VLA-AN: An Efficient and Onboard Vision-Language-Action Framework for Aerial Navigation in Complex E
|
序号 |
属性 | 值 |
|---|---|---|
| 1 | 论文名称 | VLA-AN |
| 2 | 发表时间/位置 | 2025 |
| 3 | Code | |
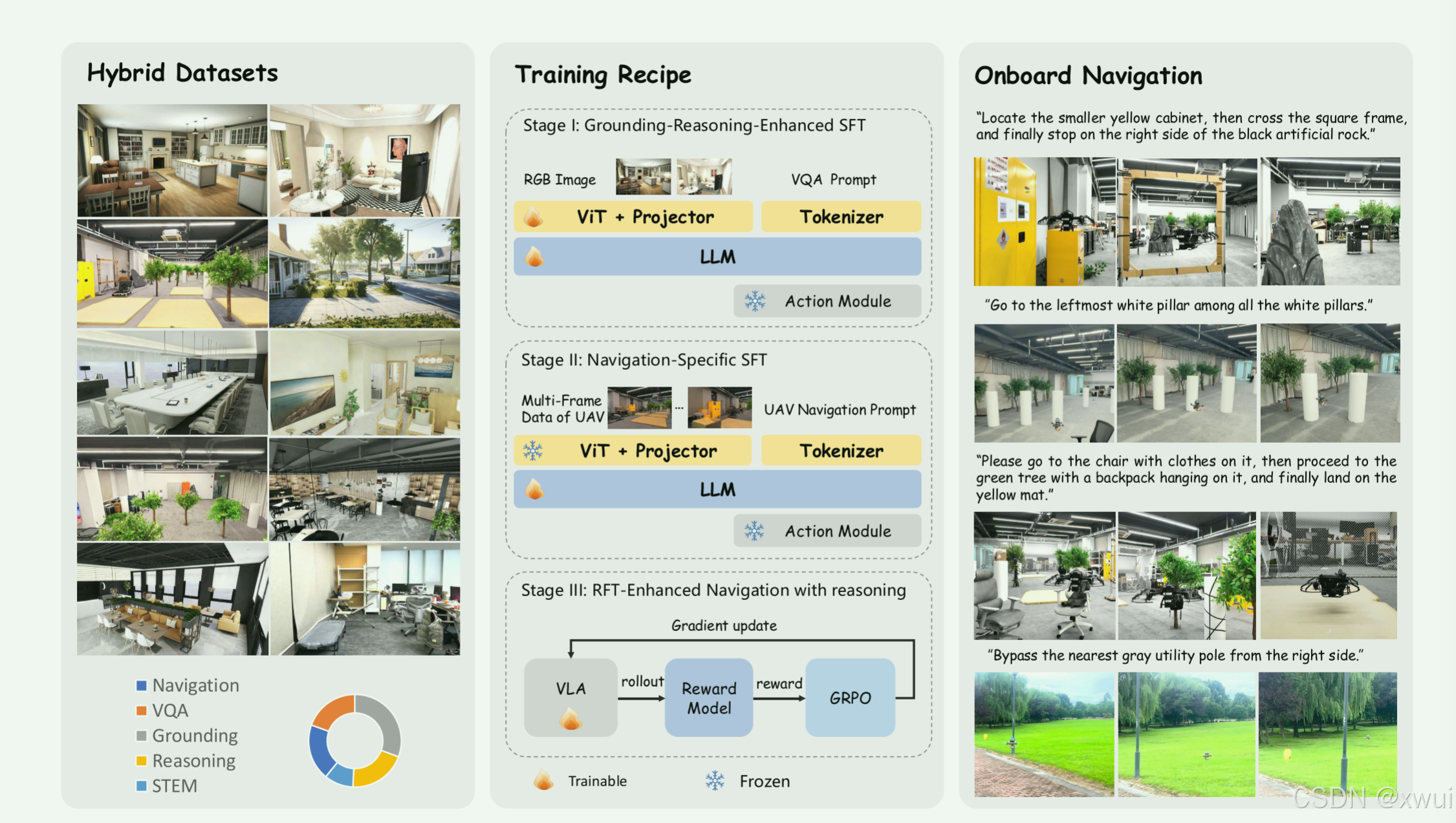
| 4 | 创新点 | 1:引入“3D-GS + 动力学约束”的混合数据闭环 在仿真数据生成中,结合了 3D 高斯溅射(3D-GS)的高保真光影纹理和网格(Mesh)模型的高可编辑性。同时在数据采集中引入了运动学动力学规划器(Kinodynamic Planning)。确保了合成数据在视觉层面的真实性,并且生成的飞行轨迹(包含多视角图像与深度图)严格符合无人机的物理限制(如加减速、机动位姿),有效降低了 Sim-to-Real(仿真到现实)的域偏差。 2.将 GRPO 强化学习引入无人机大模型 (RFT) 设计了“通用基础微调 -> 导航专精微调 -> 强化学习微调”的渐进式训练框架。在第三阶段引入了基于 GRPO(群体相对策略优化)的算法。针对大模型容易出现的“幻觉”和格式错误,将空间定位的精准度(Bounding Box IoU)和输出格式约束作为奖励函数(Reward Function)进行优化。以此提升模型对 3D 空间坐标估计的精确度及输出指令的可靠性。。 3.提出“反纯端到端”的几何安全兜底模块 系统未采用纯端到端(End-to-End)的动作生成策略(如 Diffusion 策略),而是将高频的底层控制与低频的大模型解耦。VLA 模型输出 3D 目标航点,底层动作模块结合深度图,基于可微排斥梯度场(类似人工势场法)进行局部轨迹修正。通过传统机器人运动规划算法进行“安全兜底”。在检测到潜在碰撞时实时施加排斥力并重新分配轨迹时间,弥补了大模型推理延迟高、存在概率噪声的缺陷,确保了受限空间内飞行的物理安全性。 4.针对边缘计算平台(ARM+受限GPU)的系统级推理优化 在低功耗硬件(NVIDIA Jetson Orin NX,100 TOPS)上,除常规引入 Flash-Attention、KV-Cache 和算子融合外,重点针对视觉大模型(ViT)进行了底层适配优化。针对 ARM 架构下 CPU 处理视觉特征效率低下的问题,利用 SIMD 指令集进行加速,并采用 CUDA Graph 降低 CPU 对 GPU 的调度开销。通过系统级重构,消除了进程间等待瓶颈,使全链路推理频率达到 2-3 Hz 的可闭环控制水平。 |
| 5 | 引用量 |
一:提出问题
目前,VLA 框架(如 RT-2, OpenVLA 等)在机械臂和自动驾驶汽车上取得了很大进展,但用在无人机(UAV)上非常少。原因正是作者提到的四大痛点:
-
痛点一:数据域偏差(Domain Gap)。无人机在天上飞,视角和地面机器人完全不同。如果在粗糙的仿真软件里训练,放到现实中肯定会“炸机”。
-
痛点二:时序推理能力弱。无人机飞行是一个连续的过程(不能像机械臂那样走一步停下来想很久),模型需要记住上一秒看到了什么,去推理下一秒该往哪飞。
-
痛点三:大模型的“幻觉”与安全风险。VLA 本质上是生成式模型(Generative Policies),它输出的动作带有一定的概率随机性。一旦模型抽风输出一个极端的偏航角,无人机就会直接撞墙。
-
痛点四:机载算力受限(SWaP限制)。无人机对体积、重量和功耗(Size, Weight, and Power)要求极高,通常只能背着一块算力很弱的板子(如 Jetson Orin Nano),跑不动几十亿参数的 VLA 模型。
针对上述问题:本文提出了以下的解决方案,
一:用 3D-GS 解决数据不真实的问题
3D Gaussian Splatting (3D-GS) 是最近计算机视觉圈火爆的新技术,它可以把现实世界极其逼真地重建为3D场景。作者用 3D-GS 渲染出了以假乱真的无人机视角画面来做训练数据,这样模型在训练时看到的东西和现实中无人机的摄像头拍到的几乎一样,完美跨越了“Sim-to-Real”(仿真到现实)的鸿沟。
二:渐进式三阶段训练策略
大模型不能一口吃成个胖子。作者采用了“课程学习”的思路:
-
第一阶段:学“认东西”(场景理解,知道哪里是门,哪里是障碍物)。
-
第二阶段:学“基础操作”(核心飞行技能,怎么往前飞、怎么转弯)。
-
第三阶段:学“高级任务”(复杂导航,比如“飞过那棵树后左转找到红色的车”)。
三:“大模型脑” + “传统几何小脑” 保障安全
这是工程上非常聪明的做法。作者没有完全信任 VLA 模型的输出。VLA 负责“高层意图”,但最终输出动作前,套了一个“几何安全校正模块”(基于传统的空间几何避障算法)。这就好比给大模型加了一个物理安全锁,彻底解决了端到端模型容易撞墙的硬伤。
四:端侧深度优化实现 2-3 Hz 推理
对于无人机来说,2-3 Hz(每秒处理 2 到 3 帧图像并输出动作)已经是可以满足低速闭环控制的及格线了。这意味着它不需要依赖地面的超算中心,哪怕在没有网络的大山深处,无人机仅仅依靠自己背着的小算力盒子就能完成复杂的自然语言指令飞行。
传统的无人机系统是一个固定的路径;感知->建图->规划->控制:
先用 YOLO 识别出物体。
再用 VSLAM 建一张 3D 地图。
接着用 A* 或 RRT 算法在地图上找一条路。
最后用 PID 或 MPC 控制器让飞机飞过去。
但是这种逻辑很容易出现错误累计,也就是其中一个环节出现问题,就会导致后期出现崩盘。而VLA这样的模型可以有效的避免这个问题:
一:造数据的降维打击(3D-GS vs 传统仿真引擎)
以前做无人机仿真,都在 Unreal 或 Unity 这种游戏引擎里搭模型(基于 Mesh)。这种画面看起来再精美,对大模型来说依然是一眼假的“游戏画风”(Domain Gap)。而这篇论文引入了目前 CV 界极其火爆的 3D-GS (3D Gaussian Splatting) 技术。3D-GS 是通过现实世界的照片渲染出来的,光影、质感几乎和真实世界一模一样。作者用这种技术生成了 10万条轨迹、100万样本,这在数据集层面上是对以往研究的“降维打击”。
二:无人机的“RLHF”(三阶段训练与 RFT)
大语言模型(如 ChatGPT)之所以好用,是因为经历了 Pre-training -> SFT -> RLHF(人类反馈强化学习)。这篇论文在第三阶段引入了 RFT(强化学习微调)。这是一个非常前沿的尝试!这意味着模型不只是在“模仿”人类怎么飞,它还在通过强化学习自己去探索“怎么飞最不容易撞墙,怎么飞最快”,从而掌握复杂的长视距导航逻辑。
三:拒绝“大模型的浪漫”(Action Module 结合几何安全)
最近具身智能非常流行用 Diffusion(扩散模型) 来生成动作,认为这样能生成丝滑的多模态轨迹。但是!Diffusion 本质上是个画图的模型,它有随机性。无人机在狭窄走廊里飞,如果模型突然“抽风”生成了一个偏航动作,无人机就碎了。所以,作者非常清醒地抛弃了极其耗时的生成式动作大模型,而是用了一个轻量级模块,最关键的是加上了“几何安全校正”。这意味着,哪怕大模型下达了撞墙的指令,底层的几何物理引擎也会把它拦下来强制避障。这在落地工程中是极其聪明的做法。
四:把大象装进冰箱(极客级别的部署优化)
无人机载重极小,往往只能背得起一块算力只有 100 TOPS 左右的板子(比如 NVIDIA Jetson Orin Nano/NX,对比之下,台式机上的 RTX 4090 有几百上千 TOPS 且功耗巨大)。在这么弱的板子上,跑通大模型,还要做到一秒钟处理 2 到 3 帧(2-3 Hz),同时吞吐量提升 8.3 倍,这背后一定做大量的算子融合、量化(Quantization)或者剪枝。这证明这个模型不是一个放在超算中心跑的“实验室玩具”,而是真正能拔掉网线,在荒郊野外独立飞行的产品雏形。
二:解决方案
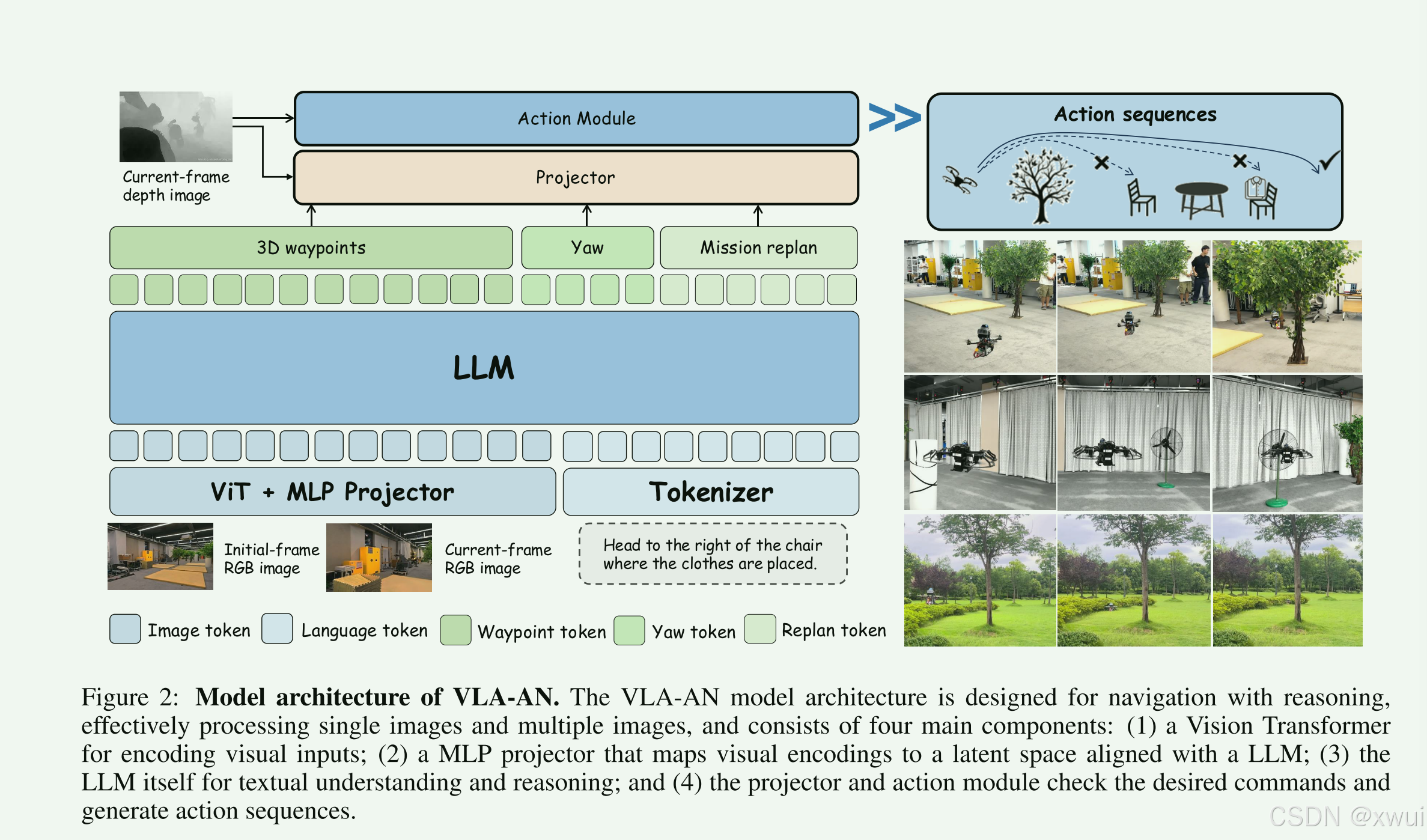
原文明确提到了 “hierarchical architecture(分层架构)”,把“语义推理(Semantic reasoning)”和“细粒度空间导航(Fine-grained spatial navigation)”解耦了。
-
大脑负责“想”: 大语言模型负责处理复杂的指令和做长期的规划(全局重规划)。
-
小脑负责“动”: 动作模块(Action module)负责接住大脑传下来的航点(Waypoints),并把它们变成安全的局部飞行序列。这彻底印证了我们之前的讨论:真正解决机载部署的秘诀不是强行让大模型跑得快,而是架构分层。
传统的语音控制无人机只能听懂“前进三米”或“左转90度”这种呆板的指令。而 VLA-AN 的大脑是如何处理“飞到放着衣服的白椅子右边”这样极其复杂的开放式指令的呢?它展示了三步走逻辑:
-
找实体(Entity): 画面里这么多东西,找到“白椅子”。
-
看属性(Attribute): 画面里可能有两把白椅子,它要找“上面放着衣服”的那一把。
-
算空间(Spatial relation): 找准椅子后,不能直接撞上去,而是要算出“它的右边”这个虚拟的 3D 坐标点。这展现了多模态大模型极其可怕的上下文理解和空间定位(Spatial Grounding)能力。
在许多早期的具身大模型研究中,模型往往是“开环”的——看一眼画面,盲猜一个动作,然后闭着眼睛执行。VLA-AN 是“闭环(Closed-loop)”的。它一边飞,一边拿着当前的摄像头画面和刚起飞时的画面做对比(检查自己飞到哪了)。如果发现目标被挡住了或者走错路了,它会触发“全局重规划(global replanning)”。这是让无人机能够在复杂走廊里完成长距离(long-horizon)任务的根本保障。
在 VLM/VLA 架构中,Projector(投影器) 通常是用来把图像特征和文本特征对齐的结构(比如 MLP 线性层)。在这里,作者似乎做了一个巧妙的设计:把高层的语义特征投射下来,与底层的动作模块结合。动作模块不仅仅是无脑执行大模型给的 3D 航点,它还会结合物理规律和障碍物位置,对航点进行“验证(validate)”和“细化(refine)”,确保生成的轨迹是一条不会撞墙的平滑曲线。
2.1 problem definition

公式1定义了无人机的眼睛不仅有 RGB 彩色相机(Itrgb),还加入了深度相机(Itdepth)。这是一个极其重要的细节!单纯的语言大模型不懂物理世界的远近,加入深度图输入,是后续动作模块能进行“几何安全校正”的物理基础。pt=(x,y,z,ψ)。这里只用了 4 个自由度(三维坐标 + 偏航角 Yaw)。为什么没有俯仰角(Pitch)和滚转角(Roll)?因为无人机底层飞控(如 PX4)会自动维持机身平衡。这也暗示了大模型生成的动作 at极有可能是 (x,y,z,ψ) 的目标航点,而不是底层电机的转速。

VLA 模型的输入里去掉了位姿 pt, at=π(L,Irgb,Idepth)。这意味着这颗“大模型大脑”完全不需要知道无人机的绝对 GPS 坐标,它纯粹依靠“看图听话”(视觉+语言)来输出下一步该往哪飞的相对语义动作(比如:“朝着前面的门飞2米”)。这也解释了为什么它能在“未知环境”中泛化。

-
I0 是无人机起飞时看到的第一眼(初始帧)。
-
It是当前看到的画面。
-
L是语言指令(比如“找红色椅子”)。这其实是一个视觉问答(VQA)或多模态对比匹配的过程。大模型不断问自己:“老板让我找红椅子,起飞时没看到(I0),现在眼前的画面(It)里有红椅子了吗?” 只要答案是 0,就继续飞;一旦是 1,立刻刹车。

大模型是个“黑盒”,如果直接把它接入无人机,它可能会无限循环或者卡死。
-
这是一个经典的有限状态机(Finite State Machine, FSM)。
-
无论大模型多么智能,它都必须服从这个状态机的调度。
-
重规划(REPLANNING): 结合公式3,如果飞了一半,发现目标还是没找到,或者路被堵死了,状态机就会切换到 REPLANNING,强迫大模型根据当前的新画面重新思考一条路。这就是 VLA-AN 不容易撞墙、能完成长距离任务的终极秘密。
2.2High-Fidelity Hybrid Data Collection
以往的研究往往sim2real的时候效果就变差,因为传统的 Unity/Unreal 仿真引擎是用多边形网格(Mesh)建的模,虽然看起来很精美,但对于神经网络的“眼睛”来说,那种光影和材质充满了人工痕迹(俗称“游戏画风”)。作者拿着现实世界的视频,用 3D-GS 技术“复刻”了一个由无数高斯椭球体组成的 3D 世界。大模型在这个场景里训练,看到的几乎就是现实世界的照片。这就是为什么它能在物理世界直接零样本(Zero-shot)落地的核心。
在具身数据合成中,最容易犯的错误就是“让虚拟相机在 3D 空间里随便飘”,然后录制画面。在本文中,无人机不是想停就能停的,它有惯性,还要受空气动力学限制。作者在这里使用了基于梯度的轨迹规划器,并特别强调了 Z轴(高度) 上的避障穿梭。这意味着生成的数据不仅“看起来像无人机拍的”,连飞行的姿态、加减速的物理规律都完全符合真实的无人机动力学。大模型从这些数据中学到的,是真正能在物理世界执行的飞行技能。在 3.1 节里我们讲到没有 Pitch 和 Roll,这里我们看到了四个方向(前后左右)的摄像头。这极大地拓展了无人机的“感受野”,让它不仅能往前看,还能理解三维空间中的侧向约束(为后面应对复杂的长走廊和转角打下了基础)。
虽然 3D-GS极其逼真,但它就像一张“3D相片”,极难编辑。比如,你很难用代码在 3D-GS 场景里动态地把一张桌子挪个位置,或者关掉场景里的一盏灯。虽然 Mesh 画风有点假,但你可以随意改变光照、生成各种奇形怪状的障碍物(这叫“域随机化 Domain Randomization”)。作者没有执迷于纯 3D-GS,而是把 3D-GS数据(保真实) + Mesh数据(保多样性/鲁棒性) + 真实世界少量数据(终极锚定) 混合在一起喂给模型。这正是目前特斯拉、Waymo 等自动驾驶头部企业在做数据闭环时使用的顶级策略!
2.3 Multi-stage Training for VLA
本文采用了三阶段的训练方案,采用了课程学习的方式是,对模型进行了训练:
1.作者不仅用了普通的 VQA 数据,还加入了 STEM(理科常识) 和 多帧/多视角(Temporal & Multi-view) 数据。因为无人机飞行需要理解物理规律(比如“什么东西是可以穿过去的,什么是不可以的”)。多帧/多视角的加入,让模型从一开始就习惯了上一节(3.2)提到的“前后左右四个摄像头”和“时间连续性”,这彻底打通了互联网静态图片与机器人连续视频输入之间的壁垒。
2.第二阶段注入高质量的无人机导航数据,并按比例混合经过筛选的 VQA 推理数据,以构建专为空中导航定制的密集后训练(post-training)。“按比例混合经过筛选的 VQA 推理数据”。这是一个极具实操价值的“Trick”。如果你在驾校阶段只给模型看无人机轨迹,它就会把第一阶段学到的常识全忘光。通过混合训练(Mixing),模型既能输出精确的三维航点(3D Waypoints),又能保持用自然语言思考的能力。
3.GRPO(Group Relative Policy Optimization)是目前开源界最强大的强化学习算法之一(如果你了解 DeepSeek-Math 或最近大火的 DeepSeek-R1 模型,它们的核心也是基于 GRPO)。相比于传统的 PPO,GRPO 不需要额外训练一个庞大的 Critic 模型,它通过同一组内的多次采样做相对比较。这极大地节省了显存,使得在资源受限的情况下对多模态 VLA 大模型进行强化学习成为可能。
-
奖励函数(Reward Function)的精妙设计: 大模型最大的问题是“幻觉”(胡说八道)。在无人机上,如果模型出现了格式幻觉(没按格式输出坐标),系统就会崩溃。 作者用极其严苛的规则来做 Reward:
-
IoU 奖励:你指出的目标(比如红框)和真实的红框,交并比(IoU)有多高?偏一点就扣分!这倒逼模型练就极其精准的“像素级”空间定位(Grounding)能力。
-
格式模板奖励(Format Validation):输出的 JSON 或坐标格式错一个标点符号就给负反馈。
-
答案匹配:严格的逻辑推导约束。
-
2.4 Robust Action Module
动作分块(Action Chunking) 是具身智能机械臂极其流行的方法(比如斯坦福的 ALOHA),它指的是模型一次性预测未来几十步的动作。生成式大模型(特别是现在火爆的 Diffusion 扩散模型和 Flow-Matching)本质上是带概率和噪声的。对于机械臂来说,轨迹抖一下没关系;但对于无人机,走廊宽度可能只有 1.5 米,模型产生的零点几米的“推理噪声(inference noise)”,就会让无人机直接撞墙坠毁(“结构脆弱的无人机”)。作者极其清醒地认识到了这一点。
作者用了一个极其优雅的方法来修正大模型给出的粗糙航点:排斥梯度力。
-
这本质上是传统机器人学中非常经典的 人工势场法(Artificial Potential Field) 或 基于梯度的轨迹优化(如 CHOMP 算法) 的现代结合版。无人机和终点之间有一根橡皮筋(参考轨迹),大模型告诉了终点在哪。但是中间有一根柱子(从深度图提取的障碍物)。模块会在柱子表面生成“表面锚点”,这些锚点会像“磁铁的同极相斥”一样,产生一个力(排斥方向),把这根橡皮筋瞬间推开,绕过柱子。
-
为什么快? 因为这纯粹是物理公式和几何代数运算,不需要跑神经网络!在端侧算力板上,它的计算延迟是毫秒级(<1ms)的。
大模型给了一个终点后,底层先用一条直线/平滑曲线连过去。如果这条线没有碰到任何障碍物(深度图没报警),底层就直接飞,完全不耗费算力去算复杂的避障。只有当发现轨迹会穿模时,才唤醒几何计算。这种“偷懒”极其适合资源受限的无人机平台。
“重新估计时间分配(temporal allocation)”*:这是极其硬核的一点。轨迹被“排斥力”推弯之后,路程变长了,转弯变急了。如果无人机还按照原计划的速度飞,在急转弯处一定会因为向心力不足而失控掉高。因此,系统会重新计算每个轨迹点上的速度和加速度(重新分配时间),确保它符合电机的最大拉力和倾转角限制(动力学可行性)。这保证了无人机不仅“路线对”,而且“飞得稳”。
其实就可以说是在无人机上部署了一个传统的控制模型
2.5 Onboard Deployment Framework
无人机载重和电池有限,作者最终选择:Orin NX。这是一块极其精致的边缘计算板,算力在 100 TOPS 左右(功耗 10-25W)。加上外围电路,总共只给无人机增加了 80克 的重量(相当于一个鸡蛋)。但这也意味着,作者必须要在极其抠搜的算力下跑几十亿参数的大模型。
大语言模型本质上是极其消耗“内存带宽(Memory Bandwidth)”的。作者直接把目前服务器上最成熟的优化技术搬到了小板子上:
-
Flash-Attention:把原本需要在内存里来回读写的注意力机制矩阵计算,放在了 GPU 极快但极小的 SRAM 缓存里一次性算完,大幅减少了内存搬运。
-
算子融合(Operator Fusion):原本大模型跑一层 FFN 要调一次 GPU,跑一层 LayerNorm 又要调一次 GPU。算子融合就是把这两步写进一段底层代码里,一次召唤 GPU 就搞定,省掉了排队时间。
-
KV-Cache:大模型每次输出下一个字,其实前面说过的话不需要重新算,只要把它们的特征缓存(Cache)起来直接拿来用就好。
自然语言模型(LLM)现在优化的很好,但负责“看图”的 视觉 Transformer (ViT) 在边缘端兼容性极差。因为 Orin NX 这种板子上的 CPU 是基于手机用的 ARM 架构,很多最新的视觉 AI 算子(比如特定维度的卷积或池化)在 GPU 上跑不了,被迫回退到 CPU 上跑。而这种板子的 CPU 极弱,一旦回退,整个系统直接卡死。作者直接下场重构了算子顺序,甚至动用了 SIMD(单指令多数据流,在 ARM 上叫 NEON 指令集)。这就好比用汇编语言级别的手法,强行让 ARM CPU 一口气处理成批的数据,硬生生地把视觉特征提取的速度拉了上去。
第一步:选硬件(妥协的艺术)
作者面临的困境:好芯片(比如 Jetson Thor)太重了,装上无人机飞不起来;能飞得起来的芯片(比如 Orin NX,增加 80克),算力又极其可怜。
最终决定:硬着头皮用这块算力很弱的 Orin NX。这就逼着作者必须做极其深度的代码优化,否则大模型根本跑不动。
第二步:给“语言大模型”瘦身(常规优化)
既然硬件不行,就得给算法提速。作者直接搬来了目前大语言模型界最成熟的“三大件”优化套件:
Flash-Attention:优化注意力机制的计算,省内存。
算子融合(Operator Fusion):把几步计算合并成一步,省排队时间。
KV-Cache:缓存之前计算过的内容,不重复算废话。 (到这里,语言大模型部分勉强能跑顺畅了。)
第三步:解决致命的“偏科”问题(极其硬核的底层魔改)
这是整段最核心、也是作者最引以为傲的“脏活累活”。
致命Bug出现:大模型不仅要“说话”,还得“看图”(通过 ViT 视觉模型)。但是,Orin NX 这块板子的底层架构(ARM)对视觉算子极其不友好,导致 GPU 罢工,视觉计算全被扔给了极弱的 CPU 去算,导致整个系统卡死。
作者的救场手段:
用底层的 SIMD 指令集(相当于汇编语言级别的修改),强行逼迫 ARM CPU 加速干活。
用 CUDA Graph 把几十万条指令提前画成图打包塞给 GPU,不让弱鸡 CPU 再去干预 GPU 的调度。
三:实验
四:总结
本工作提出了 VLA-AN,这是一个通过结合高保真数据生成、多模态学习、安全感知的动作生成以及高效的机载部署来推进空中机器人自主性的集成框架。利用 3D-GS 方法,我们构建了一个逼真的、以无人机为中心的数据集,缩小了合成观测与现实世界观测之间的域偏差(domain gap)。三阶段训练范式赋予了模型强大的场景理解、时序推理和长视距导航(long-horizon navigation)能力,而轻量级的实时动作模块则确保了在受限、未知环境中的安全且无碰撞的控制。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 12
12 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)