LangChain入门(四)
本文主要讲解LangChain的核心组件(消息,提示词模板,少样本提示)。
1.消息
消息是聊天模型中的通信单位,用于表示聊天模型的输入和输出。以及可能与对话关联的任何其他上下文或元数据。
LLM消息都有一个角色和内容以及因LLM的不同而不同的附加元数据。
1.1角色分类
消息角色:系统角色,用户角色,助理角色,工具角色。
系统角色用于告诉聊天模型如何行为并提供额外的上下文。
用户角色表示用户与模型交互的输入,通常以文本或其他交互式输入的形式。
助理角色表示来自于模型的响应。
工具角色用于在检索外部数据或将工具调用的结果传回模型的消息。
1.2消息内容
1.3消息其他元数据
| 元数据 | 描述 |
| ID | 消息标识符 |
| Name | 名称允许区分具有相同角色的不同实体。并非所有型号都支持此功能 |
| Metadata | 有关消息的其他信息,例如时间戳、令牌使⽤情况 |
| Tool Calls | 模型发出的⼀个或多个⼯具的调用请求 |
[
{
"role": "user",
"content": "Hello, how are you?",
},
{
"role": "assistant",
"content": "I'm doing well, thank you for asking.",
},
{
"role": "user",
"content": "Can you tell me a joke?",
}
]1.2LangChain消息
openai_model = init_chat_model("gpt-4o-mini", model_provider="openai")
anthropic_model = init_chat_model("claude-3-5-sonnet-latest",
model_provider="anthropic")
deepseek_model = init_chat_model("deepseek-chat", model_provider="deepseek")
google_genai_model = init_chat_model("gemini-2.5-flash",
model_provider="google_genai")
model = init_chat_model(...)对于输入输出,统一使用LangChain的消息格式。它主要分成五种:
1)SystemMessage:用于启动AI模型的行为并提供额外的上下文。
2)HumanMessage:人类消息表示用户与模型交互的输入。
3)AIMessage:这是来自于模型的响应。其中可以包括文本或调用工具的请求。
4)AIMessageChunk:通常在生成聊天模型时流式传输响应。
5)ToolMessage:这表示一条角色为tool的消息,其中包含调用工具的结果。
1.3缓存历史消息
from langchain_core.messages import HumanMessage, AIMessage
from langchain_openai import ChatOpenAI
model=ChatOpenAI(model="gpt-4o-mini")
messages=[
HumanMessage(content="I am Bob"),
AIMessage(content="Hello Bob! How can I assist you today?"),
HumanMessage(content="What is your name?"),
]
model.invoke(messages).pretty_print()从结果看只需要将历史信息重新发给聊天模型就可以实现多轮对话的功能。
1.4管理历史信息
我们首先要理解多轮对话的核心概念:上下文窗口。它指的是LLM在一次处理请求的时候所能查看和处理的最大token数量。token在自然语言处理中它是文本的基本单位。它并不等同于一个单词而是一个更细粒度的划分。
对于英文,1个token近似于4个字符,对于中文一个汉字近似于1.5个token。
形象来说,上下文窗口就像一个固定大小的工作台,再把token比作一个积木零件,把大模型比作一个工匠。工匠需要频出模型,必须把所需的零件放在工作台上,一边拼装一边把品好的部分也放在工作台,整个过程中所有积木的总数不能超过工作台的最大容量。
2.提示词模板
2.1概念
提示词模板是被广泛于应用到构建大语言模型应用的各个环节。
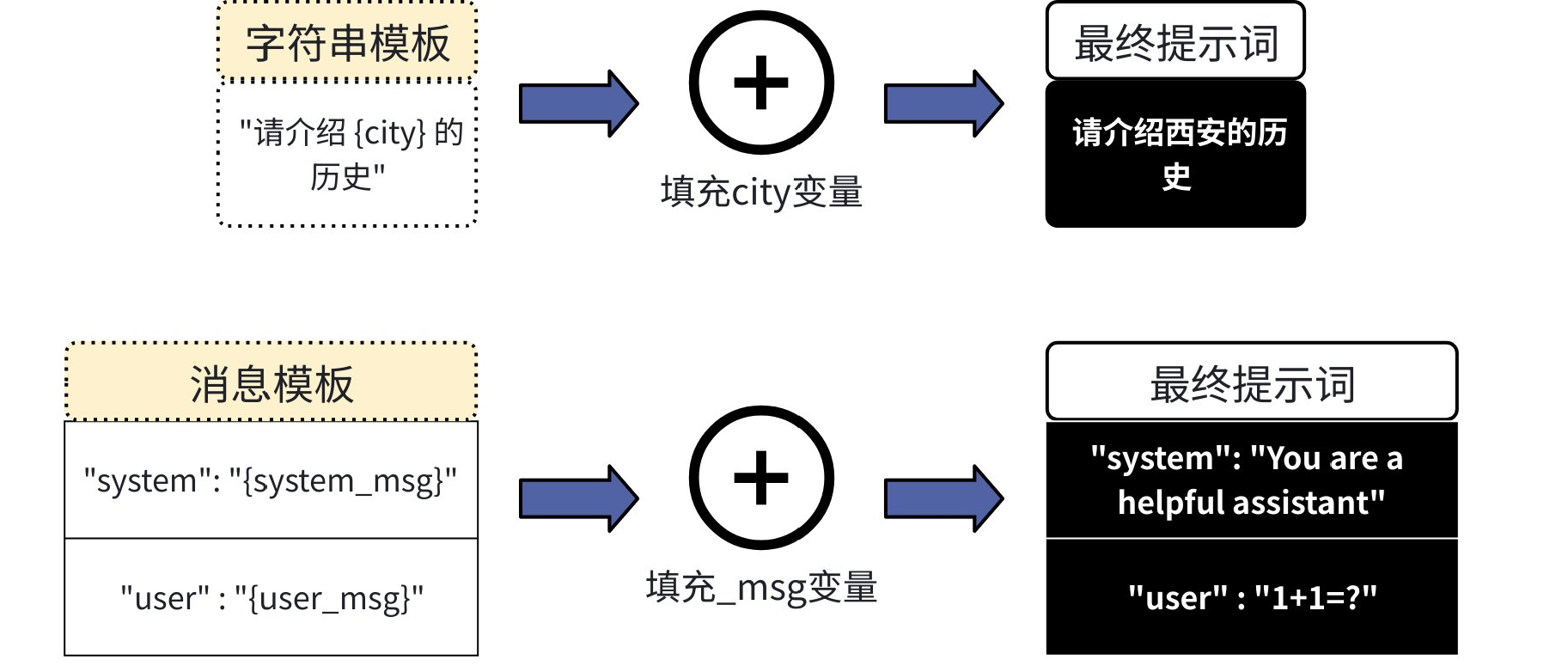
它类似于编程中的字符串格式化的功能。你创建一个带有占位符的模板然后在运行的时候,用具体的值填充这些占位符,从而生成一个最终发送给LLM的完整提示词。
2.2用法
2.2.1字符串模板
LangChain提供了PromptTemplate类来轻松实现这一功能。它实现了标准的Runnabl接口。示例如下:
from langchain_core.prompts import PromptTemplate
prompt_template = PromptTemplate.from_template(("Translate the following into {language}"))
print(prompt_template.invoke({"language":"chinese"}))PromptTemplate这个类参数如下:
template:提示模板
input_variables:需要其值作为提示输入的变量的名称列表。
内置方法:
from_template():从模板定义提示模板。方法返回一个PromptTemplate实例。
因此上述定义提示模板的方式还可以这样:
prompt_template = PromptTemplate(
input_variables=["language"],
template="Translate the following into {language}",
)2.2聊天消息模板
from langchain_core.prompts import ChatPromptTemplate
prompt_template=ChatPromptTemplate(
[
("system","translate into {language}"),
("user","{text}"),
]
)
#[SystemMessage(content='translate into Chinese', additional_kwargs={}, response_metadata={}),
# HumanMessage(content='what is your name?', additional_kwargs={}, response_metadata={})]
messagesValue=prompt_template.invoke(
{
"language":"Chinese",
"text":"what is your name?"
}
)
messages=messagesValue.to_messages()
print(messages)现在我们可以将结果发送给任何一个LLM来获取答案。
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
prompt_template=ChatPromptTemplate(
[
("system","translate into {language}"),
("user","{text}"),
]
)
#[SystemMessage(content='translate into Chinese', additional_kwargs={}, response_metadata={}),
# HumanMessage(content='what is your name?', additional_kwargs={}, response_metadata={})]
messagesValue=prompt_template.invoke(
{
"language":"Chinese",
"text":"what is your name?"
}
)
model=ChatOpenAI(model="gpt-4o-mini")
messages=messagesValue.to_messages()
parser=StrOutputParser()
chain=model | parser
print(chain.invoke(messages))由于ChatPromptTemplate同样实现Runnable接口,因此我们可以通过链来调用。
如下所示:
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
prompt_template=ChatPromptTemplate(
[
("system","translate into {language}"),
("user","{text}"),
]
)
#[SystemMessage(content='translate into Chinese', additional_kwargs={}, response_metadata={}),
# HumanMessage(content='what is your name?', additional_kwargs={}, response_metadata={})]
# messagesValue=prompt_template.invoke(
# {
# "language":"Chinese",
# "text":"what is your name?"
# }
# )
model=ChatOpenAI(model="gpt-4o-mini")
# messages=messagesValue.to_messages()
parser=StrOutputParser()
chain= prompt_template|model | parser
#print(chain.invoke(messages))
for token in chain.stream(
{
"language":"English",
"text":"我叫斯蒂芬"
}
):
print(token,end="|")2.3消息占位符
在上面的ChatPromptTemplate中我看到了如何格式化两条信息,每条消息都是一个字符串。但是如果我们希望将消息插入到特定位置怎么办?使用MessagePlaceholder。
它负责在特定位置添加消息列表。
from langchain_core.messages import HumanMessage, AIMessage
from langchain_core.prompts import PromptTemplate, MessagesPlaceholder, ChatPromptTemplate
prompt_template = ChatPromptTemplate([
("system","你是一个聊天助手"),
MessagesPlaceholder("msgs")
])
messages_to_pass=[
HumanMessage(content="中国是哪里?"),
AIMessage(content="中国首都是北京"),
HumanMessage(content="那法国呢")
]
formatted_prompt=prompt_template.invoke({"msgs":messages_to_pass})
print(formatted_prompt)2.4使用LangChain Hub的提示词模板
LangChain Hub是一个用于上传浏览拉取和管理提示词的地方。
from openai import Client
from langchain_openai import ChatOpenAI
from TEST23 import lazy_prompt
client=Client()
prompt=client.pull_prompt("hardkothai/prompt-maker",include_model=True)
model=ChatOpenAI(model="gpt-4o-mini")
chain=model|prompt
while True:
task=input("\n你的任务是什么?(输入quit退出聊天)\n")
if task=="quit":
break
lazy_prompt=input("\n你当前的提示是什么?(输入quit退出聊天)\n")
if lazy_prompt=="quit":
break
print("\n Response:")
chain.invoke({'lazy_prompt':lazy_prompt,'task':task}).pretty_print()3.少样本提示
少样本提示是一种通过向LLM提供少量具体示例或样本,来教会它如何执行某项特定任务的技术。
3.1实现少样本提示
from langchain_core.prompts import PromptTemplate, ChatPromptTemplate,FewShotChatMessagePromptTemplate
from openai.resources import Chat
examples = [
{"input": "2 🦜 2", "output": "4"},
{"input": "2 🦜 3", "output": "5"},
]
example_prompt = ChatPromptTemplate(
[
("human","{input}"),
("ai","{output}"),
]
)
#[HumanMessage(content='2 🦜 2', additional_kwargs={}, response_metadata={}),
# AIMessage(content='4', additional_kwargs={}, response_metadata={}, tool_calls=[], invalid_tool_calls=[]),
# HumanMessage(content='2 🦜 3', additional_kwargs={}, response_metadata={}),
# AIMessage(content='5', additional_kwargs={}, response_metadata={}, tool_calls=[], invalid_tool_calls=[])]
few_shot_prompt = FewShotChatMessagePromptTemplate(
example_prompt=example_prompt,
examples=examples,
)
print(few_shot_prompt.invoke({}).to_messages())FewShotChatMessagePromptTemplate它也实现了Runnable接口。
类初始化参数说明:example:样本示例。example_prompt:用于格式化单个示例。
类方法说明:.invoke()方法。输入一个字典给他,返回完整的提示内容PromptValue:
1)to_string()可以返回字符串。2)to_messages()可以将提示作为消息列表返回。
2)to_messages()可以将提示作为消息列表返回。
(补充:在Python里面[]代表列表,里面可以放数字、字符串、对象等,可以增删改查。{}代表字典或集合,()代表元组,用圆括号一旦创建就不能改,比列表更安全、更快。)
3.2示例选择器
一旦我们有了示例数据集,就需要考虑提示中应该有多少个示例。在LangChain里面示例选择器可以帮我们从一组示例的集合中根据具体策略选择正确的示例子集构建少样本提示。
选择策略有:
1)Length:根据特定长度内可以容纳的数量选择示例。
2)Similarity:使用输入和示例之间的语义相似性来决定选择哪些示例。
3)MMR:使用输入和示例之间的最大边际相关性来决定要选择哪些示例。
4)Ngram:使用输入和示例之间的ngram重叠来决定要选择哪些示例。
3.2.1按长度选择示例
第一步。给一组输入和输出互为反义词。
第二步。定义PromptTemplate字符串模板,包含输入和输出的两个占位符。
第三步。定义义 LengthBasedExampleSelector长度示例选择器,设置初始示例集与最大长度。
第四步。定义一个FewShotPromptTemplate模板对象,用于实例化示例,将示例转化为聊天信息。
第五步,打印消息结果。
from langchain.agents.middleware import dynamic_prompt
from langchain_core.example_selectors import LengthBasedExampleSelector
from langchain_core.prompts import PromptTemplate, FewShotPromptTemplate
examples=[
{"input": "happy", "output": "sad"},
{"input": "tall", "output": "short"},
{"input": "energetic", "output": "lethargic"},
{"input": "sunny", "output": "gloomy"},
{"input": "windy", "output": "calm"},
]
#定义单个示例长什么样
example_prompt=PromptTemplate(
input_variables=["input", "output"],
template="Input:{input}\nOutput:{output}",
)
#创建【按长度自动选示例】的工具
example_selector=LengthBasedExampleSelector(
examples=examples,
example_prompt=example_prompt,
max_length=25,
# ⽤于获取字符串⻓度的函数,⽤于确定包含哪些⽰例。
# 如果没有指定,它是作为默认值提供的。
# 该函数返回⼀个整数,表⽰字符串中由换⾏符或空格分隔的“单词”数量
# get_text_length: Callable[[str], int] = lambda x: len(re.split("\n| ",x))
)
#组装最终动态提示模板
dynamic_prompt=FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=example_prompt,
prefix="给出每个输入的反义词",
suffix="Input:{adjective}\nOutput",
input_variables=["adjective"],
)
print(
dynamic_prompt.invoke({"adjective":"big"}).to_messages()[0].content
)3.2.2按照语义相似性选择示例
LangChain能根据输入和示例之间的语义相似性来决定选择哪些示例,它能通过查找与输入具有最大余弦相似性的嵌入示例来实现这一点。
实现按语义相似性选择示例的示例选择器是:SemanticSimilarity ExampleSelector类。
内置方法:
from_examples():根据示例集生成语义相似示例选择器。
add_example(example:dict[str,str]):将新示例添加到列表中。
select_examples(input_variables:dict[str,str])->list[dict]:根据输入选择要使用的示例。
如何使用语义相似示例选择器:
1)给一个示例集,输入和输出互为反义词。
2)定义PromptTemplate字符串模板,包含输入和输出两个占位符。
3)定义SemanticSimilarityExampleSelector语义相似示例选择器,设置初始示例集与嵌入API接口。
4)定义一个FewShotPromptTemplate模板对象,用于实例化示例将示例转化为聊天消息。
5)打印消息结果
from langchain_chroma import Chroma
from langchain_core.example_selectors import SemanticSimilarityExampleSelector
from langchain_core.prompts import ChatPromptTemplate, PromptTemplate, FewShotPromptTemplate
from langchain_openai import OpenAIEmbeddings
from langgraph_sdk.schema import Input
examples = [
{"input": "happy", "output": "sad"},
{"input": "tall", "output": "short"},
{"input": "energetic", "output": "lethargic"},
{"input": "sunny", "output": "gloomy"},
{"input": "windy", "output": "calm"},
]
#字符串模板
example_prompt=PromptTemplate(
input_variables=["input","output"],
template="Input:{input}\nOutput:{output}",
)
#语义相似示例选择器
example_selector=SemanticSimilarityExampleSelector.from_examples(
examples,
#嵌入类用于生成用于度量语义相似度的嵌入。
OpenAIEmbeddings(),
#用于存储嵌入并对其进行显示类搜索
Chroma,
#生成示例的数量
k=1,
)
#用于实例化示例的模板
similar_prompt=FewShotPromptTemplate(
#挑选好的参考答案
example_selector=example_selector,
#答案的排版格式
example_prompt=example_prompt,
#题目要求
prefix="给出每个输⼊的反义词",
# 新题目 + 留空让学生写答案
suffix="Input: {adjective}\nOutput:",
#告诉模板:我后面会传入一个变量,叫 adjective(你要查询的单词)
input_variables=["adjective"],
)
print(
similar_prompt.invoke({"adjective": "worried"}).to_messages()[0].content
)3.2.3按照最大编辑相关性选择示例
什么是最大边际相关性?它是一种重新排序算法,使用语义相似性作为基础工具,从一个候选集中挑选出一组节能代表查询主题又彼此多样化的结果。
语义相似性与最大边际相关性对比:
【语义相似性】就像⾯试官衡量每个应聘者与职位要求的匹配度。他会给每个应聘者打⼀个分数。
【最大边际相关性】就像团队经理(MMR算法)要组建⼀个团队。⽬标是选出⼀组“精华”结果,
⽽不是⼀个单⼀结果。
MMR算法的使用场景:
1)推荐系统:推荐与用户兴趣相关但又不同类型的物品。
2)文档摘要:从长文档中选择能代表主旨又包含不同信息的句子,避免摘要内容的重复。
3)RAG:在从知识库中检索完一段相关文档之后,使用MMR进行去重喝多样化的筛选。再交给LLM生成答案。
实现方法:该示例选择器是MaxMarginalRelevanceExampleSelector,内置方法:
from_examples() :根据示例集生成 MMR 示例选择器
输入:
examples:示例列表
exbeddings:初始化的嵌入API接口
vectorstore_cls:向量存储数据库接口类
k:最终要选择的示例的数量。
add_example(example: dict[str, str]) :将新示例添加到列表中。
select_examples(input_variables: dict[str, str]) → list[dict] :根据输入选择要使用的示例。
3.2.4通过ngram重叠选择示例
什么是ngram?它是指一个文本序列中连续的n个词或者字符。
什么是ngram重叠?通过计算他们之间共同拥有的ngram数量来一种衡量两端文本相似度的地方。
实现方式略。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 1
1 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)