LangChain - AI应用开发利器(四)
1. 聊天模型 -- 结构化输出
在LangChain 中,聊天模型提供了额外的功能:结构化输出。一种使聊天模型以结构化格式(例如 JSON)进行响应的技术。例如,可能希望将模型输出存储在数据库中,并确保输出符合数据库模式。这种需求激发了结构化输出的概念,其中可以指示模型使用特定的输出结构进行响应。
这样做的核心原因是:从“字符串”到“对象”的范式转换。想象一下,在没有这个功能之前,我们调用聊天模型得到的是一个AIMessage ,其内容是一个字符串。例如下述伪代码:
model = ChatOpenAI()
response = model .invoke("告诉我关于苹果公司的最新消息。")
print(response .content)
# 输出: "苹果公司于昨日发布了新款iPhone 其股价上涨了2% "
这个字符串对人类很友好,但对程序不友好。如果我们想从这段文本中提取出“公司名”和股价变化并用在后续逻辑中,则需要编写复杂且容易出错的解析代码(例如,使用正则表达式)。
聊天模型的with_structured_output方法则允许我们预先定义一个期望的数据结构,并要求大模型必须按照这个结构返回信息。
1.1. with_structured_output()
要想使用结构化输出能力,LangChain 提供了一种方法.with_structured_output(),该方法
需要先定义输出结构,然后执行通过.with_structured_output()得到的Runnable 实例。步
骤如下(伪代码):
# 1.定义输出结构
schema = {"foo": "bar"}
# 2.绑定schema,其实是生成支持结构化返回的Runnable实例
model_with_structure = model.with_structured_output(schema)
# 3.执行
structured_output = model_with_structure.invoke(user_input)
这是获得结构化输出的最简单、最可靠的方法。此方法将输出结构作为参数输入,返回一个类似 model 的Runnable。不同之处在于执行Runnable 后的输出结果,输出的不是字符串或消息,而是输出与给定输出结构相对应的对象。
该输出结构可以指定为TypedDict 类、JSON Schema 或Pydantic 类。如果使用TypedDict 或 JSON Schema,则Runnable 将返回一个字典,如果使用Pydantic 类,则将返回一个Pydantic 对象。以下是该方法的详细定义:
with_structured_output()方法的定义:
with_structured_output(
schema : dict[str ,Any] | type[_BM] | type | None = None ,
*,
method : Literal['function_calling ', 'json_mode ', 'json_schema '] = 'json_schema ',
include_raw: bool = False ,
strict : bool | None = None ,
**kwargs :Any ,
) → Runnable[PromptValue | str | Sequence[BaseMessage | list[str] | tuple [str , str] | str | dict [str ,Any]], dict | _BM]
请求参数:
- schema: 表示输出结构。可以传入:JSON,TypedDict,Pydantic,OpenAI函数/工具
- method:表示LLM的生成方式
- include_raw:如果为False(默认),则仅返回解析的结构化输出。如果在模型输出解析过程中发生错误,则会引发错误。如果为True ,则返回原始模型的BaseMessage和解析的模型响应。如果在输出解析过程中发生错误,它也会被捕获并返回。最终输出始终是带有键“raw”、“parsed” 和 “parsing_error” 的字典。
- strict:如果为True ,保证模型输出与schema 完全匹配。输入schema 也将根据支持的schema进行验证。如果为False ,输入schema 将不会被验证,模型输出也不会被验证。如果为None(默认),则不会将strict 参数传递给模型。
- tools:要绑定到聊天模型的工具列表。
- kwargs(Any):任何附加参数都直接传递给bind()
返回值:
返回一个Runnable实例。将来在执行的时候:
- 如果include_raw = False,如果schema是Pydantic类,则Runnable会输出Pydantic对象,否则Runnable输出一个字典
- 如果include_raw = True,则Runnable输出一个带有键的字典。
1.1.1. 返回Pydantic对象
我们可以设置执行Runnable 后的输出结果指定为Pydantic 类,这将返回一个Pydantic 对象。
当收到模型的响应后,LangChain 会提取出代表Pydantic 参数的JSON 对象,并用Pydantic 模型对其进行解析和验证,将这个验证后的JSON 转换为一个可用的Pydantic 对象实例返回。如下所示:
from langchain_deepseek import ChatDeepSeek
from typing import Optional
from pydantic import BaseModel , Field
# 定义大模型
model = ChatDeepSeek(model="deepseek-chat", temperature=0.7, max_tokens=2048)
# 定义输出结构: Pydantic类
class Joke(BaseModel):
"""给用户讲一个笑话"""
setup: str = Field(description="这是这个笑话的开头")
puncline: str =Field(description="这是这个笑话的妙语")
rating: Optional[int] = Field(default=None, description="1-10分,给这个笑话评分")
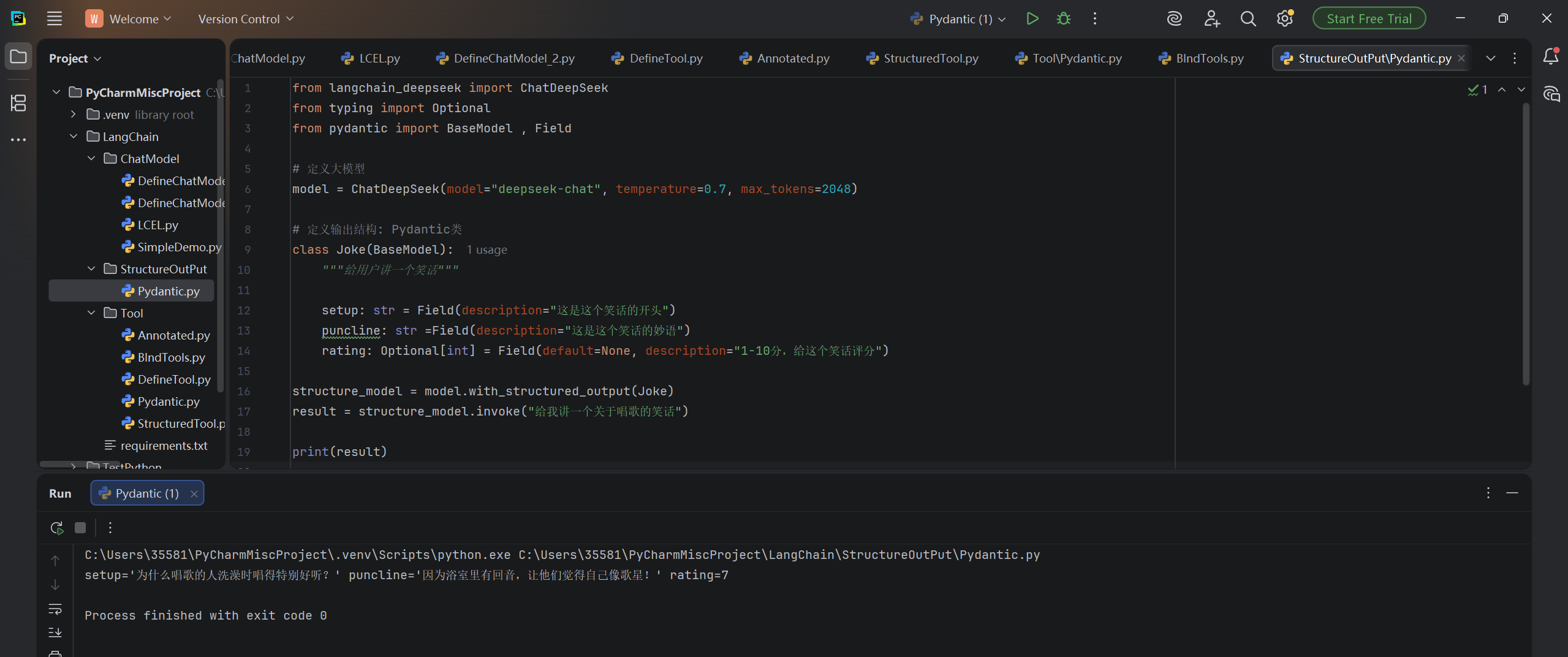
structure_model = model.with_structured_output(Joke)
result = structure_model.invoke("给我讲一个关于唱歌的笑话")
print(result)运行结果:
此外还支持嵌套输出:
from langchain_deepseek import ChatDeepSeek
from typing import Optional, List
from pydantic import BaseModel , Field
# 定义大模型
model = ChatDeepSeek(model="deepseek-chat", temperature=0.7, max_tokens=2048)
# 定义输出结构: Pydantic类
class Joke(BaseModel):
"""给用户讲一个笑话"""
setup: str = Field(description="这是这个笑话的开头")
puncline: str =Field(description="这是这个笑话的妙语")
rating: Optional[int] = Field(default=None, description="1-10分,给这个笑话评分")
class Data(BaseModel):
"""获取关于笑话的数据"""
jokes: List[Joke]
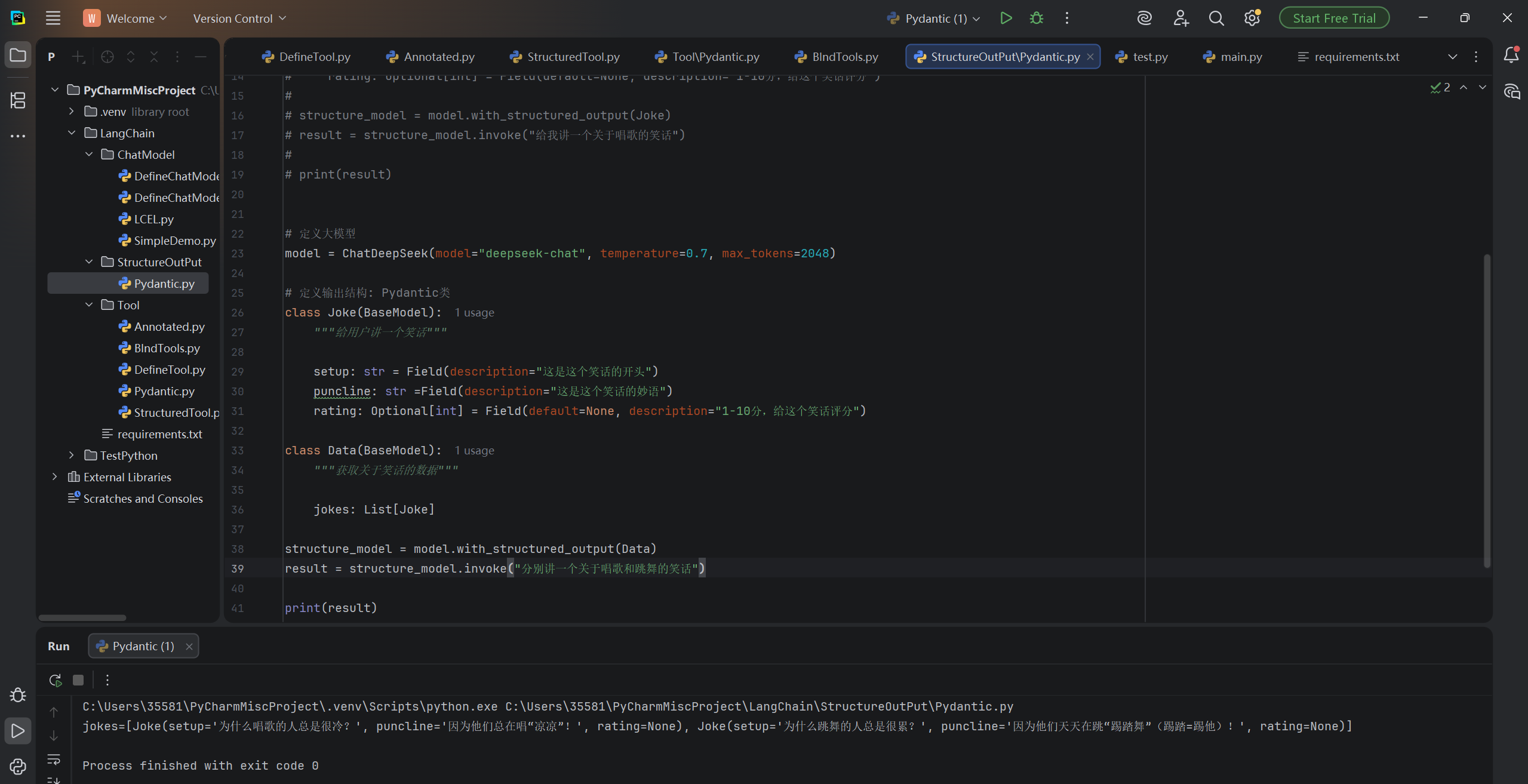
structure_model = model.with_structured_output(Data)
result = structure_model.invoke("分别给我讲一个关于唱歌和跳舞的笑话")
print(result)运行结果:
1.1.2. 返回TypedDict
先了解一下TypedDict,它用于为字典对象提供精确的,结构化的类型提示。它允许我们指定字典中应该有那些键,以及每个键对应的值的类型。
最清晰,最常用的定义方式,就是类似于定义一个类,如下所示:
from typing import TypedDict
class User(TypedDict):
name : str
age : int
email : str
is_active : bool =True # 默认值
这有什么用呢?对于它非常重要的一个能力就是捕捉键名拼写错误与类型错误。如:
user1 : User = {
"name": "Bob",
"age": 25 ,
"email": "bob@example.com"
}
# 类型检查器会捕获这些错误
bad_user : User = {
"name": "Dave",
"age": "forty", # 错误:应该是int
"emial": "dave@example.com" # 错误:拼写错误
}
因此,我们也可以设置执行Runnable 后的输出结果指定为TypedDict 类,这将返回一个字典,且输出后,会根据设定进行验证。以下是该方法的使用姿势:
from langchain_deepseek import ChatDeepSeek
from typing import Optional
from typing_extensions import Annotated ,TypedDict
# 1.定义大模型
model = ChatDeepSeek(model="deepseek-v4-flash")
# 2.定义输出结构
class Joke(TypedDict):
setup: Annotated[str, ..., "这个笑话的开头"]
puncline: Annotated[str, ... , "这个笑话的妙语"]
rating: Annotated[Optional[int], None, "从1到10分,给这个笑话评分"]
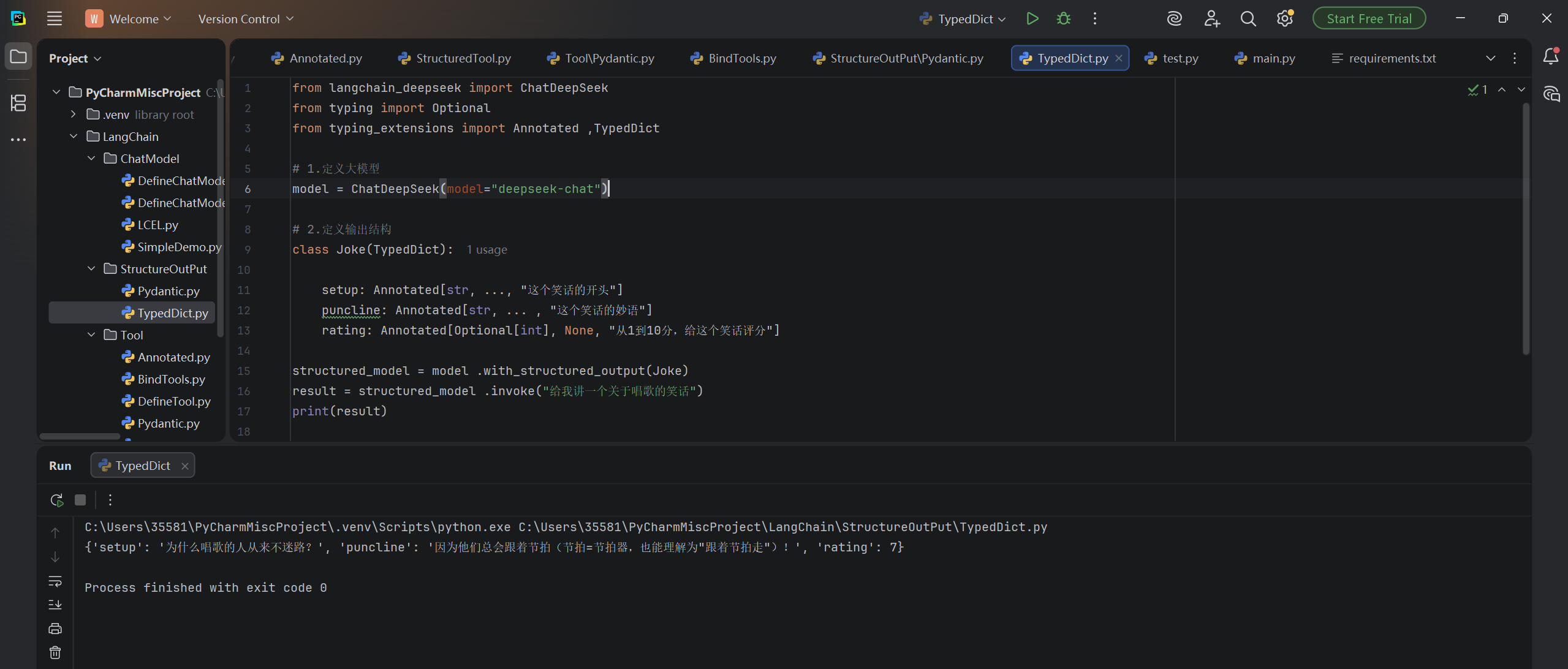
structured_model = model .with_structured_output(Joke)
result = structured_model .invoke("给我讲一个关于唱歌的笑话")
print(result)
运行结果:
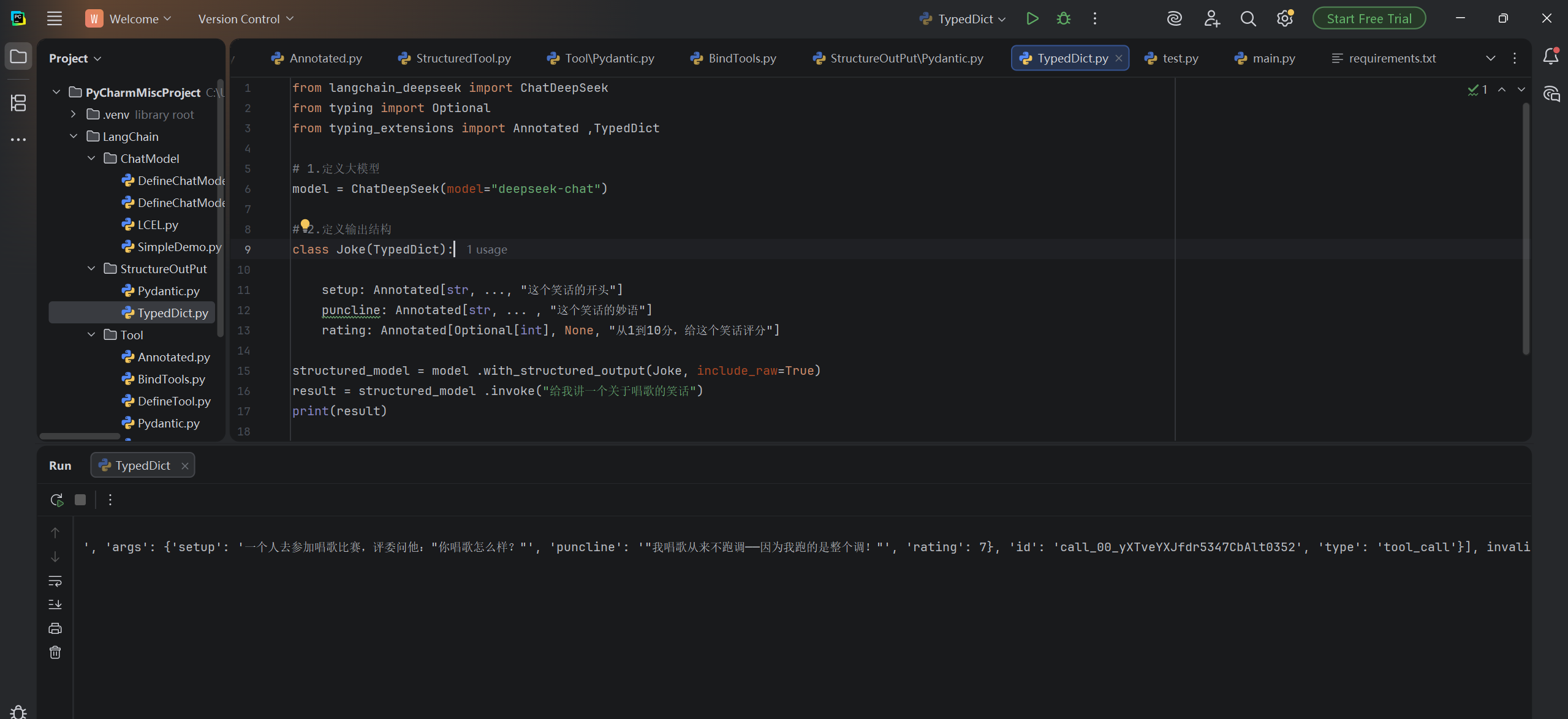
让我们加入include_raw=True,再来看看效果:
from langchain_deepseek import ChatDeepSeek
from typing import Optional
from typing_extensions import Annotated ,TypedDict
# 1.定义大模型
model = ChatDeepSeek(model="deepseek-chat")
# 2.定义输出结构
class Joke(TypedDict):
setup: Annotated[str, ..., "这个笑话的开头"]
puncline: Annotated[str, ... , "这个笑话的妙语"]
rating: Annotated[Optional[int], None, "从1到10分,给这个笑话评分"]
structured_model = model .with_structured_output(Joke, include_raw=True)
result = structured_model .invoke("给我讲一个关于唱歌的笑话")
print(result)运行结果:
1.1.3. 返回JSON
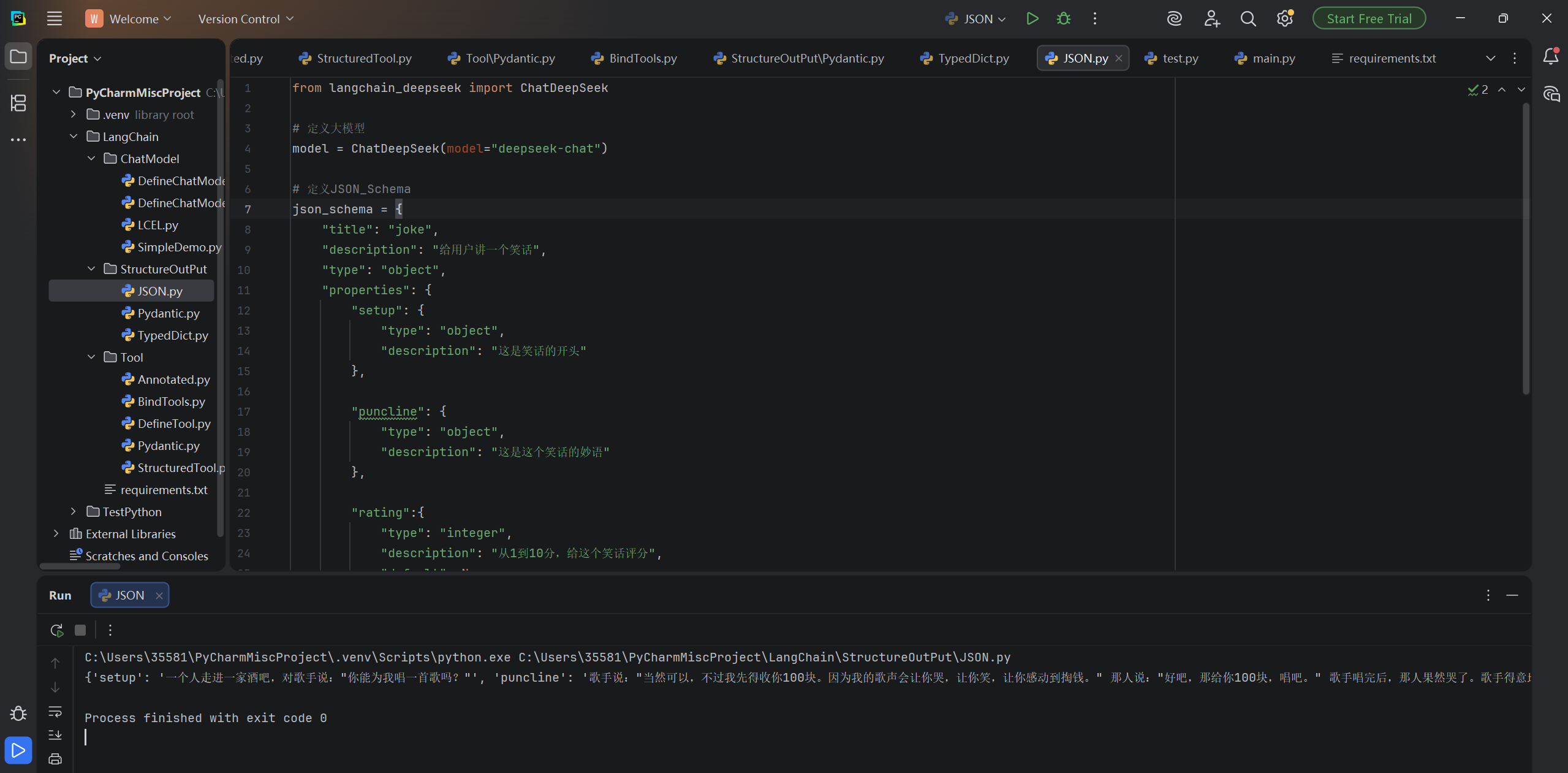
还可以让聊天模型返回直接返回JSON,只不过为了声明JSON,我们要定义JSON Schema,如下所示:
from langchain_deepseek import ChatDeepSeek
# 定义大模型
model = ChatDeepSeek(model="deepseek_chat")
# 定义JSON_Schema
json_schema = {
"title": "joke",
"description": "给用户讲一个笑话",
"type": "object",
"properties": {
"setup": {
"type": "object",
"description": "这是笑话的开头"
},
"puncline": {
"type": "object",
"description": "这是这个笑话的妙语"
},
"rating":{
"type": "integer",
"description": "从1到10分,给这个笑话评分",
"default": None
},
},
"required": ["setup", "puncline"],
}
structured_model = model .with_structured_output(json_schema)
result = structured_model .invoke("给我讲一个关于唱歌的笑话")
print(result)运行结果:
1.1.4. 选择输出格式
创建具有联合类型属性的父模式,下面举Pydantic和TypeDict的两个例子,代码如下:
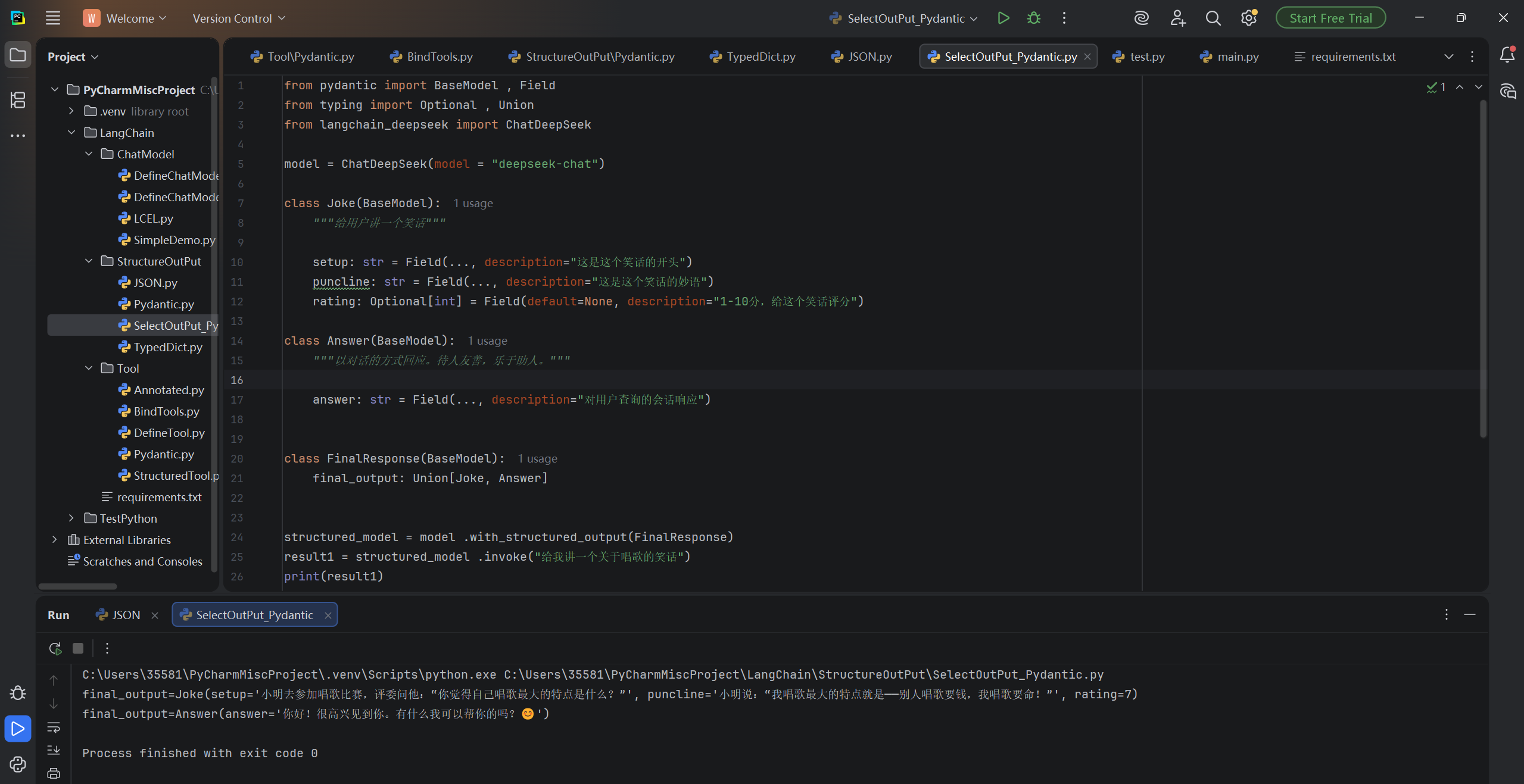
Pydantic:
from pydantic import BaseModel , Field
from typing import Optional , Union
from langchain_deepseek import ChatDeepSeek
model = ChatDeepSeek(model = "deepseek-chat")
class Joke(BaseModel):
"""给用户讲一个笑话"""
setup: str = Field(..., description="这是这个笑话的开头")
puncline: str = Field(..., description="这是这个笑话的妙语")
rating: Optional[int] = Field(default=None, description="1-10分,给这个笑话评分")
class Answer(BaseModel):
"""以对话的方式回应。待人友善,乐于助人。"""
answer: str = Field(..., description="对用户查询的会话响应")
class FinalResponse(BaseModel):
final_output: Union[Joke, Answer]
structured_model = model .with_structured_output(FinalResponse)
result1 = structured_model .invoke("给我讲一个关于唱歌的笑话")
print(result1)
result2 = structured_model .invoke("你好")
print(result2)运行结果:
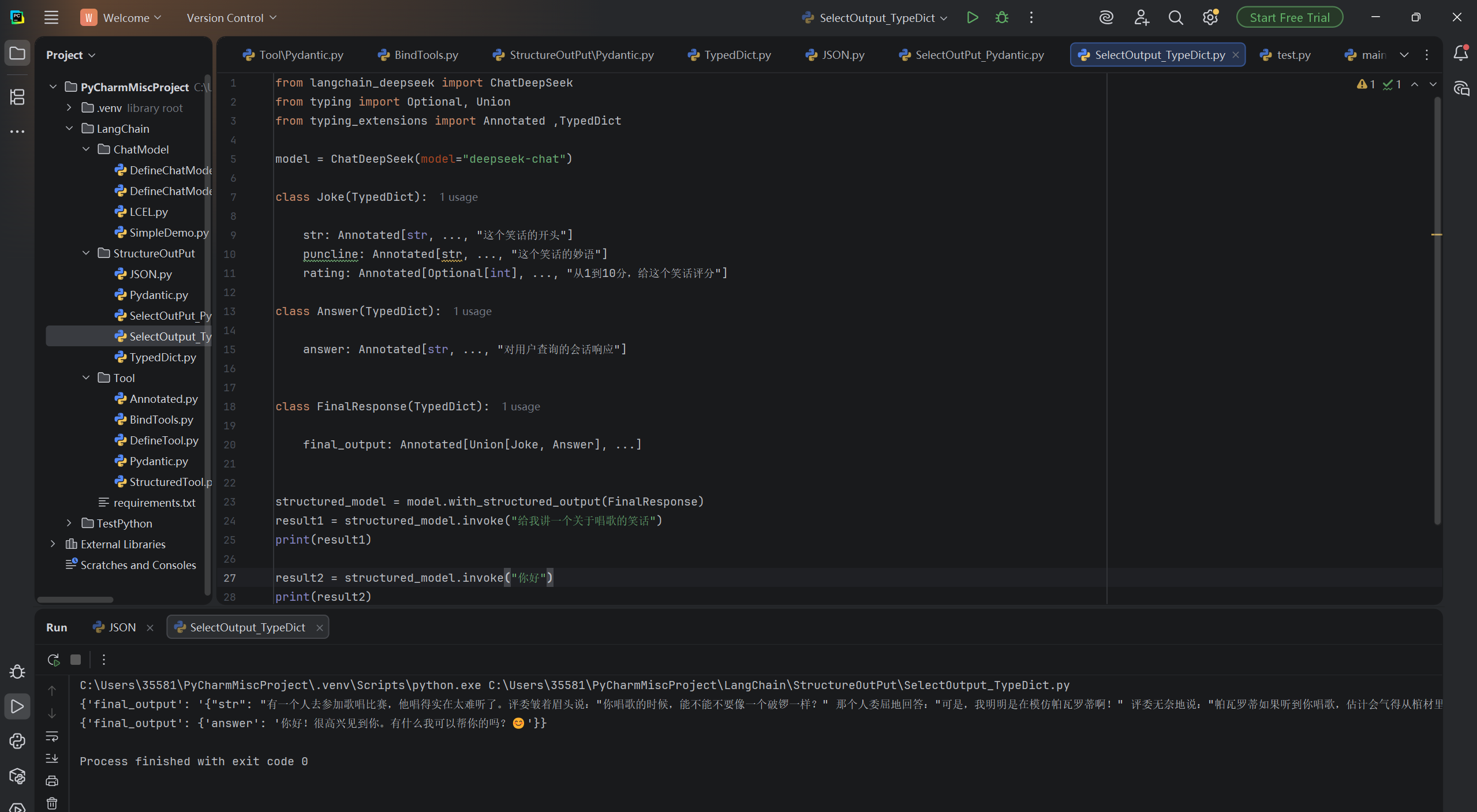
TypeDict:
from langchain_deepseek import ChatDeepSeek
from typing import Optional, Union
from typing_extensions import Annotated ,TypedDict
model = ChatDeepSeek(model="deepseek-chat")
class Joke(TypedDict):
str: Annotated[str, ..., "这个笑话的开头"]
puncline: Annotated[str, ..., "这个笑话的妙语"]
rating: Annotated[Optional[int], ..., "从1到10分,给这个笑话评分"]
class Answer(TypedDict):
answer: Annotated[str, ..., "对用户查询的会话响应"]
class FinalResponse(TypedDict):
final_output: Annotated[Union[Joke, Answer], ...]
structured_model = model.with_structured_output(FinalResponse)
result1 = structured_model.invoke("给我讲一个关于唱歌的笑话")
print(result1)
result2 = structured_model.invoke("你好")
print(result2)运行结果:
1.2. 实用场景
1.2.1. 场景1:作为信息提取器
from langchain_deepseek import ChatDeepSeek
from typing import Optional
from pydantic import BaseModel , Field
from langchain_core .messages import HumanMessage , SystemMessage
# 目标:提取人的个人信息
model = ChatDeepSeek(model="deepseek-chat")
class Person(BaseModel):
"""一个人的个人信息"""
# 注意:
# 1 . 每个字段都是Optional“可选的”—— 允许LLM 在不知道答案时输出None。
# 2 . 每个字段都有一个description“描述”—— LLM使用这个描述。
# 有一个好的描述可以帮助提高提取结果。
name: Optional[str] = Field(default = None, description="这个人的名字")
age: Optional[int] = Field(default = None, description="如果知道这个人的年龄")
hair_color: Optional[str] = Field(default = None, description="如果知道这个人的头发颜色")
height_in_meters: Optional[str] = Field(default = None, description="如果知道这个人的身高请将升高转化为以米为单位的高度")
structure_model = model.with_structured_output(Person)
Message1 = [
SystemMessage("你是一个提取信息的专家,只从文本中提取相关信息。如果您不知道要提取的属性的值,属性值返回null"),
HumanMessage("content=史密斯身高6英尺,金发.")
]
Message2 = [
SystemMessage("你是一个提取信息的专家,只从文本中提取相关信息。如果您不知道要提取的属性的值,属性值返回null"),
HumanMessage("content=王小明身高212厘米,头发是黑色的,年龄22岁.")
]
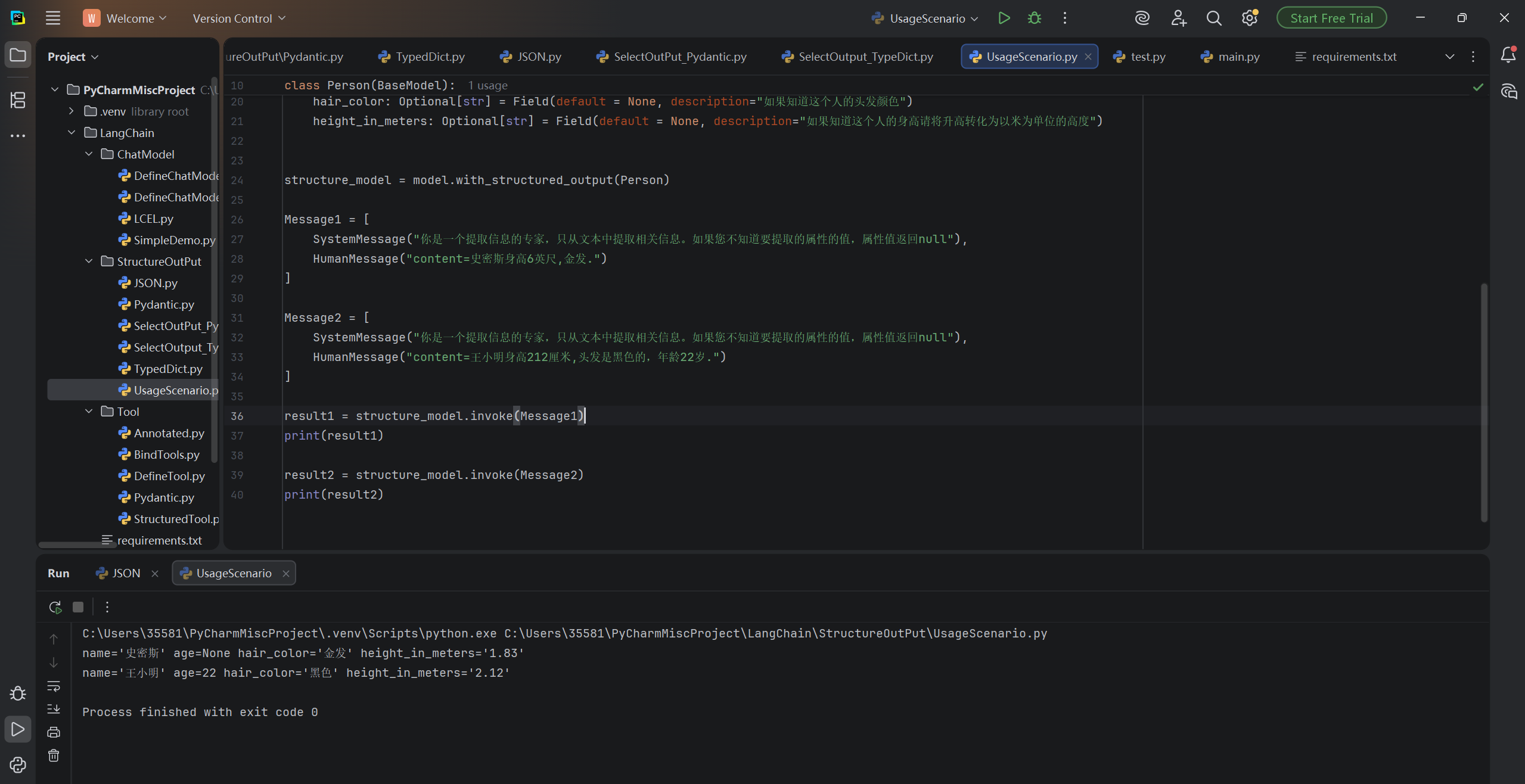
result1 = structure_model.invoke(Message1)
print(result1)
result2 = structure_model.invoke(Message2)
print(result2)运行结果:
1.2.2. 与工具相结合
from langchain_deepseek import ChatDeepSeek
from langchain_core.tools import tool
from pydantic import BaseModel , Field
model = ChatDeepSeek(model="deepseek-chat")
class SearchResult(BaseModel):
"""结构化搜索结果。"""
query: str = Field(description="搜索查询"),
findings: str = Field(description="调查结果摘要")
@tool
def web_search(query : str) -> str :
"""在网上搜索信息。
Args :
query : 搜索查询
"""
return "长沙今天多云转小雨,气温18-23度,东南风2级,空气质量良好"
structured_search_model = model .with_structured_output(
SearchResult ,
tools=[web_search],
strict=True ,
include_raw=True ,
)
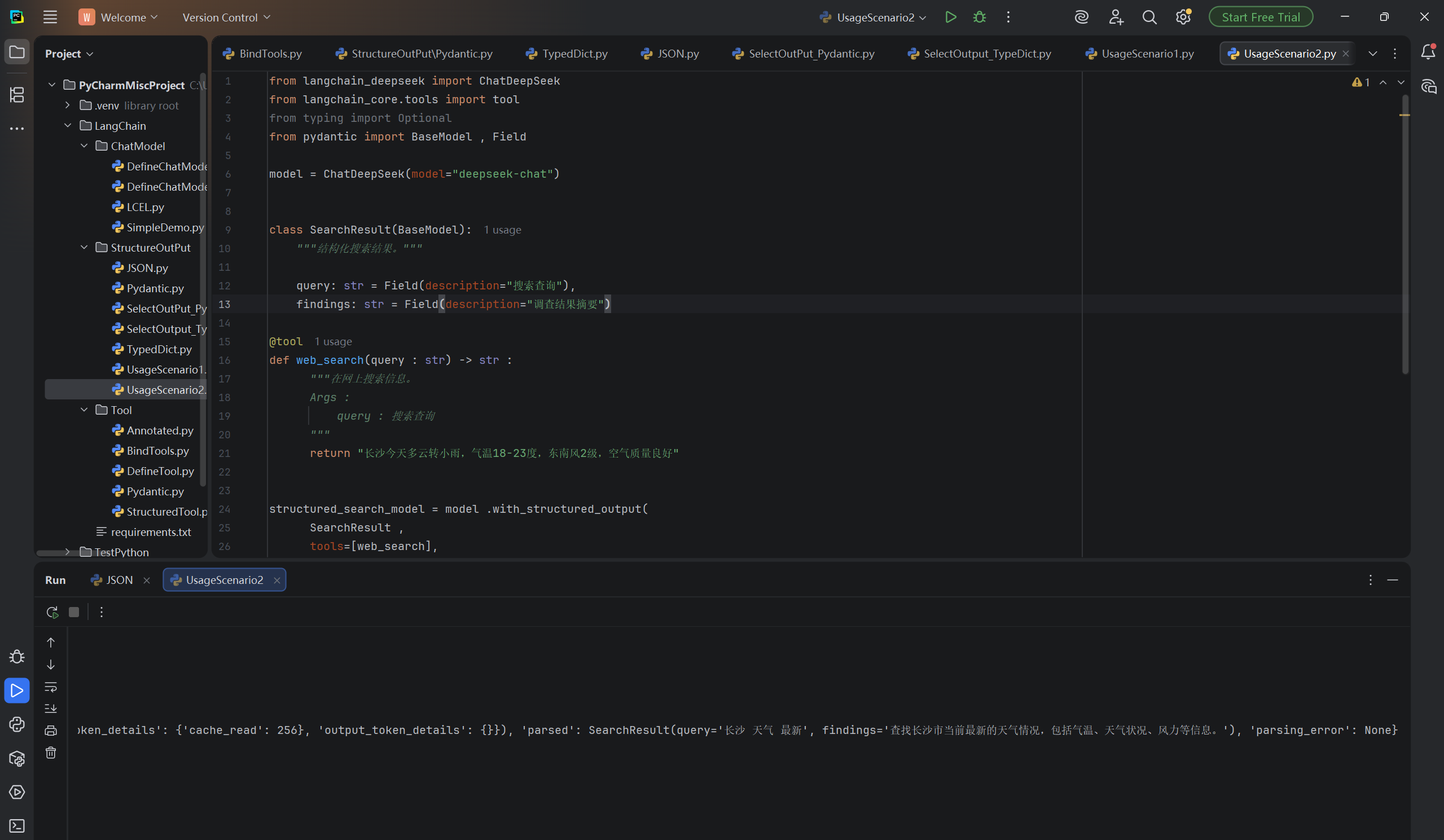
result = structured_search_model .invoke("搜索当前最新的长沙的天气")
print(result)运行结果:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)