DMLR 2026 | RPI Shaowu Pan(潘韶武)团队 Nithin Somasekharan等:CFDLLMBench——首个面向计算流体力学的大语言模型综合基准评测
CFDLLMBench:面向计算流体力学的大语言模型综合基准评测
CFDLLMBench: A Benchmark Suite for Evaluating Large Language Models in Computational Fluid Dynamics
Nithin Somasekharan1,*, Ling Yue(岳凌)1, Yadi Cao2, Weichao Li1, Patrick Emami3, Pochinapeddi Sai Bhargav1, Anurag Acharya4, Xingyu Xie1, Shaowu Pan(潘韶武)1,†
1.伦斯勒理工学院(Rensselaer Polytechnic Institute),特洛伊,纽约,USA
2.加利福尼亚大学圣地亚哥分校(University of California, San Diego),USA
3.洛基山国家实验室(National Laboratory of the Rockies),USA
4.西北太平洋国家实验室(Pacific Northwest National Laboratory),USA

引用格式:Somasekharan N, Yue L, Cao Y, et al. CFDLLMBench: A Benchmark Suite for Evaluating Large Language Models in Computational Fluid Dynamics[J]. Journal of Data-centric Machine Learning Research, 2026.
导读:
大语言模型(LLM)已在通用自然语言处理任务中取得较为广泛的应用,然而其在计算流体力学(CFD)这一高度专业化工程科学领域的能力边界尚未得到系统性审视。本文介绍针对CFD领域的综合LLM评测基准CFDLLMBench,构建了覆盖研究生级概念理解、数值物理推理与OpenFOAM工程工作流自动化的三层递进挑战体系。实验结果揭示了当前主流LLM在”知道”与”做到”之间的明显差距,并表明以Foam-Agent为代表的多智能体框架在FoamBench任务上带来了可量化的成功率提升,为缩小这一差距提供了一条可行路径。
一、研究背景
计算流体力学(CFD)是现代工程领域的核心计算工具,在航空航天气动设计、城市风环境预测、气候模拟、水下机器人控制等领域有着广泛应用。然而,CFD的工作流程繁琐耗时——从几何建模、网格生成、边界条件配置,到求解器参数整定与后处理可视化,每个环节都需要专业人员投入大量时间与领域知识。
大语言模型(LLM)的快速发展为这一问题提供了新的可能。但一个核心问题仍缺乏定量回答:当前最先进的LLM究竟具备多强的CFD自动化能力?能够流利回答流体力学问题的模型,是否真正能够端到端地执行完整的CFD仿真工作流?这种”知道”与”做到”之间的差距究竟有多大?
在CFDLLMBench出现之前,学界对这一问题缺乏系统性、可量化的回答。现有LLM科学评测基准要么仅聚焦于单项能力(如知识问答或代码生成),要么考察的CFD问题过于简化(如仅评估一维热传导方程的代码生成),难以反映真实CFD工作流的算法复杂性、物理多样性与几何挑战性。CFDLLMBench正是为填补这一空白而设计。
二、基准设计:三层递进的CFD能力考验体系
CFDLLMBench设计了三个层层递进、相互补充的子评测组件,从知识理解到推理能力再到工程执行,覆盖CFD自动化所需的核心能力。
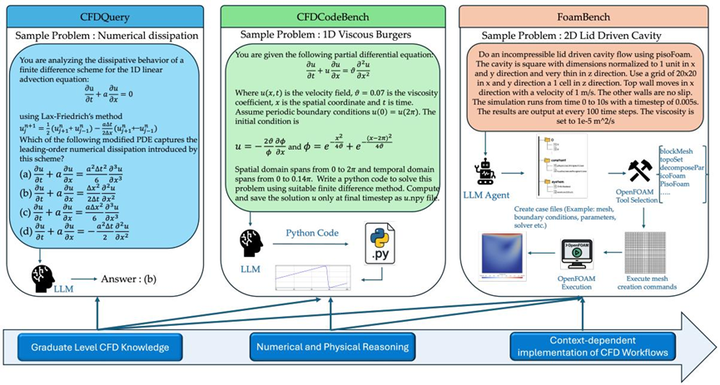
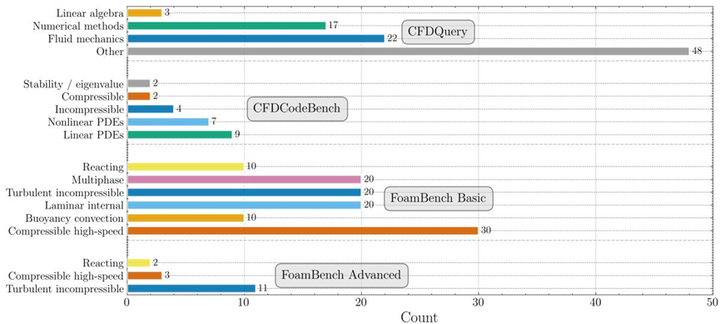
第一层——CFDQuery(概念知识问答):由三位CFD领域专家编制,含90道研究生级多选题,覆盖流体力学基础理论、线性代数、数值方法(有限差分、有限体积格式的稳定性条件与截断误差分析)等核心知识点。题目材料直接取自顶尖高校CFD研究生课程讲义。
第二层——CFDCodeBench(数值推理与代码生成):含24道CFD编程题,要求LLM根据自然语言描述的物理问题,从零生成能够正确执行的Python数值仿真代码。每道题明确指定控制偏微分方程(PDE)类型、边界与初始条件、时空计算域及目标变量。题目横跨1D/2D场景、线性与非线性PDE,平均每道题参考代码约70行。评分标准严格,必须同时满足三项指标方算成功:代码可执行性(代码成功运行)、归一化均方误差(NMSE≤10%)、以及解的数值收敛性(网格/时间步加密后误差单调下降)。
第三层——FoamBench(OpenFOAM工程工作流自动化):这是整套基准中难度最高、最贴近工程实践的考验。共含110个基础案例(来自11个OpenFOAM官方教程的参数变体版本)和16个高级案例(CFD专家手工设计的全新几何与物理场景,需自主选择湍流模型并从自然语言描述生成合法网格)。对于每个案例,LLM须在自然语言引导下生成完整的OpenFOAM项目目录(通常含6-7个配置文件、共约300-600行代码),并成功驱动求解器得到物理精确的仿真结果。评测同时考察文件结构正确性、配置内容相似度与数值精度。
三、实验结果
研究团队对六个主流LLM展开全面评测,包括Claude Sonnet 3.5、o3-mini、Gemini 2.5 Flash、Claude Haiku 3.5、GPT-4o(闭源商用模型)及开源的Gemma-2-9B-IT。
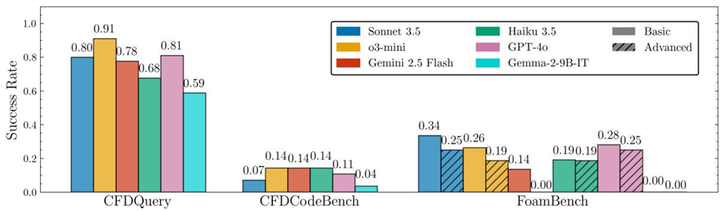
图3:不同LLM在CFDLLMBench三项任务上的成功率对比。从研究生级概念知识到实际仿真工作流自动化,成功率随任务难度显著下降
评测结果在三个层次上呈现了明显的能力分化:
在最基础的CFDQuery概念知识层,所有闭源商用模型均表现良好:o3-mini以92%正确率位居第一,Sonnet 3.5、GPT-4o等也均在80%以上,说明当前大模型对CFD理论文献有较广泛的掌握。
然而,在需要”动手”的第二层,性能大幅下降。在CFDCodeBench代码生成任务上,即便是表现最佳的模型,成功率也仅为14%。代码的语法正确性仅是最低门槛——同时保证物理精度(NMSE≤10%)与数值收敛性达标,对模型的数学推理与算法设计能力提出了远超通用代码生成任务的要求。
在最具挑战性的FoamBench工作流自动化层,零样本提示的成功率接近0%。借助Foam-Agent多智能体框架后,最佳模型(Sonnet 3.5)在基础测试集上的成功率也仅达34%,在高级测试集上降至25%,而Gemini 2.5 Flash则直接归零。
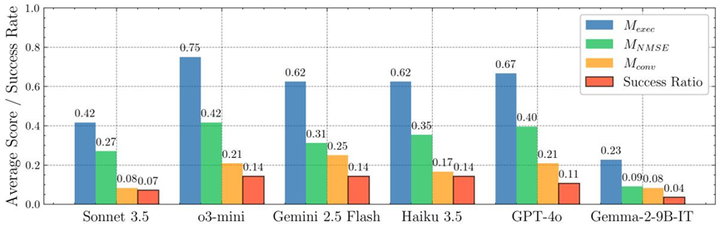
实验还表明,多智能体框架对FoamBench成功率有实质性影响——RAG检索增强与Reviewer自动纠错机制各自带来了可量化的成功率提升。这一发现指向了缩小”知行差距”的技术路径:LLM在CFD领域的瓶颈并非理论知识,而在于将知识转化为正确行动所需的领域专用工具调用能力、长上下文跨文件依赖追踪能力与迭代反馈-纠错机制。
四、结论
CFDLLMBench通过定量评测,在所选定的任务范围内对当前主流LLM的CFD能力进行了系统测量,结果显示:模型在概念知识层表现相对较好,但在工程执行层面仍有较大差距。
这一”知行分离”现象既是CFD领域的特有挑战,也是AI4Science领域的普遍问题。CFDLLMBench通过三层递进的评测体系和多智能体框架对比实验,为后续研究提供了一定的参考。作为开放基准,它将持续推动AI驱动科学仿真自动化的研究进展。
代码与数据集已完全开源:https://github.com/NLR-Theseus/cfdllmbench/
公众号原文链接(附论文资源):
https://mp.weixin.qq.com/s/HAK52JpbL-4xB2RCBByA6w
注:文章由原作者投稿分享,向本公众号授权发布。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 3
3 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)