Spring AI Alibaba 1.x 系列【50】状态图执行引擎:GraphRunner、MainGraphExecutor、NodeExecutor 源码解析
文章目录
1. 前言
在调用 CompiledGraph#invoke 方法执行时:
/**
* 同步执行状态图流程,阻塞等待最终结果
* 底层基于响应式 stream 实现,阻塞获取最后一个输出结果,并提取最终状态
* @param inputs 图执行输入参数
* @param config 运行时配置(线程、中断、持久化等)
* @return 包装最终状态的 Optional,执行异常/无结果时返回空
*/
public Optional<OverAllState> invoke(Map<String, Object> inputs, RunnableConfig config) {
return Optional.ofNullable(stream(inputs, config).last().map(NodeOutput::state).block());
}
同步执行的底层也是基于响应式 stream 实现:
/**
* 响应式流式执行状态图(基于 Project Reactor)
* 是执行图的核心响应式入口,将输入数据构建为全局状态后开始执行流
* @param inputs 图执行输入参数
* @param config 运行时配置
* @return 响应式流 Flux,持续发射节点执行结果 NodeOutput
*/
public Flux<NodeOutput> stream(Map<String, Object> inputs, RunnableConfig config) {
return streamFromInitialNode(stateCreate(inputs), config);
}
会先创建并初始化图执行的全局状态对象 OverAllState :
/**
* 创建并初始化图执行的全局状态对象 OverAllState
* 处理输入参数、自动生成执行ID、装配键策略和数据存储
* @param inputs 图执行的输入参数
* @return 构建完成的全局状态对象
*/
private OverAllState stateCreate(Map<String, Object> inputs) {
// 处理空输入:如果输入为null,初始化为空Map(用于恢复执行场景)
if (inputs == null) {
inputs = new HashMap<>();
}
// 确保执行ID存在:如果没有执行ID,自动生成UUID作为唯一执行标识
if (!inputs.containsKey(GraphLifecycleListener.EXECUTION_ID_KEY)) {
Map<String, Object> newInputs = new HashMap<>(inputs);
newInputs.put(GraphLifecycleListener.EXECUTION_ID_KEY, java.util.UUID.randomUUID().toString());
inputs = newInputs;
}
// 使用建造者模式构建全局状态
// 1. 设置键策略映射 2. 设置输入数据 3. 设置全局存储 4. 构建最终状态
return OverAllStateBuilder.builder()
.withKeyStrategies(getKeyStrategyMap()) // 绑定图的键策略
.withData(inputs) // 绑定输入参数
.withStore(compileConfig.getStore()) // 绑定全局存储
.build();
}
工作流真正的执行是从 GraphRunner 开始:
/**
* 从初始全局状态开始,创建响应式执行流
* 真正启动 GraphRunner 执行图逻辑,并处理执行中的正常/完成/异常三种信号
* @param overAllState 初始全局状态(包含输入、策略、存储)
* @param config 运行时配置
* @return 节点执行输出流 Flux<NodeOutput>
*/
public Flux<NodeOutput> streamFromInitialNode(OverAllState overAllState, RunnableConfig config) {
// 校验配置不能为空
Objects.requireNonNull(config, "config cannot be null");
try {
// 创建图执行器
GraphRunner runner = new GraphRunner(this, config);
// 运行执行器,处理执行结果流
return runner.run(overAllState).flatMap(data -> {
// 情况1:执行完成 → 输出最终结果
if (data.isDone()) {
if (data.resultValue().isPresent() && data.resultValue().get() instanceof NodeOutput) {
return Flux.just((NodeOutput) data.resultValue().get());
} else {
return Flux.empty();
}
}
// 情况2:执行异常 → 发射异常信号
if (data.isError()) {
return Mono.fromFuture(data.getOutput()).onErrorMap(throwable -> throwable).flux();
}
// 情况3:正常执行中 → 发射当前节点输出
return Mono.fromFuture(data.getOutput()).flux();
});
} catch (Exception e) {
// 启动异常 → 直接返回错误流
return Flux.error(e);
}
}
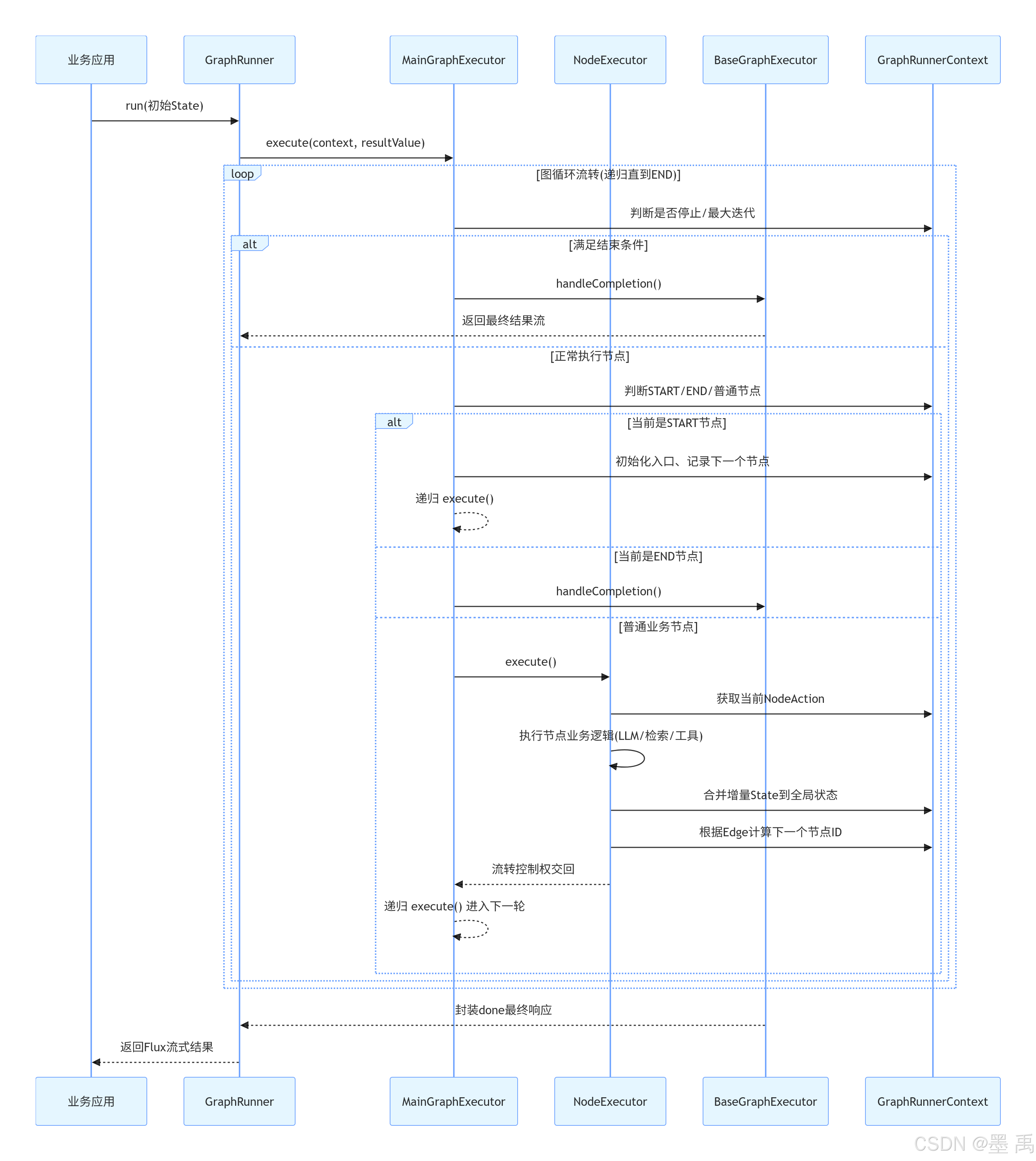
2. GraphRunner
GraphRunner 是 Spring AI Alibaba Graph 的【图执行引擎】,自己不执行逻辑,只负责接收初始状态 → 交给执行器 → 流式返回结果。
源码类注释:
这是一个基于 Reactor 的响应式图执行引擎。
为了代码更清晰、职责更分离,使用了面向对象(封装、继承、多态)重构。
2.1 成员变量
public class GraphRunner {
private final CompiledGraph compiledGraph;
private final RunnableConfig config;
private final AtomicReference<Object> resultValue = new AtomicReference<>();
private final MainGraphExecutor mainGraphExecutor;
逐个解释:
CompiledGraph: 已经编译好的可执行流程图RunnableConfig:运行时配置类resultValue: 线程安全存放最终执行结果MainGraphExecutor: 真正干活的核心执行器 ,GraphRunner只是外壳,执行逻辑都在这
2.2 构造方法
传入编译好的图 + 运行配置,并初始化执行器:
public GraphRunner(CompiledGraph compiledGraph, RunnableConfig config) {
this.compiledGraph = compiledGraph;
this.config = config;
this.mainGraphExecutor = new MainGraphExecutor();
}
2.3 run()
核心逻辑:
- 初始化
GraphRunnerContext(图运行上下文) - 调用真正的执行器运行图流程
- 响应式流式返回
public Flux<GraphResponse<NodeOutput>> run(OverAllState initialState) {
return Flux.defer(() -> {
try {
GraphRunnerContext context = new GraphRunnerContext(initialState, config, compiledGraph);
return mainGraphExecutor.execute(context, resultValue);
}
catch (Exception e) {
return Flux.error(e);
}
});
}
3. BaseGraphExecutor
BaseGraphExecutor 是所有图执行器的统一抽象父类,为所有图执行器提供通用的执行逻辑、完成处理、线程释放、结果封装等能力,采用抽象类设计,子类必须实现核心执行方法,体现多态与封装特性。
可用实现类:

整体层级关系:
- 继承关系:两个执行器都继承
BaseGraphExecutor - 协作关系:
GraphRunner调用MainGraphExecutorMainGraphExecutor内部调用NodeExecutor
3.1 execute()
定义了抽象执行方法,由子类实现具体的图执行逻辑:
public abstract class BaseGraphExecutor {
/**
* 抽象执行方法:由子类实现具体的图执行逻辑
* 不同执行器(同步/异步/流式)提供各自的执行实现,体现多态设计
*
* @param context 图执行上下文(包含编译图、配置、状态等)
* @param resultValue 结果存储引用,用于保存最终执行结果
* @return 图执行响应流 Flux<GraphResponse<NodeOutput>>
*/
public abstract Flux<GraphResponse<NodeOutput>> execute(GraphRunnerContext context,
AtomicReference<Object> resultValue);
}
3.2 handleCompletion()
定义了处理图执行完成逻辑(子类可复用):
/**
* 统一处理图执行完成逻辑(子类可复用)
* 封装通用完成逻辑:释放线程、保存检查点、封装最终结果
*
* @param context 图执行上下文
* @param resultValue 结果引用,用于存储最终返回值
* @return 完成状态的响应流
*/
protected Flux<GraphResponse<NodeOutput>> handleCompletion(GraphRunnerContext context,
AtomicReference<Object> resultValue) {
return Flux.defer(() -> {
try {
// 判断是否需要释放线程 + 存在检查点保存器
if (context.getCompiledGraph().compileConfig.releaseThread()
&& context.getCompiledGraph().compileConfig.checkpointSaver().isPresent()) {
// 执行线程释放,获取释放标记
BaseCheckpointSaver.Tag tag = context
.getCompiledGraph().compileConfig.checkpointSaver()
.get()
.release(context.getConfig());
resultValue.set(tag);
} else {
// 无释放配置:直接返回当前状态数据副本
resultValue.set(new HashMap<>(context.getOverallState().data()));
}
// 封装完成响应并返回
return Flux.just(GraphResponse.done(resultValue.get()));
}
catch (Exception e) {
// 异常时封装错误响应
return Flux.just(GraphResponse.error(e));
}
});
}
}
4. MainGraphExecutor
继承 BaseGraphExecutor 是图执行核心处理器(主执行器),实现完整的状态图执行流程:启动节点 → 业务节点 → 中断/恢复 → 结束节点 → 完成处理。
public class MainGraphExecutor extends BaseGraphExecutor {
/** 节点执行器:负责单个节点的实际逻辑运行 */
private final NodeExecutor nodeExecutor;
/**
* 构造方法:初始化节点执行器
*/
public MainGraphExecutor() {
this.nodeExecutor = new NodeExecutor(this);
}
4.1 execute()
核心职责:
- 判断当前节点类型(
START/END/ 普通节点) - 处理中断、恢复、循环、最大迭代次数
- 调度节点执行器(
NodeExecutor)运行节点
【核心执行方法】重写抽象执行逻辑:
/**
* 【核心执行方法】重写抽象执行逻辑
* 编排整个图执行流程:启动、中断、恢复、节点执行、结束、完成
* @param context 图执行上下文(状态、配置、节点、边)
* @param resultValue 执行结果引用
* @return 响应式执行流
*/
@Override
public Flux<GraphResponse<NodeOutput>> execute(GraphRunnerContext context, AtomicReference<Object> resultValue) {
try {
// ===================== 1. 终止条件:停止/达到最大迭代次数 =====================
if (context.shouldStop() || context.isMaxIterationsReached()) {
return handleCompletion(context, resultValue);
}
// ===================== 2. 从嵌入模式返回处理 =====================
final var returnFromEmbed = context.getReturnFromEmbedAndReset();
if (returnFromEmbed.isPresent()) {
var interruption = returnFromEmbed.get().value(new TypeRef<InterruptionMetadata>() {
});
if (interruption.isPresent()) {
return Flux.just(GraphResponse.done(interruption.get()));
}
return Flux.just(GraphResponse.done(context.buildNodeOutputAndAddCheckpoint(Map.of())));
}
// ===================== 3. 中断恢复:当前节点已中断,标记为已恢复 =====================
if (context.getCurrentNodeId() != null && context.getConfig().isInterrupted(context.getCurrentNodeId())) {
context.getConfig().withNodeResumed(context.getCurrentNodeId());
return Flux.just(GraphResponse.done(context.getCurrentStateData()));
}
// ===================== 4. 处理 START 启动节点 =====================
if (context.isStartNode()) {
return handleStartNode(context);
}
// ===================== 5. 处理 END 结束节点 =====================
if (context.isEndNode()) {
return handleEndNode(context, resultValue);
}
// ===================== 6. 从中断状态恢复 =====================
final var resumeFrom = context.getResumeFromAndReset();
if (resumeFrom.isPresent()) {
if (context.getCompiledGraph().compileConfig.interruptBeforeEdge()
&& java.util.Objects.equals(context.getNextNodeId(), INTERRUPT_AFTER)) {
var nextNodeCommand = context.nextNodeId(resumeFrom.get(), context.getCurrentStateData());
context.setNextNodeId(nextNodeCommand.gotoNode());
context.setCurrentNodeId(null);
}
}
// ===================== 7. 执行中断:需要暂停,返回中断元数据 =====================
if (context.shouldInterrupt()) {
try {
InterruptionMetadata metadata = InterruptionMetadata
.builder(context.getCurrentNodeId(), context.cloneState(context.getCurrentStateData()))
.build();
return Flux.just(GraphResponse.done(metadata));
}
catch (Exception e) {
return Flux.just(GraphResponse.error(e));
}
}
// ===================== 8. 正常执行:交给节点执行器运行业务节点 =====================
return nodeExecutor.execute(context, resultValue);
}
catch (Exception e) {
// 全局异常捕获:触发错误监听器 + 打印日志 + 返回错误流
context.doListeners(ERROR, e);
org.slf4j.LoggerFactory.getLogger(com.alibaba.cloud.ai.graph.GraphRunner.class)
.error("Error during graph execution", e);
return Flux.just(GraphResponse.error(e));
}
}
处理图启动节点(START):
/**
* 处理图启动节点(START)
* 触发启动监听器 → 获取入口节点 → 设置下一个节点 → 生成检查点 → 递归执行
*/
private Flux<GraphResponse<NodeOutput>> handleStartNode(GraphRunnerContext context) {
try {
// 触发 START 监听器
context.doListeners(START, null);
// 获取入口节点命令
Command nextCommand = context.getEntryPoint();
context.setNextNodeId(nextCommand.gotoNode());
// 保存检查点
Optional<Checkpoint> cp = context.addCheckpoint(START, context.getNextNodeId());
NodeOutput output = context.buildOutput(START, cp);
// 切换当前节点为入口节点,继续递归执行
context.setCurrentNodeId(context.getNextNodeId());
return Flux.just(GraphResponse.of(output))
.concatWith(Flux.defer(() -> execute(context, new AtomicReference<>())));
}
catch (Exception e) {
return Flux.just(GraphResponse.error(e));
}
}
处理图结束节点(END):
/**
* 处理图结束节点(END)
* 触发结束监听器 → 构建输出 → 执行完成逻辑
*/
private Flux<GraphResponse<NodeOutput>> handleEndNode(GraphRunnerContext context,
AtomicReference<Object> resultValue) {
try {
// 触发 END 监听器
context.doListeners(END, null);
NodeOutput output = context.buildNodeOutput(END);
// 输出结束信号,然后执行完成逻辑
return Flux.just(GraphResponse.of(output))
.concatWith(Flux.defer(() -> handleCompletion(context, resultValue)));
}
catch (Exception e) {
return Flux.just(GraphResponse.error(e));
}
}
5. NodeExecutor
单个 Node 真正执行的执行者,负责跑每一个具体业务节点,不负责全局流程,只专注「当前节点干完活」。
核心职责:
- 根据节点
ID获取 NodeAction(LLM节点/检索节点/工具节点/自定义节点) - 执行节点异步逻辑
action.apply() - 支持
InterruptableAction前置/后置中断拦截 - 合并节点输出增量
State到全局 OverAllState - 根据
Edge规则计算下一个节点 ID - 处理高级能力:
- 流式
Flux输出 Parallel并行节点GraphFlux/ParallelGraphFlux子流- 流式分片合并、推理内容合并、工具调用合并
- 流式
- 执行完节点后,交回 MainGraphExecutor 继续下一轮调度
内部持有主执行器,执行完节点后递归回去继续调度:
public class NodeExecutor extends BaseGraphExecutor {
private static final Logger log = LoggerFactory.getLogger(NodeExecutor.class);
// 持有主执行器,执行完节点后递归回去继续调度
private final MainGraphExecutor mainGraphExecutor;
public NodeExecutor(MainGraphExecutor mainGraphExecutor) {
this.mainGraphExecutor = mainGraphExecutor;
}
// ..............
}
MainGraphExecutor 的构造函数中会将自己本身传递给 NodeExecutor :
public MainGraphExecutor() {
this.nodeExecutor = new NodeExecutor(this);
}
5.1 executeNode()
@Override
public Flux<GraphResponse<NodeOutput>> execute(GraphRunnerContext context, AtomicReference<Object> resultValue) {
return executeNode(context, resultValue);
}
/**
* 【核心】执行单个节点
*/
private Flux<GraphResponse<NodeOutput>> executeNode(
GraphRunnerContext context,
AtomicReference<Object> resultValue
) {
try {
// 1. 设置当前节点
context.setCurrentNodeId(context.getNextNodeId());
String currentNodeId = context.getCurrentNodeId();
// 2. 获取节点要执行的动作(LLM/检索/自定义)
AsyncNodeActionWithConfig action = context.getNodeAction(currentNodeId);
if (action == null) {
return Flux.just(GraphResponse.error(RunnableErrors.missingNode.exception(currentNodeId)));
}
// 3. 处理可中断动作
if (action instanceof InterruptableAction interruptable) {
context.getConfig().metadata(RunnableConfig.STATE_UPDATE_METADATA_KEY).ifPresent(update -> {
if (update instanceof Map<?, ?> map) {
context.mergeIntoCurrentState((Map<String, Object>) map);
}
});
Optional<InterruptionMetadata> interruptMetadata = interruptable.interrupt(
currentNodeId,
context.cloneState(context.getCurrentStateData()),
context.getConfig()
);
if (interruptMetadata.isPresent()) {
resultValue.set(interruptMetadata.get());
return Flux.just(GraphResponse.done(interruptMetadata.get()));
}
}
// 4. 触发节点前置监听器
context.doListeners(NODE_BEFORE, null);
// 5. 【执行节点】异步执行
var future = action.apply(context.getOverallState(), context.getConfig());
// 6. 处理执行结果
return Mono.fromFuture(future)
.flatMapMany(updateState -> handleActionResult(context, updateState, resultValue))
.onErrorResume(error -> {
context.doListeners(ERROR, new Exception(error));
return Flux.just(GraphResponse.error(error));
});
}
catch (Exception e) {
return Flux.just(GraphResponse.error(e));
}
}
5.2 handleActionResult()
/**
* 处理节点执行结果:状态合并 + 路由下一个节点
*/
private Flux<GraphResponse<NodeOutput>> handleActionResult(
GraphRunnerContext context,
Map<String, Object> updateState,
AtomicReference<Object> resultValue
) {
try {
// 处理流式输出 Flux
Optional<Flux<GraphResponse<NodeOutput>>> embedFlux = getEmbedFlux(context, updateState);
if (embedFlux.isPresent()) {
return handleEmbeddedFlux(mainGraphExecutor, context, embedFlux.get(), updateState, resultValue);
}
// 处理并行流
Optional<ParallelGraphFlux> parallelFlux = getEmbedParallelGraphFlux(updateState);
if (parallelFlux.isPresent()) {
return handleParallelGraphFlux(context, parallelFlux.get(), updateState, resultValue);
}
// 处理中断
String currentNodeId = context.getCurrentNodeId();
AsyncNodeActionWithConfig action = context.getNodeAction(currentNodeId);
if (action instanceof InterruptableAction interruptable) {
Optional<InterruptionMetadata> interruptMetadata = interruptable.interruptAfter(
currentNodeId,
context.cloneState(context.getCurrentStateData()),
updateState,
context.getConfig()
);
if (interruptMetadata.isPresent()) {
context.mergeIntoCurrentState(updateState);
Command nextCmd = context.nextNodeId(currentNodeId, context.getCurrentStateData());
context.setNextNodeId(nextCmd.gotoNode());
context.buildNodeOutputAndAddCheckpoint(updateState);
context.doListeners(NODE_AFTER, null);
resultValue.set(interruptMetadata.get());
return Flux.just(GraphResponse.done(interruptMetadata.get()));
}
}
// --------------------------
// 【核心】合并状态到全局State
// --------------------------
context.mergeIntoCurrentState(updateState);
// --------------------------
// 计算下一个节点
// --------------------------
if (context.getCompiledGraph().compileConfig.interruptBeforeEdge()
&& context.getCompiledGraph().compileConfig.interruptsAfter().contains(currentNodeId)) {
context.setNextNodeId(INTERRUPT_AFTER);
}
else {
Command nextCmd = context.nextNodeId(currentNodeId, context.getCurrentStateData());
context.setNextNodeId(nextCmd.gotoNode());
}
// 构建输出 & 保存 checkpoint
NodeOutput output = context.buildNodeOutputAndAddCheckpoint(updateState);
context.doListeners(NODE_AFTER, null);
// --------------------------
// 递归回到主执行器,继续跑下一个节点
// --------------------------
return Flux.just(GraphResponse.of(output))
.concatWith(Flux.defer(() -> mainGraphExecutor.execute(context, resultValue)));
}
catch (Exception e) {
return Flux.just(GraphResponse.error(e));
}
}
5.3 流式、并行、中断处理
// ==================== 工具方法:流式、并行、中断处理 ====================
public Optional<Flux<GraphResponse<NodeOutput>>> getEmbedFlux(GraphRunnerContext context, Map<String, Object> partialState) {
return partialState.entrySet().stream()
.filter(e -> e.getValue() instanceof Flux<?>)
.findFirst()
.map(e -> transformFluxToGraphResponse(context, (Flux<?>) e.getValue(), e.getKey(), context.getCurrentNodeId()));
}
private Optional<ParallelGraphFlux> getEmbedParallelGraphFlux(Map<String, Object> partialState) {
return partialState.entrySet().stream()
.filter(e -> e.getValue() instanceof ParallelGraphFlux)
.findFirst()
.map(e -> (ParallelGraphFlux) e.getValue());
}
// 流式输出转换(省略大量流式细节,保留核心逻辑)
private Flux<GraphResponse<NodeOutput>> transformFluxToGraphResponse(
GraphRunnerContext context, Flux<?> rawFlux, String key, String nodeId) {
return rawFlux.map(element -> GraphResponse.of(context.buildStreamingOutput(element, nodeId, true)));
}
// 处理嵌入式流
public Flux<GraphResponse<NodeOutput>> handleEmbeddedFlux(
MainGraphExecutor main, GraphRunnerContext context,
Flux<GraphResponse<NodeOutput>> flux, Map<String, Object> state, AtomicReference<Object> result
) {
return flux.concatWith(Flux.defer(() -> main.execute(context, result)));
}
// 处理并行流
private Flux<GraphResponse<NodeOutput>> handleParallelGraphFlux(
GraphRunnerContext context, ParallelGraphFlux flux,
Map<String, Object> state, AtomicReference<Object> result
) throws Exception {
return Flux.merge(flux.getGraphFluxes().stream()
.map(f -> transformFluxToGraphResponse(context, f.getFlux(), f.getKey(), f.getNodeId()))
.toList())
.concatWith(Flux.defer(() -> mainGraphExecutor.execute(context, result)));
}
// 中断后处理
private Optional<InterruptionMetadata> interruptAfterForStreaming(GraphRunnerContext context, Map<String, Object> result) {
var action = context.getNodeAction(context.getCurrentNodeId());
if (action instanceof InterruptableAction ia) {
return ia.interruptAfter(context.getCurrentNodeId(), context.cloneState(context.getCurrentStateData()), result, context.getConfig());
}
return Optional.empty();
}
}
6. 总结
6.1 类的关系
- GraphRunner:启动入口
- MainGraphExecutor:判断节点、处理中断、循环、递归调度
- NodeExecutor:执行节点、合并状态、找下一个节点
- BaseGraphExecutor:公共完成逻辑
6.2 Graph 引擎执行流程图

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献83条内容
已为社区贡献83条内容

所有评论(0)