从 TDD 到 SDD:当“代码”不再是核心资产,软件工程正在发生什么变化?
目录
- 序言
- 第那些“DD”到底是什么?——从测试到规范的五种开发视角
- 从 “Vibe Coding” 到规范化——问题是怎么暴露出来的?
- 进阶:工具化的 Spec
- OpenSpec vs Spec Kit:两种“工具化 Spec”的路线
- OpenSpec笔记
- Spec Kit(Speckit)笔记
- ❓ FAQ(常见问题)
-
- Q1:OpenSpec 和普通“AI 写代码”有什么区别?
- Q2:OpenSpec的这些 `/opsx:` 命令是在终端运行的吗?
- Q3:OpenSpec必须按完整流程走吗?
- Q4:OpenSpec 会不会自动帮我写完整项目?
- Q5:OpenSpec中sync 和 archive 有什么区别?
- Q6:OpenSpec 是不是必须配 AI 才能用?
- Q7:Claude Code 登录失败怎么办?
- Q8:Spec Kit 和 OpenSpec 有什么区别?
- Q9:Spec Kit 和 TDD 有什么关系?
- Q10:`specify-cli` 安装失败怎么办?
- Q11:Spec Kit 适合什么项目?
- Q12:Spec Kit 会不会限制开发自由度?
- Q13:Spec Kit 和 OpenSpec 可以一起用吗?
- Q14:SDD(Spec-Driven Development)和各大厂商的 Plan 模式有什么区别?
- 🧩 结尾
序言
过去二十年,软件开发方法论层出不穷。从 Kent Beck 提出的 TDD,到 Dan North 推动的 BDD,再到 Eric Evans 构建的 DDD 体系,这些方法试图解决同一个问题:如何让软件开发从混乱走向可控。
它们分别从不同角度给出了答案。TDD试图用测试约束代码的正确性,BDD试图用行为统一业务与开发的理解,而DDD则进一步将焦点上移,试图让软件结构本身映射真实世界的业务领域。在没有AI的时代,这些方法已经构成了一套相对完整的软件工程实践体系。
但今天,事情开始发生变化。
随着以 Anthropic 的 Claude Code 等工具为代表的AI编程方式兴起,越来越多的开发者开始直接用自然语言驱动代码生成。我们不再总是从“写代码”开始,而是从“描述需求”开始。代码,正在逐渐从“生产目标”变成“中间产物”。
这带来了一个新的问题:当代码可以被生成,我们还需要过去这些方法论吗?如果需要,它们的位置又在哪里?
在这样的背景下,一个新的概念开始被频繁提起——SDD(Specification-Driven Development)。它试图进一步前进:不只是用测试或行为约束代码,而是让“规范”本身成为唯一的事实来源,让代码成为规范的投影。
问题也随之而来:SDD是对TDD、BDD、DDD的继承,还是对它们的替代?这些看似纷繁复杂的“DD”,究竟各自解决了什么问题,又处在软件工程的哪个层级?
这篇文章不会简单罗列概念,而是试图回答一个更本质的问题:
在AI已经可以参与甚至主导编码的今天,我们到底应该如何重新理解这些开发方法论?
第那些“DD”到底是什么?——从测试到规范的五种开发视角
如果你在过去几年里接触过软件工程方法论,很可能会被一堆缩写包围:TDD、BDD、ATDD、DDD,甚至最近开始出现的SDD。
它们看起来像一条演进路线,但实际情况并没有那么简单。这些“DD”并不是简单的替代关系,而是分别站在不同层级,试图解决软件开发中的不同问题。
要理解它们,最好的方式不是记定义,而是回答四个问题:它是谁提出的?解决什么问题?核心做法是什么?它的局限在哪里?
1. TDD:从“先写代码”到“先写测试”
TDD(Test-Driven Development,测试驱动开发)由 Kent Beck 在2000年前后系统化提出,是极限编程(XP)中的核心实践之一。
它要解决的问题非常直接:在传统开发模式中,测试往往是最后一步,经常被压缩甚至忽略,导致代码质量不可控。
TDD的做法简单而激进:先写测试,再写实现。开发流程通常被总结为三个步骤——红(测试失败)、绿(让测试通过)、重构(优化代码结构)。
换句话说,TDD强迫开发者在写代码之前先思考:这段代码应该“如何被验证”。
这种方式的好处是显而易见的:代码天然具备可测试性,回归风险降低,重构更加安全。但它也有局限——测试用例本质上是对“局部行为”的验证,很难保证整体业务逻辑的正确性。如果方向错了,测试写得再多也只是“高质量地做错事”。
2. BDD:把“测试”换成“行为”
在实践TDD的过程中,Dan North 发现一个有趣的问题:很多开发者和业务人员对“测试”这个词天然排斥,他们更关心的是“系统应该怎么工作”。
于是,BDD(Behavior-Driven Development,行为驱动开发)在2003年前后被提出。
BDD并没有否定TDD,而是换了一种表达方式。它强调用接近自然语言的形式描述系统行为,例如经典的:
Given(某个前提)
When(发生某个行为)
Then(得到某个结果)
这种描述方式有两个重要变化:第一,它让非技术人员也能理解;第二,它把关注点从“代码是否正确”转移到“系统行为是否符合预期”。
BDD的优势在于沟通,它在产品、测试和开发之间建立了一种共享语言。但在实际项目中,如果维护成本过高,这些行为描述文件也可能变成另一种“过时文档”。
3. ATDD:在写代码之前定义“完成标准”
ATDD(Acceptance Test-Driven Development,验收测试驱动开发)常常和BDD一起出现,但它关注的不是“怎么描述”,而是“什么时候算完成”。
它没有一个单一的提出者,而是在2000年代中期随着敏捷开发实践逐渐成熟。
ATDD的核心思想是:在开发开始之前,由产品经理、测试人员和开发人员共同定义“验收标准”(Acceptance Criteria)。这些标准通常会被转化为可执行的测试用例。
你可以把它理解为一种“对齐机制”——在写任何代码之前,团队已经对“什么是完成”达成一致。
相比TDD关注函数级别的正确性,ATDD关注的是系统级别的结果。它解决的是“做没做对”的问题,而不是“代码写得对不对”。
当然,它的挑战也很现实:需要跨角色协作,成本更高,一旦团队沟通机制不成熟,很容易流于形式。
4. DDD:当问题不再是代码,而是业务
如果说前面的几种方法还停留在“怎么写代码”或“怎么验证”,那么DDD(Domain-Driven Design,领域驱动设计)则直接跳到了更高一层。
DDD由 Eric Evans 在2003年提出,其核心观点是:软件的复杂性,往往来自业务本身,而不是技术实现。
它要解决的问题是:为什么系统越做越复杂,代码结构和业务逻辑越来越脱节?
DDD的答案是:让软件结构直接反映业务领域。为此,它引入了一整套概念,例如“通用语言”(Ubiquitous Language)、“限界上下文”(Bounded Context)、“实体”、“值对象”、“聚合”等。
这些概念的目标只有一个——让开发人员和业务人员说的是同一套语言,并且让代码结构与业务模型保持一致。
但DDD的难点也在这里:它不是一个可以“照着做”的流程,而是一种需要持续维护的建模能力。很多团队在建模阶段做得很好,但随着代码演进,很快就偏离了最初的领域模型。
5. SDD:当“规范”成为代码的上游
相比前面几种方法,SDD(Specification-Driven Development,规范驱动开发)并不是一个已经被严格定义的经典方法论,而是近年来,随着AI编程兴起逐渐被提出的一种新思路。
它关注的问题是:当代码可以被生成时,开发的核心还应该是代码吗?
SDD的核心观点是:规范(Specification)才是系统的唯一事实来源,代码只是规范在某种技术栈中的具体实现。在理想状态下,开发者不再直接修改代码,而是修改规范,然后由工具或AI生成对应实现。
这种思路在过去其实已经有雏形,例如API规范生成代码、基础设施即代码(IaC)等。但在AI时代,这种能力被极大放大——像 Claude Code 这样的工具,已经可以根据自然语言或结构化规范生成复杂逻辑。
SDD带来的变化是根本性的:代码不再是“源”,而是“结果”。
当然,它目前仍处于早期阶段,最大的问题在于:如何定义一套足够精确、可执行、可维护的规范。如果规范本身不严谨,那么生成的代码只会放大问题。
它们不是一条线,而是不同层级的答案
回过头来看,这些“DD”其实回答的是不同层面的问题:
TDD关注的是“代码是否正确”,BDD关注的是“行为是否符合预期”,ATDD关注的是“功能是否完成”,DDD关注的是“系统是否反映业务本质”,而SDD则试图回答“在AI时代,代码是否还是核心”。
它们并不是相互替代的关系,而更像是从不同高度,对软件开发复杂性的一次次回应。
从 “Vibe Coding” 到规范化——问题是怎么暴露出来的?
在真正进入 BDD 和 SDD 之前,我们需要先面对一个现实:很多人已经在用 AI 写代码了,但方式其实还停留在一个非常原始的阶段。(包括我自己)
一个很形象的说法叫做:Vibe Coding。
如果直译,它通常会被翻成“凭感觉开发”,但这个翻译多少有点误导。更准确的理解应该是:
用直觉驱动开发,而不是用代码驱动开发。
在这种模式下,开发者不再从“写代码”开始,而是从“描述需求”开始。你只需要用自然语言告诉 AI 你想做什么,剩下的事情交给它完成。
从体验上来说,这种方式非常有吸引力,甚至可以说是很多人第一次真正“掌控开发”的时刻。
它之所以流行,是因为它确实解决了一些长期存在的问题:
首先,自然语言成为了主要接口。你不再需要关心语法、框架或者具体实现细节,甚至不需要知道是用 Python 还是 JavaScript。
其次,注意力被彻底转移到了“业务逻辑”上。你思考的是“我要解决什么问题”,而不是“这段代码怎么写”。
再者,反馈周期极短。功能不对?直接改描述,让 AI 重来一版,而不是自己一点点调试。
最重要的是,它几乎消除了开发门槛。很多原本不会写代码的人,也可以通过描述需求来构建应用。
听起来很美好,对吧?
但问题很快就出现了。
当项目变大之后,Vibe Coding 开始失效
在简单场景下,Vibe Coding 的确高效。但一旦项目复杂度上来,一些结构性问题就会暴露出来。
最典型的,是不精确性。
自然语言本身就是模糊的。例如一句“帮我写一个计算两个数字相加的程序”,对人来说似乎很清楚,但对 AI 来说却存在歧义:是整数?浮点数?是否需要处理异常?有没有边界限制?
这种模糊在小工具中问题不大,但在复杂系统中会不断放大。
第二个问题是不一致性。
在传统开发中,团队通常会维护一套统一的代码风格和设计约束。但在 Vibe Coding 模式下,每一次生成的代码都可能风格不同。一旦你开始手动修补这些差异,就已经在偏离“完全依赖 AI”的初衷。
第三个问题是隐性错误(Bugs)。
AI 生成的代码往往“看起来是对的”,但在边界条件(例如极端输入、异常流程)下可能出现问题。而对于非技术人员来说,这类问题很难被系统性发现。
最后,也是最容易被忽略的一点,是安全性问题。
例如 SQL 注入、XSS 等经典漏洞,在 AI 生成代码中并不罕见。而这些问题往往不会在“功能正常”的情况下暴露出来。
换句话说:
Vibe Coding 很擅长“快速做出一个能跑的东西”,但不擅长“保证这个东西长期可用”。
BDD 与 SDD:让 AI 不再“自由发挥”
当你把这些问题放在一起看,会发现它们其实指向同一个根因:
缺少一套结构化的约束来约定“系统应该是什么样”。
Vibe Coding 本质上是“自由输入 → 自由输出”,它没有强制你把需求描述清楚,也没有机制保证结果的一致性。
而这,正是 BDD 和 SDD 要解决的问题。
BDD(Behavior-Driven Development,行为驱动开发)和 SDD(Specification-Driven Development,规范驱动开发)可以看作是对 Vibe Coding 的一次“收敛”。
它们的共同点在于:不再允许你随意描述需求,而是要求你用结构化的方式表达。
但两者的侧重点不同。
BDD关注的是“行为”,它试图回答:系统在某种情境下应该如何反应。
而SDD关注的是“规范”,它试图回答:系统整体应该满足哪些约束、规则和结构。
BDD:把“随便说”变成“讲清楚”
BDD 的核心形式是一个非常简单的结构:
- Given(前提)
- When(行为)
- Then(结果)
例如,一个购物车功能可以这样描述:
Given 用户进入商品页面
When 用户点击「加入购物车」
Then 系统显示「商品已加入购物车」
相比“帮我写一个购物车功能”,这种描述方式明显更加清晰。
更重要的是,它在无形中做了一件事:强迫你把隐含的前提说出来。
在 AI 开发场景中,我们可以进一步简化流程:
- 你只负责写行为描述
- 测试由 AI 生成
- 代码也由 AI 生成
于是,开发的核心从“写代码”变成了“描述行为”。
仅仅有行为,有时候还不够。
AI 很依赖上下文,如果缺少背景信息,它仍然可能“理解跑偏”。这时候,引入 User Story 会非常有效。
一个典型的 User Story 结构是:
我是 <某种用户>,我想要 <某个功能>,以便于 <某个目的>
例如:
我是一个在线购物用户,我想要将商品加入购物车,
以便于我可以在结账时一次购买多个商品。
当你把 User Story 和 BDD 结合起来,效果会明显提升。
例如:
# Requirements
## Requirement 1
User Story:
我是一个在线购物用户,我想要将商品加入购物车,
以便于我可以在结账时一次购买多个商品。
1. Given 用户进入商品页面 When 用户点击「加入购物车」 Then 系统显示成功提示
2. Given 用户已加入商品 When 用户查看购物车 Then 系统显示购物车内容
3. Given 用户在购物车页面 When 用户点击结账 Then 系统跳转到结账页
你会发现,这已经不再是“随便说说”,而是一份结构清晰的需求说明。
对于 AI 来说,这种输入远比自然语言段落更容易理解,也更容易生成稳定的结果。
一个过渡问题:那 SDD 呢?
如果说 BDD 解决的是“行为描述不清晰”,那么接下来要面对的问题是:
当系统变得复杂,仅靠行为描述是否足够?
答案通常是否定的。
因为行为描述解决的是“点”的问题,而不是“整体结构”的问题。
这也是 SDD 要解决的核心。
从“讲故事”到“画蓝图”——SDD 是怎么补上最后一块拼图的?
在上一节我们提到,BDD 本质上是在做一件事:把需求讲清楚。
但当系统继续变复杂时,一个新的问题会浮现出来:
光讲清楚“发生什么”,还不够。
因为你会开始遇到这些情况:
- 行为是清楚的,但数据结构不统一
- 场景是对的,但实现方式五花八门
- AI 理解了“要做什么”,但还是在“怎么做”上自由发挥
这时候,你会发现:我们缺的不是行为,而是“约束行为的结构”。
这就是 SDD 要补的那一块。
如果说 BDD 是在讲故事,那么 SDD 更像是在画蓝图。
它关注的不是:
用户会做什么
而是:
系统应该长什么样
在 SDD 中,你不再只是描述行为,而是开始定义:
- 系统用什么技术
- 数据长什么结构
- API 怎么设计
- 哪些能做,哪些不能做
- 边界在哪里
换句话说:
BDD 解决的是“说清楚”,SDD 解决的是“说完整”。
来看一个很现实的例子。
当你用 Vibe Coding 时,你可能会这样跟 AI 说:
帮我实现一个用户注册功能
听起来没问题,但 AI 很可能会给你一整套“工业级方案”:
- 邮箱验证
- 密码强度校验
- 手机验证码
- OAuth 登录
- 激活流程
它不是错,它只是不知道你的边界在哪。
问题的本质不是 AI 太“蠢”,而是你给的信息太“模糊”。
现在换一种方式,用 Spec 来描述:
## 用户注册功能规格
### 功能范围
- 实现基础账号密码注册
### 规则(仅限以下)
1. 密码长度 ≥ 8
2. 必须包含大写字母
3. 必须包含数字
### API
- register(email: string, password: string)
### 不在范围
- 邮箱验证
- 手机验证码
- OAuth 登录
这时候会发生一个非常明显的变化:
👉 AI 不再“发挥”,而是“执行”。
很多人第一次接触 SDD,会以为它只是“写更详细的文档”。
但它真正的价值在于:
不仅定义“要什么”,还定义“不要什么”
这一点极其关键。
因为 AI 有一个很典型的行为模式:
做多不做少
如果你不给边界,它一定会补全;
如果你不给限制,它一定会扩展。
而 SDD,本质上就是在做一件事:
把“猜”变成“约束”
而在实际项目中,SDD 通常不会是一段 Prompt,而是一组结构化文件。
例如,你可能会有两类核心文件:
1️⃣ 设计文件(Design / Architecture)
定义系统的“骨架”:
## Technology Stack
- TypeScript
- Nuxt 3
- Firebase
## Data Structures
interface Product {
id: string
name: string
price: number
stock: number
}
你会发现这些细节相较于 BDD 来说,更加技术性,对于非技术人员来讲其实满不友善的,但对于 AI 跟开发者来讲,这些细节却是非常重要的,也相对容易理解。
2️⃣ 规格文件(Specifications)
定义具体功能“怎么实现”:
### Function: addToCart
Pre-conditions:
- quantity > 0
- stock >= quantity
Logic:
- 已存在 → 数量 +1
- 不存在 → 新增
Side Effects:
- 更新 cart state
你会发现一件很有意思的事:
👉 这些内容其实已经非常接近代码了
但它比代码更高一层,因为它是:
可以被 AI 理解的“意图表达”
如果你用 SDD 写到这么细的话,AI 要发生幻觉的机会基本上是很低的,因为它不需要去猜「库存不足要干嘛?」,也不用猜「重复加入是要新增一笔还是数量 +1?」,因为你都透过规格文件告诉它了。
BDD + SDD 之后,还缺什么?
到目前为止,我们已经解决了两个关键问题:
- BDD:让需求“说得清楚”
- SDD:让实现“有边界、有约束”
从输入角度来看,这已经非常完整了。
但这里有一个容易被忽略的问题:
当 AI 按照你的描述实现之后,你怎么确定它真的“做对了”?
这是一个本质问题。
因为无论你的描述写得多好,AI 的实现依然存在几个不确定性:
- 是否遗漏了某些边界条件?
- 是否在某些场景下逻辑错误?
- 是否“看起来对”,但其实在特殊情况下会出 bug?
换句话说:
BDD 和 SDD 解决的是“输入问题”,但还没有解决“验证问题”。
而这正是 TDD 的位置。
TDD(测试驱动开发)在这里的角色,不再是传统意义上的“先写测试再写代码”,而是:
为 AI 生成的代码提供一套可执行的验证标准
在 AI Coding 场景中,一个更现实的流程是:
需求 → BDD(行为描述) → SDD(规范约束)
→ 生成测试(AI 或人) → AI 实现 → 跑测试验证
也就是说:
- BDD:定义“要做什么”
- SDD:定义“怎么做 & 不要做什么”
- TDD:定义“什么叫做做对了”
当三者结合时,你可以这样理解:
BDD(行为:What)
↓
SDD(规范:How + Constraint)
↓
TDD(验证:Correctness)
↓
AI Implementation
这其实对应了三个完全不同的问题:
| 层级 | 解决问题 |
|---|---|
| BDD | 需求是否表达清楚 |
| SDD | 实现是否受控 |
| TDD | 结果是否正确 |
我们把前面的购物车例子补完整:
## Requirement: Add to Cart
### 1. Behavior(BDD)
Given 用户进入商品页
When 点击加入购物车
Then 显示“加入成功”
### 2. Specification(SDD)
- CartItem: { productId, quantity }
- quantity ≤ stock
- 必须通过 store action 修改 state
### 3. Test(TDD)
- 加入新商品 → cart 数量 +1
- 重复加入 → 数量递增,不新增条目
- 库存不足 → 抛出错误或限制数量
这个时候,你会发现一个本质变化:
👉 AI 不再只是“生成代码”,而是在满足一组明确约束 + 通过验证标准
在传统开发中:
- 测试是“保障代码质量”的工具
但在 AI Coding 中:
测试是“约束 AI 行为”的工具
它的作用已经从“质量控制”变成了“执行约束”。
所以再回到最初那个问题:
我到底该用 BDD 还是 SDD?
更准确的答案应该是:
BDD + SDD + TDD 是一整套体系,而不是三选一
它们分别解决:
- BDD:防止你“说错需求”
- SDD:防止 AI“乱实现”
- TDD:防止 AI“实现错”
如果要用一句话总结这一整套组合:
Vibe Coding 让你“快速做出来”,
BDD 让你“说清楚”,
SDD 让你“约束住”,
TDD 让你“验证对”。
而这四者叠加之后,软件开发的重心也发生了变化:
从“写代码”,变成“定义 + 约束 + 验证系统”。
进阶:工具化的 Spec
手写 Markdown Spec,其实已经足够你完成大多数项目。
但当项目开始变大,你很快会遇到几个很现实的问题:
- Spec 越写越多,开始散落在各个文件里
- 每次修改需求,不知道哪些 Spec 需要一起改
- AI 的上下文不稳定,经常“忘了之前说过什么”
- 同一个功能,不同人写出来的 Spec 风格完全不一致
这时候问题就不再是“会不会写 Spec”,而是:
你有没有能力“管理 Spec”。
手写 Spec,本质上还是一种“文档行为”。
但当你开始频繁做这些事情:
- 为一个功能持续迭代 Spec
- 让 AI 多轮根据 Spec 实作
- 用测试验证 Spec
- 在多个 feature 之间复用或对齐规则
Spec 就不再只是文档,而变成了:
开发流程的一部分。
一旦进入这个阶段,你会自然想要三样东西:
- 结构统一(不要每个人写一套风格)
- 流程可控(知道现在做到哪一步)
- 变更可追踪(这个功能改了什么、为什么改)
而这,正是“工具化 Spec”要解决的问题。
工具在做什么?
很多人第一次接触这类工具,会以为它们是在“帮你写 Spec”。
其实不是。
它们真正做的事情只有三件:
1)把 Spec 结构标准化
不再是随意的 Markdown,而是明确拆分为:
- proposal(为什么做)
- spec(要做什么)
- design(怎么做)
- tasks(怎么拆)
这样 AI 在不同阶段拿到的是“刚好需要的信息”,而不是一整坨上下文。
2)把开发流程显式化
从原本的:
想需求 → 写点文档 → 直接让 AI 写代码
变成:
定义需求 → 写 Spec → 拆任务 → 实作 → 验证 → 归档
你不再依赖“记忆”来控制流程,而是用工具把流程固定下来。
3)让 AI 有“稳定上下文”
这是很多人低估的一点。
AI 最大的问题不是不聪明,而是:
它没有长期记忆。
当你的 Spec 被结构化、文件化之后:
- AI 可以随时读取当前 feature 的完整上下文
- 不需要依赖聊天历史
- 不会因为“上下文漂移”而越写越偏
换句话说:
Spec 成了 AI 的“外部记忆”。
一个典型的工具化流程
当 Spec 被工具接管之后,一个功能的生命周期通常会变成这样:
探索需求
→ 定义变更(change)
→ 生成 Spec / Design / Tasks
→ AI 实作
→ 测试验证
→ 归档
你会发现,这其实就是你前面看到的:
BDD + SDD + TDD 的工程化版本
只不过:
- BDD → 体现在场景(Given-When-Then)
- SDD → 体现在 Spec / Design
- TDD → 体现在验证和测试
工具只是把这些东西串起来,并且“强制你走一遍”。
当你真正用上这些工具之后,会有一个很明显的感受:
你花时间最多的地方,不再是写代码。
而是:
- 定义 Spec
- 拆分任务
- Review AI 的实现
- 修正 Spec 或测试
代码本身,反而变成“执行结果”。
这也是为什么很多人会产生错觉:
“有了 AI + SDD,开发是不是更轻松了?”
现实往往是:
- 以前你只需要维护代码
- 现在你要维护:Spec + 测试 + 代码
短期来看,成本是上升的。
但换来的东西是:
可控性 + 一致性 + 可持续演进
这里需要再强调一遍(也是最容易被误解的一点):
工具解决的是“表达问题”,不是“思考问题”。
它可以帮你:
- 规范格式
- 约束流程
- 减少 AI 偏离
但它解决不了:
- 需求拆解
- 架构设计
- 边界判断
- 代码质量
这些东西,依然完全取决于你。
一个例子:OpenSpec 的工作方式
OpenSpec 是一个典型的 SDD 工具。
它做的事情,本质上和手写 Markdown 是一样的:
用结构化的 Spec,引导 AI 实现。
但它额外做了两件事:
- 格式标准化
- 流程命令化
也就是说,你不再只是“写”,而是通过命令驱动整个开发流程。
它对应到 SDD,大致是这样一条链路:
探索需求 建立 change 产生规则文件 实现 验证 归档
│ │ │ │ │ │
▼ ▼ ▼ ▼ ▼ ▼
/opsx:explore → /opsx:new → /opsx:ff → /opsx:apply → /opsx:verify → /opsx:archive
/opsx:continue
每一步其实都非常清晰:
-
/opsx:explore
当需求还不明确时,先进入探索模式,补齐上下文和边界 -
/opsx:new
创建一个 change,对应一次功能变更 -
/opsx:ff//opsx:continue
生成完整规划文件(proposal / specs / design / tasks),或者分阶段生成方便审查 -
/opsx:apply
根据 tasks 开始实现 -
/opsx:verify
检查实现是否符合 spec -
/opsx:archive
将本次变更归档,并合并回主 specs
比如你要做一个“深色模式”功能:
你:/opsx:propose add-dark-mode
AI:
✓ proposal.md — 为什么要做
✓ specs/ — 行为与场景
✓ design.md — 技术方案
✓ tasks.md — 实现步骤
这一步,其实就已经把一件事拆清楚了:
- 为什么做(Why)
- 做什么(What)
- 怎么做(How - design)
- 怎么落地(Tasks)
接着进入实现:
你:/opsx:apply
AI:
✓ 1.1 添加 theme provider
✓ 1.2 创建切换组件
✓ 2.1 添加 CSS 变量
✓ 2.2 接入 localStorage
这里的关键在于:
AI 是在“执行 Spec”,而不是“根据 prompt 发挥”。
最后是归档:
你:/opsx:archive
AI:
✓ 归档 change
✓ 更新主 specs
这一步解决的是一个很关键的问题:
AI 没有长期记忆,但 Spec 可以成为“外部记忆”。
Spec 可以有很多写法,但在 AI 时代,有一种格式特别有效:
Given-When-Then
它本来是为了让“人”沟通需求(Dan North),但现在反而变成了:
最适合 AI 理解的结构
原因很简单:
- 结构化:固定三段(Given / When / Then)
- 具体:用实例表达,而不是抽象描述
- 可验证:Then 本身就是断言
举个对比:
普通 prompt:
帮我实现一个网球计分系统,要能够追踪两个玩家的分数,
用 love、fifteen、thirty、forty 来表示,
还要处理 deuce 和 advantage 的情况。
Given-When-Then:
Feature: 网球计分系统
跟踪两位球员的分数,并使用标准网球术语返回比分
Scenario: 比赛开始时
Given 一场新的比赛
When 查询当前比分
Then 比分应该是 "love all"
Scenario: 一方得分
Given 一场新的比赛
When player1 得 1 分
Then 比分应该是 "fifteen love"
Scenario: 双方各得一分
Given 一场新的比赛
When player1 得 1 分
And player2 得 1 分
Then 比分应该是 "fifteen all"
Scenario: 平分 (Deuce)
Given 一场新的比赛
When player1 得 3 分
And player2 得 3 分
Then 比分应该是 "deuce"
Scenario: 优势 (Advantage)
Given 双方比分为 deuce
When player1 得 1 分
Then 比分应该是 "advantage player1"
Scenario: 从优势回到 Deuce
Given player1 处于 advantage
When player2 得 1 分
Then 比分应该是 "deuce"
Scenario: 赢得比赛
Given player1 处于 advantage
When player1 得 1 分
Then player1 赢得比赛
区别在于:
前者是“描述”,后者是“定义行为 + 验证标准”
差异很明显。 每个场景都把前置条件、动作、预期结果写清楚了,AI可以精确地知道每个情境下系统应该怎么表现。 不会多做,也不会少做
SDD 不是银弹
这里必须泼一盆冷水。
SDD 能解决的是:
- 输入不清晰
- AI 乱发挥
- 结果不一致
但它解决不了:
- 需求拆解(你要懂业务)
- 架构设计(AI 不负责长期演进)
- 代码质量(能跑 ≠ 好代码)
- 边界发现(依赖经验)
换句话说:
SDD 降低的是“表达成本”,不是“思考成本”。
Spec 写多少才够?
一个常见的问题是:Spec 要写到多细?
答案取决于你对 AI 的信任度和功能的复杂度。
简单功能(工具函数、格式转换等):Spec 可以很简短,几行就够。AI 在这类任务上的表现通常很好,不需要过度约束。
中等功能(业务逻辑、API endpoint 等):需要明确的范围、API 设计、关键的 Given-When-Then 场景。特别是不在范围的部分要写清楚。
复杂功能(跨模块交互、状态管理等):除了 Spec 之外,可能还需要拆分成多个小 Spec,每个小 Spec 对应一个 TDD 循环。
一个衡量标准是:如果你把 Spec 给另一个人类开发者,他能不能理解你要做什么、做到什么程度?如果可以,那这份 Spec 给 AI 也够用了。如果连人都看不懂,AI 更不可能猜对。
工具在变,速度在变,但本质没有变:
- 理解需求
- 做出设计
- 保证质量
AI 是加速器,但:
方向是 Spec 给的,正确性是测试给的,最终质量是人把关的。
OpenSpec vs Spec Kit:两种“工具化 Spec”的路线
当 Spec 开始从“写文档”走向“驱动开发流程”,工具就自然分化成了两条路线。
目前比较典型的两种实现就是:
- OpenSpec(偏轻量、流程驱动)
- Spec Kit(偏规范、体系化、工程治理)
它们都属于 Spec-Driven Development(SDD)工具化实践,但设计哲学差异非常明显。
先用一句话把差异说清楚:
- OpenSpec:更像“开发流程脚手架 + 命令驱动 AI 执行”
- Spec Kit:更像“完整的软件工程治理体系 + SDD 操作系统”
OpenSpec 的核心目标很直接:
让 AI coding 过程“可控 + 可重复 + 可追踪”,但不要太重。
它做的事情可以拆成三层:
① 把 Spec 标准化
原本你手写 Markdown:
- proposal
- spec
- design
- tasks
OpenSpec 直接帮你变成固定结构。
② 把开发过程命令化
核心就是这一套 OPSX 流程:
/opsx:explore → 理解需求
/opsx:new → 创建变更
/opsx:ff → 生成完整规划
/opsx:apply → AI 实现
/opsx:verify → 验证结果
/opsx:archive → 归档沉淀
它本质是在做一件事:
把“写 prompt + 管理上下文”变成“操作流程”。
③ 强调“轻”
OpenSpec 的设计哲学很明确:
- 不强制复杂工程结构
- 不绑定特定 IDE
- 不引入重型流程治理
- 允许逐步 review(/continue)
它更像:
AI 编程的“流程增强插件”
而不是一个完整体系。
OpenSpec 的特点总结
可以归纳为四点:
- 流程轻
- 上手快
- 约束适中
- 更偏“单项目开发体验优化”
适合:
- 个人项目
- 小团队
- 快速 AI coding workflow
- 实验型开发
Spec Kit 走的是完全不同的路线。
它不是在优化“怎么写 prompt”,而是在做:
软件工程流程本身的结构化重建。
① Spec 不只是文件,而是“生命周期对象”
Spec Kit 不是简单生成:
- spec.md
- tasks.md
它定义的是一整套生命周期:
specify → plan → tasks → implement → verify → iterate → archive
每一步都有明确职责边界。
② 强调“工程治理能力”
Spec Kit 引入了大量工程级能力,比如:
- spec drift 检测(规范和实现是否偏离)
- 质量 gate(进入 implement 前必须满足条件)
- 任务追踪(spec → task → issue)
- review flow(多阶段验证)
- extension system(扩展整个 SDD 生命周期)
甚至包括:
- CI/CD 集成
- Jira / GitHub issues 同步
- 多 agent 协作
- security / QA / architecture review
③ 它更像“AI 时代的软件工程框架”
Spec Kit 的定位已经不是工具,而是:
Spec-driven Software Engineering System
它试图解决的问题是:
- 大型项目如何用 AI 管理复杂性
- 多人协作如何保持 spec 一致性
- AI 参与开发时如何防止“结构漂移”
- 如何把 spec 变成长期可演进资产
Spec Kit 的特点总结:
可以归纳为:
- 强流程约束
- 强工程治理
- 强扩展能力
- 面向复杂项目 / 企业级场景
适合:
- 中大型项目
- 长生命周期系统
- 多团队协作
- AI + 工程体系融合场景
可以用一张结构化对比来看:
| 维度 | OpenSpec | Spec Kit |
|---|---|---|
| 设计目标 | 简化 AI 开发流程 | 构建完整 SDD 工程体系 |
| 复杂度 | 轻 | 重 |
| 学习成本 | 低 | 中高 |
| 流程约束 | 弱到中 | 强 |
| 工程治理 | 基础 | 完整体系 |
| 扩展能力 | 有限 | 很强(extension/preset) |
| 适用场景 | 个人/小团队 | 中大型/企业级 |
| 核心思想 | “让 AI 好用” | “让 AI 可控地参与工程” |
如果从更底层看,它们的差异不是“功能多少”,而是哲学不同:
OpenSpec 的假设
AI 已经足够强了,我们要做的是让它“更容易被用”。
重点是:
- 提升效率
- 降低输入成本
- 减少 prompt 混乱
Spec Kit 的假设
AI 不可控是常态,我们要做的是“工程化约束它”。
重点是:
- 控制复杂性
- 管理长期演进
- 约束 AI 行为边界
- 保证系统一致性
回到 SDD 的本质其实两者都在做同一件事:
把“自然语言 prompt 驱动开发”升级为“结构化规格驱动开发”。
区别只是:
- OpenSpec:偏“开发体验优化”
- Spec Kit:偏“工程体系重构”
OpenSpec笔记
OpenSpec 是一个面向 AI 辅助开发的结构化工作流工具。它通过一组统一的斜杠命令(如 /opsx:)来组织开发流程,引导开发者与 AI 在同一套规范下协作,从需求探索、方案规划、任务拆解,到代码实现、结果验证与最终归档,每个阶段都有明确的输入与输出。
它的核心思想可以概括为一句话:
先约定,再编码。
在真正编写代码之前,开发者会先与 AI 一起明确需求边界、设计实现方案,并将其拆解为可执行的任务清单;在实现过程中,AI 按照这些约定进行编码;实现完成后,再通过验证步骤检查是否符合最初的规格;最后将本次变更归档,形成可追溯、可回顾的开发历史。
通过这种方式,OpenSpec 将原本分散在“对话式 prompt”中的开发过程,结构化为一条清晰、可控且可复用的工作流,从而减少沟通偏差,提高 AI 辅助开发的稳定性与工程质量。
安装 OpenSpec CLI
npm install -g @fission-ai/openspec@latest
进入你的项目根目录,执行:
openspec init
该命令会创建基础目录结构,例如:
openspec/changes/- 配置文件等
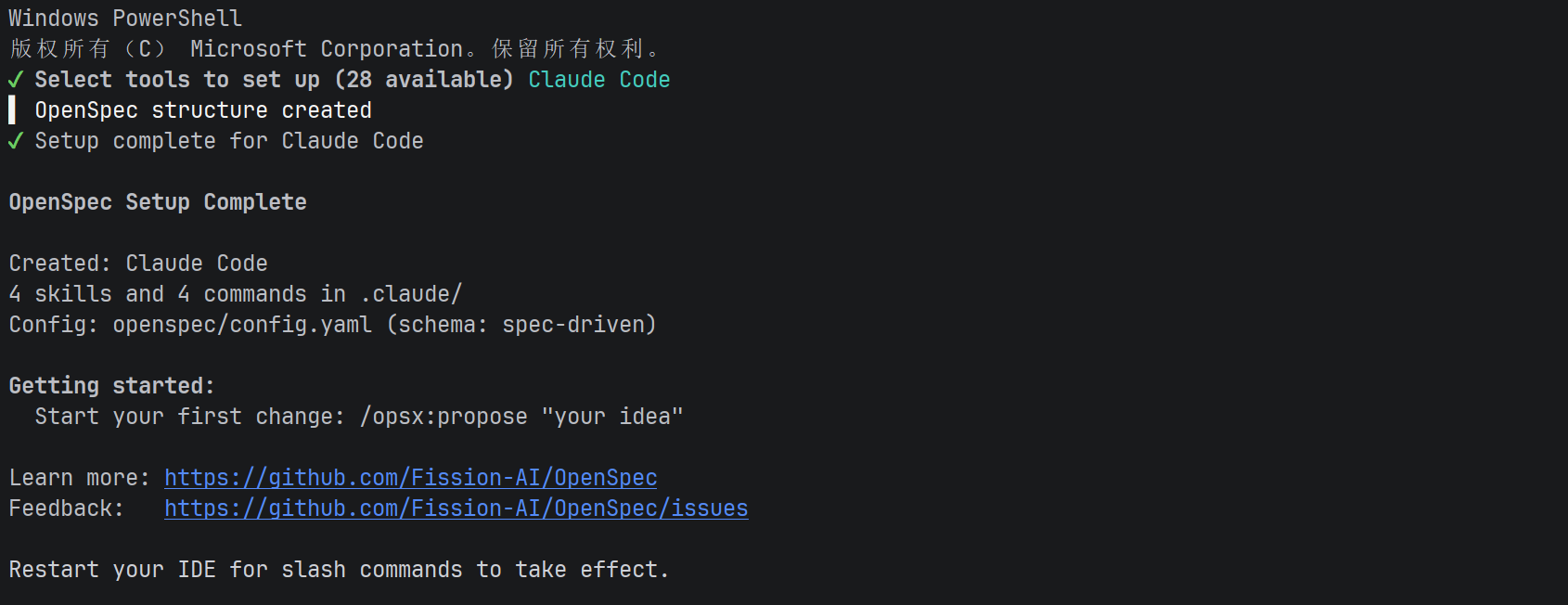
这段输出本质上是在说:OpenSpec 已经帮你把“AI 编程工作流插件”装进了 Claude Code,并完成初始化配置。
🧩 1. “✔ Select tools to set up (28 available) Claude Code”
意思是:
OpenSpec 支持 28 种 AI 工具 / 集成环境,你当前选择的是 Claude Code
也就是说它不是只能用在一个工具里,而是“多代理适配器”,这里选的是 Claude Code 这一套。
🏗️ 2. “▌ OpenSpec structure created”
意思是:
项目目录结构已经生成好了
通常会创建类似这些东西:
.claude/(AI 命令和 skills)openspec/(配置与规范)changes/(变更目录)
✔ 3. “Setup complete for Claude Code”
意思是:
OpenSpec 已经成功集成到 Claude Code 里了
换句话说:
👉 现在 Claude Code 已经“懂 OpenSpec 的工作流命令”了
🧠 4. “4 skills and 4 commands in .claude/”
这个很关键:
意思是:
OpenSpec 给 Claude Code 注入了:
- 4 个 skills(能力模块)
- 4 个 commands(/opsx: 之类的命令)
也就是说:
👉 /opsx:propose、/opsx:apply 这些不是魔法,是“被写进 AI 工具里的规则脚本”
⚙️ 5. “Config: openspec/config.yaml (schema: spec-driven)”
意思是:
当前项目启用了一个配置文件,模式是 spec-driven(规格驱动开发)
这个配置控制:
- 用不用完整 SDD 流程
- 启用哪些 opsx 命令
- 工作流是轻量还是严格
🚀 6. “Start your first change: /opsx:propose “your idea””
意思是:
现在可以开始你的第一个需求变更了
比如:
/opsx:propose "add dark mode"
它会帮你:
👉 创建 proposal + specs + design + tasks
🔁 7. “Restart your IDE for slash commands to take effect”
意思是:
你需要重启编辑器(Cursor / VS Code / Claude Code)
因为:
👉 slash commands 是“插件注入的能力”,要重载才生效
OpenSpec 默认只启用核心命令(如 explore、apply、archive 等 4 个)。
如果你希望使用完整工作流(包括 new、continue、ff、verify、sync 等扩展命令),需要切换配置。
步骤 1:切换 Profile
openspec config profile
选择:
👉 Expanded Profile(完整工作流)
步骤 2:选择 Workflows(可选)
如果只想启用部分功能,可以选择:
👉 Workflows only
然后用空格键勾选需要的命令。
步骤 3:刷新配置
openspec update
步骤 4:重启编辑器
重启 Cursor / VS Code / Copilot,使 /opsx: 命令生效。
核心概念
变更(Change)
一次独立的开发任务,对应一个功能点。
存放路径:
changes/<change-name>/
制品(Artifact)
在一次变更过程中生成的所有产物,例如:
- proposal(提案)
- specs(规范)
- design(设计)
- tasks(任务清单)
- 代码实现
- 验证报告
规范(Specs)
全局或模块级设计约定,存放在:
openspec/specs/
可以在多个变更中复用。
快进(Fast-forward)
一次性生成规划阶段全部内容(proposal + specs + design + tasks)。
OpenSpec 工作流
一个完整的 OpenSpec 工作流分为:
探索 → 规划 → 执行 → 验证 → 同步 → 归档 六个阶段。
🔍 1. 探索阶段:/opsx:explore
在动手写代码前,与 AI 进行纯粹的讨论,分析需求、调研技术方案、梳理潜在风险。
/opsx:explore
适用场景:
- 需求模糊
- 技术选型不确定
- 需要头脑风暴
行为说明:
- AI 进入“只读模式”
- 不创建任何文件
- 只输出讨论性分析
输出:
通常是一段对话记录,可手动保存到项目文档中作为参考。
🧱 2. 规划阶段:从想法到任务清单
规划阶段的目标是产出清晰的:
📌 提案(proposal) + 规范(specs) + 设计(design) + 任务清单(tasks)
作为后续编码依据。
🚀 2.1 启动新变更:/opsx:new
/opsx:new
行为:
-
在
changes/下创建以时间戳命名的新目录 -
生成基础文件框架,例如:
proposal.mdtasks.md
提示:
需要你描述本次变更目标(一句话或一段话)。
🔄 2.2 逐步完善:/opsx:continue
/opsx:continue
作用:
按顺序逐步生成每个工件。
行为逻辑:
- 如果已有
proposal.md→ 生成specs/ - 再执行 → 生成
design.md - 再执行 → 生成
tasks.md
优点:
✔ 每一步可审查
✔ 可修改方向
✔ 降低 AI 偏差
⚡ 2.3 快速完成规划:/opsx:ff
/opsx:ff
行为:
一次性生成全部规划产物:
- proposal.md
- specs/
- design.md
- tasks.md
适用场景:
- 需求明确
- 变更较小
- 有经验的开发者
📦 规划阶段产出物
- proposal.md → 背景 / 目标 / 验收标准
- specs/ → 详细规范(接口 / 数据结构 / UI 等)
- design.md → 技术设计(模块 / 算法 / 依赖)
- tasks.md → 可执行任务清单(供 apply 使用)
⚙️ 3. 执行阶段:/opsx:apply
/opsx:apply
作用:
根据任务清单执行代码生成。
行为:
- 读取
tasks.md - 按任务逐个生成代码
- 写入项目对应位置
交互方式:
- 每个任务完成后可能请求确认
- 可中途暂停 / 修改 tasks / 继续执行
🧪 4. 验证阶段:/opsx:verify
/opsx:verify
作用:
检查代码是否符合规范与设计。
行为:
- 对照
specs/+design.md - 输出验证报告
📄 通常生成:
verify-report.md
报告内容:
- ✔ 符合项
- ❌ 不符合项
- ⚠ 潜在问题
- 🛠 修复建议
循环机制:
修复 → 再 verify → 直到通过
🔁 5. 同步规范:/opsx:sync
/opsx:sync
作用:
把本次变更中的“可复用规范”沉淀到全局。
行为:
- 将
changes/<change>/specs/ - 合并到:
openspec/specs/
注意:
- ❗不会归档变更
- ❗变更仍处于开发状态
📦 6. 归档阶段
🗂 6.1 单个归档:/opsx:archive
/opsx:archive
行为:
- 移动变更:
changes/active/ → changes/archived/
- 自动 sync(确保规范已合并)
- 更新 CHANGELOG.md
- 标记完成状态
📚 6.2 批量归档:/opsx:bulk-archive
/opsx:bulk-archive
行为:
- 列出所有可归档变更
- 支持多选
- 逐个归档
- 自动检测规范冲突
- 更新变更日志
📋 命令速查表
| 命令 | 阶段 | 功能 |
|---|---|---|
/opsx:explore |
探索 | 只读模式讨论需求,不生成文件 |
/opsx:new |
规划 | 创建新变更目录及基础文件 |
/opsx:continue |
规划 | 按进度生成下一个工件 |
/opsx:ff |
规划 | 快进:一次性生成所有规划工件 |
/opsx:apply |
执行 | 根据任务清单编写代码 |
/opsx:verify |
验证 | 检查代码是否符合规范,生成报告 |
/opsx:sync |
同步 | 将变更中的规范合并到主规范库 |
/opsx:archive |
归档 | 归档单个已完成变更 |
/opsx:bulk-archive |
归档 | 批量归档多个变更 |
/opsx:onboard |
学习 | 交互式教程(约15分钟) |
💡 最佳实践与典型场景
🧩 场景一:复杂功能开发(逐步推进)
/opsx:explore – 与 AI 讨论需求、技术选型
/opsx:new – 创建变更
/opsx:continue – 生成 proposal,审阅后继续
/opsx:continue – 生成 specs,审阅后继续
/opsx:continue – 生成 design,审阅后继续
/opsx:continue – 生成 tasks,审阅后定稿
/opsx:apply – 执行任务清单,生成代码
/opsx:verify – 验证代码一致性,修复问题
/opsx:sync – 将新增规范合并到主库
/opsx:archive – 归档变更
⚡ 场景二:小型快速迭代
/opsx:ff – 快进生成所有规划工件(需需求明确)
/opsx:apply – 编码
/opsx:verify – 验证
/opsx:archive – 归档
🏗 场景三:规范先行,团队协作
在项目启动阶段,可以先通过:
/opsx:explore
/opsx:new
建立全局规范(例如代码风格、API 设计原则),并存放在:
openspec/specs/
之后所有功能变更都从主规范派生,并在开发完成后执行:
/opsx:sync
用于将新规范回写到主规范库,保持团队一致性。
🚀 下一步该做什么(标准流程起点)
当你已经做完 初始化(openspec init) 这一步了,接下来本质上就进入 OpenSpec 的“第一段工作流”:先把第一个 change 跑起来,而不是直接写代码。
① 先启动你的第一个需求(推荐)
直接进入:
/opsx:explore "你要做的功能"
比如:
/opsx:explore "做一个本地待办事项系统"
👉 这一步的意义
- 不写代码
- 不建结构
- 只和 AI 对齐需求
- 把“要做什么”先说清楚
如果你已经很确定要做什么(更快路径)
可以跳过 explore,直接开始:
② 创建第一个变更
/opsx:new
然后描述你的需求,例如:
我要做一个用户登录系统,支持邮箱登录 + JWT
③ 选择规划方式(关键分叉点)
🟡 方式 A:逐步规划(推荐)
/opsx:continue
你会依次得到:
- proposal.md
- specs/
- design.md
- tasks.md
👉 每一步都可以检查、修改
🔵 方式 B:一次生成(快)
/opsx:ff
👉 AI 一次性帮你把规划全部写完
当你有了 tasks.md 之后,才开始:
/opsx:apply
👉 AI 才会真正开始写代码
如果你是第一次用 OpenSpec,我建议你按这个走:
1. /opsx:explore (先对齐需求)
2. /opsx:new (创建 change)
3. /opsx:continue (逐步生成 spec)
4. /opsx:apply (开始写代码)
5. /opsx:verify (检查)
6. /opsx:archive (完成归档)
❗ OpenSpec init 只是“装工具”,
真正开始开发,是从/opsx:explore或/opsx:new开始的。
Spec Kit(Speckit)笔记
Spec Kit 是 GitHub 官方开源的规范驱动开发(Spec-Driven Development, SDD)工具包。它通过"规范→计划→任务→实现"的结构化流程,将 AI 从"代码生成工具"转变为"产品开发伙伴"。
你可以选择不同的安装方式:
⚠️ 重要说明
Spec Kit 唯一官方维护的包来自 GitHub 仓库。
在 PyPI 上任何同名包 都不是官方项目的一部分,也不受维护。
👉 请务必像下面这样从 GitHub 安装。
📦 方式一:持久安装(推荐)
一次安装,全局可用。建议锁定版本号(更稳定):
注意:下面的
uv需要 Python 包管理工具 uv
如果提示command not found: uv,请先安装 uv
或使用 pipx 替代(不依赖 uv)
🔧 安装指定版本(推荐)
uv tool install specify-cli --from git+https://github.com/github/spec-kit.git@vX.Y.Z
👉 将 vX.Y.Z 替换为最新 release 版本
🔧 安装最新 main(可能包含未发布内容)
uv tool install specify-cli --from git+https://github.com/github/spec-kit.git
🔧 pipx 替代方案
pipx install git+https://github.com/github/spec-kit.git@vX.Y.Z
pipx install git+https://github.com/github/spec-kit.git
✅ 验证是否安装成功
specify version
如果你的环境无法访问 PyPI 或 GitHub:
👉 请参考企业/离线安装指南
核心思路是:
- 在可联网机器下载 wheel 包
- 再转移到离线环境安装
⬆️ 升级方式
uv tool install specify-cli --force --from git+https://github.com/github/spec-kit.git@vX.Y.Z
pipx 用户:
pipx install --force git+https://github.com/github/spec-kit.git@vX.Y.Z
🚀 使用方式
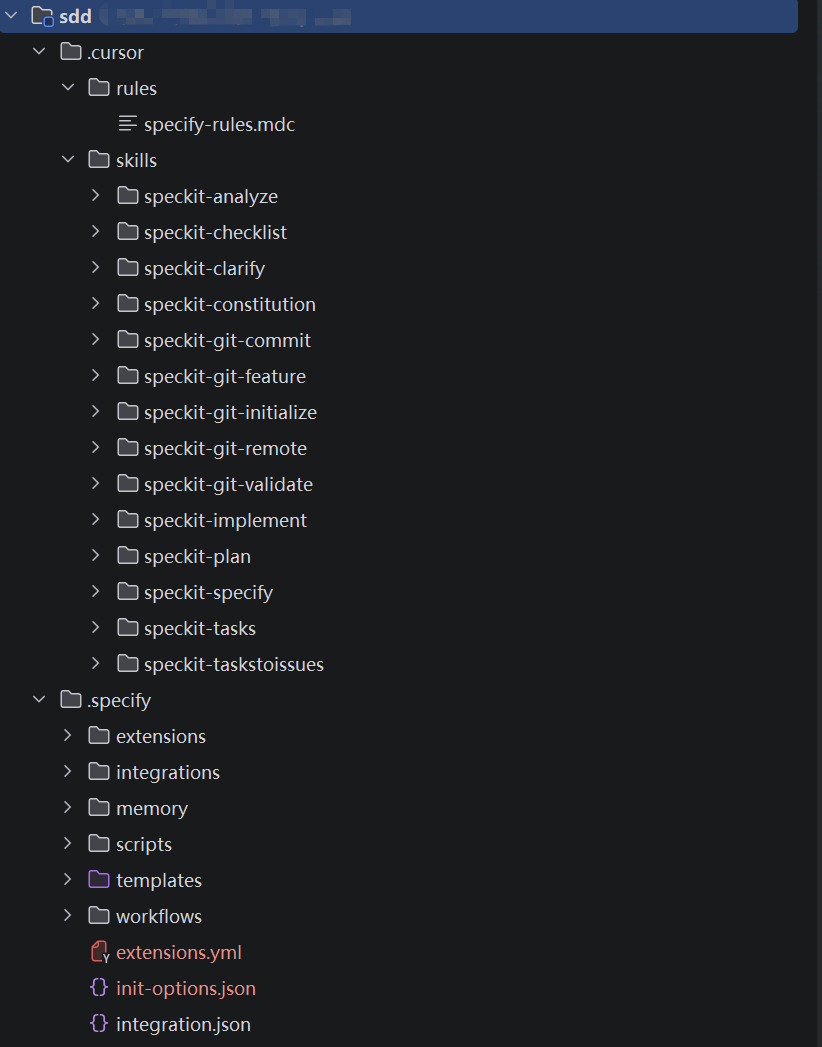
创建新项目
specify init <PROJECT_NAME>
在现有项目初始化
specify init . --integration copilot
或:
specify init --here --integration copilot
检查工具状态
specify check
建立项目原则
在项目目录中启动你的 AI 编程代理。
大多数工具会提供类似 /speckit.* 的命令;
Codex CLI 在 skills 模式下则使用 $speckit-*。
使用:
/speckit.constitution
用来创建项目的开发原则与规范,包括:
- 代码质量标准
- 测试规范
- 用户体验一致性
- 性能要求
创建 spec(需求规格)
使用:
/speckit.specify
描述你要做什么(What & Why),不要写技术栈。
示例:
构建一个应用,用来整理照片到不同相册。
相册按日期分组,可以在主页拖拽重新排序。
相册不能嵌套。
每个相册内用网格方式展示照片预览。
创建技术方案
使用:
/speckit.plan
定义技术栈与架构:
示例:
- 使用 Vite
- 尽量少依赖第三方库
- 使用原生 HTML / CSS / JS
- 图片不上传服务器
- metadata 存储在本地 SQLite
拆解任务
使用:
/speckit.tasks
将方案拆解为可执行任务列表。
执行实现
使用:
/speckit.implement
AI 会按照任务列表:
- 自动实现代码
- 完成整个功能开发流程
Spec Kit 的核心流程就是:
constitution → specify → plan → tasks → implement
❓ FAQ(常见问题)
Q1:OpenSpec 和普通“AI 写代码”有什么区别?
OpenSpec 不是“帮你写代码的工具”,而是一个结构化开发流程框架。
普通 AI coding:
你说一句需求 → AI 直接写代码
OpenSpec:
需求 → 结构化拆解(spec / design / tasks)→ 再编码 → 再验证 → 再归档
核心区别是:
AI 不再“自由发挥”,而是“按约定执行”。
Q2:OpenSpec的这些 /opsx: 命令是在终端运行的吗?
不是。
/opsx:* 是 AI 对话指令,不是 shell 命令。
你应该在支持 OpenSpec 的 AI 工具中输入,例如:
- Claude Code
- Cursor
- Copilot Chat(部分支持)
例如:
/opsx:explore 做一个待办事项系统
Q3:OpenSpec必须按完整流程走吗?
不必须。
OpenSpec 是可裁剪流程:
- 小需求 →
/opsx:ff一步到位 - 中等需求 →
/opsx:new + /opsx:apply - 复杂需求 → 完整 flow(explore → archive)
它的设计理念是:
流程是建议,不是强制。
| 命令 | 行为 | 适用场景 |
|---|---|---|
/opsx:continue |
一步一步生成 spec → design → tasks | 需要审查、复杂项目 |
/opsx:ff |
一次性生成全部规划产物 | 简单需求 / 快速开发 |
一句话:
continue = 可控推进
ff = 一步到位
Q4:OpenSpec 会不会自动帮我写完整项目?
不会。
OpenSpec 的定位不是:
❌ 自动写完项目的 AI
而是:
✅ 让 AI 按工程规范参与开发的系统
它不会替你:
- 拆需求
- 做架构决策
- 判断设计质量
它只会:
- 把你的思考结构化
- 帮你执行
- 帮你验证一致性
Q5:OpenSpec中sync 和 archive 有什么区别?
这是很多人容易混淆的点。
-
/opsx:sync
👉 只做“规范沉淀”,不结束任务 -
/opsx:archive
👉 结束整个变更生命周期
简单理解:
sync = 更新知识库
archive = 关闭项目
Q6:OpenSpec 是不是必须配 AI 才能用?
严格来说:
- OpenSpec 本身是流程工具
- AI 是执行载体
所以:
OpenSpec ≠ AI
OpenSpec + AI = 工作流系统
没有 AI,它只是 Markdown 结构 + 目录规范。
Q7:Claude Code 登录失败怎么办?
Claude Code 会在用户主目录下生成一个本地状态文件 .config.json,其中包含一个关键字 段 hasCompletedOnboarding,用于标记用户是否已经完成了初次引导流程。
-
hasCompletedOnboarding: true:表示引导已完成,程序启动后直接进入工作模式。
-
hasCompletedOnboarding: false:表示引导未完成,程序会在每次启动时尝试引导用户。
我们新建一个.config.json文件写入:
{
"hasCompletedOnboarding": true,
...
}
工作目录在 Windows 上一般是:
C:\Users\<你的用户名>\.claude\
在 macOS / Linux 上是:
~/.claude/
settings.json 是什么?
这个就是 Claude Code 的用户级配置文件。
类似于:
- VSCode 的
settings.json - Git 的
.gitconfig
典型结构(示例):
{
"env": {
// 🔌 Claude API 的基础地址
// 这里指向本地服务(例如 Ollama),而不是 Anthropic 官方 API
"ANTHROPIC_BASE_URL": "http://localhost:11434",
// 🔑 认证 token
// 在本地模型(如 Ollama)中通常是随便填或固定值(如 "ollama")
// 在官方 Claude API 中这里会是真实的 API Key
"ANTHROPIC_AUTH_TOKEN": "ollama",
// 🤖 使用的模型名称
// 这里是本地模型 gemma4:e4b(具体取决于你 Ollama pull 的模型)
"ANTHROPIC_MODEL": "gemma4:e4b",
// 🚫 是否关闭非必要网络流量
// 1 = 开启(更隐私,只做必要请求)
// 0 = 关闭(允许更多遥测/非核心请求)
"CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC": "1"
}
}
Q8:Spec Kit 和 OpenSpec 有什么区别?
一句话版本:
Spec Kit = 重型规范驱动框架
OpenSpec = 轻量 AI 工作流工具
更具体一点:
- Spec Kit:结构完整、流程严格(constitution → spec → plan → tasks → implement)
- OpenSpec:更灵活,用
/opsx:控制 AI 流程 - Spec Kit 更偏“工程规范体系”
- OpenSpec 更偏“AI 协作工作流”
👉 一个偏“方法论框架”,一个偏“工具化执行”。
Q9:Spec Kit 和 TDD 有什么关系?
Spec Kit 本质上是:
Spec-First + TDD 思想的工程化版本
区别:
- TDD:从测试驱动代码
- Spec Kit:从“规格驱动 → 再到任务 → 再到实现”
两者结合:
Spec 定义行为,Test 保证正确性,AI 负责实现
Q10:specify-cli 安装失败怎么办?
最常见原因是:
- GitHub 连接失败(443 超时)
- 网络被限制
- Git 未配置代理
解决方向:
- 配置 Git proxy
- 使用 VPN
- 或改用 SSH clone
有些地方你可能浏览器可以访问,但git没走魔法,检查:
git config --global --get http.proxy
设置
git config --global http.proxy http://127.0.0.1:xxx
git config --global https.proxy http://127.0.0.1:xxx
Q11:Spec Kit 适合什么项目?
适合:
- 中大型项目
- 有明确业务逻辑的系统
- 需要多人协作的工程
- 希望 AI 辅助开发但不失控的场景
不太适合:
- 小脚本
- 临时工具
- 快速 demo(overkill)
Q12:Spec Kit 会不会限制开发自由度?
会,但这是设计目的。
它的思路是:
用结构换可控性,用流程换一致性
所以你会感觉:
- 少了“随便写代码”的自由
- 多了“按流程走”的约束
但换来的是:
AI 不容易乱写 + 项目更可维护
Q13:Spec Kit 和 OpenSpec 可以一起用吗?
理论上可以,但:
- Spec Kit:强流程 + 强结构
- OpenSpec:轻流程 + 灵活命令
👉 一起用会出现:
- 流程重复
- 抽象层冲突
- AI 指令混乱
建议:
二选一作为主框架
Q14:SDD(Spec-Driven Development)和各大厂商的 Plan 模式有什么区别?
很多 AI 编程工具(比如 Cursor、Claude Code、GitHub Copilot Agent 等)都有所谓的 Plan / Planning 模式,看起来和 SDD 很像,但本质上不是一回事。
🧠 1. 核心目标不同
SDD(Spec-Driven Development)
👉 目标是“让规格成为开发的第一等公民”
强调的是:
- 先定义“系统应该是什么样”(Spec)
- 再拆解为任务(Tasks)
- 最后由 AI 执行实现
它是一个开发方法论 / 工程范式
Plan 模式(厂商功能)
👉 目标是“让 AI 在写代码前先想一想”
强调的是:
- 生成一个临时的执行计划
- 用来指导当前对话中的代码生成
- 通常不会长期保存
它是一个交互增强功能
🔧 2. 生命周期不同
| 对比项 | SDD | Plan 模式 |
|---|---|---|
| 是否持久化 | ✔ 是(spec / tasks 会保存) | ❌ 否(通常是临时上下文) |
| 是否可复用 | ✔ 可以跨会话/团队复用 | ❌ 仅当前对话 |
| 是否工程化 | ✔ 是完整流程体系 | ❌ 只是步骤优化 |
| 是否影响项目结构 | ✔ 会生成 spec / task / design | ❌ 不改变项目结构 |
🏗️ 3. 抽象层级不同
可以这样理解:
🟦 Plan 模式(低层)
“先帮我想一下怎么写这段代码”
属于:
- 单任务优化
- prompt-level planning
- 临时思考过程
🟩 SDD(高层)
“先定义系统应该是什么,再逐步实现”
属于:
- 系统设计方法
- 长期规范
- AI 可执行的结构化开发流程
⚙️ 4. 是否“可执行规格”
这是最关键差异:
Plan 模式:
- ❌ 输出的是“建议”
- ❌ 不具备结构约束
- ❌ 不保证一致性
SDD:
- ✔ 输出的是“结构化规格”
- ✔ 可拆解为 tasks
- ✔ 可验证(verify)
- ✔ 可迭代演进
🧠 5. 一句话总结
Plan 模式是“让 AI 想清楚这一轮怎么做”
SDD 是“让整个项目从一开始就结构化地被定义”
你可以这样类比:
- Plan 模式 = 导航系统临时规划路线
- SDD = 城市规划 + 建筑图纸 + 施工流程
🧩 结尾
vibe coding 的确很爽,尤其是在结合 plan 模式之后,很多小功能可以很快跑起来,甚至能做到“想到就写、写了就能用”的流畅体验。
但如果从更长周期的软件工程来看,问题也很明显:一旦项目变大、协作变多、迭代变频繁,代码风格、结构设计、边界处理很容易开始“各写各的”。一开始看起来是自由发挥,后面往往就变成维护灾难。
对于初学者来说,学习 SDD 确实是有成本的,就像小孩子学写字一样。你可以直接拿笔写,也能写出字,但如果没有字帖、没有楷书练习、没有基本结构训练,写出来的东西大概率就是“能看懂,但不统一”。甚至每个人都有自己的一套“自创草书”——包括我以前写的代码也是这样(笑)。
但问题在于:
写得出来 ≠ 写得可维护
SDD 的意义不在于限制创造力,而在于提供一个“统一的骨架”:
- 让 AI 不至于自由发挥过度
- 让项目结构保持一致
- 让需求、设计、实现之间有清晰的映射关系
- 让后期维护不会变成“读心游戏”
所以 SDD 的价值会在中大型项目中逐渐体现出来。
你依然可以 vibe coding,也可以用 plan 模式快速推进开发——这些都没问题。但当系统开始变复杂的时候,你会慢慢意识到:
真正难的不是“写出代码”,而是“让代码长期保持可理解”。
而 SDD 做的,就是把这个问题前置解决掉。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)