我用 Codex 把《西游记》做成绘本 PDF,才发现生图只是最小的一步
 我把《西游记 · 三打白骨精》做成了一本 12 页绘本 PDF。
我把《西游记 · 三打白骨精》做成了一本 12 页绘本 PDF。
这件事看起来像“生成一堆图,再拼成一个 PDF”,但真正有用的地方,不在生成本身,而在流程拆分。
我把整件事拆成了四层:
-
- 用 Markdown 写内容
-
- 从 Markdown 里解析分镜
-
- 统一生成图像提示词,再调用生图
-
- 把图片和旁白拼成 PDF
最后得到的不是一次性脚本,而是一条可以反复复用的内容生产流水线。
这次做出来的是什么
最终产物是一份绘本式 PDF:
- • 12 页
- • 每页一张插图
- • 每页一条旁白
- • 中文版和英文版都可以导出
 项目里已经有这几份核心文件:
项目里已经有这几份核心文件:
- [00_style.md](./san_da_bai_gu_jing/00_style.md)- [01_scenes.md](./san_da_bai_gu_jing/01_scenes.md)- [02_prompts.md](./san_da_bai_gu_jing/02_prompts.md)- [03_generate.md](./san_da_bai_gu_jing/03_generate.md)
它们不是“文档装饰”,而是整个流水线的输入。
为什么用 Markdown
这套方案的关键,不是“AI 能画图”,而是“内容和流程分离”。
我用 Markdown 做输入,有三个直接好处。
第一,内容可读。
分镜、旁白、风格、角色设定都能直接在文本里看,不需要进数据库、不需要改代码。
第二,流程可控。
你改的是 scene 文本,不是 Python 逻辑。换故事、换语言、换风格,都不必动主程序。
第三,适合自动化。
Markdown 天然适合被解析。只要约定好结构,比如:
- •
#### Scene 1 - •
描述:... - •
旁白:...
程序就能稳定抽取数据。
这比把所有东西硬编码在脚本里要稳得多。
核心原理
这条流水线本质上是一个内容编排器。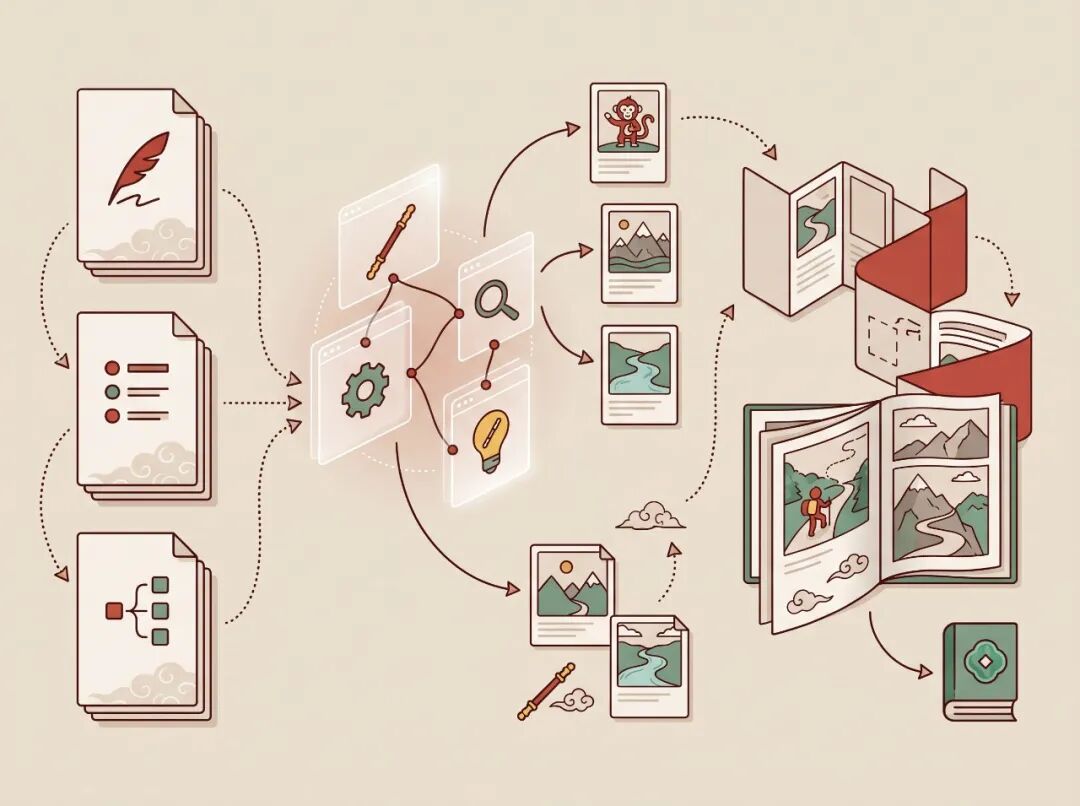
1. 解析分镜
程序先扫描项目里的所有 Markdown 文件,找到 01_scenes.md 里的分镜块。
每个分镜包含:
- • 场景编号
- • 场景描述
- • 旁白
例如:
- • Scene 1:师徒四人走在山路上
- • 旁白:他们一路向西,去寻找真经
这一步的作用是把“人写的故事”变成“机器可处理的数据”。
2. 生成提示词
接下来,程序把三部分内容合并成完整 prompt:
- • 全局画风
- • 角色设定
- • 当前 scene 的内容
这样做的目的,是保证整本书的视觉一致性。
如果每一页都临时手写 prompt,风格会漂,角色会变,画面会散。
如果把全局风格固定下来,再只替换场景内容,模型更容易保持:
- • 人物一致
- • 构图一致
- • 颜色一致
- • 叙事语气一致
3. 生图
这里有两条路:
- • 用 Codex 内置的
image_gen生图 - • 用 OpenAI Image API 走脚本化批量生成
这次我实际采用的是前者,原因很简单:
- • 不需要
OPENAI_API_KEY - • 直接在当前工作流里生成可用图片
- • 适合先把故事书做完,再回到代码层整理流程
从原理上看,两种方式都在做同一件事:把 prompt 变成图像资产。
4. 生成 PDF
最后一步是排版。
我用 reportlab 把每一页的:
- • 插图
- • 旁白
- • 页码
- • 标题
组合成 PDF。
这一步很重要。很多人把“生成图片”当成终点,但真正可交付的成果往往不是图片,而是一本能直接阅读、打印、分享的文档。
我是怎么实践的
这次不是从零瞎写,而是沿着项目现有结构往下做。
第一步:先读现有 Markdown
项目里已经有四份关键文件:
- •
00_style.md:全局画风和角色约束 - •
01_scenes.md:12 个分镜 - •
02_prompts.md:提示词模板 - •
03_generate.md:生成任务说明
这意味着素材本身已经结构化了,程序只需要把它们串起来。
第二步:先做解析器,再做生成器
我先写了一个 Python 脚本,把 Markdown 里的 scene 解析成数据结构。
这样做的好处是,后面的所有步骤都围绕一个统一的数据模型展开。
不是“读一段文本就画一张图”,而是:
-
- 读 scene
-
- 生成 prompt
-
- 产出 image
-
- 写 PDF page
每一步都可单独验证。
第三步:先跑 dry-run
在正式出图前,我先用占位图跑通了整条链路。
这个动作看起来朴素,但很关键。
它能确认:
- • scene 是否能正确解析
- • prompt 是否能正确渲染
- • PDF 是否能生成
- • 页数是否对齐
先把管线打通,再把占位图替换成真图,风险最低。
第四步:再用 Codex 生图替换占位图
接着我用 Codex 的内置生图能力,逐张生成 12 张绘本图。
每一张图都落到项目目录里,再由 PDF 生成器读取。
这样整个项目就没有依赖临时文件,也没有把“生成资产”留在工作区外。
第五步:补英文版
中文版跑通之后,我又加了英文旁白和英文标题输出。
这一步不是简单翻译,而是把“同一套视觉资产”变成“双语可交付版本”。
最后又遇到了一个典型问题:
- • 英文页文字看起来折叠、挤压
原因不是内容本身,而是 PDF 字体选错了。
我把英文页改成 Helvetica,问题就消失了。
这就是工程上的真实过程:你以为是在修文案,实际上是在修字体和渲染链。
这套流程的价值
这类项目真正值得复用的,不是“做了一本书”,而是这几个原则。
1. 内容和生成解耦
故事内容放 Markdown,生成逻辑放 Python。
以后换成别的题材,比如:
- • 儿童绘本
- • 企业案例集
- • 产品手册
- • 双语故事集
都只需要换内容文件,不需要重写流程。
2. 风格和场景分离
风格定义只写一次,scene 只描述变化。
这样才能保证整本书是“同一本”,而不是“十二张各自独立的图”。
3. 先验证 pipeline 管线,再追求质量
先跑通,再优化。
先确认能导出 PDF,再去调 prompt。
先确认版式正常,再去纠结艺术风格。
这比一开始就追求完美更有效。
4. 输出要能交付
只会出图还不够,最终交付物最好是:
- • 可打印
- • 可分享
- • 可二次编辑
- • 可复现
PDF 正好符合这个目标。
怎么用这套项目
现在这套流程已经能直接跑。
生成中文 PDF
直接用现成图片生成 PDF:
python3 storybook_pipeline.py --use-existing-images
输出会在:
- •
build/storybook/san_da_bai_gu_jing_storybook.pdf
生成英文 PDF
如果要英文版:
python3 storybook_pipeline.py --language en --use-existing-images
输出会在:
- •
build/storybook/san_da_bai_gu_jing_storybook_en.pdf
重新生成图片和 PDF
如果你想改图,再重新走整条链路,可以切回生图模式。
当前项目里保留了两条思路:
- • Codex 内置生图,适合直接在当前工作流里生产图片
- • OpenAI API 路径,适合批处理和脚本化接入
改故事内容
如果要换一个故事,只需要改这些 Markdown:
- •
00_style.md - •
01_scenes.md - •
02_prompts.md
程序会自动重新解析并生成新的页面。
一个值得注意的工程细节
很多人第一次做这类项目,注意力会放在“生图是不是更像原著风格”上。
但真正容易出问题的,往往是后半段:
- • 图片尺寸不统一
- • 版面溢出
- • 字体不兼容
- • 英文显示变形
- • PDF 页数和 scene 数不一致
所以这次我特意把流程拆开,让每一层都能单独检查。
事实证明,管线越清晰,返工越少。
结语
这次做的不是单张图,而是一套可重复生产绘本的最小系统。
它的逻辑很简单:
- • Markdown 管内容
- • prompt 管风格
- • Codex 管生图
- • Python 管编排
- • PDF 管交付
如果以后继续扩展,这套结构还能往下长:
- • 增加更多章节
- • 输出更多语言版本
- • 换成不同题材
- • 加封面和目录
- • 加自动排版和校验
真正有价值的不是某一张图,而是这条可持续复用的生产链。
2026.05.08 22:16
沪·赵巷
📌 声明:本文由 AI 辅助完成

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)