【AI测试功能6】功能测试的自动化率:哪些该自动、哪些必须人工——AI测试人机协作决策指南
把“自动化率”当成唯一 KPI,很容易让团队测到大量“可断言、易脚本化”的东西,却在用户真正买单的体验与风险上失守——这在生成类、对话类 AI 产品里非常常见。下文讨论的是:哪些判定适合自动化门禁;哪些必须靠人(含真实用户信号)做校准与深测——前提始终是把口径与风险说清楚,而不是追求一个漂亮的百分比。
0. 写在前面:CI 绿了,用户仍可能不满意(合成教学场景)
先写清楚本文对“真实性”的约定,避免把示意叙事误读成可核验的单一客户项目:
- 下面故事是把多类 AI 内容/文案生成 产品测试里反复出现的结构性问题压缩成一个对照案例,用来检查你们自己的指标是否覆盖了“用户在乎的东西”。
- 文中的 用例条数、通过率、满意度 等数字表示量级与方向(“流水线好看但满意度起不来”这类矛盾),不是可引用的统计结论;请以贵司埋点、问卷、工单、评测集与实验设计为准。
叙事设定: 某团队搭建测试体系时,把 KPI 定成 “自动化率尽量拉满”。他们在 CI 里堆叠了大量 oracle 明确、实现成本低 的检查:JSON/字数/关键词/规则项,并叠加 LLM-as-a-Judge 做质量打分。
短期内确实可能出现:用例规模大、流水线全绿、通过率也很高。但上线后反馈仍常集中在 生硬、缺少感染力、信息密度低 ——也就是:表层约束对了,体验与文本价值仍不对。
这类落差通常不是“再加几百条断言”能兜底的,更常见的根因是:优化目标与用户体验目标不一致——自动化部分大量覆盖的是“易写脚本”的维度,而对 自然度、说服力、场景适配、措辞风险 等维度投入不足或缺少稳定的评测口径。
因此更务实的取向不是执着于口头上的 100%,而是:
- 先定义自动化率统计口径(按用例条数、执行时长、风险加权覆盖、评测维度等,不同口径会得到完全不同的百分比);
- 把断言分层:硬门禁(合同/合规/安全/schema/工具参数等)与非硬门禁(体验与质量基线);
- 把“人”放进校准环:抽检与双人一致性不是为了否定自动化,而是为了持续校准脚本、裁判模型与数据集,避免“自动化自嗨”。
下面把这个取向展开为可执行的划分方法。
1. 概念讲解
自动化率不是越高越好;更关键的是:自动化是否覆盖高损失场景,以及自动结果是否被持续校准。
讨论“合理自动化率”之前,建议先对齐两件事:
- 自动化率怎么算? 是否把 LLM 评测流水线也算进“自动化”?是否区分硬断言与软评分?
- 失败代价是什么? ToC 体验、ToB 合同、合规、金融/医疗等专业域,对“必须人过目”的要求不同。
把“整体自动化率”固定成某个百分比(例如 60–80%)并不具备跨团队可比性;更稳妥的表述是:硬 oracle、可重复、口径稳定的检查应尽量自动化;主观体验与开放域质量以抽样深测为主,并用数据反哺脚本与评测集。
也不是“主观题机器永远零分”:LLM-as-a-Judge、相似度、规则与检索证据链都能辅助,但它们会引入新的偏差与方差,需要 golden set、对抗样本、双人一致性 与版本化评测集去约束。
主观与专业判断类问题(例如“读起来自然吗”“法律/医疗建议是否适用”),不应期待单靠一次模型打分给出终裁;更合理的工程化路径是:自动筛 + 人审/专家审 + 线上反馈闭环。
过度追求“全自动化”时,常见副作用是为了凑指标把用例写“薄”——断言很多,但对关键失败模式不敏感。
1.5. 自动化 vs 半自动化 vs 人工:决策矩阵
判断一个测试场景更适合哪一类执行方式,可以用下表做启发式对照(真实项目里常有交叉与灰区):
| 判定维度 | 100% 自动化 | 半自动化(机器+人工) | 100% 人工 |
|---|---|---|---|
| 判定标准 | 有明确预期结果(是/否) | 可量化但有灰度(分数/等级) | 需要主观判断或强领域责任 |
| 典型场景 | 格式/schema、类型检查、结构校验 | 与参考答案的语义相近度、有对标源时的事实核对、关键词覆盖 | 创意写作质量、复杂体验、强领域专业性 |
| 自动化手段 | 精确断言、契约测试 | LLM-as-a-Judge、BERTScore 等(偏语义/表述相近度,不等价于“事实为真”)、规则与统计 | 人工评分、用户反馈、探索性测试 |
| 人工参与 | 低(仍需定期校准数据集与断言) | 定期抽检验证机器与裁判稳定性 | 高:终裁、争议样本、探索发现 |
| 执行频率 | 每次代码提交 | 每次 PR + 周期性抽检 | 按版本/按风险节奏安排 |
| “覆盖”怎么理解 | 对已建模的硬标准尽量全覆盖 | 对可量化维度做趋势监控 + 抽检 | 对主观维度做有计划的抽样 |
| 成本 | 主要是一次性工程化成本 + 维护 | API/算力 + 抽检人力 | 纯人力与组织协调成本 |
| 发现问题的类型 | 回归、格式/结构错误 | 质量退化、语义偏差、裁判漂移 | 体验问题、创意不足、专业错误、未知风险 |
关键结论: 决策核心不是“能不能自动化”,而是“自动化之后是否仍对齐用户损失与合规风险”。格式/schema 很适合门禁自动化;用户体验与开放域正确性通常需要人机协同与线上证据,而不是一张满分流水线就能代表。
2. 核心方法论
仍可用同一套分层思路做落地(与上表一致,细节按业务裁剪):
- 有明确 oracle 且稳定的 → 优先自动化。 格式、schema、类型、关键结构、合同级条款的可判定项等。
- 可量化但存在灰度/漂移的 → 半自动化。 语义相似度、(在有权威源或可比对数据前提下的)事实核对、关键词覆盖、LLM 裁判打分;必须配 golden 集、对抗样本与周期性抽检。
- 强主观或强责任边界的 → 人工为主。 创意、品牌调性、复杂体验、专业建议是否“可用”等;机器输出只能作辅助信号。
- 探索性测试 → 以人驱动为主。 目标不是重复执行固定 oracle,而是发现尚未建模的失败模式;应有章程、记录与复盘产出(缺陷/风险单/新用例入库)。
执行层面可对应为:
- 自动化层(CI/CD): 硬门禁断言、可重复的结构化检查、(可选)趋势型质量信号。
- 人工与协同层(按节奏): 抽检、探索性测试、边界案例评审(反哺黄金集)、版本级体验评估。
用一张图来看人机协作的决策流程(启发式,真实分类常有交叉):
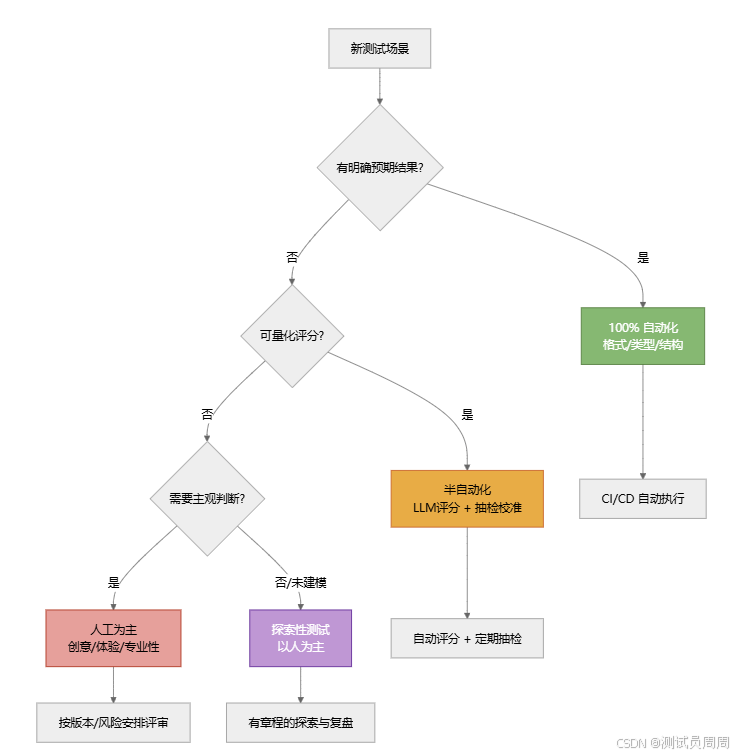
从绿到紫大致表示:门禁自动化最多、辅助信号次之、需要人类判断与发现最多。你的策略应是分层组合,而不是单层百分比竞赛。
3. 实战案例
说明: 本节与第 0 节同属合成教学案例,数字用于对齐“调整策略前后可能看到的指标形态”,请在贵司用真实数据复盘。
场景: 某 AI 内容生成类平台的测试策略调整。
前置条件: 用户输入主题后生成文章/社媒文案/商品描述等;测试团队规模中等。
问题: 初期把 KPI 压到“能自动化的都自动化”,回归里大量是格式、关键词、字数与规则项,并辅以 LLM 打分。结果常见是:流水线通过率高,但用户侧仍反馈 生硬、空洞、感染力不足 ——即 “测到的”和“用户损失的”不对齐。
根因分析: 覆盖了大量易脚本化维度,但对 自然度、信息密度、风格与场景适配 等要么缺少 oracle,要么仅有弱裁判且缺少校准环。
解决方案(方向性):
- 重划门禁与评测: 硬门禁(schema/合规/安全/关键字段)保持高自动化;开放体验维度改为 “趋势 + 抽检 + 黄金集升级”。
- 建立抽检与一致性: 对生成样本做固定节奏的随机抽检,关键维度双人独立评分并跟踪一致性(见第 5 节)。
- 探索性测试制度化: 模糊主题、矛盾指令、敏感话题等作为发现未知风险的输入,不仅产出缺陷,也回流为数据与用例。
- 指标上可能出现的变化是:自动化“条数占比”下降,但 用户满意度、工单率、严重缺陷逃逸 等更贴近业务的指标改善——这才是是否改对的判据。
4. 代码示例
下面是一段示意代码:演示如何把硬检查、软评分与人工复审标记串起来。依赖 openai 与 random;生产环境请用环境变量管理密钥,并对 LLM 输出做 schema 约束与重试。
import os
import random
import json
from typing import List, Dict
from openai import OpenAI
client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY"))
# ===<span class="wx-em-red"> 硬性标准验证(适合 CI 门禁) </span>===
def verify_format(response: str, format_type: str) -> bool:
"""格式验证:JSON/HTML/Markdown 等(示例偏简化,生产请用更严格解析器)"""
if format_type <span class="wx-em-red"> "json":
try:
json.loads(response)
return True
except json.JSONDecodeError:
return False
elif format_type </span> "html":
return "<html>" in response and "</html>" in response
return True
def verify_keywords(response: str, required_keywords: List[str]) -> Dict:
"""关键词验证:返回覆盖率和缺失列表"""
found = [kw for kw in required_keywords if kw in response]
missing = [kw for kw in required_keywords if kw not in response]
return {
"coverage": len(found) / len(required_keywords) if required_keywords else 1.0,
"found": found,
"missing": missing,
}
# ===<span class="wx-em-red"> 软性标准评分(半自动化:需校准) </span>===
def llm_judge_score(input_text: str, response: str, reference: str = None) -> float:
"""LLM-as-a-Judge 评分:0-1 之间(裁判模型需版本化与回归)"""
eval_prompt = f"""请评价以下 AI 回答的质量(0-1 分):
用户输入:{input_text}
AI 回答:{response}
参考要点:{reference or '无'}
只返回一个数字(0-1),不要解释。"""
result = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": eval_prompt}],
temperature=0,
)
try:
score = float(result.choices[0].message.content.strip())
return max(0.0, min(1.0, score))
except ValueError:
return 0.5 # 解析失败:应记录告警,而非静默吞掉
# ===<span class="wx-em-red"> 人机协作测试执行 </span>===
def hybrid_test_execution(test_case: Dict) -> Dict:
"""
人机协作测试执行
决策逻辑:
1. 硬性标准 → 自动验证(oracle 明确、可重复)
2. 软性标准 → LLM 评分 + 抽检校准(裁判不是真理)
3. 主观标准 → 人工评估
"""
results = {"auto": {}, "human_review_needed": False, "reason": ""}
if test_case.get("format_required"):
format_pass = verify_format(
test_case["response"], test_case["format_required"]
)
results["auto"]["format"] = format_pass
if test_case.get("required_keywords"):
keyword_result = verify_keywords(
test_case["response"], test_case["required_keywords"]
)
results["auto"]["keywords"] = keyword_result
if test_case.get("quality_threshold"):
auto_score = llm_judge_score(
test_case["input"],
test_case["response"],
test_case.get("reference")
)
results["auto"]["quality_score"] = auto_score
if auto_score < 0.7:
results["human_review_needed"] = True
results["reason"] = f"质量分数过低: {auto_score:.2f}"
elif 0.80 <= auto_score <= 0.85:
results["human_review_needed"] = True
results["reason"] = f"质量分数在边界区间: {auto_score:.2f}"
if test_case.get("category") in ["creative_writing", "user_experience"]:
results["human_review_needed"] = True
results["reason"] = f"主观类别: {test_case['category']}"
return results
# ===<span class="wx-em-red"> 人工抽检调度 </span>===
def schedule_human_review(
all_cases: List[Dict],
failed_cases: List[Dict],
sample_rate: float = 0.1
) -> List[Dict]:
"""
人工抽检调度
策略:
- 自动化失败的用例:建议全量复核(至少抽样复核)
- 自动化通过的用例:随机抽检(验证脚本/裁判是否漂移)
"""
review_queue = []
for case in failed_cases:
review_queue.append({**case, "review_reason": "自动化失败"})
passed_cases = [c for c in all_cases if c.get("auto_pass")]
sample_size = int(len(passed_cases) * sample_rate)
if sample_size > 0:
sampled = random.sample(passed_cases, min(sample_size, len(passed_cases)))
for case in sampled:
review_queue.append({**case, "review_reason": "随机抽检"})
return review_queue
# ===<span class="wx-em-red"> 使用示例 </span>===
if __name__ == "__main__":
test_cases = [
{
"id": "TC001",
"input": "帮我写一封拒绝邀请的邮件",
"response": "尊敬的XXX,感谢您的邀请...",
"format_required": None,
"required_keywords": ["感谢", "抱歉"],
"quality_threshold": 0.85,
"reference": "礼貌拒绝、表达感谢、说明原因",
"category": "writing",
"auto_pass": True,
},
{
"id": "TC002",
"input": "用 JSON 格式输出用户信息",
"response": '{"name": "张三", "age": 28}',
"format_required": "json",
"required_keywords": ["name", "age"],
"quality_threshold": 0.80,
"category": "structured_output",
"auto_pass": True,
},
]
all_results = []
failed = []
for case in test_cases:
result = hybrid_test_execution(case)
all_results.append({"case": case, "result": result})
if not result["auto"].get("format", True):
failed.append(case)
review_queue = schedule_human_review(test_cases, failed, sample_rate=0.1)
print(f"总用例数: {len(test_cases)}")
print(f"失败用例: {len(failed)}")
print(f"需要人工复核: {len(review_queue)}")
for item in review_queue:
print(f" - {item['id']}: {item['review_reason']}")
代码说明:
- 硬标准:适合 CI 门禁;维护成本在断言与数据。
- 软标准:LLM 裁判需版本化与回归;低分/边界分触发复审。
- 主观类:默认进入人工通道更稳妥。
- 抽检:同时用于抓 产品问题 与 测试实现/裁判漂移。
5. 注意事项和常见坑
- 别把 LLM-as-a-Judge 当真理。 已知偏差包括长度偏好、位置偏好、自举偏好等;应用上把它当作信号源之一,用 golden 集与双人标注做校准。抽检比例应随风险上调,10% 只是常见讨论起点,不是行业标准。
- 人工抽检要有记录。 评分、评语、问题类型、样本版本与模型版本要可追溯,否则无法复盘“是产品坏了还是评测坏了”。
- 探索性测试要有章程。 目标、范围、时间盒、记录模板与复盘产出(缺陷/风险/新用例)应固定下来,避免变成无效漫游。
- 自动化率目标要与口径绑定。 不同团队、不同系统的合理区间差很大;资源紧张时提高自动化通常伴随维护成本与假阴性/假阳性的取舍,需要显式讨论。
- 别忽略“通过”的用例。 抽检通过样本能发现脚本 bug、数据泄漏、阈值过松、裁判漂移等问题。
- 人工评估建议多人交叉。 至少两人独立评分并计算一致性(如 Cohen's Kappa);阈值是否“够好”取决于类别数、标注指南与业务容忍度,不宜写死单一魔法数字,应建立团队基线并持续对比。
- 定期做自动化 vs 人工的对照实验。 用固定评测集比较脚本/裁判与人工结论的一致性;当一致性低于团队基线时,优先复盘度量口径与数据,而不是简单加用例条数。
5.5. 常用工具一览
| 工具 | 用途 | 适用层级 |
|---|---|---|
| pytest | Python 测试框架 | 自动化层(CI/CD 集成) |
| openai 等 SDK | LLM API 客户端 | 半自动化层(裁判/生成) |
| bert-score | 语义相似度(不等价事实核验) | 半自动化层(初筛/辅助) |
| 统计库 | Kappa、相关性与置信区间等 | 评测治理与一致性分析 |
| Allure | 测试报告 | 各层结果可视化(按需要) |
| Notion/飞书 等 | 记录与评审流 | 人工层留痕 |
工具原则:每层选对工具,并把版本、数据与结论一并治理;避免“工具堆叠但口径漂移”。
6. 总结与思考
值得优化的是 风险覆盖与校准闭环,而不是口头上的自动化率。硬 oracle 应尽量自动化;开放体验与开放域正确性需要 人机协同 + 线上证据;探索性测试负责把未知变成已知。
【思考题】 你们统计的“自动化率”口径是什么?当前自动化最可能漏掉的高损失场景是哪一个,你打算用抽检还是线上指标去证明它已被覆盖?
关键词: 自动化率、AI测试、人机协作、LLM测试、测试自动化、测试策略、质量保障、评测集、LLM-as-a-Judge

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)