AI 时代真正贵的不是模型,而是基础设施的确定性
AI 时代真正贵的不是模型,而是基础设施的确定性
这两天几个看起来不相干的热点,其实在讲同一件事。
玻璃硬盘量产,说的是冷数据怎么长期保存。SK 海力士发高额奖金、三星员工因待遇落差拟罢工,说的是 HBM 和 AI 存储利润如何重新分配。政治局会议提到水网、新型电网、算力网、新一代通信网、物流网,说的是未来几年最缺的底层能力在哪里。
这些事放在一起看,会发现 AI 行业正在从模型热闹,进入基础设施算账。
过去一年,大家更容易被模型名、参数、榜单、发布会吸引。哪个模型更聪明,哪个工具更便宜,哪个 Agent 演示更丝滑。但真正进入规模化应用后,问题会变得朴素:算力够不够,内存供不供得上,电价扛不扛得住,数据怎么存,网络怎么调度,故障怎么恢复。
模型只是前台,基础设施才是后台。
图一|AI 成本从模型扩散到基础设施

算力不是一张显卡的事。
一套 AI 系统需要 GPU,也需要 HBM、服务器、交换机、存储、机房、供电、散热和运维。训练模型时,瓶颈可能在 GPU;推理规模上来后,瓶颈可能变成显存、网络、延迟、电费和调度效率。很多团队一开始以为自己是在买模型能力,后来才发现自己是在买整条基础设施链的确定性。
这也是 HBM 变得这么重要的原因。AI 服务器不是只看峰值算力,数据能不能快速喂给芯片,决定了算力会不会空转。SK 海力士吃到的红利,本质上是它卡住了 AI 服务器里最紧的存储环节之一。奖金争议只是表面,背后是利润从传统消费电子链条转向 AI 基础设施链条。
一旦某个环节从普通零部件变成瓶颈,它就会重新定价。企业会重新分配资本,员工会重新比较薪酬,客户会提前锁定订单,竞争对手会加速追赶。
图二|AI 基础设施的四个瓶颈

存储也在被重新理解。
很多人谈 AI 存储,只想到训练数据集和向量数据库。但真实系统里,数据分很多层:模型训练数据、用户交互日志、审计记录、知识库文件、推理缓存、业务归档、冷备份。热数据追求速度,冷数据追求耐久,合规数据追求可追溯,业务数据追求能被再次调用。
玻璃硬盘这类长期归档介质,不会替代个人电脑的 SSD,也不适合每天改来改去。但它提醒我们,数据增长到一定规模后,保存本身就是成本。一个机构真正害怕的不是今天硬盘不够大,而是十年后介质老化、格式迁移、设备停产、校验缺失,导致关键数据找不回来。
AI 越深入行业,这类问题越多。医疗影像、城市治理、工业质检、科研实验、金融风控、自动驾驶数据,都不是用完就删。数据生命周期越长,冷存储和归档系统就越重要。
电力和网络则决定 AI 能不能从少数大厂能力变成普遍生产力。
如果算力集中在少数园区,网络延迟高,调度系统弱,电力成本波动大,中小企业用 AI 的成本就很难稳定。很多 AI 应用不是技术上做不出来,而是用起来太贵、太慢、太不确定。所谓算力网、新型电网、新一代通信网,真正要解决的是让算力像基础设施一样被调度,而不是让每家公司都从零买一套昂贵机器。
图三|从模型能力到交付确定性
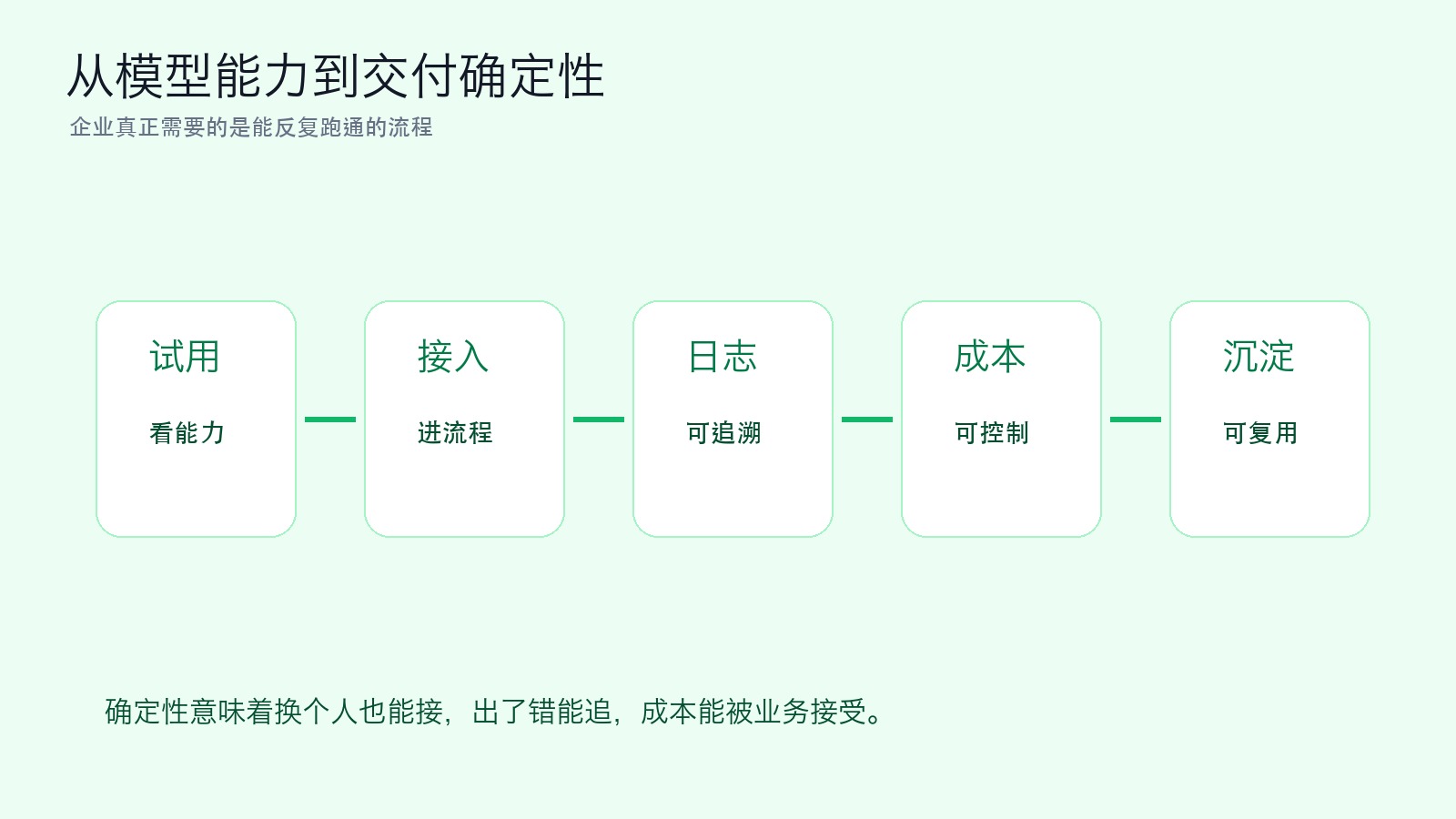
对个人和小团队来说,这个趋势有一个很实际的提醒:不要把 AI 能力只理解成会用某个工具。
未来的竞争会越来越像工程能力竞争。你能不能把数据整理好,能不能选择合适的模型,能不能控制调用成本,能不能保留日志,能不能在出错时回滚,能不能把结果沉淀成流程。这些能力不如模型发布会亮眼,但它们决定 AI 能不能稳定交付。
对企业来说,也不能只追最新模型。真正要评估的是:哪些业务值得用 AI,数据是否能合规进入系统,推理成本能不能被业务承受,供应商是否稳定,关键数据怎么备份,出了问题谁负责。
AI 时代真正贵的,往往不是某一次模型调用,而是不确定性。
算力不确定,会拖慢产品节奏;存储不确定,会带来数据风险;电力不确定,会推高运营成本;网络不确定,会影响用户体验;组织分配不确定,会让关键人才流动。模型能力当然重要,但当模型能力逐渐商品化,谁能把基础设施、数据和流程做成稳定系统,谁才会把 AI 用成长期优势。
所以这轮热点给人的启发并不玄。玻璃硬盘提醒我们数据会长期存在,HBM 奖金提醒我们瓶颈环节会拿走利润,新型基础设施提醒我们 AI 不是漂在云上的魔法。
它最终会落到很硬的东西上:电、网、芯片、存储、机房、标准、运维和人。谁把这些硬东西组织好,谁才真正拥有 AI 的确定性。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)