你的 Kafka 该怎么办?一份选型决策指南 | 流湖之变(三)
本文是「边界层笔记 · AI+数据平台」系列文章,「流湖之变」专题的收官篇。前两篇我们拆了Kafka 正在被三个方向同时挑战和当 AI 成为流数据的买家。今天回到你的办公室——手上的 Kafka 集群该怎么处理,新项目该选谁。

回到现实
技术路线分析可以很优雅,但企业 CTO 和数据架构师面对的不是白纸——是几十个 Kafka 集群、上百个 consumer、几个年薪百万的 Kafka 团队,以及一个正在催 AI 能力上线的业务部门。
三条路线都有道理,但你的牌该怎么打?
存量 Kafka:不是「要不要迁」,是「迁什么」
一个现实:全球 Kafka 集群的存量规模是天文数字。LinkedIn 单集群日处理 7 万亿条消息。任何「把 Kafka 撕掉重建」的方案,在企业级场景下都不现实。
真正的决策是按场景分层:

核心消息总线——短期不动。 高吞吐、低延迟(<50ms)、上下游 producer/consumer 庞大,深度集成 Kafka Connect 和 Schema Registry——这是 Kafka 的核心护城河。等 Lakestream 经过 12-18 个月生产验证后再评估。AI 管道从下游湖表取数据,不直接消费消息总线,暂不影响。
日志/事件采集——优先改造。 高吞吐但延迟容忍度高(秒到分钟级),数据最终流入数据湖做分析。这是路线 B(Lakestream)和路线 A(Flink+Paimon)最有价值的切入点:副本复制成本占比最高,延迟又不敏感。改造后流数据即湖表,AI 实时特征延迟从小时级降至秒级。
CDC / 数据同步——观望。 Flink CDC 已经是不依赖 Kafka 的成熟替代(直读 binlog → 直写湖表),但切换需要管道改造。现有管道稳定的不建议主动迁。中期看,CDC 直写湖表意味着 AI 能更快看到数据变更。
流计算管道——逐步迁移。 引入 Paimon/Fluss 作为中间存储,让 Flink 直接读写湖表,Kafka 的角色从"必经之路"变为"可选入口"。这是核心收益场景:Flink 流式湖表 = 实时 Feature Store,直接消除 Training-Serving Skew。
一句话:核心消息总线不动,日志采集优先改造,流计算管道逐步迁移。
如果选路线 B:UFK 迁移路径
对于已有大规模 Kafka 集群、不想重构整个管道的企业,路线 B 提供了一条渐进式迁移路径。UFK 的 Universal Linking 功能支持从现有 Kafka 部署(Confluent、MSK、Redpanda、自建)向 UFK 持续复制数据,不需要改动 producer/consumer 代码。
迁移可以分三步走:
Phase 1 日志采集先行——延迟容忍度高、成本占比大,改造收益最明显;
Phase 2 流计算管道跟进——让 Flink/Spark 消费 UFK 的湖表接口,流数据直接可查询;
Phase 3 评估核心消息总线——等 UFK 有了 12-18 个月的生产验证和大型客户案例后,再决定核心总线是否迁移。
Universal Linking 的价值在于:迁移期间新旧集群共存,业务不中断。这是路线 B 区别于路线 A 的关键落地优势——不需要「推翻重建」,而是「逐层替换」。
新项目:2026 年还要不要默认选 Kafka?
对于从零开始的新项目,没有历史包袱的约束,选型逻辑完全不同。
传统架构中,「需要流数据 → 先搭一套 Kafka」几乎是条件反射。但 2026 年的技术现实是:
-
Kafka 解决的问题在被更简洁的方案覆盖。 Flink + Paimon 一层搞定过去需要 Kafka + ETL + 湖表三层才能搞定的事。
-
Kafka 运维成本不低。 即使是托管 Kafka,跨 AZ 副本复制、分区再平衡仍然是实打实的成本。
-
如果你的业务路线图上有 AI,这个选型决定了你未来 AI 系统的天花板。
一棵决策树
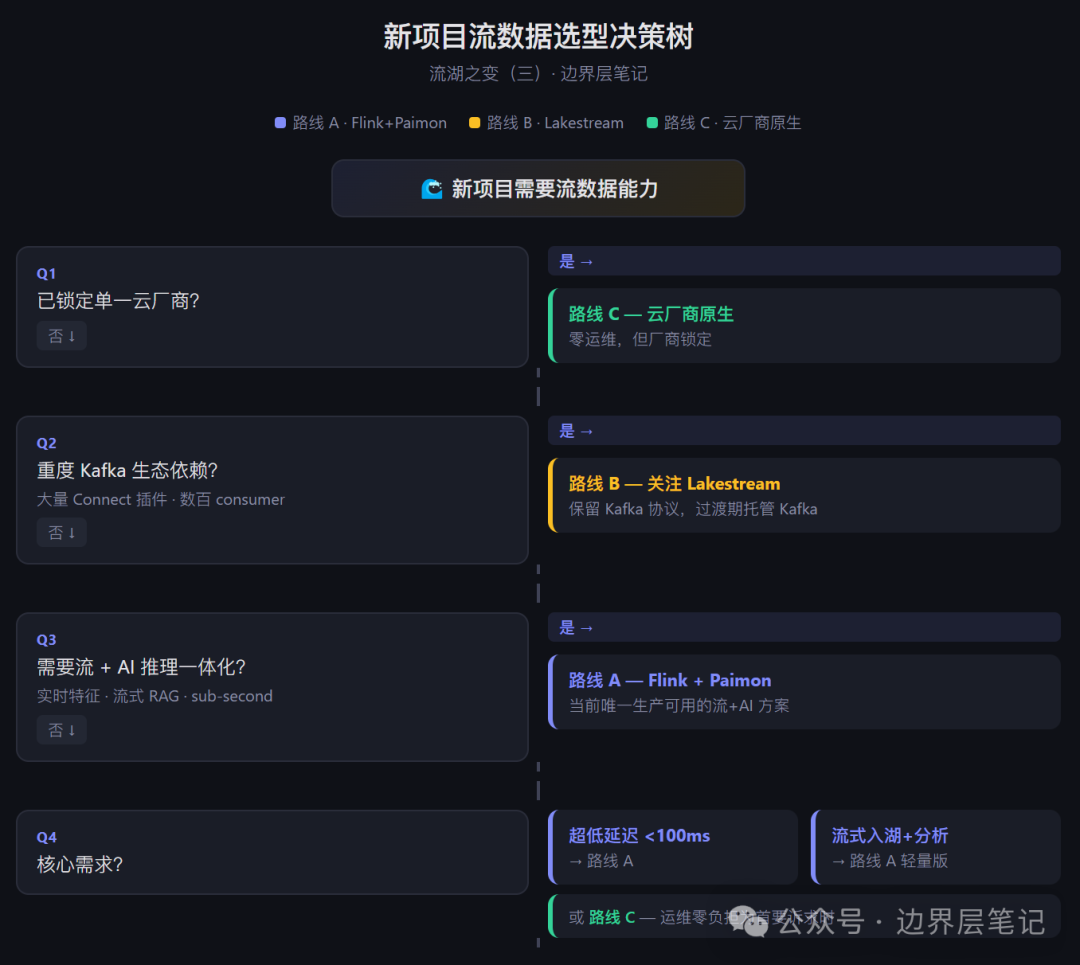
三条路线新项目对比

路线 B 评级反映 GA 前的不确定性。如果你的团队深度绑定 Kafka 生态,路线 B 的长期价值可能高于当前评级。
AI 能力:选型时别忘了问这个问题
在传统的流数据选型中,评估维度是吞吐、延迟、运维成本、生态兼容。但 2026 年之后,「这个数据底座能不能支撑我的 AI 路线图」是一个必须回答的问题。
具体来说:
-
如果你需要实时 AI 推理(欺诈检测、实时风控、IoT 决策)→ 路线 A 的 Flink ML_PREDICT / VECTOR_SEARCH 是当前唯一生产可用的方案。路线 B 和 C 都需要外挂独立的模型服务。
-
如果你需要 AI Agent 持续运行(监控类 Agent、自动化运维、客服 Agent)→ 路线 A 的 Flink Agents 和路线 B 的 Orca 都在这个方向上。但两者都处于早期阶段,选型时应关注而非押注。
-
如果你的 AI 团队已经在 Databricks/Snowflake 上运转→ 路线 B 的联邦目录让流数据自动出现在这些平台里,迁移成本最低。路线 A 需要 AI 团队学 Flink SQL。
-
如果你需要消除 Training-Serving Skew→ 两条路线都能解决。路线 A 靠引擎内嵌推理 + 统一湖表,路线 B 靠存储层统一。选哪个取决于你的团队更熟悉 Flink 还是 Kafka。
边界层外,这个维度的权重在未来 2-3 年只会增加。今天选了一个不支持流式 AI 的数据底座,两年后要补这个能力时,代价是整个管道的重构。
不可忽视的关键因素:团队和组织
技术选型分析容易陷入「哪个架构更优雅」的视角。但在企业实际决策中,组织因素往往比技术因素更有决定性:
1. Kafka 团队不会自我革命。 如果企业有一个 5-10 人的 Kafka 运维团队,这个团队不会主动推动「去 Kafka」方案。路线 A 的最大阻力不是技术,是组织惯性。
2. Flink 人才稀缺是路线 A 的真正瓶颈。 Kafka 运维人才市场已经非常成熟,LinkedIn 上 Kafka 相关职位是 Flink 的 3-5 倍。在海外市场,找到靠谱的 Flink 团队比选型本身更难。(中国市场情况不同——阿里、腾讯、字节等大厂培养了大量 Flink 人才,路线 A 的落地条件在中国最好。)
3. CTO 的风险偏好决定路线。 保守型选路线 C(全托管零运维)或维持 Kafka 等 Lakestream 成熟;激进型选路线 A 获取架构优势。这不是技术判断,是组织文化。
成本真相
StreamNative 的 Ursa 论文获得了 VLDB 2025 最佳工业论文奖,其中一个核心论证是:基于对象存储的流架构可以将基础设施成本降低一个数量级(约 10x)。
成本降低的主要来源:
-
消除跨 AZ 副本复制。 这是传统 Kafka 部署中最大的成本项。三副本意味着每字节数据的网络传输成本是实际数据量的 2 倍。
-
对象存储取代本地 SSD。 对象存储(S3/GCS)的单位成本是本地 SSD 的 1/5 到 1/10。
-
消除独立 ETL 管道。 流数据直接写入湖表,不再需要 Kafka Connect 集群 + 中间存储的额外开支。
但有两个重要注意事项:
-
这个数据是 StreamNative 自己的论文结论,尚无独立第三方在大规模生产环境中验证。 引用时需标注来源。
-
对象存储有延迟代价。 尾延迟(p99/p999)在对象存储架构下可能高于本地磁盘架构。对超低延迟场景(<10ms),这是一个需要实测的 trade-off。
中国企业 vs 海外企业:选型逻辑会分化
这不是一个全球统一答案的选型题。中国企业和海外企业的最优路线可能系统性地不同:
中国企业 → 路线 A 条件最好。 Flink + Paimon 全托管服务已经成熟,Flink 人才供给充足,云厂商有强动力推广(利润比卖 Kafka 托管高)。
海外企业 → 路线 B 和路线 C 接受度更高。 Kafka 生态投资更深,Flink 人才更稀缺,多云需求更普遍。Lakestream 的「保留 Kafka 协议」主张对海外企业的吸引力更大。
这个分化不是暂时的。技术路线一旦选定,生态积累会形成正反馈——中国的 Flink 生态会越来越强,海外的 Kafka 改造方案会越来越多。两个市场可能走向不同的均衡。
12-18 个月:关键观察窗口
最后给一个时间框架。
现在能做的决策:
-
存量 Kafka 按场景分层,日志采集和流计算管道优先探索改造
-
新项目如果没有 Kafka 历史包袱,认真评估路线 A(Flink+Paimon)或路线 C
-
在选型评估中加入「AI 集成能力」维度
需要等 12-18 个月才能判断的:
-
StreamNative UFK 能否拿出 3-5 个大型生产案例?这决定路线 B 是否从"有潜力"升级为"可信赖"
-
Flink + Paimon 在海外市场的采用进展——如果只在中国落地,路线 A 的全球叙事就不成立
-
IBM/Confluent 整合后的产品路线图——他们是否也会走向存储层融合?如果是,路线 B 的窗口期会被压缩
-
AI Agent 基础设施(Flink Agents / Orca)的生产验证——这决定了流数据 + AI 的结合是技术 demo 还是真正的范式转移
一句可执行的建议: 不要在 2026 年为新项目默认选 Kafka。花两周时间做一个 Flink + Paimon 的 PoC,和你的 Kafka 方案做一次真实的对比——包括运维成本、AI 集成能力、团队学习曲线。这两周的投入,可能替你避免两年后的架构重写。
系列回顾
「流湖之变」三篇写完了。回头看:
第一篇 拆解了触发事件和三条路线——去 Kafka、改造 Kafka、云厂商封闭。核心判断是:三条路线的终极竞争是谁成为 AI 的默认数据底座。
第二篇 展开了 AI 层面的冲击——Feature Store 可能被消解、AI Agent 基础设施的范式转移、两条路线的 AI 焦点差异。
第三篇 回到企业决策——存量分层、新项目决策树、AI 能力作为选型维度、团队组织因素、成本真相。
这三篇覆盖的是一个正在发生的架构变局。接下来「边界层笔记 · AI+数据平台」系列还会继续——Lakehouse 对 AI 训练管道的影响、Agent 编排框架之争、中美 AI 基础设施路径分化,都是值得深入的方向。
如果你觉得有价值,转发给你的数据团队和 AI 团队——这两个团队可能需要坐下来一起看这三篇。
#流湖融合 #AIAgent #数据平台 #大模型
边界层笔记 · AI+数据平台 系列 | 流湖之变(三)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 13
13 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)