当 AI 成为流数据的买家:流湖之变(二)
本文是「边界层笔记 · AI+数据平台」系列文章,「流湖之变」专题的第二篇。上一篇我们拆解了Kafka 正在被三个方向同时挑战——去 Kafka、改造 Kafka、云厂商封闭。今天聊聊流湖融合为什么正在接管 AI 平台的数据供给。。

一笔账
先算一笔账:一条典型的 AI 数据管道——Kafka → Flink → Iceberg → Trino → Feature Store → Model Serving——六个组件,每个 99.9% 可用性。六个 99.9% 相乘,整体可用性掉到 99.4%。折算下来,每年超过 50 小时不可用。
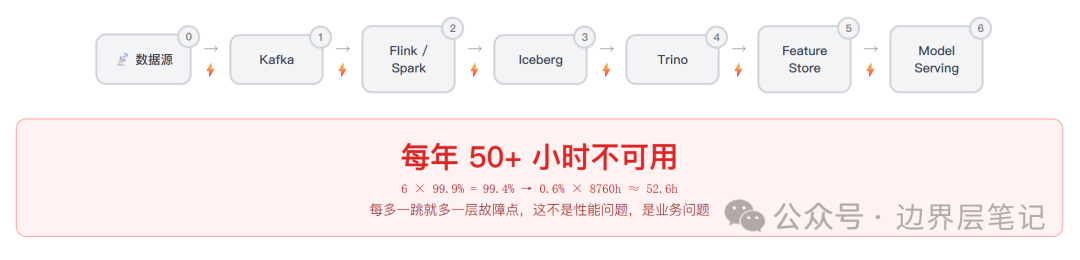
50 小时的不可用背后,流湖融合不只是数据工程师的内部优化,而是 AI 系统层面的结构性变化。答案藏在 AI 当前的数据消费方式里。
AI 的数据瓶颈:不是算力,是管道
今天绝大多数 AI/ML 系统消费数据的方式,仍然是批处理:
数据源 → Kafka → ETL 管道 → 数据湖 → 定时抽取 → Feature Store → 模型推理
这条链路有三个结构性问题:
延迟太高。 从事件发生到模型能看到这条数据,通常是分钟到小时级。对于欺诈检测、实时推荐、自动驾驶决策等场景,这个延迟不是性能问题,是业务问题——你的模型用的是"过去"的数据做"现在"的决策。
链路太长。 Kafka → Flink/Spark → Iceberg → Trino → Feature Store → Model Serving,六个以上组件各自独立运维。每多一跳就多一层故障点——开头那笔 50 小时的账就是这么来的。
训练-服务偏差(Training-Serving Skew)。 ML 工程领域公认的"沉默杀手":训练时用的是离线特征(从湖表批量抽取),推理时用的是在线特征(从 Feature Store 实时查询),两套处理逻辑不同,导致模型在线上的表现和训练时不一致。如果训练和推理不读同一份数据、不用同一套处理逻辑,模型效果在上线那一刻就开始衰减。
流湖融合直接攻击这三个问题的根基。
路线 A 的 AI 野心:Flink 要变成 AI 推理引擎
Apache Flink 社区的野心不止于流湖融合。他们的目标是让 Flink 本身承担 AI 推理职责——不是把数据传给模型,而是让模型直接跑在流里。
几个关键能力:

把这些拼在一起,路线 A 的 AI 架构愿景变得清晰:
数据源 → Flink(流处理 + AI 推理一体化)→ Paimon 湖表(= 实时 Feature Store)
↕ ↕
ML_PREDICT / VECTOR_SEARCH 批量训练 / 离线分析
ETL 管道消失了。Feature Store 和湖表合一了。推理直接发生在流处理引擎内部。
这不是渐进式优化。六个组件变成两个,链路可用性的数学直接变了。更关键的是,训练和推理读的是同一张 Paimon 表、用同一套 Flink SQL 逻辑——Training-Serving Skew 从架构层面被消除。
如果你的场景是 sub-second 决策——欺诈检测、实时风控、工业 IoT——路线 A 的 ML_PREDICT + VECTOR_SEARCH 是当前唯一生产可用的方案。但你的 AI 团队需要学 Flink。
路线 B 的 AI 布局:让 AI 平台直接读流数据
StreamNative 走了一条不同的路。他们不试图把 AI 推理塞进流引擎,而是让现有 AI 平台无缝消费流数据。
核心组合是 Ursa(湖仓原生流)+ Orca(事件驱动 Agent 引擎):
Ursa 的价值在于:每个 Kafka topic 同时是一个 Iceberg/Delta Lake 表。AI 系统可以用 Kafka 协议实时消费,也可以用 SQL 引擎批量查询——读的是同一份数据。更关键的是,Ursa 内置联邦目录,自动注册到 Databricks Unity Catalog、Snowflake Horizon Catalog。这意味着 Databricks ML、Snowflake Cortex 等 AI 平台不需要额外配置,就能发现和查询流数据。
Orca 的价值更激进。它是一个事件驱动的 AI Agent 运行时(2025 年推出,目前 Private Preview),架构是"事件总线 + Agent 运行时":底层用 Pulsar/Kafka 作为共享事件总线,Agent 之间不直接通信,而是通过发布和订阅事件协作。Agent 拥有持久化流式记忆——不是每次请求重新加载上下文,而是持续运行、持续记住。
路线 B 的 AI 架构愿景:
数据源 → Kafka 协议写入 → Ursa(topic = 湖表,一次写入)
↕ ↕
Orca AI Agents(实时消费) Databricks/Snowflake(批量训练 + SQL 查询)
流数据写入一次,AI 实时推理和批量训练读同一份数据。Training-Serving Skew 同样从架构层面被消除——但路径不同:路线 A 靠的是引擎内嵌推理,路线 B 靠的是存储层统一。选路线 B 的企业,AI 团队可以继续用Databricks/Snowflake,不需要学新东西。
AI 平台的四层冲击
不管选哪条路线,流湖融合对 AI 平台的冲击是结构性的:

其中最值得展开的是 Feature Store 和 AI Agent。
Feature Store 还需要独立存在吗?
Feature Store 作为一个独立品类,核心价值是解决三件事:特征版本管理、在线/离线一致性、时间旅行查询。
但如果湖表本身就支持流式读写(Paimon changelog)、changelog 订阅(实时获取特征变更)、时间旅行(Iceberg snapshot),那 Feature Store 的核心功能都能被流式湖表原生提供。
这不是理论推演。Flink + Paimon 方案已经在内部把 Materialized Table 用作实时特征视图——本质上就是用湖表替代了 Feature Store 的在线服务层。
边界层外,这对 Feast、Tecton 等独立 Feature Store 厂商意味着生存威胁。当平台层把你的核心功能吞噬了,你要么向上走(做更高层的特征编排和治理),要么面临被消解。这是数据基础设施"从拆分到重新聚合"的又一个案例。
AI Agent 的范式之争:函数编排 vs 事件驱动
当前主流的 Agent 框架——LangChain、CrewAI、AutoGen——本质上是无状态的函数编排。每次请求进来,框架拉取上下文、调用 LLM、执行工具、返回结果,然后状态清空。Agent 的"记忆"靠外部存储(数据库、向量库)在每次请求时重新拼接。
这个模式在 demo 场景下运行良好。但在生产环境中,它有一个结构性的限制:Agent 不能真正"持续运行"。 它只能被触发、执行、返回——像一个函数,不像一个服务。
Flink Agents 和 StreamNative Orca 代表的方向完全不同。
Flink Agents 是 Apache Flink 社区的开源子项目,用 Flink 的状态管理(state backend)作为 Agent 的持久记忆,用事件流驱动 Agent 的行为。Agent 不是被"调用"的,而是"一直在跑"——持续监听事件流,持续更新状态,在需要时做出决策。
Orca 的思路类似但入口不同:底层用 Pulsar/Kafka 事件总线做 Agent 间协调,Agent 通过订阅事件而非 API 调用获取信息。目前已支持 Google ADK 和 OpenAI Agents SDK 接入。
这两者和 LangChain 的区别不是实现细节的差异,是范式级的分歧:

一句话总结:函数编排把 Agent 当函数——调用、执行、销毁;事件驱动把 Agent 当服务——常驻、感知、演化。 前者的天花板是"更聪明的 API",后者的天花板是"持续运行的数字员工"。
三个判断
-
流湖融合的终极客户不是数据工程师,是 AI 平台。 数据工程师关心的是管道运维和成本;AI 平台关心的是数据新鲜度和一致性。流湖融合的真正价值在于解决 AI 的数据供给问题。
-
Feature Store 作为独立品类可能被消解。 当湖表本身就支持流式读写、changelog 订阅、时间旅行,Feature Store 的核心功能被平台层吞噬只是时间问题。
-
AI Agent 的基础设施层正在从「LLM API + 向量数据库」转向「事件驱动流 + 持久化状态」。 这是范式级的转移,不是工具级的替代。但需要 12-18 个月的生产验证才能下定论。
下一篇回到你的办公室:你手上的 Kafka 集群该怎么办?新项目的 AI 管道该选谁?我给你一棵决策树。
#流湖融合 #AIAgent #数据平台 #大模型
边界层笔记 · AI+数据平台 系列 | 流湖之变(二)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 13
13 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)