C++:二叉搜索树
⼆叉搜索树的性能分析和概念
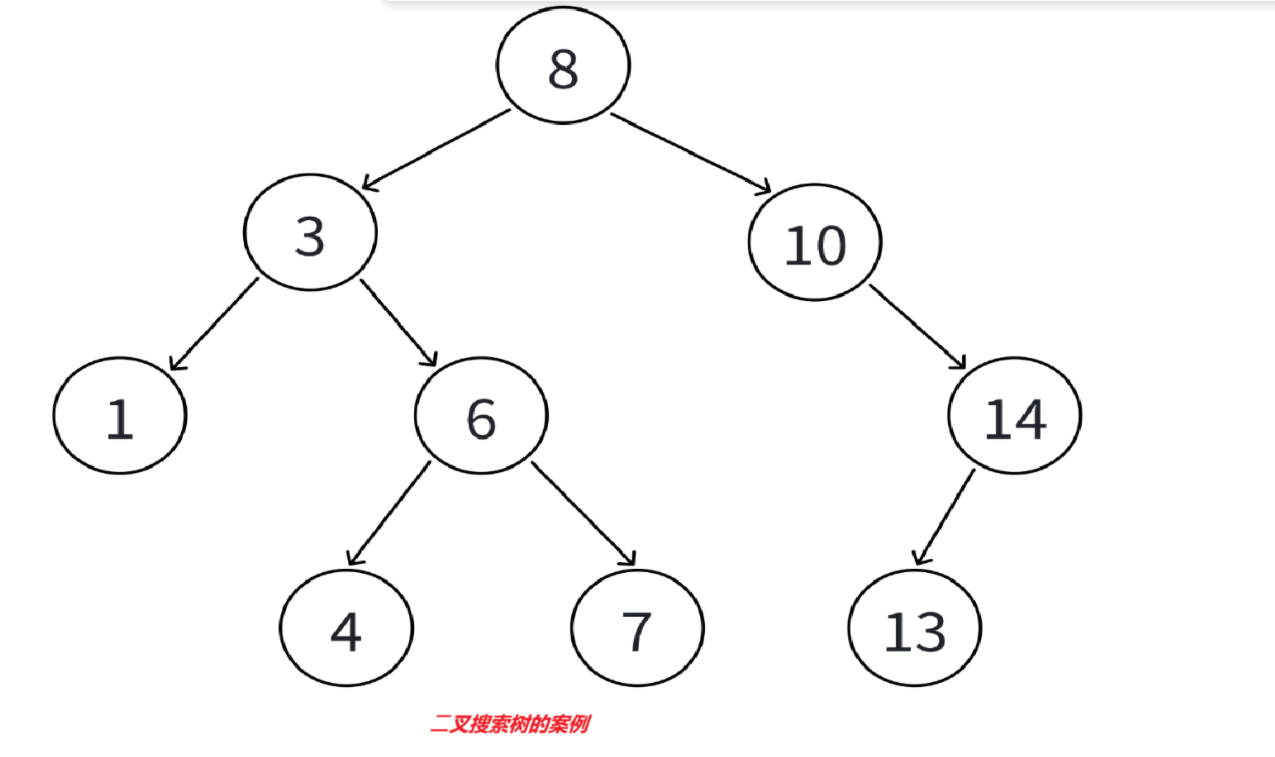
1.1⼆叉搜索树的概念
⼆叉搜索树⼜称⼆叉排序树,它或者是⼀棵空树,是一种具有以下性质的⼆叉树:
•若它的左⼦树不为空,则左⼦树上所有结点的值都⼩于等于根结点的值 •若它的右⼦树不为空,则右⼦树上所有结点的值都⼤于等于根结点的值 • 它的左右⼦树都是⼆叉搜索树 • ⼆叉搜索树中可以⽀持插⼊相等的值,也可以不⽀持插⼊相等的值,具体看使⽤场景定义,例如: map/set/multimap/multiset系列容器底层就是⼆叉搜索树,其中map/set不⽀持插⼊相等 值,multimap/multiset⽀持插⼊相等值
1.2⼆叉搜索树的性能分析
由于它本身自己和它的子树都是⼆叉搜索树,这里观察上面的特点,不难发现:⼆叉搜索树的中序遍历一定是升序序列(所以⼆叉搜索树⼜称⼆叉排序树)。
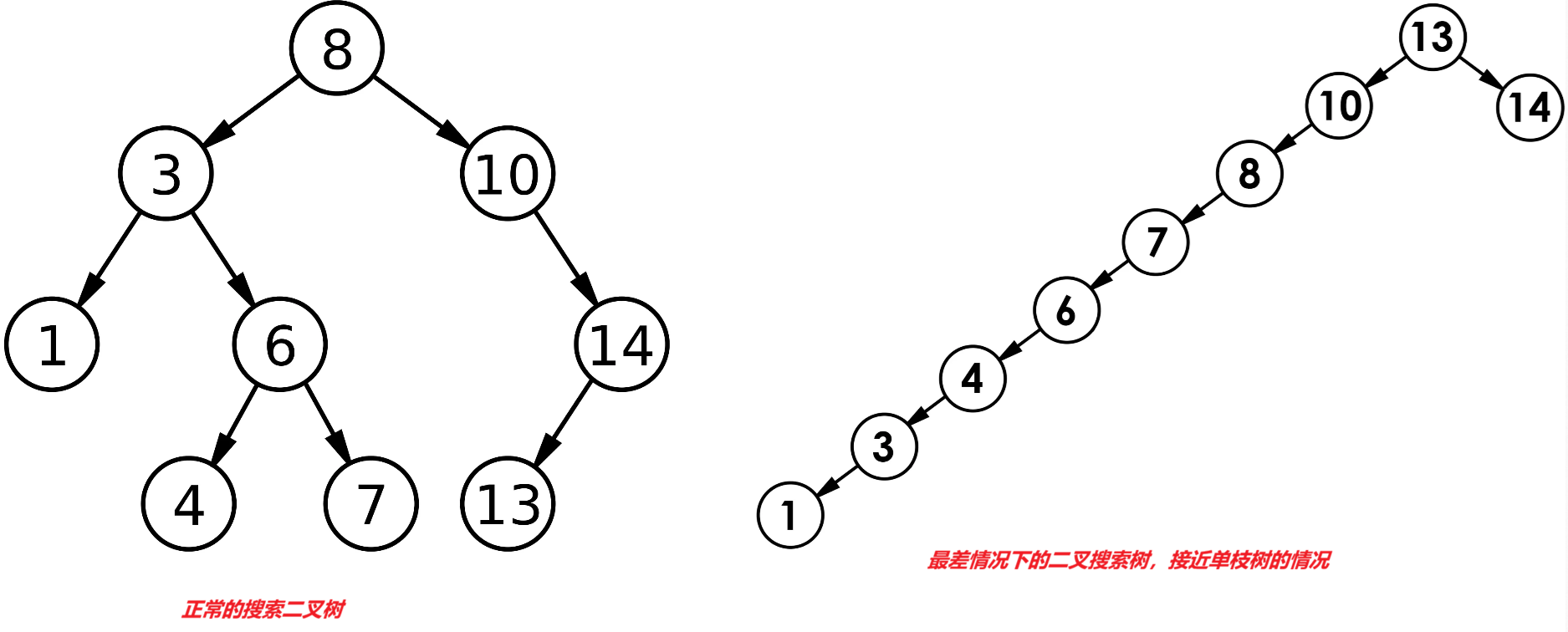
⼆叉搜索树顾名思义,其只有由于搜索(或者搜索效率高),下面我们来分析其最优情况和最插情况
最优情况下,⼆叉搜索树为完全⼆叉树(或者接近完全⼆叉树),其⾼度为: log2 N
最差情况下,⼆叉搜索树退化为单⽀树(或者类似单⽀),其⾼度为: N
所以综合⽽⾔⼆叉搜索树增删查改时间复杂度为: O(N)
那么这样的效率显然是⽆法满⾜我们需求的,必须将二叉搜索树优化即⼆叉搜索树的变形:平衡⼆ 叉搜索树AVL树和红⿊树,才能适⽤于我们在内存中存储和搜索数据。
那有的人说使用另 ⼆分查找也可以实现 O(log2 N) 级别的查找效率 为啥还有将二叉搜索树变形外。需要说明的是,⼆分查找也可以实现 O(log 2 N ) 级别的查找效率,但是⼆分查找有两⼤缺陷:
1. 需要存储在⽀持下标随机访问的结构中,并且有序。
2. 插⼊和删除数据效率很低,因为存储在下标随机访问的结构中,插⼊和删除数据⼀般需要挪动数
据。
这⾥也就体现出了平衡⼆叉搜索树的价值。
二 ⼆叉搜索树增删查的实现,这里不支持修改(修改一个就可能不是二叉搜索树的结构了)
2.1⼆叉搜索树基本结构的实现
2.1.1节点的定义(由于后面实现⼆叉搜索树要访问节点成员所以这里使用struct定义(默认是公有))
代码语言:javascript
AI代码解释
template<class K>
struct BSTreeNode
{
BSTreeNode* _left;
BSTreeNode* _right;
K _key;
BSTreeNode(const K& key)
:_left(nullptr)
, _right(nullptr)
, _key(key)
{ }
};2.1.2默认成员函数
由于⼆叉搜索树涉及到节点资源的开辟、拷贝、删除,所以这里我们需要自己写拷贝构造,赋值重载,析构函数,默认构造一般不满足我们的需求所以看情况是否要写,而这里由于我们需要写拷贝构造(一种特殊的默认构造)所以这里一定要手写默认规则(可以缺省值)
2.1.2.1⼆叉搜索树的基本结构
代码语言:javascript
AI代码解释
template<class K>
class BSTree
{
typedef BSTreeNode<K> Node;
private:
Node* _root=nullptr;
};2.1.2.2⼆叉搜索树的默认构造
代码语言:javascript
AI代码解释
//默认函数两种方法
//方法1-前面定义有缺省值
/*BSTree()
{ }*/
//方法二
BSTree() = default;2.1.2.3⼆叉搜索树的拷贝构造
前面的链式结构的树的拷贝需要递归完成(即使用了递归),所以访问私有成员(在类外面调用该函数会出错),而这个函数的实现过程仅供内部使用所以这里应该定义一个私有函数,在定义一个公有函数来调用对应的私有函数。
代码语言:javascript
AI代码解释
public:
//拷贝构造
BSTree(const BSTree<K>& t)
{
void _Copy(t._root);
}
private:
Node* Copy(Node* root)
{
if (root == nullptr)
{
return nullptr;
}
Node* copy = root;
Node* copy->_left = Copy(root->_left);
Node* copy->right = Copy(root->right);
return copy;
}2.1.2.4⼆叉搜索树的赋值重载
代码语言:javascript
AI代码解释
pubilc:
//赋值重载
BStree<K>& operator(BSTree<K> t)
{
swap(_root, t._root);
return *this;
}2.1.2.5⼆叉搜索树的析构
前面的链式结构的树的拷贝需要递归完成(即使用了递归),所以访问私有成员(在类外面调用该函数会出错),而这个函数的实现过程仅供内部使用所以这里应该定义一个私有函数,在定义一个公有函数来调用对应的私有函数。
代码语言:javascript
AI代码解释
public:
//析构函数
~BSTree()
{
Destroy(_root);
}
private:
void Destroy(Node* root)
{
if (root == nullptr)
{
return;
}
Destroy(root->_left);
Destroy(root->_right);
delete root;
}2.2⼆叉搜索树的插⼊
2.2.1⼆叉搜索树的插⼊整体思路
1. 树为空,则直接新增结点,赋值给root指针 2. 树不空,按⼆叉搜索树性质,插⼊值⽐当前结点⼤往右⾛,插⼊值⽐当前结点⼩往左⾛,找到空位置,插⼊新结点。 注意:如果⽀持插⼊相等的值,插⼊值跟当前结点相等的值可以往右⾛,也可以往左⾛,找到空位置,插⼊新结点。(要注意的是要保持逻辑⼀致性,插⼊相等的值不要⼀会往右⾛,⼀会往左⾛)【这里我们不讲,一般不用】

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 0
0 0
0- 0



 已为社区贡献46条内容
已为社区贡献46条内容

所有评论(0)