ReAct 架构深度解析:让大模型学会“边想边做“
文章目录
ReAct 架构深度解析:让大模型学会"边想边做"
核心观点:ReAct 不是某种复杂的神经网络魔法,而是一种极其朴素的认知外包策略——把逻辑推理交给 LLM,把具体执行交给外部工具,两者通过简单的文本交互交替进行。理解这一点,你就理解了现代 AI Agent 的底层逻辑。
一、问题的根源:LLM 的"闭关锁国"
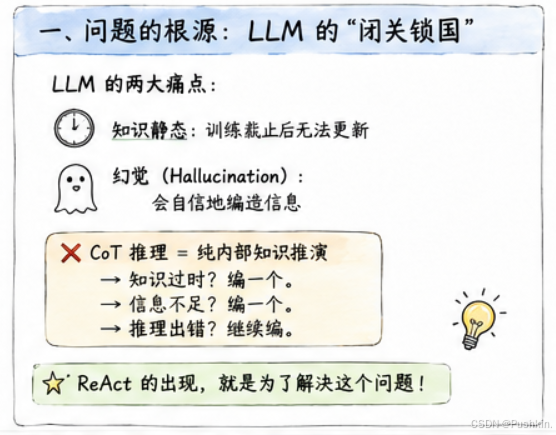
大语言模型本质上是一个静态的知识压缩包。它的训练数据截止于某个时间点,之后发生的事它一无所知。更致命的是,它有一个根深蒂固的毛病——幻觉(Hallucination)。
你问它:“阿根廷现任总统的夫人是哪里人?“它可能连眼都不眨就给你编一个名字。不是它想骗你,而是它的训练目标就是"预测下一个最可能的词”,而不是"说真话”。
这就是传统 Chain-of-Thought(CoT)推理的致命缺陷:
❌ CoT 推理 = 纯内部知识推演
→ 知识过时?编一个。
→ 信息不足?编一个。
→ 推理出错?继续编。
ReAct 的出现,就是为了解决这个问题。
二、ReAct 的本质:推理与行动的交响
2.1 论文中的原始定义
ReAct(Reasoning + Acting)由普林斯顿大学和 Google Research 在 ICLR 2023 上提出。论文的核心洞察是:
人类的智能有一个独特特征:能够无缝地将目标导向的行动与语言推理(或内心独白)结合起来。
做饭的时候,你切完菜会想:“现在该热锅了”(推理),然后去开火(行动)。发现没盐了,你会想:“用酱油代替吧”(推理调整),然后去拿酱油(行动调整)。
推理帮助你制定计划、处理异常、更新知识;行动让你从外部世界获取新信息。 两者的紧密协同,才是人类快速学习新任务、在不确定环境下做出稳健决策的关键。
2.2 核心循环:Thought → Action → Observation
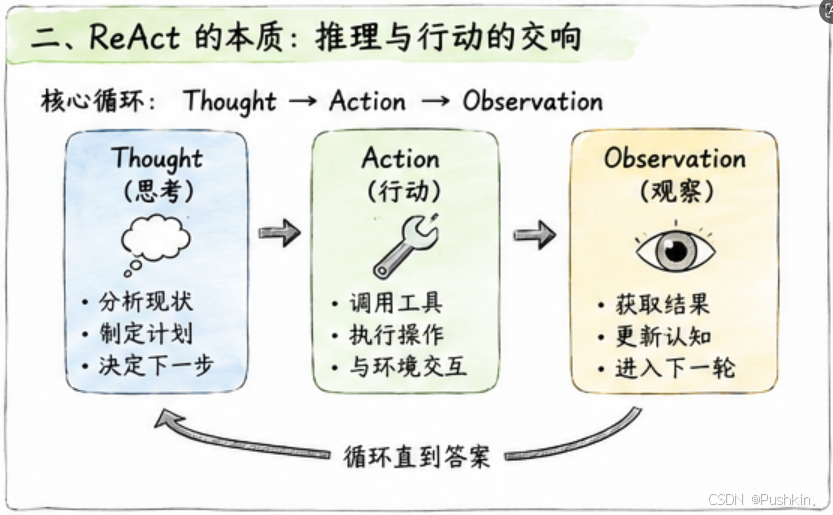
关键理解:Thought 不改变外部环境,它只是模型内部的"内心独白"。Action 才会真正与环境交互,产生 Observation。Observation 又成为下一轮 Thought 的输入。
2.3 一个真实的例子
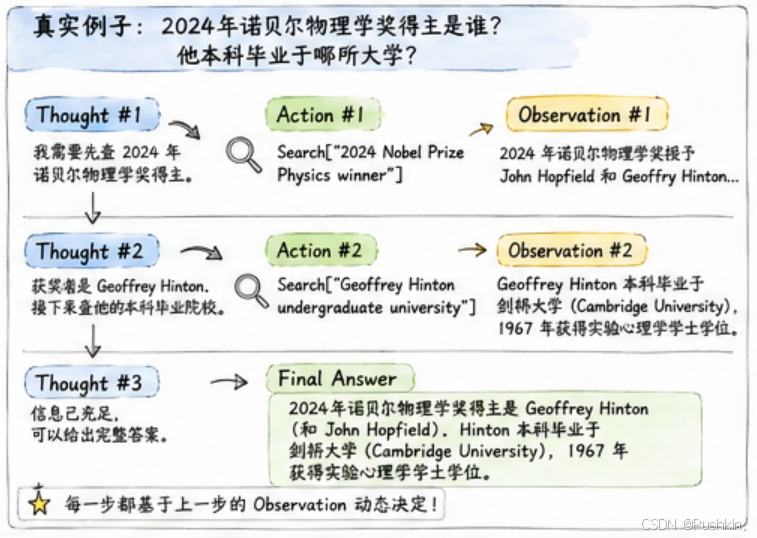
用户问题:2024年诺贝尔物理学奖得主是谁?他本科毕业于哪所大学?
Thought #1: 我需要先查2024年诺贝尔物理学奖得主。
Action #1: Search["2024 Nobel Prize Physics winner"]
Observation #1: 2024年诺贝尔物理学奖授予John Hopfield和Geoffrey Hinton...
Thought #2: 获奖者是 Geoffrey Hinton。接下来需要查他的本科毕业院校。
Action #2: Search["Geoffrey Hinton undergraduate university"]
Observation #2: Geoffrey Hinton earned his bachelor's degree in experimental psychology from Cambridge University in 1967.
Thought #3: 信息已经充足,可以给出完整答案。
Final Answer: 2024年诺贝尔物理学奖得主是 Geoffrey Hinton(和 John Hopfield)。
Hinton 本科毕业于剑桥大学(Cambridge University),1967年获得实验心理学学士学位。
注意:模型不是一开始就知道要查两次的。每一步都是基于上一步的 Observation 动态决定的。这就是 ReAct 的灵魂——动态的、自适应的多步推理。
三、为什么 ReAct 有效?认知科学视角
3.1 工作记忆扩展
认知科学中的工作记忆(Working Memory)理论认为,人类的推理能力受限于工作记忆的容量。ReAct 通过外部化工具调用,实际上扩展了模型的"工作记忆":
| 维度 | 纯 LLM(CoT) | ReAct |
|---|---|---|
| 知识来源 | 仅内部训练数据 | 内部知识 + 外部工具 |
| 信息更新 | 不可能(训练截止后无法更新) | 实时获取新信息 |
| 错误纠正 | 错误会传播(错一步,步步错) | 每一步都可以基于 Observation 纠正 |
| 可解释性 | 推理过程是黑盒 | Thought 轨迹人类可读 |
3.2 论文中的实验证据
论文在四个基准任务上验证了 ReAct 的效果:
| 任务 | 类型 | ReAct 提升 |
|---|---|---|
| HotpotQA | 多跳问答 | 超越纯 CoT,减少幻觉 |
| FEVER | 事实验证 | 超越纯行动生成 |
| ALFWorld | 文本游戏 | 超越 RL 方法 34% |
| WebShop | 网页导航 | 超越 RL 方法 10% |
关键发现:
- 推理密集型任务(如 QA):需要密集的 Thought-Action 交替(每步都有 Thought)
- 决策密集型任务(如游戏):Thought 可以稀疏出现,模型自主决定何时推理
四、从论文到生产:现代 ReAct 实现的演进
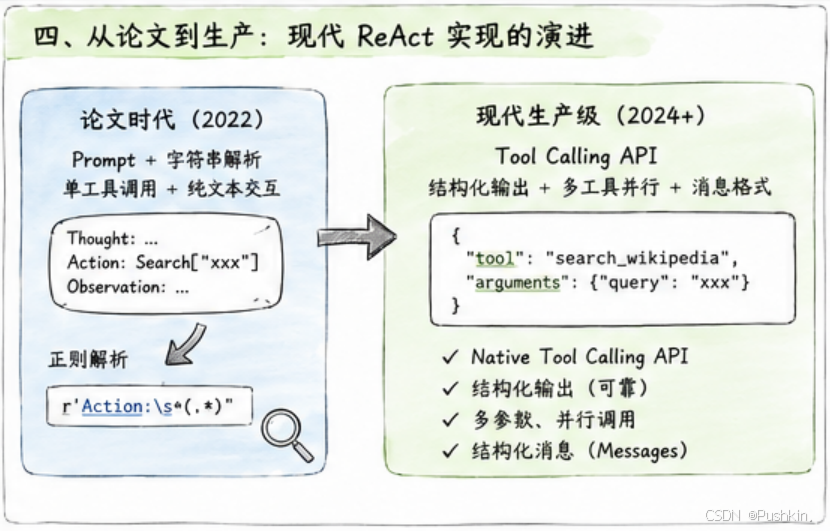
4.1 论文时代的实现(2022)
Prompt + 字符串解析 + 单工具调用 + 纯文本交互
论文中的实现方式:
- 通过 Prompt 让模型输出 “Thought: … Action: … Observation: …” 格式的文本
- 用正则表达式解析模型输出,提取 Action
- 一次只能调用一个工具
- 所有输入输出都是纯字符串
4.2 现代生产级实现(2024+)
Tool Calling API + 结构化输出 + 多工具并行 + 消息格式
现代实现的关键改进(以 LangGraph 为例):
| 维度 | 论文时代 | 现代实现 |
|---|---|---|
| 工具调用 | Prompt + 正则解析 | Native Tool Calling API |
| 交互格式 | 纯字符串 | 结构化消息(Messages) |
| 工具参数 | 单个字符串 | 多参数、结构化输入 |
| 并行调用 | 不支持 | 支持多工具并行调用 |
| Thought 生成 | 必须显式生成 | 可选(模型足够好时可省略) |
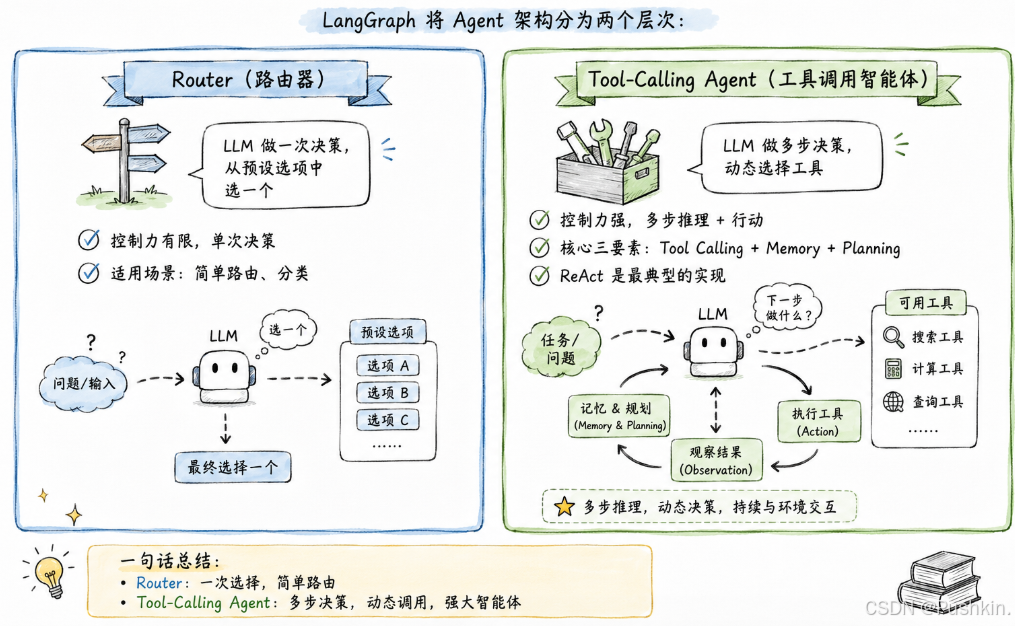
4.2 架构对比:Router vs Tool-Calling Agent
LangGraph 将 Agent 架构分为两个层次:
五、代码实现:从玩具到生产
5.1 本质:一个 while 循环
抛开所有框架,ReAct 的底层逻辑就是一个简单的循环:
def react_loop(user_input, tools, llm):
"""ReAct 的本质:一个带有中断机制的 while 循环"""
history = [{"role": "user", "content": user_input}]
while True:
# 1. LLM 思考:基于历史决定下一步
response = llm.chat(history)
# 2. 如果不需要工具,直接回答
if not response.needs_tool:
return response.content
# 3. 调用工具,获取观察结果
for tool_call in response.tool_calls:
result = execute_tool(tool_call.name, tool_call.args)
history.append({"role": "observation", "content": result})
就这?对,就这。 所有 Agent 框架的底层都逃不出这个逻辑。
5.2 生产级实现:LangGraph
from langchain_openai import ChatOpenAI
from langchain_core.tools import tool
from langgraph.prebuilt import create_react_agent
# 1. 定义工具
@tool
def search_wikipedia(query: str) -> str:
"""搜索维基百科获取信息"""
# 实际实现中调用 Wikipedia API
...
@tool
def calculate(expression: str) -> str:
"""计算数学表达式"""
return str(eval(expression))
# 2. 初始化模型
model = ChatOpenAI(model="gpt-4o", temperature=0)
# 3. 创建 ReAct Agent
agent = create_react_agent(model, [search_wikipedia, calculate])
# 4. 运行
result = agent.invoke({
"messages": [("user", "2024年诺贝尔物理学奖得主是谁?他本科毕业于哪所大学?")]
})
5.3 核心三要素详解
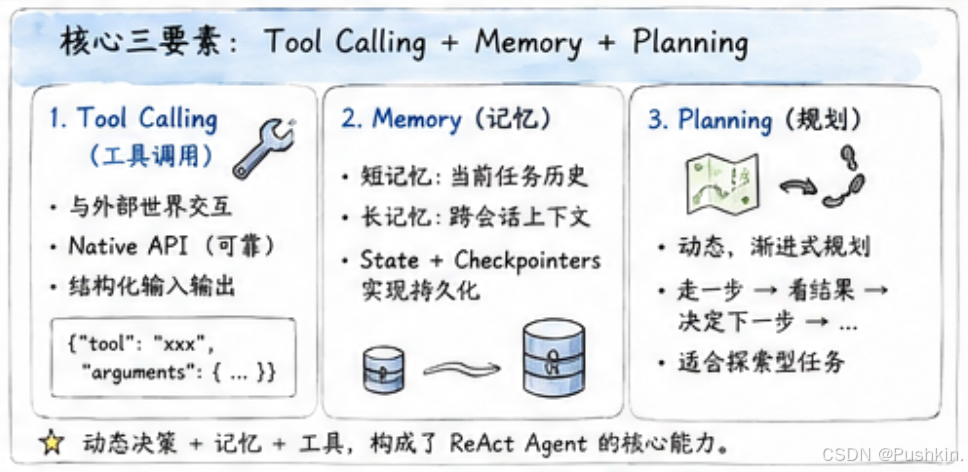
Tool Calling(工具调用)
工具是 Agent 与外部世界交互的唯一通道。现代 Tool Calling 的优势:
# 旧方式:Prompt + 解析(不可靠)
"Thought: 我需要搜索...\nAction: Search[query='xxx']"
# 需要用正则解析,容易出错
# 新方式:Native Tool Calling(可靠)
# 模型直接返回结构化调用:
{
"tool": "search_wikipedia",
"arguments": {"query": "2024 Nobel Prize Physics"}
}
Memory(记忆)
Agent 需要记住之前的步骤,才能做出连贯的推理:
短记忆:当前任务中,前面几步做了什么
长记忆:跨会话,用户的历史偏好和上下文
LangGraph 通过 State + Checkpointers 实现:
State:定义记忆的结构Checkpointers:持久化状态,支持跨会话恢复
Planning(规划)
ReAct 的规划是动态的、渐进式的:
不是:先制定完整计划 → 严格执行
而是:走一步 → 看结果 → 决定下一步 → 看结果 → ...
这适合探索型任务(你不知道需要几步),但不适合执行型任务(计划明确,只需执行)。
六、ReAct 的局限与进阶架构
6.1 ReAct 的三大局限
| 局限 | 原因 | 影响 |
|---|---|---|
| 死循环 | 模型陷入"查了又查"的循环 | Token 消耗无限增长 |
| 上下文膨胀 | 每轮的 Thought/Action/Observation 都堆积在 Context 中 | 推理变慢、可能超限 |
| 缺乏全局规划 | 每步只看当前,没有整体计划 | 复杂任务效率低 |
6.2 进阶架构对比
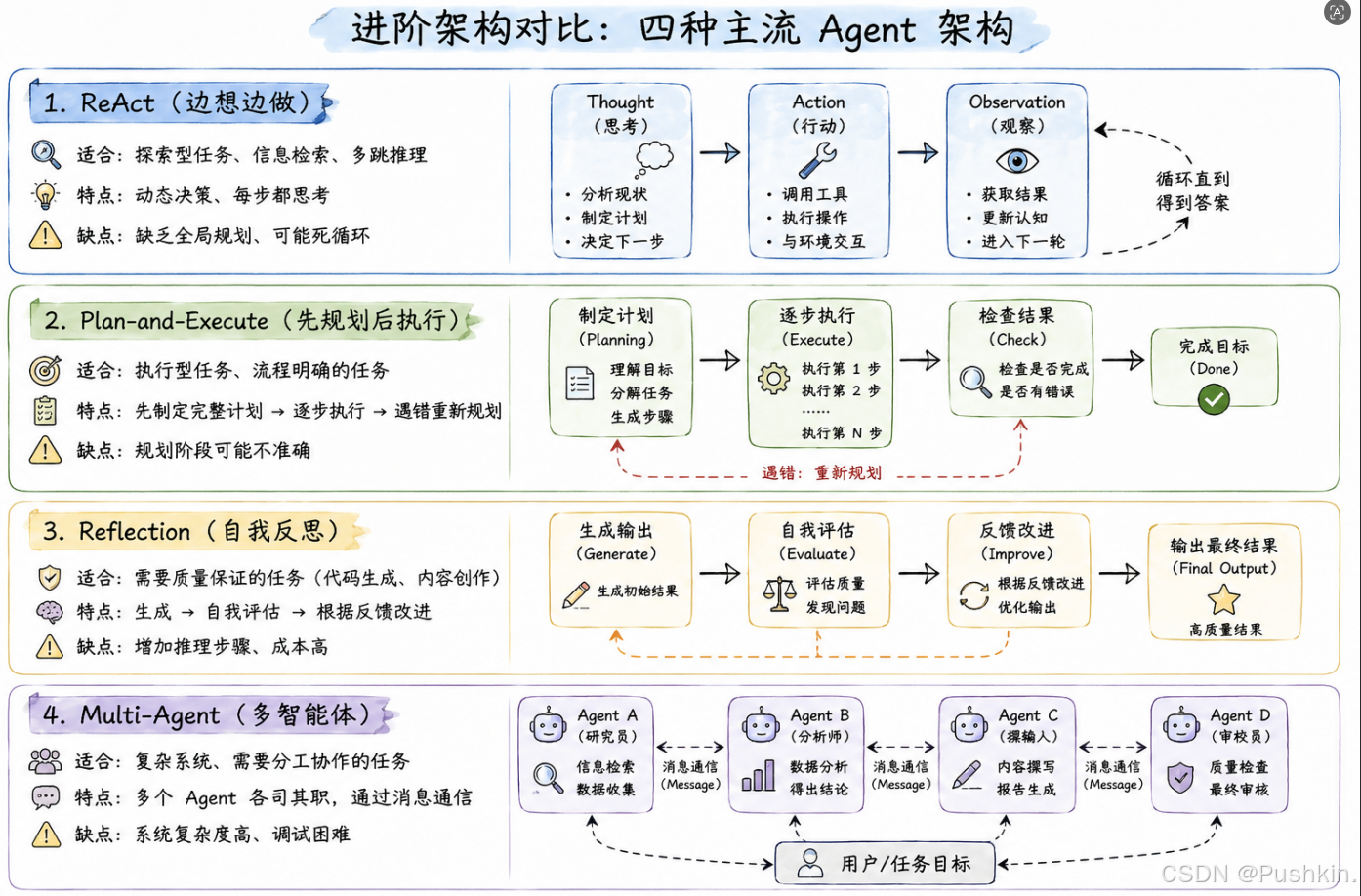
6.3 实战选择指南
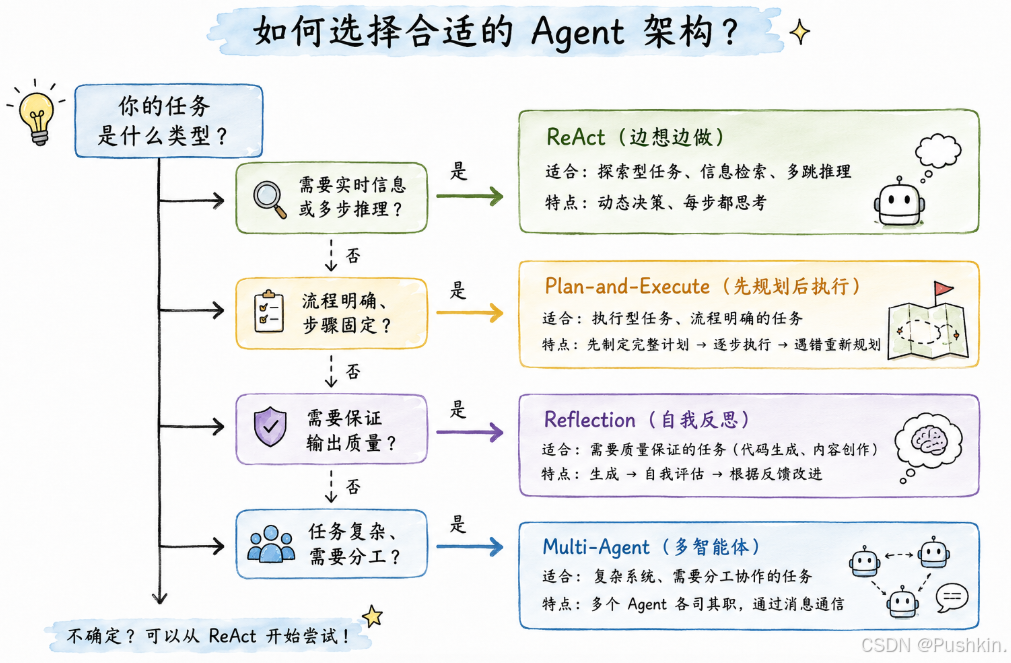
七、实战避坑指南
7.1 死循环防护
# ❌ 危险:无限循环
while True:
response = llm.chat(history)
...
# ✅ 安全:设置最大迭代次数
MAX_ITERATIONS = 10
for _ in range(MAX_ITERATIONS):
response = llm.chat(history)
if not response.needs_tool:
return response.content
# 超过最大次数仍未完成,返回当前最佳结果或报错
LangGraph 中通过 recursion_limit 配置:
config = {"configurable": {"recursion_limit": 25}}
result = agent.invoke(inputs, config=config)
7.2 上下文管理
# 策略1:滑动窗口(保留最近 N 轮)
def trim_history(history, max_rounds=5):
if len(history) > max_rounds * 3: # 每轮3条消息
return history[-(max_rounds * 3):]
return history
# 策略2:定期总结(压缩中间过程)
def summarize_progress(history):
# 让 LLM 把前面的进展浓缩成一段话
summary_prompt = "请总结目前的进展和已获取的关键信息..."
return llm.chat(summary_prompt)
7.3 工具设计原则
好的工具设计:
✅ 单一职责:一个工具只做一件事
✅ 明确描述:Tool 的 description 要清晰,帮助 LLM 判断何时调用
✅ 结构化输入:参数类型明确,避免歧义
✅ 容错处理:工具失败时返回有意义的错误信息
差的工具设计:
❌ 一个工具做太多事(LLM 不知道该传什么参数)
❌ 描述模糊(LLM 无法判断何时调用)
❌ 返回信息不透明(LLM 看不懂结果)
八、总结
核心公式
ReAct = Thought(推理) + Action(行动) + Observation(观察)
= 一个带有中断机制的 while 循环
= 认知外包:推理交给 LLM,执行交给工具
关键认知
- ReAct 不是魔法,是策略:它不改变模型本身,只是改变了模型与外部世界的交互方式。
- 动态 vs 静态:CoT 是静态推理(一口气想到底),ReAct 是动态推理(走一步看一步)。
- 可解释性是巨大优势:Thought 轨迹让人类能理解模型的决策过程,这在生产环境中至关重要。
- 现代实现已大幅进化:从 Prompt+解析 到 Native Tool Calling,从单工具到多工具并行,从纯文本到结构化消息。
下一步
ReAct 是现代 AI Agent 的基石,但并非终点。在实际生产中,你往往需要:
- Reflection:让 Agent 自我检查,提升输出质量
- Planning:让 Agent 先制定计划再执行,提升复杂任务效率
- Multi-Agent:多个 Agent 分工协作,处理更复杂的系统
理解 ReAct,你就理解了 Agent 的"Hello World"。从这里出发,你可以构建出越来越强大的智能系统。
参考:
- ReAct: Synergizing Reasoning and Acting in Language Models (Yao et al., ICLR 2023)
- LangGraph Agent Concepts
- What is an Agent?

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)