AI-常见的AI概念
AI时代
文章目录
一、基础核心概念
Token(词元)
定义: LLM处理文本的最小单位,可以是一个字、一个词或一个词的一部分。
关键点:
- 中文通常1-2个字=1个Token,英文约4个字符=1个Token
- Token数量直接影响API调用成本和模型响应速度
- 不同模型使用不同的Tokenizer(分词器),如GPT系列用tiktoken、Claude用自己的分词器
- 常见估算规则:1个中文字≈1.5-2 Token,1个英文单词≈1-2 Token
实际应用:
- 评估输入/输出长度是否超出限制
- 计算API调用费用(按Token计费)
- 优化Prompt以减少Token消耗
Context(上下文)
定义: 模型在一次对话中所能"看到"的所有信息,包括系统提示、用户消息、历史对话、工具返回结果等。
关键点:
- Context是模型生成回答时的"工作记忆"
- 包含:System Prompt + User Prompt + Assistant回复历史 + 工具调用结果
- Context越长,模型能参考的信息越多,但计算成本也越高
- 超出Context Window的内容会被截断或遗忘
Context Window(上下文窗口)
定义: 模型单次能处理的最大Token数量上限。
常见模型的Context Window大小:
| 模型 | Context Window |
|---|---|
| GPT-3.5-turbo | 16K |
| GPT-4o | 128K |
| GPT-4-turbo | 128K |
| Claude 3.5 Sonnet | 200K |
| Claude 3 Opus | 200K |
| Gemini 1.5 Pro | 1M-2M |
关键点:
- Context Window = 输入Token + 输出Token 的总和
- 长上下文不等于长记忆——模型可能无法有效利用全部上下文("Lost in the Middle"现象)
- 实际可用空间需要预留输出Token的余量
LLM(大语言模型)
定义: Large Language Model,基于深度学习的大规模语言模型,通过海量文本数据训练而成。
核心能力:
- 文本理解与生成
- 知识问答与推理
- 代码编写与调试
- 多语言翻译
- 摘要与创作
代表模型:
- OpenAI: GPT-4, GPT-4o, GPT-3.5
- Anthropic: Claude 3.5 Sonnet, Claude 3 Opus
- Google: Gemini Pro/Ultra
- Meta: LLaMA 系列
- 国产: DeepSeek, Qwen, GLM, Yi 等
技术架构:
- 基于 Transformer 架构
- 核心机制:Attention(注意力机制)
- 训练阶段:预训练(Pre-training) → 微调(Fine-tuning) → 对齐(RLHF/DPO)
二、提示词工程(Prompt Engineering)
Prompt(提示词)
定义: 用户发送给AI模型的指令或问题,用于引导模型产生期望的输出。
优质Prompt的核心要素:
- 明确的角色设定 — “你是一位资深Python工程师”
- 具体的任务描述 — “帮我写一个爬虫脚本”
- 清晰的格式要求 — “请用表格形式输出”
- 提供示例(Few-shot) — 给出输入输出的范例
- 约束条件 — “不超过200字”、“使用通俗语言”
常用技巧:
- Chain of Thought(思维链):引导模型逐步推理
- Few-shot Learning:提供少量示例
- Role Playing:赋予角色身份
- Structured Output:指定输出格式(JSON、Markdown等)
User Prompt(用户提示词)
定义: 对话中用户侧发送的消息内容,是用户与AI交互的主要载体。
特点:
- 是每次对话轮次中的"输入"
- 可以包含文本、代码、指令等多种内容
- 在多轮对话中,User Prompt会累积在Context中
- 支持多模态输入(图片、文件等,取决于模型能力)
最佳实践:
- 避免歧义表达,尽量具体明确
- 合理组织信息结构,长任务可分段进行
- 利用分隔符区分不同部分的内容
System Prompt(系统提示词)
定义: 在对话开始时设置的"隐藏指令",用于定义AI的行为规范、角色定位和能力边界。
作用:
- 设定AI的人格和角色(“你是一个专业的翻译助手”)
- 定义输出风格和语气(“用简洁的语言回答”)
- 约束行为边界(“不要编造不确定的信息”)
- 提供背景知识和领域专长
与User Prompt的区别:
| 维度 | System Prompt | User Prompt |
|---|---|---|
| 优先级 | 高(覆盖默认行为) | 低(具体请求) |
| 可见性 | 用户不可见(通常) | 用户可见 |
| 作用范围 | 全局生效 | 单次请求 |
| 典型用途 | 角色设定、行为约束 | 具体任务、问题提问 |
进阶用法:
- 使用XML标签结构化组织(
<rules>...</rules>) - 分层设计:角色层 + 技能层 + 约束层
- 动态注入:根据场景切换不同的System Prompt
三、Agent(智能体)体系
Agent(智能体/代理)
定义: 能够自主感知环境、规划任务、使用工具完成目标的AI系统。Agent = LLM + 记忆 + 规划 + 工具使用。
核心组件:
┌─────────────────────────────────────┐
│ Agent 架构 │
├─────────────────────────────────────┤
│ 🧠 LLM (大脑) │
│ - 理解指令 │
│ - 推理决策 │
│ - 生成行动 │
├─────────────────────────────────────┤
│ 📝 Memory (记忆) │
│ - 短期记忆:当前对话上下文 │
│ - 长期记忆:向量数据库/RAG │
│ - 工作记忆:任务执行状态 │
├─────────────────────────────────────┤
│ 🗺️ Planning (规划) │
│ - 任务分解 │
│ - 步骤排序 │
│ - 自我反思与修正 │
├─────────────────────────────────────┤
│ 🔧 Tools (工具) │
│ - API调用 │
│ - 代码执行 │
│ - 搜索引擎 │
│ - 文件操作 │
│ - 数据库查询 │
└─────────────────────────────────────┘
Agent vs 传统LLM的区别:
| 能力 | 传统LLM | Agent |
|---|---|---|
| 回答问题 | ✅ | ✅ |
| 使用工具 | ❌ | ✅ |
| 多步推理 | 弱 | ✅ 强 |
| 自主规划 | ❌ | ✅ |
| 记忆持久化 | ❌ | ✅ |
| 错误自修复 | ❌ | ✅ |
主流Agent框架:
- LangChain / LangGraph
- AutoGPT
- BabyAGI
- CrewAI
- MetaGPT
- OpenClaw (QClaw)
- Dify
- Coze (扣子)
Agent Skill(智能体技能)
定义: 封装了特定领域能力和知识的专业模块,可以被Agent动态加载和调用,使Agent具备专业化的任务执行能力。
Skill的本质:
- 一套结构化的指令(SKILL.md)+ 可选的工具/脚本
- 类似于人类的"专业技能"或"职业技能"
- 让通用Agent变成领域专家
Skill的组成:
skill-name/
├── SKILL.md # 技能说明文档(必填)
├── scripts/ # 辅助脚本(可选)
├── templates/ # 模板文件(可选)
└── resources/ # 资源文件(可选)
Skill的类型:
- 工具类Skill:封装外部工具的使用方法(如搜索、邮件、浏览器)
- 知识类Skill:注入领域专业知识(如法律、医疗、金融)
- 流程类Skill:定义标准化的工作流程(如代码审查、文章写作)
- 人格类Skill:定义特定的行为模式和沟通风格
Skill的实际价值:
- 解耦能力与框架,便于复用和共享
- 降低Agent的开发门槛
- 支持按需加载,节省资源
- 社区生态驱动,持续进化
MCP(Model Context Protocol)
定义: 由Anthropic提出的开放协议标准,用于统一AI模型与外部工具/数据源之间的连接方式。
核心目标:
- 标准化Model与Tool之间的通信协议
- 解决"每个工具都要写适配器"的问题
- 实现一次开发,到处运行
MCP架构:
┌─────────┐ ┌─────────┐ ┌─────────┐
│ LLM/ │ │ MCP │ │ 外部 │
│ Agent │◄──► │ Server │◄──► │ 工具/ │
│ │ │ (Host) │ │ 数据源 │
└─────────┘ └─────────┘ └─────────┘
│
▼
┌─────────────┐
│ MCP Client │
└─────────────┘
MCP的核心概念:
- Resource(资源):外部数据源(文件、数据库、API等)
- Tool(工具):可调用的功能(搜索、执行命令等)
- Prompt Template(提示模板):预定义的提示词模板
- Server(服务端):提供资源和工具的服务程序
- Client(客户端):连接Server的接口层
类比理解:
- MCP之于AI ≈ USB之于电脑
- 统一接口标准,任何符合MCP规范的工具都可以即插即用
主流MCP实现:
- Filesystem MCP(文件操作)
- Database MCP(数据库访问)
- Web Search MCP(网络搜索)
- GitHub MCP(代码仓库操作)
- Browser MCP(浏览器控制)
Tool(工具)
定义: Agent可以调用的外部功能模块,扩展了LLM纯文本交互的能力边界。
工具类型:
| 类型 | 示例 | 用途 |
|---|---|---|
| 🔍 搜索工具 | Google/Bing API | 获取实时信息 |
| 💻 代码执行 | Python/Shell解释器 | 运行代码验证 |
| 🌐 浏览器控制 | Playwright/Selenium | 操作网页 |
| 📧 通信工具 | Email/Slack API | 发送消息 |
| 📊 数据工具 | SQL/CSV处理 | 数据分析 |
| 📁 文件工具 | 读写/编辑文件 | 文档处理 |
| 🎨 创意工具 | DALL-E/Midjourney | 图像生成 |
工具调用的基本流程:
- 用户提出需求
- LLM判断是否需要调用工具
- 选择合适的工具并生成调用参数
- 执行工具调用,获取结果
- 将结果融入Context,继续推理
- 生成最终回答
Function Calling / Tool Use:
- 模型原生支持的结构化工具调用方式
- 模型输出JSON格式的函数名和参数
- 系统负责执行并将结果返回给模型
四、增强技术
RAG(检索增强生成)
定义: Retrieval-Augmented Generation,结合信息检索和文本生成的技术范式。
工作原理:
用户提问 → 向量检索相关文档 → 将检索结果注入Prompt → LLM生成回答
RAG的核心组件:
- 索引阶段:文档→分块→向量化→存入向量数据库
- 检索阶段:Query向量化→相似度搜索→取Top-K结果
- 生成阶段:将检索到的内容作为上下文→LLM生成答案
RAG的价值:
- 解决LLM知识滞后问题(可随时更新知识库)
- 减少模型幻觉(基于真实文档回答)
- 支持私有数据问答(企业内部知识库)
- 可追溯答案来源
RAG vs Fine-tuning:
| 维度 | RAG | Fine-tuning |
|---|---|---|
| 知识更新 | ✅ 实时更新 | ❌ 需重新训练 |
| 可解释性 | ✅ 可溯源 | ⚠️ 黑盒 |
| 私有数据 | ✅ 支持 | ✅ 支持 |
| 成本 | 💚 低 | 🔴 高 |
| 适用场景 | 知识问答 | 风格/格式适配 |
向量数据库(Vector Database)
定义: 专门用于存储和检索高维向量数据的数据库系统,是RAG技术的核心基础设施。
核心概念:
- Embedding(嵌入):将文本/图像转换为高维向量表示
- 相似度搜索:通过向量之间的距离度量语义相似性
- Index(索引):加速向量检索的数据结构(IVF、HNSW、PQ等)
主流向量数据库:
| 数据库 | 特点 |
|---|---|
| Pinecone | 全托管云服务,易上手 |
| Milvus | 开源,性能强,支持大规模 |
| Weaviate | 开源,内置向量化pipeline |
| ChromaDB | 轻量级,适合本地开发 |
| Qdrant | Rust编写,高性能 |
| FAISS | Meta开源,纯向量检索库 |
| Elasticsearch | 8.0+原生支持向量 |
应用场景:
- 语义搜索引擎
- 推荐系统
- RAG知识库
- 图像/视频相似度检索
- 异常检测
记忆化搜索(Memorized Search / Memory Search)
定义: 基于存储的历史交互记录和知识进行检索的技术,让AI能够"记住"之前的对话内容和学到的知识。
记忆的层次:
| 层次 | 说明 | 实现方式 |
|---|---|---|
| 短期记忆 | 当前对话上下文 | Context Window |
| 长期记忆 | 跨会话持久化知识 | 向量数据库 + RAG |
| 工作记忆 | 任务执行过程中的状态 | State Management |
| 情景记忆 | 特定事件/经历 | 向量检索 + 时间戳 |
| 语义记忆 | 通用知识和事实 | Knowledge Graph |
记忆系统的关键技术:
- 记忆写入:判断什么值得记住(重要性评分)
- 记忆检索:根据当前需求找到相关记忆
- 记忆压缩:对旧记忆进行摘要和提炼
- 记忆遗忘:定期清理过时或低价值的记忆
五、训练与优化技术
Fine-tuning(微调)
定义: 在预训练模型的基础上,使用特定领域的数据进行二次训练,使模型适应特定任务或领域。
微调类型:
- 全量微调(Full Fine-tuning):更新所有模型参数
- 高效微调(PEFT):只更新少量参数
- LoRA(Low-Rank Adaptation):低秩矩阵适应
- QLoRA:量化+LoRA,显存需求更低
- Adapter Tuning:添加小型适配器模块
- Prompt Tuning:只优化软提示(Soft Prompt)
何时选择Fine-tuning而非RAG:
- 需要改变模型的输出风格/格式
- 领域术语和表达方式特殊
- 需要降低延迟(不需要检索步骤)
- 数据量足够且质量高
RLHF(基于人类反馈的强化学习)
定义: Reinforcement Learning from Human Feedback,通过人类偏好数据来对齐模型行为的训练方法。
训练流程:
预训练模型 → SFT(有监督微调)→ 奖励模型训练 → PPO强化学习优化
三阶段流程:
- SFT(Supervised Fine-Tuning):用高质量问答数据微调
- Reward Modeling:训练奖励模型,学习判断回答好坏
- RL Optimization(PPO):用强化学习最大化奖励
RLHF的作用:
- 让模型输出更符合人类价值观
- 减少有害、偏见内容
- 提升回答的有用性和诚实性
- ChatGPT之所以"好用"的关键技术之一
替代方案:DPO(Direct Preference Optimization)
- 直接从偏好数据优化,跳过奖励模型训练
- 更简单、更稳定、计算成本更低
Prompt Caching(提示缓存)
定义: 缓存Prompt中的静态部分(如System Prompt、大量文档),避免重复处理相同内容,降低延迟和成本。
适用场景:
- 长System Prompt(如完整的Agent指令)
- 批量处理多个用户的相同前缀请求
- 多轮对话中的历史消息复用
- RAG中固定的参考文档
效果:
- 显著降低Token处理成本(最高可达50%以上折扣)
- 减少首Token延迟(Time to First Token)
- 特别适合大规模生产环境
六、高级架构模式
ReAct(Reasoning + Acting)
定义: 一种Agent推理模式,交替进行"思考(Reasoning)“和"行动(Acting)”,让Agent在执行过程中不断反思和调整。
ReAct循环:
Thought(思考)→ Action(行动)→ Observation(观察)→ Thought(思考)→ ...
示例:
Thought: 用户想知道今天北京天气,我需要调用天气API
Action: call_weather_api(city="北京")
Observation: 北京今天晴,气温25°C
Thought: 已获取天气信息,可以回答用户了
Answer: 北京今天天气晴朗,气温25°C,适合外出!
Chain-of-Thought(思维链/CoT)
定义: 引导模型逐步展示推理过程,而不是直接给出最终答案。
CoT的效果:
- 显著提升复杂推理任务的准确率
- 让推理过程可解释、可审查
- 减少"跳跃式"错误推理
CoT变体:
- Zero-shot CoT:“让我们一步步思考”
- Few-shot CoT:提供带推理过程的示例
- Self-Consistency:多次采样取多数投票
- Tree-of-Thought(ToT):探索多条推理路径
Multi-Agent System(多智能体系统)
定义: 多个Agent协作完成复杂任务的系统架构,每个Agent专注特定角色。
常见模式:
- 流水线模式:Writer → Reviewer → Editor
- 辩论模式:多个Agent讨论后达成共识
- 层级模式:Manager分配任务给Worker
- 角色分工:程序员+测试+产品经理+设计师
优势:
- 任务专业化,各司其职
- 互相审核,减少错误
- 并行处理,提高效率
- 模拟真实团队协作
代表框架:
- CrewAI:角色扮演式的多Agent编排
- MetaGPT:模拟软件公司的多Agent系统
- AutoGen(微软):多Agent对话框架
- LangGraph:基于图的多Agent工作流
Function Calling / Tool Use(函数调用/工具使用)
定义: LLM原生支持的、结构化地调用外部函数的能力。
工作机制:
- 在System/User Prompt中声明可用的工具(名称、参数描述)
- 模型根据用户意图决定是否调用工具
- 模型输出结构化的函数调用请求(JSON格式)
- 系统执行函数并返回结果
- 模型基于函数返回结果生成最终回答
关键技术点:
- 模型需要理解工具的功能和参数要求
- 参数提取和类型转换要准确
- 支持并行调用多个工具
- 支持工具调用的嵌套和链式调用
七、评估与安全
Hallucination(幻觉)
定义: 模型生成看似合理但实际上虚假或不准确的内容的现象。
幻觉类型:
- 事实性幻觉:编造不存在的事实、数据、引用
- 忠实性幻觉:偏离提供的上下文或源材料
缓解策略:
- RAG(基于检索的真实文档回答)
- 设定温度参数(Temperature设低减少随机性)
- 明确告知模型"不知道就说不知道"
- 事实核查与引用来源
Temperature(温度参数)
定义: 控制模型输出随机性的参数,值越低输出越确定,值越高输出越有创造性。
典型值设置:
| 场景 | Temperature推荐值 |
|---|---|
| 事实性问答、代码生成 | 0.0 - 0.3 |
| 一般对话、翻译 | 0.5 - 0.7 |
| 创意写作、头脑风暴 | 0.8 - 1.2 |
| 高度创意(诗歌等) | 1.0 - 1.5 |
Guardrails(护栏/安全防护)
定义: 用于确保AI系统安全、合规运行的防护机制。
常见护栏措施:
- 输入过滤:检测恶意Prompt注入
- 输出过滤:过滤有害、不当内容
- 主题限制:限定AI的回答范围
- 速率限制:防止滥用
- 审计日志:记录所有交互以便审查
Evaluation(模型评估)
定义: 系统性地衡量AI模型或Agent表现的过程。
评估维度:
| 维度 | 说明 |
|---|---|
| 准确性 | 回答的正确程度 |
| 相关性 | 回答与问题的匹配度 |
| 连贯性 | 回答的逻辑一致性 |
| 有用性 | 对用户实际帮助的大小 |
| 安全性 | 是否包含有害内容 |
| 效率 | 响应速度和资源消耗 |
评估方法:
- 人工评估:专家打分(最可靠但成本高)
- 自动化评估:使用评判模型(如GPT-4当裁判)
- 基准测试:在标准数据集上测试(MMLU、HumanEval、GSM8K等)
- A/B测试:对比不同版本的表现
八、多模态与新兴方向
Multimodal Model(多模态模型)
定义: 能够同时理解和生成多种类型内容(文本、图像、音频、视频)的AI模型。
代表模型:
- GPT-4V / GPT-4o:文本+图像理解
- Gemini Pro/Vision:Google的多模态模型
- Claude 3:支持图像输入
- Whisper(语音转文字)、TTS(文字转语音)
- Sora(文生视频)、Runway Gen-3
- Midjourney / DALL-E / Stable Diffusion(文生图)
Embedding(嵌入/向量化)
定义: 将离散的数据(文本、图像等)转换为连续的高维向量表示,使得语义相近的内容在向量空间中距离也更近。
应用:
- 语义搜索
- 文本聚类
- 推荐系统
- RAG检索
- 异常检测
主流Embedding模型:
- OpenAI: text-embedding-3-small/large
- Cohere: embed-v3/v4
- BGE(智源):中文优秀
- MokaAI: m3e(开源中文首选之一)
Knowledge Graph(知识图谱)
定义: 用图结构表示实体及其之间关系的知识库,由节点(实体)和边(关系)组成。
在AI中的作用:
- 为RAG提供结构化知识补充
- 提升事实准确性
- 支持复杂的关系推理
- 可解释性强(推理路径可视化)
与向量检索的结合:
- 图谱+向量混合检索(GraphRAG)
- 先图谱精确匹配,再向量模糊召回
- 知识图谱作为RAG的后验校验
九、部署与工程实践
Inference(推理)
定义: 使用训练好的模型对新数据进行预测/生成的过程,也就是我们日常"调用AI"时发生的事情。
推理优化技术:
- 量化(Quantization):降低数值精度(FP16→INT8→INT4),减少显存和加速
- 蒸馏(Distillation):用大模型教小模型,获得更快更便宜的模型
- 剪枝(Pruning):移除不重要的模型参数
- KV Cache:缓存注意力计算的中间结果,加速自回归生成
- Speculative Decoding(推测解码):用小模型草拟,大模型验证,加速生成
- Continuous Batching:动态批处理,提升GPU利用率
LoRA(Low-Rank Adaptation)
定义: 一种参数高效的微调方法,通过在模型中注入低秩矩阵来适配新任务,只需训练极少量的参数。
优势:
- 只需训练原模型参数量的0.1%-1%
- 显存需求大幅降低
- 可快速切换不同LoRA适配器
- 支持LoRA组合/合并
流行平台:
- Hugging Face PEFT
- Axolotl
- Unsloth(极速LoRA训练)
Quantization(量化)
定义: 降低模型权重的数值精度(如从32位浮点数降到4位整数),以减小模型体积、降低显存需求、加速推理。
量化级别:
| 精度 | 表示 | 大小缩减 | 质量损失 |
|---|---|---|---|
| FP32 | 原始精度 | 1x(基准) | 无 |
| FP16/BF16 | 半精度 | ~2x | 极小 |
| INT8 | 8位整数 | ~4x | 很小 |
| INT4 | 4位整数 | ~8x | 小 |
| 乃至 INT2/INT3 | 极限量化 | 更大 | 明显 |
主流量化工具:
- GPTQ、AWQ、GGUF(最流行的本地部署格式)
- bitsandbytes
- llama.cpp(支持GGUF量化)
vLLM / TGI / Ollama(推理框架/服务)
定义: 高性能的大模型推理服务和部署框架。
| 框架 | 特点 |
|---|---|
| vLLM | 高吞吐、PagedAttention、OpenAI兼容API |
| TGI(HuggingFace) | 文本生成推理、易于部署 |
| Ollama | 本地运行大模型的最简单方式 |
| LM Studio | GUI界面的本地模型运行工具 |
| LocalAI | OpenAI API兼容的本地推理服务 |
十、概念关系总览
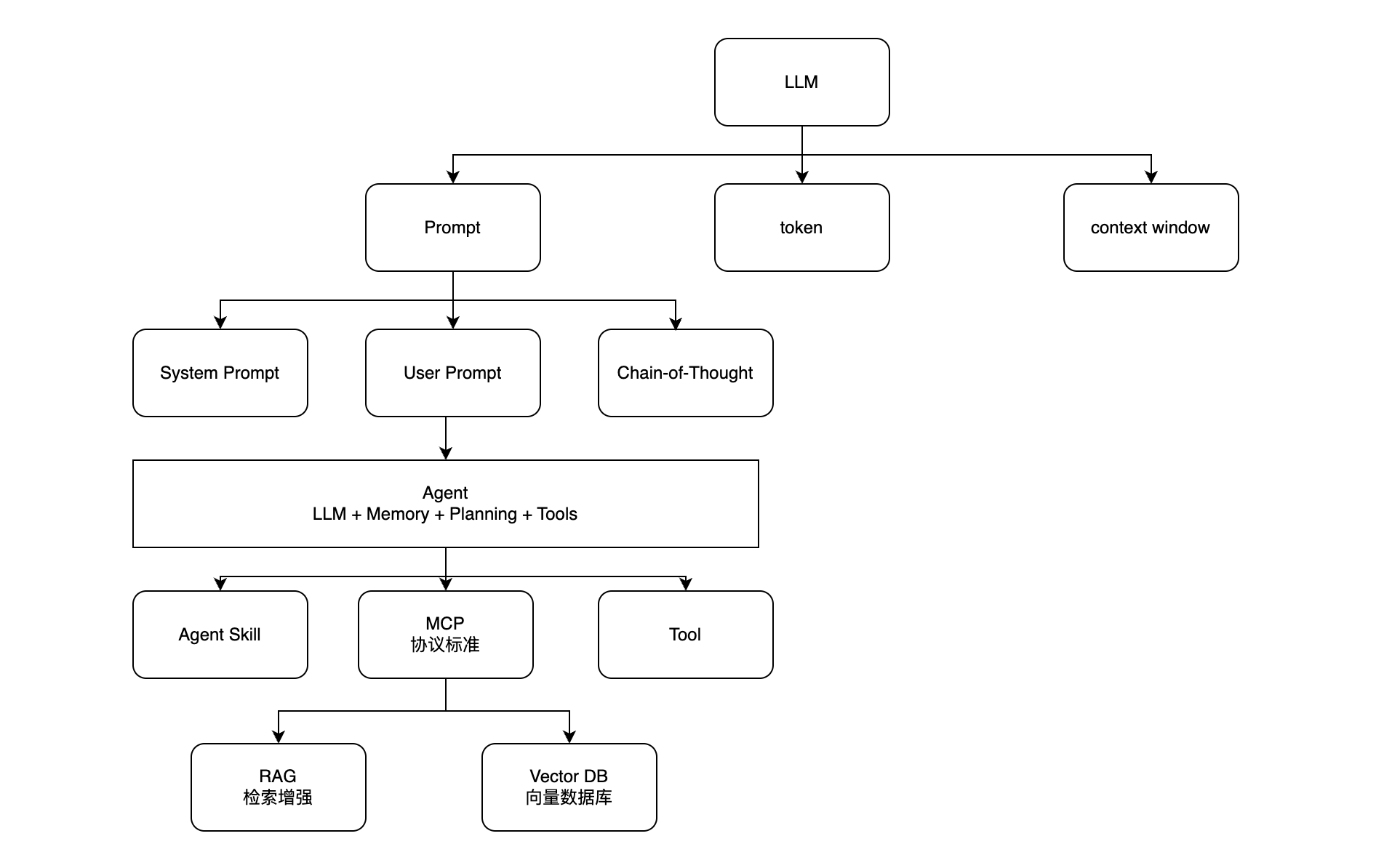
参考来源:B站视频《从 LLM 到 Agent Skill,一期视频带你打通底层逻辑!》+ AI概念思维导图整理

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)