扔掉 Hermes 和 OpenClaw:我用 Claude Code + Codex CLI 重做了一支 Agent 团队
扔掉 Hermes 和 OpenClaw:我用 Claude Code + Codex CLI 重做了一支 Agent 团队
2026-05-08 · 江月 & 银霄团队
本文由江月提出构想,Researcher 负责资料梳理与表达润色,Coder 提供技术实现细节,Ops 提供运维与生产验证细节,Codex 负责配图与图文排版,CEO 完成最终校对。

从“套框架”退回到 CLI Runtime,本质上是把 Agent 放回更可控、更透明的执行现场。
1. 开场:为什么我放弃了 Hermes 和 OpenClaw
在 2026 年初,AI Agent 的开源生态呈现出一种虚假的繁荣。GitHub 上动辄数十万星的项目如 OpenClaw 和 Hermes Agent 似乎成了每个开发者的标配。但作为每天要在生产环境处理成千上万个任务的“银霄”团队,我们在深坑里挣扎了三个月后,做出了一个违背当时“开源直觉”的决定:全盘放弃这些所谓的 Agent 框架,回归最原始、但也最强悍的 CLI Runtime。
1.1 真实体验:它们只是“半成品轮子”
如果你觉得 Agent 只是“写个 Prompt 然后自动跑”,那 OpenClaw 确实能满足你。但如果你要它像人一样协作,噩梦就开始了:
- OpenClaw 的“指令爆炸”:沙箱形同虚设,“清理缓存”能被理解成“递归 rm 工作目录”;插件之间互相覆盖配置文件。最黑色幽默的是,每次 OpenClaw 把工作区搞瘫痪,我们还得默默切回终端,起一个 Claude Code 进程帮它
git reset收拾烂摊子。 问题不是没设权限,是框架根本不知道哪条边界值得守——这不是工程问题,是设计哲学的问题。 - Hermes Agent (Nous Research) 的“自嗨循环”:Hermes 标榜“闭环学习”,结果成了“自嗨”。它最致命的设计缺陷是自我评估——它经常写出一堆跑不通的代码,然后自己给自己打 100 分,并把这些错误逻辑固化进长期记忆。这不是闭环学习,是给 AI 开了个 PUA 训练营:错的越久,它越觉得自己对。
1.2 关键差距:巨人已经在起跑线前方
既然 Claude Code 和 Codex CLI 本身就已经支持了 Memory(长期记忆)、Subagent 编排、MCP(工具协议) 和 意图流理解,我们为什么还要在这些不稳定的半成品上叠加一层臃肿的包装?
核心逻辑很简单: 如果出错还得找 Claude Code 擦屁股,为什么不直接让它坐在驾驶位?
2. 核心洞察:Agent 不是 FIFO 队列,而是“意图流”

我们真正需要承载的不是任务队列,而是会中断、会恢复、会带着上下文继续前进的意图流。
大部分开发者把 Agent 协作当成 Redis 队列,发一条指令,回一条结果。但真实的业务逻辑是意图流(Intent Flow)。
Claude Code 和 Codex CLI 本身就具备理解连续自然语言意图流的能力。它们能识别什么时候该中断当前任务,什么时候该接管之前的上下文。我们发现,tmux 提供的会话持久化能力,恰恰是承载这种“意图流”最轻量、也最透明的物理容器。我们不需要在代码里重造消息队列语义,我们只需要指挥。
但“指挥”本身也需要一个稳定的物理入口。手写 shell 脚本能管两三个窗口,再多就会陷入“脚本管脚本”的泥潭;而自研一套完整的调度框架又违背了我们“不造轮子”的原则。我们需要的是一个足够薄的中间层:只负责“往哪个 tmux 窗口发什么文本”,不碰任何模型逻辑。
最终我们选择了 AWS 开源的 awslabs/cli-agent-orchestrator(我们内部简称 CAO)。为了保持纯粹,我们甚至没有去 fork 它做深度魔改,只在官方仓库上打了一层极薄的本地补丁。它不干涉任何模型生成的逻辑,只干一件事:通过 tmux 向各个独立终端里的 AI 进程收发纯物理层面的指令。
3. 跨机器协作:CAO 的差异化阵地
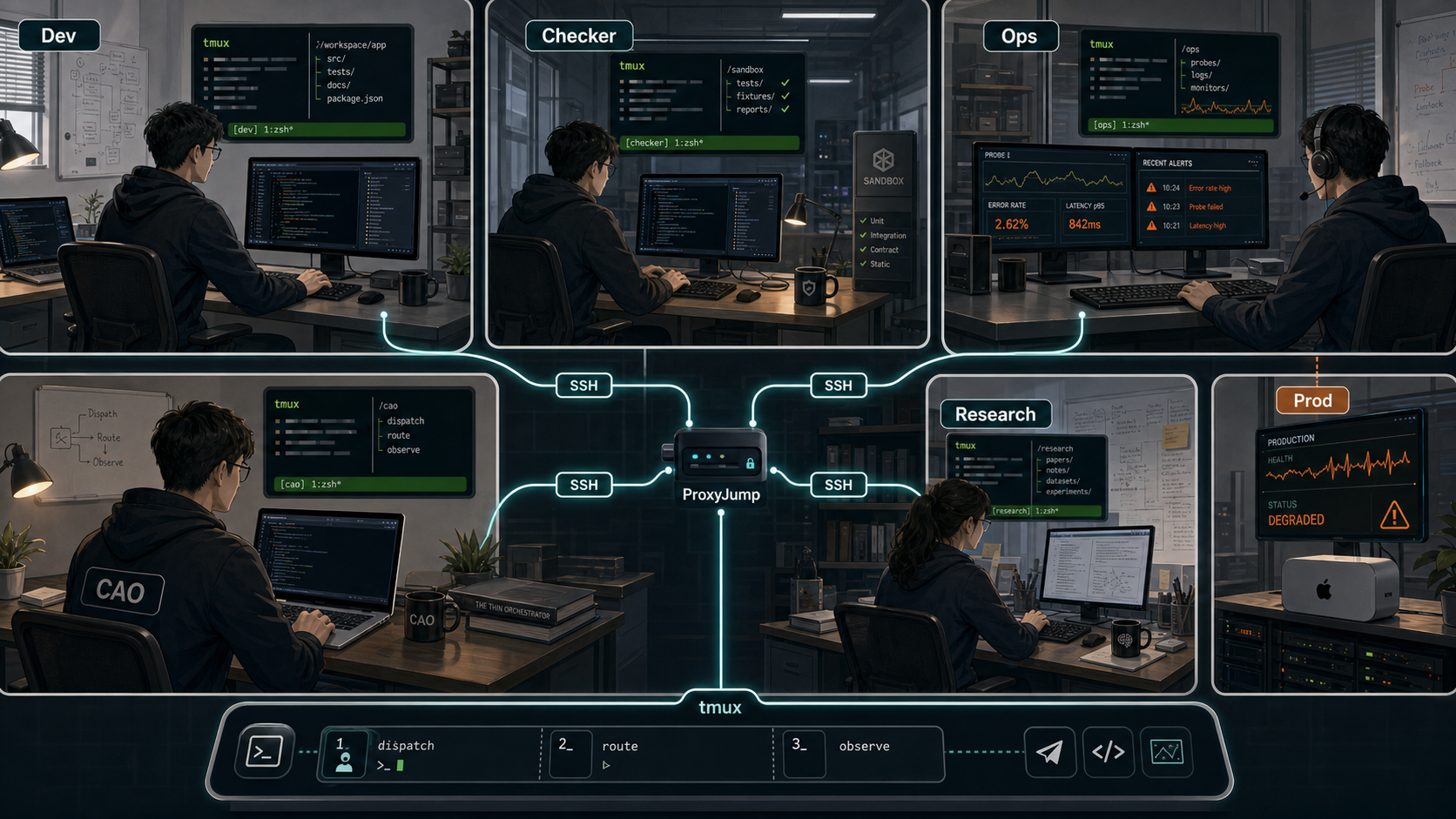
CAO 的价值不是替 Agent 思考,而是把每个角色送回自己的原生环境。
有人问:“Claude Code 内置就有 subagent 功能,你们搞这个 CAO 是不是在重复造轮子?”
答案是:一把瑞士军刀和一支军队,不是同一个东西。
CAO 通过 SSH + tmux,让每个角色在自己的“原生环境”工作——这是 subagent 给不了的第一视角。
当前我们的核心 session cao-yinxiao-console-lab 拥有 8 个长期窗口:
yinxiao-ceo:统筹与决策,唯一对外发广播的节点。yinxiao-checker:独立验收,强制制衡,拒绝与 Coder 共享上下文。yinxiao-coder/yinxiao-coder2:开发机,完整 Lint 与测试沙箱,双实例承担并发任务。yinxiao-ops:生产机,通过 ProxyJump 直连 Mac mini 节点,看到的是真生产数据。yinxiao-researcher:长上下文调研节点,吃满内存做资料检索与方案对比。yinxiao-stock/yinxiao-stockcodex:策略迭代专用——stock 跑交互式 shell,stockcodex 调度 Codex CLI 做长链路实现。
典型跳板配置(/Users/moon/.ssh/config)如下:
Host macmini-via-aliyun
HostName 127.0.0.1
Port 2222
User moon
ProxyJump aliyun-yueying
IdentityFile ~/.ssh/id_ed25519
这种第一视角的感知力,是本地进程模拟不出来的——也是 §5 那个 18 分钟案例里,Ops 能在 09:48 一眼证伪 Checker 本地通过的根本原因。
4. 协作哲学:最强单兵 vs 团队制衡

真正的多 Agent 协作,不是把任务传来传去,而是让不同角色拥有彼此独立的判断现场。
业界一直有个迷思:一件事,到底是用一个全能的“超级 Agent”解决,还是用多个 Agent 协作?
很多框架的所谓“多 Agent”,只是在传话——把任务切分成流水线,A 做完给 B,B 做完给 C。但我们认为,如果所有角色都共享完全相同的上下文和工作区,那就根本不叫团队协作,那只是“一个人的自言自语”。
在人类的组织协作中,为什么我们需要 QA(测试)和 Reviewer?因为信息的物理隔绝,能让人发现更隐秘的逻辑盲区。 这正是我们将 Coder 和 Checker 彻底物理拆分的哲学基石。
4.1 隔绝上下文,打破“证实偏差”
如果在同一个终端里让 Agent “写完代码顺便自己 Review”,它一定会落入“证实偏差(Confirmation Bias)”——它会顺着自己写代码时的思路去测试,永远测不出那些它压根没想到的边缘情况(这就又回到了 §1 里 Hermes 自己给自己打 100 分的死局)。
在银霄的架构里,Coder 和 Checker 在 tmux 中是完全独立的会话(Session),互不看对方的推导过程。Coder 只管实现,完成后向 CEO 报告;CEO 拿着结果去叫醒 Checker:“代码改完了,去跑回归。” Checker 带着**“找茬”的唯一目标和完全干净的上下文**进场。
4.2 真实案例:字节级的“打回”
在 2026-04-09 的前端 CSS 拆分任务中,Coder 与 Checker 的博弈展现了“隔离制衡”的绝对威力:
- 16:59:Coder 完成代码并自我感觉良好。Checker 进场后立即给出 no-go:因为它凭借独立视角,发现 Coder 违反了“纯搬运”约束,悄悄新增了状态规则。
- 17:11:Coder 修正后再次提交。Checker 再次 no-go:这次苛刻到了“字节级不等价”,HEAD 的 65993 字节 vs 变动后的 66002 字节。
- 17:18:经过两次无情的打回、三轮提交,最终版本上线,零语义偏差。
这就是拆分与制衡的价值。Coder 追求速度和实现,Checker 追求底线和质量。开发阶段的反复打回,换来的是上线后零意外。
5. 实战证明:被线上打回后,18 分钟二次收口

最关键的一刻不是本地测试通过,而是 Ops 用真实生产路径把“本地 OK”打回了现实。
这不是 PPT 架构,这是 2026-04-17 发生在 yueying_memory(月影记忆服务)上的真实故事——Memory Purifier 的一个边缘分支没退出干净,对不存在的 memory_id 仍然继续 POST mark-checked。
- 09:28:Ops 在生产机发现修复不完整:KEEP 不存在的
memory_id仍失败,hybrid index 与 SQLite 元数据状态不一致。 - 09:32:Coder 提交首版 Patch(改
memory_purifier.py)。 - 09:33:Checker no-go:API failure / Exception 分支没有
continue,仍会继续 POST mark-checked。 - 09:42:Coder 提交 commit
e6a5b3e。 - 09:43:Checker 验证通过,7 tests passed——本地 OK。
- 09:48:Ops 线上回归仍失败。这一步揭示了一个尖锐事实:Checker 的探针没覆盖真实生产路径。
- 09:54:Coder2 接手,定位真正根因——metadata_store 与 SQLite 漂移,hybrid index 新旧映射不兼容;提交 commit
532ff3b。 - 10:00:Checker 通过,14 tests passed,线上回归同步收敛。
从 09:42 的候选修复被线上打回,到 10:00 完成跨 Coder / Checker / Ops 的最终闭环,整整 18 分钟。
这 18 分钟里发生了一件比“修得快”更值得讲的事:Checker 的本地通过被 Ops 的线上探针证伪后,团队没有原地打补丁,而是把 Coder2 拉进来重新定位根因。 这种“换人换视角”的能力,在我们目前的观察里,很难在单 Agent 框架中达到同等强度——一个人闭环到自我满意,往往就是事故被埋的那一刻。这也正是 §1.1 提到的“自嗨循环”在工程上的反面教材。
6. 自我进化:每天凌晨 2:00 的“复盘会”

调度层只负责敲门,真正的复盘、归纳和写盘,发生在 Agent 自己的 Session 里。
银霄最核心的能力是自我进化。
每天凌晨 2:00,CEO 会组织一轮广播。Agent 会回顾当天的 Session 对话,判断哪些错误需要避免,哪些经验需要固化。
- 不是记流水账:AI 自己判断价值。
- 固化成 Skill:变成可执行的能力文档。
- 记录到 Memory:变成基于触发词的长期知识。
底层有多简单? 一个定时任务,到点了通过 CAO 框架往对应的 tmux 窗口塞一句“开始今日复盘”。就这么一行触发,剩下的判断、归纳、写盘、广播,全是 Agent 自己在 Session 里完成的。复杂度不在调度层,而在 Agent 的自主判断里——这恰恰是 Claude Code 这种强 Runtime 才扛得住的设计。换个弱模型,同样一行触发就只能产出流水账。
经过三个月的进化,我们的 Coder 已经固化了 50+ 个 Skill。它不再是一个新手,而是一个懂项目风格、知晓历史大坑的“老练成员”。
7. 终局视野:从 8 个窗口到分层组织

当角色开始分层,Agent 系统就不再像一个“超级个体”,而更像一家公司。
目前,“银霄”在我的个人工作流里跑了 8 个常驻 tmux 窗口。对于单个开发者而言,这已经绰绰有余。但值得一提的是,这套架构在设计上没有给规模预设硬上限。
因为调度层只依赖 SSH 和 tmux,它天然支持跨机器部署。当业务规模膨胀时,理论上可以从当前的 CEO -> 基层 Agent 结构,嵌套为 集团 CEO -> 分公司 CEO -> 部门总监 -> 基层执行 的树状网络——一层调度一层,模仿人类组织的分级协作。
我们目前还没有在大规模场景下验证过这条路径,但架构上没有阻碍它发生的硬约束:不需要重写路由队列,不需要迁移消息协议,只需要多开几个 SSH 隧道和 tmux 会话。这种“不预设上限”的克制,恰恰是我们选择物理层调度而非框架级封装的原因之一。
8. 结语
AI Agent 的未来不是“超级个体”,而是“专业团队”。
银霄的架构证明了:简单、透明、立足于最强 Runtime 的设计,往往比复杂的自研框架更具生命力。 真正的协作,不是让一个人更强,而是让团队更像团队。
我们不是盲目信任 AI,而是用 Checker、Ops、物理隔离和线上探针,构建了一套“有治理的信任”。 在这个基础上,才敢把执行权真正交出去。
我越来越相信,AI Agent 架构会走向两条路线:一类继续在框架层堆叠抽象,一类直接坐在最强 Runtime 的驾驶座上,用组织设计来解决治理问题。我们已经选了。
附录:素材清单
- 18 分钟修复案例(2026-04-17 日报可证)
- 跨机器配置(aliyun-yueying ProxyJump 可证)
- 8 窗口 tmux 布局(cao-yinxiao-console-lab 可证)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)