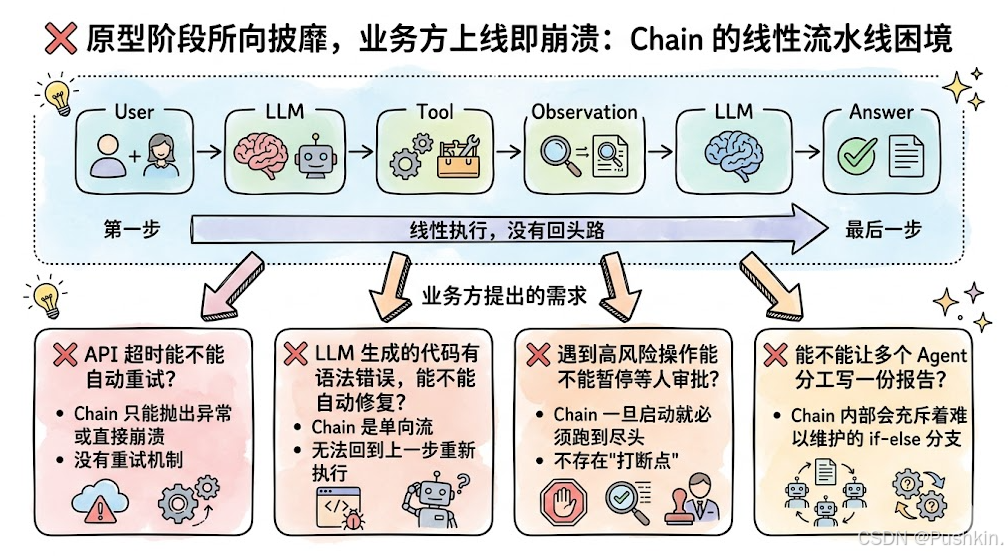
核心问题:Chain 假设的是一个理想化的、一路绿灯的乌托邦。而真实商业世界充满报错、异常与复杂规则。
1.2 演进的必然性
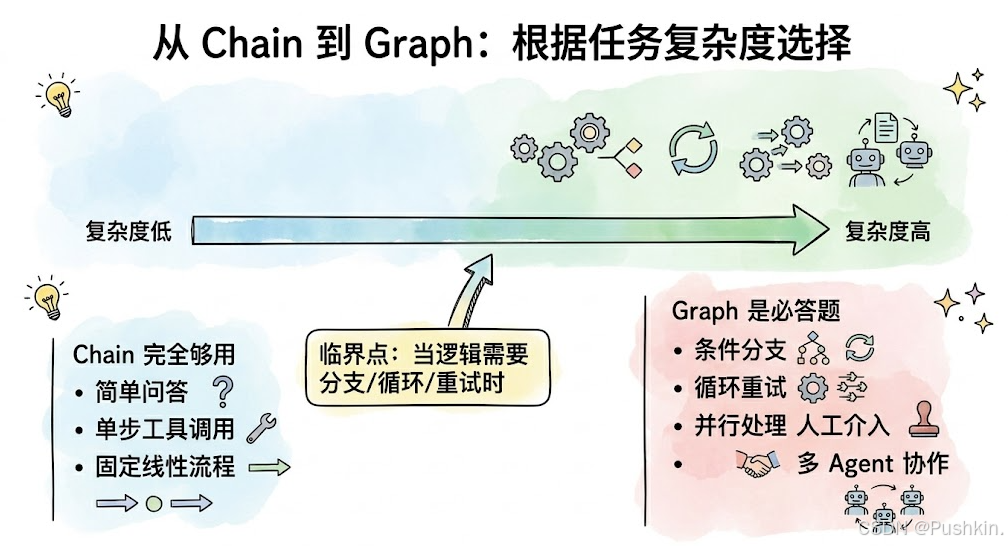
结论:从 Chain 到 Graph 不是 API 调用的更替,而是AI 工程化思维的一次跃迁。
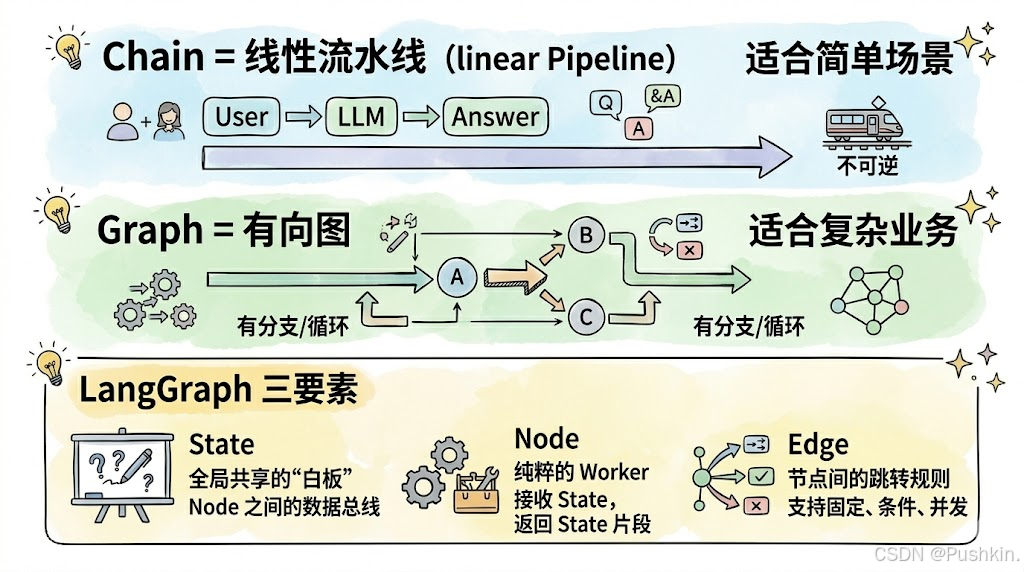
二、Graph 的核心概念:State / Node / Edge
LangGraph 强制你抛弃"一步步往下走"的思维,转而在一个"图"中声明业务逻辑。图的三个核心概念: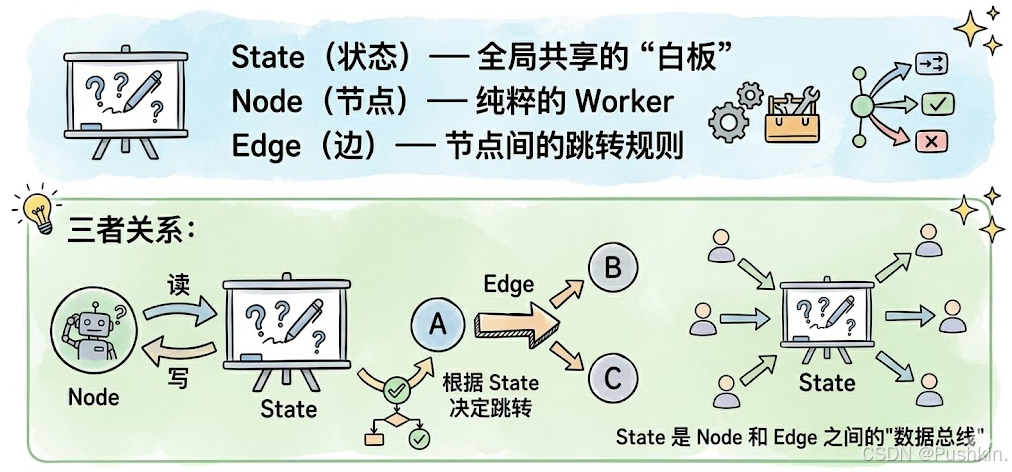
2.1 State:全局共享的"白板"
State 是 LangGraph 的数据总线。所有 Node 通过读写 State 来协作,Node 之间不直接通信。
State 的定义
from typing import Annotated, List, TypedDict
import operator
class AgentState(TypedDict):
messages: Annotated[List[dict], operator.add]
# ↑ 列表字段,使用 operator.add 作为 Reducer(追加而非覆盖)
current_step: str
# ↑ 普通字段,新值直接覆盖旧值
retry_count: int
# ↑ 普通字段,用于控制重试次数
Reducer:State 更新的核心机制
问题场景:两个并行 Node 同时修改 State,直接赋值会相互覆盖。
# 场景:两个并行 Node 同时向 messages 追加内容
# Node A 返回: {"messages": [msg_a]}
# Node B 返回: {"messages": [msg_b]}
# ❌ 没有 Reducer(覆盖):
# 最终 messages = [msg_b] ← msg_a 丢失!
# ✅ 有 Reducer(追加):
# messages: Annotated[List[dict], operator.add]
# 最终 messages = [msg_a, msg_b] ← 两者都保留
常用 Reducer:
import operator
# 列表追加
messages: Annotated[List[dict], operator.add]
# 字典合并(自定义 Reducer)
def merge_dict(left: dict, right: dict) -> dict:
return {**left, **right}
data: Annotated[dict, merge_dict]
# 取最新值(默认行为,不需要 Annotated)
status: str # 新值直接覆盖旧值
工程最佳实践
# ✅ 推荐:用 Pydantic 做运行时校验
from pydantic import BaseModel, Field
class Message(BaseModel):
role: str = Field(pattern="^(user|assistant|tool)$")
content: str
tool_call_id: str | None = None
class AgentState(TypedDict):
messages: Annotated[List[Message], operator.add]
# ❌ 不推荐:裸 dict,下游节点拿到脏数据直接崩溃
class BadState(TypedDict):
messages: List[dict] # 没有任何校验
2.2 Node:纯粹的 Worker
一个 Node 就是一个纯函数:接收当前 State,返回需要更新的 State 片段。
Node 的本质
def call_llm_node(state: AgentState):
"""单纯的 LLM 调用节点"""
messages = state["messages"]
response = llm.invoke(messages)
return {"messages": [response]} # 只返回需要更新的字段
关键原则:
- Node 之间不直接通信,全部通过 State 间接协作
- Node 返回的字典只包含需要更新的字段,未提及的字段保持不变
- 每个 Node 只做一件事,保持职责单一
Command:节点内自治路由
Node 可以直接返回 Command,把"状态更新"和"下一步去向"捆绑在一起:
from langgraph.types import Command
def supervisor_node(state: AgentState) -> Command:
"""主管节点:根据分析结果决定下一步"""
decision = llm.invoke(state["messages"])
if "需要查数据库" in decision.content:
return Command(
goto="database_tool",
update={"current_step": "querying"}
)
elif "需要计算" in decision.content:
return Command(
goto="calculator",
update={"current_step": "calculating"}
)
else:
return Command(goto=END)
Command 的优势:
- 节点内聚性更强:路由逻辑和节点逻辑写在一起
- 减少 Graph 配置:不需要在外面写
addConditionalEdges - 更灵活:可以根据运行时状态动态决定去向
2.3 Edge:节点间的跳转规则
Edge 定义了 Node 之间的流转方式,有三种类型:
固定边
builder.add_edge("node_a", "node_b")
# A 做完一定走 B,无条件跳转
条件边
def quality_check(state: TranslationState):
"""根据质量决定下一步"""
if state["quality"] == "pass":
return "end"
if state.get("revision_count", 0) >= 3:
return "end"
return "translate" # 打回重译
builder.add_conditional_edges("review", quality_check, {
"translate": "translate",
"end": END
})
Send:动态并发
from langgraph.types import Send
def split_document(state: DocumentState):
"""将文档切片,动态创建并行任务"""
chunks = split_text(state["content"], chunk_size=5000)
return [Send("summarize_chunk", {"chunk": chunk}) for chunk in chunks]
# 框架自动并发执行所有 Send 任务,然后收集结果
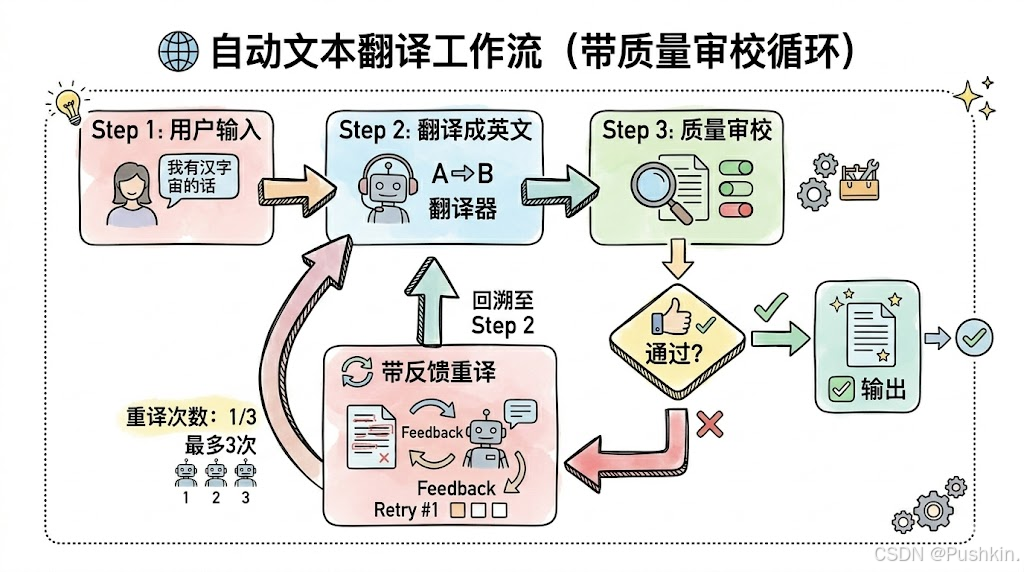
三、实战:自修复翻译审校 Agent
3.1 需求
3.2 完整实现
from typing import Annotated, TypedDict, Literal
import operator
import json
from langgraph.graph import StateGraph, START, END
from langchain_openai import ChatOpenAI
# ─── 1. 定义 State ───
class TranslationState(TypedDict):
original_text: str
translated_text: str
review_feedback: str
revision_count: Annotated[int, operator.add]
quality: Literal["pass", "fail", "pending"]
llm = ChatOpenAI(model="gpt-4o", temperature=0.3)
# ─── 2. 定义 Nodes ───
def translate_node(state: TranslationState):
"""翻译节点"""
is_revision = state.get("revision_count", 0) > 0
if is_revision:
prompt = (
f"根据反馈改进翻译。\n"
f"原文:{state['original_text']}\n"
f"上次译文:{state['translated_text']}\n"
f"反馈:{state['review_feedback']}"
)
else:
prompt = f"将以下中文翻译为英文:{state['original_text']}"
response = llm.invoke(prompt)
return {
"translated_text": response.content,
"revision_count": 1 # Reducer 累加 +1
}
def review_node(state: TranslationState):
"""审校节点"""
prompt = (
f"评估翻译质量。\n"
f"原文:{state['original_text']}\n"
f"译文:{state['translated_text']}\n\n"
f"严格按 JSON 格式输出:\n"
f'{{"quality": "pass/fail", "feedback": "修改建议"}}'
)
response = llm.invoke(prompt)
try:
result = json.loads(response.content)
return {
"quality": result["quality"],
"review_feedback": result["feedback"]
}
except json.JSONDecodeError:
return {"quality": "pass", "review_feedback": "解析失败,强制通过"}
# ─── 3. 定义路由逻辑 ───
def quality_check(state: TranslationState):
if state["quality"] == "pass":
return "end"
if state.get("revision_count", 0) >= 3:
return "end"
return "translate"
# ─── 4. 组装 Graph ───
builder = StateGraph(TranslationState)
builder.add_node("translate", translate_node)
builder.add_node("review", review_node)
builder.add_edge(START, "translate")
builder.add_edge("translate", "review")
builder.add_conditional_edges("review", quality_check, {
"translate": "translate",
"end": END
})
graph = builder.compile()
# ─── 5. 运行 ───
result = graph.invoke({
"original_text": "微前端架构通过 Module Federation 实现了运行时模块共享。",
"translated_text": "",
"review_feedback": "",
"revision_count": 0,
"quality": "pending"
})
print(f"最终译文:{result['translated_text']}")
print(f"重试次数:{result['revision_count']}")
3.3 执行流程
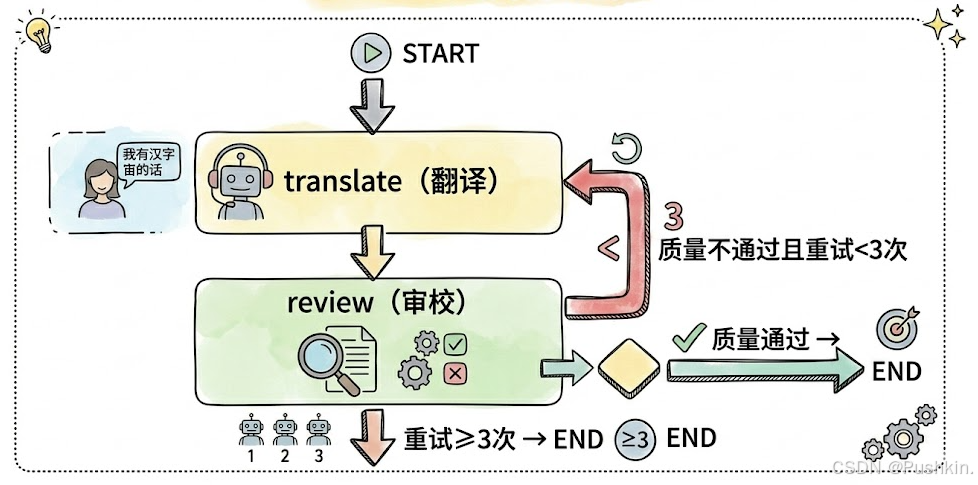
这个案例展示了 Graph 的三大核心:
- State:
TranslationState作为数据总线,所有 Node 通过它协作 - Node:
translate_node和review_node各司其职 - Edge:
quality_check条件边实现循环重试逻辑
四、核心概念对比:Chain vs Graph
| 维度 | Chain | Graph |
|---|---|---|
| 控制流 | 线性、固定 | 图结构、动态 |
| 状态管理 | 隐式、分散 | 显式、集中(State) |
| 容错 | 无,出错即崩溃 | 支持重试、回退、分支 |
| 并发 | 不支持 | 支持 Send 动态并发 |
| 人工介入 | 不支持 | 支持 interrupt + resume |
| 可调试性 | 差,黑盒执行 | 好,每步状态可追溯 |
| 适用场景 | 简单问答、单步调用 | 复杂业务、多步推理 |
五、总结
核心认知
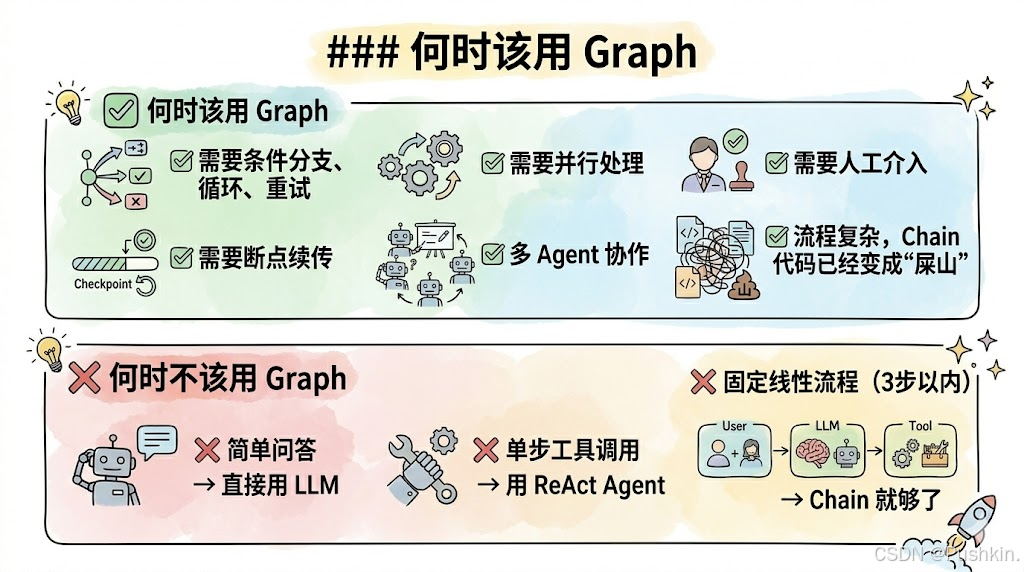
何时该用 Graph
参考:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 12
12 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)