ChatGPT Images 2.0五大硬核能力深度实测,以假乱真毫无破绽
过去一年,AI已经把“画图”这件事卷到了极致。
但问题是它画得很好看,却一点也不好用。
ChatGPT Images 2.0发布以来,最近国内外各大社交平台上都出现了网友们基于它生成的作品,比如“为某个产品生成一个电商海报”、“2000年代中国大学生网吧打游戏的照片”、“某个历史文物或某件历史故事的图文介绍”,还有可以以假乱真的“库克在抖音直播间卖华为手机的截图”、“雷军为特斯拉汽车做代言的广告”、“马斯克入职小米汽车的官宣海报”等等。

下面我自己尝试让它生成两张图片:
-
示例1
提示词:
超写实摄影风格,一位中国80后男孩在90年代的水泥院子里打弹珠,地面有粉笔画的圆圈,阳光从侧面照射形成长阴影,远处有老式自行车和砖墙,画面带有轻微胶片颗粒感,色彩偏暖,35mm镜头,f1.8景深生成效果:

你几乎分不清这是AI生成图还是真实照片。
地面的灰尘、弹珠的反光、孩子手指的细微弯曲、墙体的斑驳纹理,全部真实到“过分”。甚至连「90年代空气的质感」,都被完美还原。
这不是“生成图片”,这是在“还原记忆”。
-
示例2
提示词:
一张超写实摄影风格的画面:凌晨4点的上海外滩,细雨刚停,地面湿润反光,霓虹灯在积水中形成拉丝光影;一位穿黑色风衣的年轻女性站在路边,手里撑着透明雨伞,远处黄浦江上有轻微雾气;画面采用电影级构图,50mm镜头,浅景深,皮肤细节真实,衣物有水珠,空气中有湿润雾气颗粒,整体氛围偏冷色调,类似王家卫电影风格生成效果:

图中,地面的反光是有层次的;透明的雨伞是有折射的;风衣有湿度变化;远处灯光在雾气中有真实的“扩散”。
如果你玩过老一代生图模型,你会知道,这种“复杂环境 + 情绪氛围 + 真实质感”的组合,以前几乎不可能稳定生成。但现在,ChatGPT Images 2.0 一段话就可以直接搞定。
ChatGPT Images 2.0 到底强在哪?
ChatGPT Images 2.0到底强在哪里呢?能让广大用户如此追捧、刷屏热议?
可以理解为:AI画图终于“懂你在说什么了”。
它在理解复杂指令、摆放物体位置、处理多元素关系,甚至生成大段清晰文字方面都有明显提升,还支持多种画面比例。同时,画面构图与审美质感也大幅提升,生成的图片不再一眼“AI味”,而更像专业设计作品。
同时,它对不同语言的理解更加准确,并能自动补全细节,如果你不擅长写Prompt,甚至只需要一句简单描述,它就能利用其丰富的视觉与世界知识为你填补细节,把你想法变成可展示、可传播、甚至可用于教学和创作的完整成果。
更大的变化在于,它开始“会思考”。在思考或专业模式下,它可以联网获取最新信息,一次生成多种方案,并对结果进行自我检查,让图像在准确性、时效性和一致性上更可靠。很多原本需要人工反复调整的工作,现在可以直接交给它完成。
这一代图像模型,已经不只是一个“画图工具”,而更像一个能帮你完成创意设计的视觉助手。
1. 语义理解能力:从“关键词拼图”到“场景建模”
过去的图像模型,很像在拼积木,你输入“夜晚 + 雨 + 女生 + 城市”,它就把这些元素尽量拼在一起。
让我想到24年刚接触Stable Diffusion的时候,生成图像都是把我们想画的元素以标签的形式写在正向提示词中,比如”1girl,very delicate features,very detailed eyes and mouth,big eyes,long hair,curly hair,delicate skin“,不想让哪些元素出现就把它们写在反向提示词中,比如"(low quality:2),skin spots,(fat:1.2),acnes,missing fingers,extra fingers,bad feet,mutation,deformed":
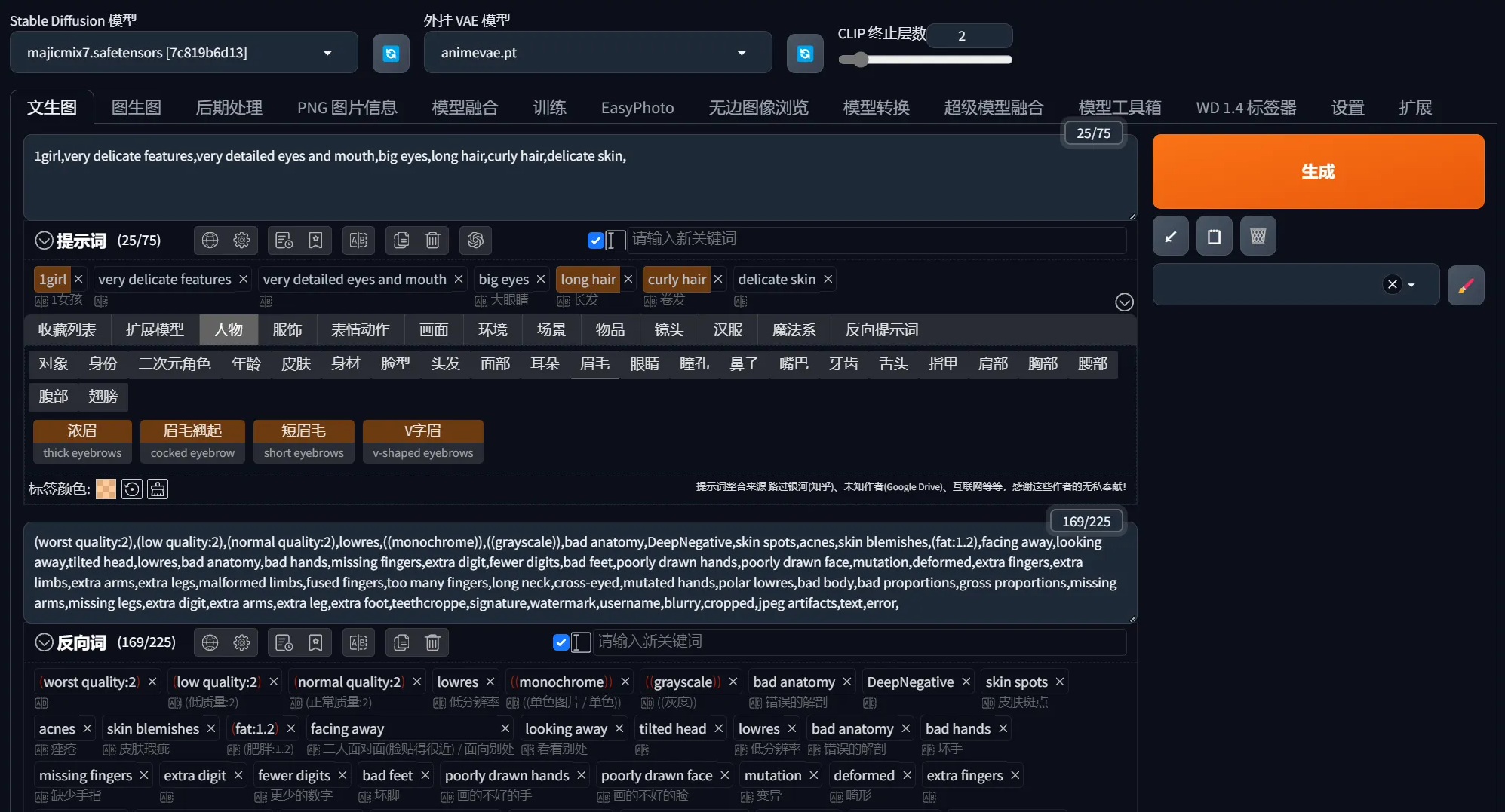
它更像是靠关键词标签约束生成效果,而 Images 2.0 更像是可以“理解一句话,并推导出一个完整场景”。如果再通俗点说,前者是在“把你写的词尽量都画出来”,后者是在“理解你想表达的那个画面”。
做个测试,我用一段一模一样的提示词,让国内某AI大模型和ChatGPT分别生成一张菜单。
提示词:
为一家北京菜馆生成一张菜单
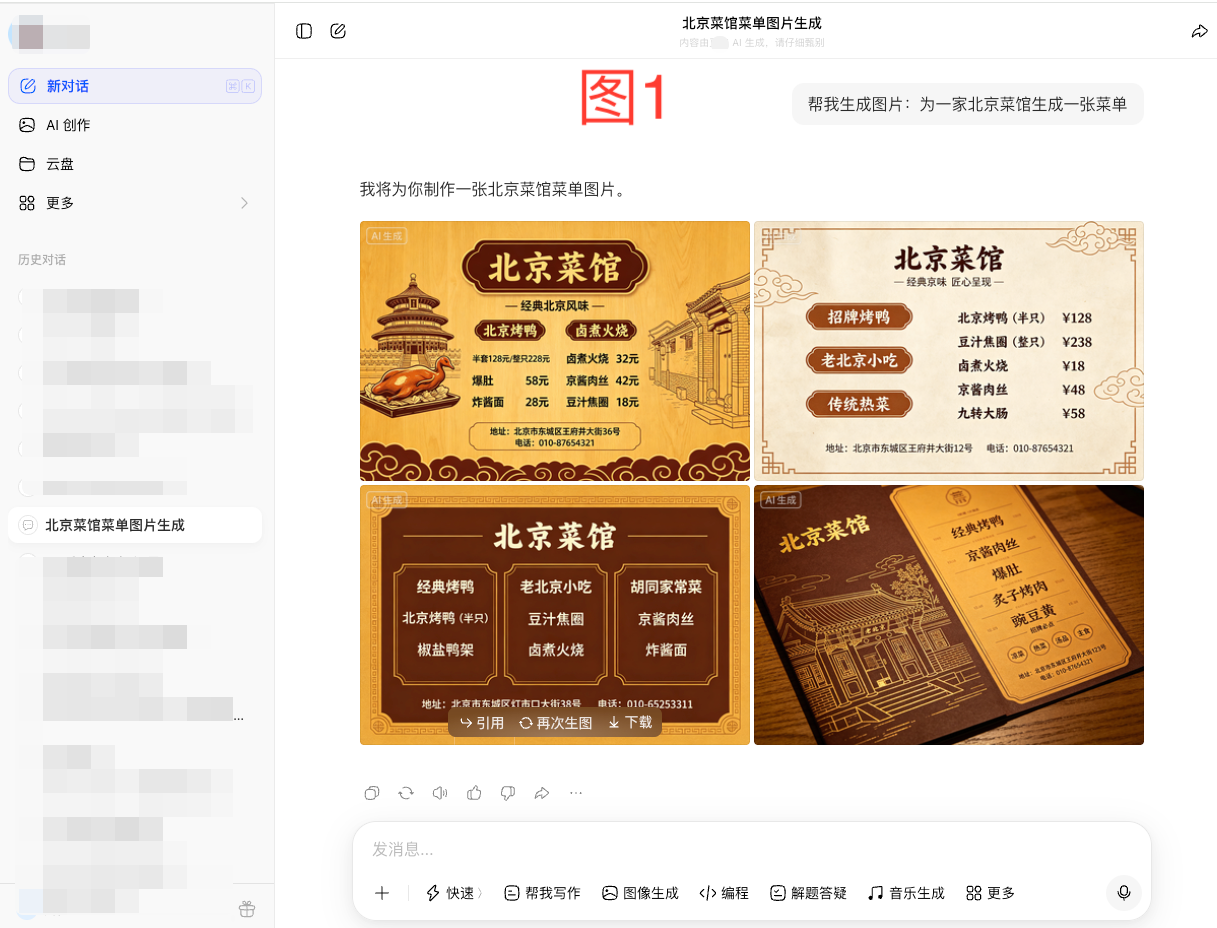
国内某AI大模型生成结果(默认会生成4张):
ChatGPT生成结果:
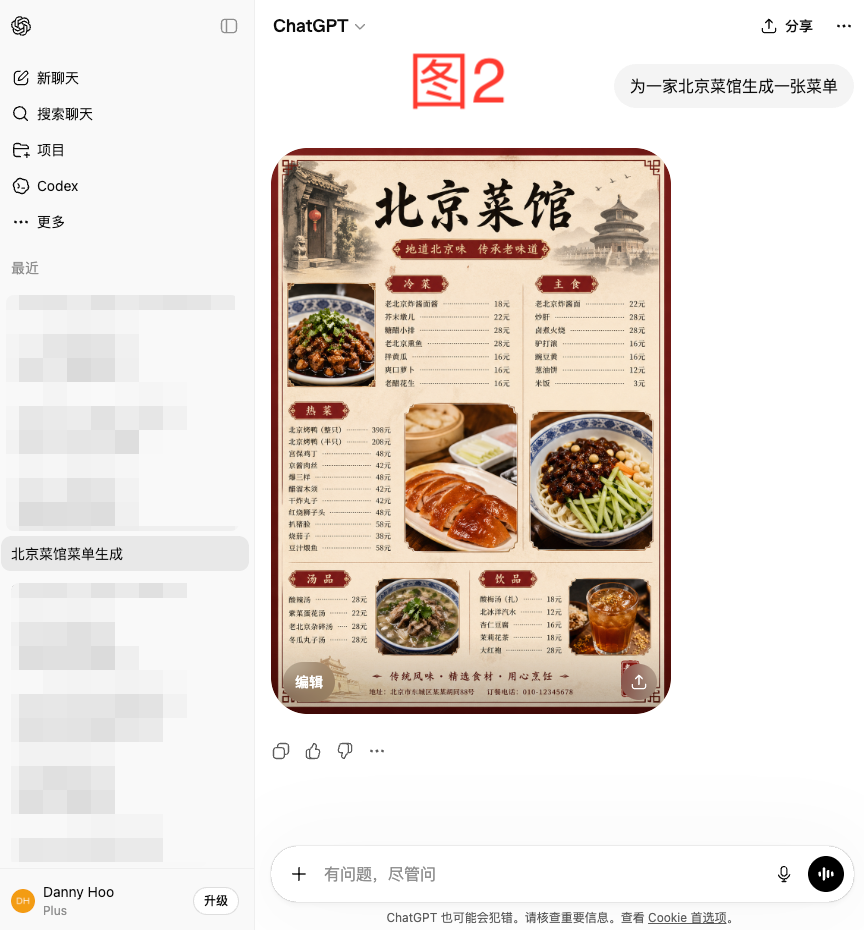
为了保证真实性,上面是对整个提问界面进行截图,ChatGPT的界面中图形不是很清晰,这里再贴一下生成的原图,来分析一下两者的差异:

图1虽然生成了四张风格各异的图片,像是在展示"菜单可以长什么样"的方案集,而非真正可用的菜单。它理解的是"菜单"这个词的视觉特征分布,于是输出了多种符合该特征的样式变体,但有的菜品条目寥寥无几,有的价格残缺不全。要说生成得完全错误倒也不至于,但完全没法直接商用。如果我作为一个饭店老板,肯定不会用,如果我作为一名顾客,看到这种菜单也没有点菜的欲望。
图2则输出了一张完整、甚至可以直接印刷使用的菜单。它理解的不只是"菜单长什么样",而是"一张菜单应该完成哪些功能":招揽顾客、分类呈现菜品、标注价格、提供联系方式。更绝的是,它构建了一套完整的信息层级:冷菜、热菜、主食、汤品、饮品五个分类清晰分区,每个分类下有4到11道菜不等,价格齐全,价格区间也符合北京餐馆的真实水平(3元米饭、398元整只烤鸭),底部有地址和订餐电话。这说明ChatGPT在生成图像之前,实际上在"脑中"先规划了一份真实可信的菜单内容,再将其视觉化,真正做到了先理解需求、再生成内容。
2. 文字渲染能力:彻底告别“鬼画符”
以往的模型(包括目前国内很多生图模型)在生成图像时,文字渲染都是一个很大的坎。比如你让它设计一张海报、生成一张产品包装图、制作一个带有标语的广告横幅,或者简单地在图片上添加一段说明文字,经常会出现乱码、文字重叠、字母变形、笔画断裂、同一个词被"拼凑"成莫名其妙的字符组合等问题,严重影响图片的实用性和美观度。
ChatGPT Images 2.0 在文字渲染能力上做出了巨大改进,确保模型对所有语言的文本都能够准确、清晰地呈现,彻底杜绝"鬼画符"现象。我记得在 ChatGPT Images 2.0 的线上直播发布会上,一位技术小哥还专门强调了此次改进对汉语、印地语、日语、韩语等亚洲语言有显著提升(相比于英语仅由 26 个字母排列组合而成,这些语言通常拥有成千上万个独立符号,对模型的字形学习和渲染精度的考验也远比拉丁语系语言严峻得多)。
这里我还是以同样的提示词,来对国内某AI大模型和ChatGPT Images 2.0的生成结果做一下对比。
提示词:
小学五年级数学期末试卷
国内某AI大模型生成结果(限于篇幅,我从生成的4张结果中随机选了1张):

ChatGPT生成结果:

两张图均要求生成"小学五年级数学期末试卷",但呈现效果天差地别。
图1中的文字渲染几乎完全失控:
-
大面积乱码:正文题目中充斥着无意义的字符组合,根本无法阅读;
-
文字重叠与错位:多处出现字符叠压、行与行之间内容混杂,视觉上一片混乱;
-
数字与汉字混搭错乱:题目编号与题目内容随机拼接,逻辑结构完全丢失;
-
内容重复冗余:同一道题的内容在不同位置反复出现(如"一个长方体水箱,长5分米,宽4分米"多次重复),说明模型在"填充"文字时毫无语义理解;
-
整体可用性为零:整个试卷都在考“体积与容积”,仿佛五年级只学了这点东西,几乎没有一道正常的题,如果非要夸的话,它的标题"小学五年级数学期末试卷"几个字是正确的。
图2中文字渲染接近真实印刷品:
- 所有汉字清晰准确:填空题、选择题、计算题、操作题各板块的题目文字完整、可读,无乱码;
- 数学符号与分数格式正确:如"3/8 + 1/8="、"5÷( )=0.625"等,分数线、运算符号均正确渲染;
- 排版结构合理:包含学校/班级/姓名填写栏、得分表格、题号分区,完整还原了真实试卷的版式逻辑;
- 细节到位:括号、空格、句号等标点符号位置准确。
3. 局部修改能力:不再"重新画一张"
过去用AI生图,有一个让人抓狂的体验:
你终于生成了一张99%满意的图,但有一处细节不满意,比如背景色调、人物穿搭、产品 Logo 位置。然后你只能重新调整提示词,再生成一张,等细节修改好了,新的问题又出现了。只能反复微调重绘,陷入「这张不行、再画一张」的死循环。
这个问题的本质是:你没有办法只动一个地方,每次修改都是"重新开始"。
ChatGPT Images 2.0 对此做出了根本性的改变。它支持上传一张已有图片,然后用自然语言告诉它"只改这里",其余部分保持不动。
这里依旧以实操来验证:
第一步,先生成一张基础图,提示词为:
超写实摄影风格,一位穿白色T恤的年轻男性站在咖啡馆门口,阳光照射,背景是玻璃橱窗和绿植,35mm镜头,自然光
生成效果:

第二步,上传这张图,再输入局部修改指令:
提示词:
保持人物、背景、光线完全不变,只把他的白色T恤改成深蓝色格子衬衫
生成效果:

人物的面部、背景的绿植、光线的方向和强度全部没有变,唯独衣服发生了改变。而且衬衫的光影、皱褶逻辑,也和原图的光源方向保持一致。
这种能力意味着什么?假设你拍了一张产品的照片,做电商主图,背景和构图都很满意,但老板说"把产品颜色换一个版本",以前你得重新拍,现在你可以直接改。
比如这个例子中我们再进一步测试文字层面的局部修改:
提示词:
保持图片其他部分完全不变,只把咖啡馆门口的招牌文字改为"每天见"
生成效果:

4. 角色与风格一致性:让同一个对象出现在不同场景里
你想给自己设计一个IP形象,或者给一个产品创建一套统一的宣传图,要求是:不同图片里,同一个角色/产品,必须看起来是"同一个"。
在旧模型里,这几乎不可能靠提示词单独实现。每次生成的角色,发型、五官、体型都会出现细微甚至明显偏差,生成10张图就像10个不同的人。
ChatGPT Images 2.0 在这方面有了显著的改进。你可以上传一张参考图,然后指定"保持这个角色/产品的外观不变,把他/它放在不同场景里"。
实操:
第一步,生成一个角色参考图:
提示词:
插画风格,一只圆滚滚的橙色柴犬,戴着一顶蓝色棒球帽,表情憨厚,白色背景,正面视角,角色设计参考图风格
生成效果:

第二步,上传参考图,生成场景1:
提示词:
保持这只柴犬的外形、颜色和帽子完全不变,把它放在一个下雪的冬日街道场景里,它正在看橱窗里的蛋糕,插画风格
生成效果:

第三步,上传参考图,生成场景2:
提示词:
保持这只柴犬的外形、颜色和帽子完全不变,把它放在一个夏天的海滩边,它正在喝椰子汁,插画风格,阳光明媚
生成效果:

三张图里,这只柴犬的耳朵形状、口鼻比例、帽子的颜色与款式,保持了足够高的一致性,让你一眼认出"这是同一只狗"。
如果一致性到位,这个能力对于IP运营、表情包制作、绘本创作来、漫画分镜或图文故事等场景说,价值是巨大的,你可以用AI持续产出同一个"活的"角色,每一格都是"同一个主角",而不是每次都在生成一个陌生人。
5. 商业落地能力:从"好看"到"能用"
前几节说的都是"技术上能做什么",最后我想聊一个更现实的问题:ChatGPT Images 2.0,真的能用在工作中吗?
答案是,在不少实际应用场景中,已经完全够用。
我自己测试了三个典型的商业应用场景:
场景一:电商主图
提示词:
为这款椅子做一张高质量电商介绍图
我现场给我的椅子拍的照片:

生成效果:
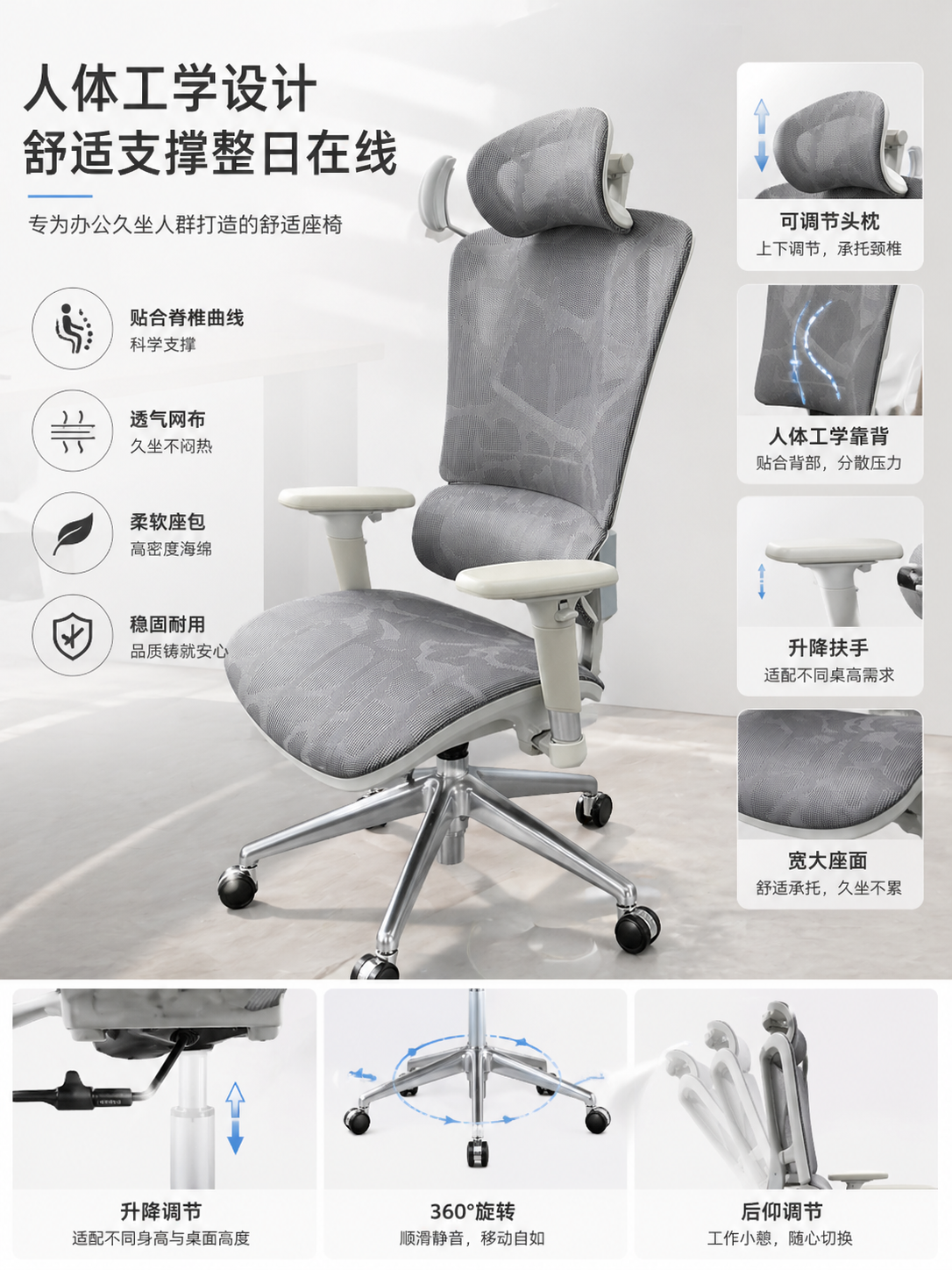
我个人觉得这张图几乎已经完全可以直接作为电商主图使用。
对椅子本身的还原相当准确:网布材质的透气孔、扶手形态、五星底座的金属质感,都和原物高度一致,而非生成一把"差不多的椅子"。文字渲染同样经受住了考验,中文标题、功能标注、说明小字均清晰无乱码,排版层级清楚。
最主要的是,它真正理解了"电商海报"的完整信息架构,不只是把椅子"画好看",而是主动补全了一套完整的产品详情页逻辑:大标题、卖点图标、功能细节分区、底部参数说明,一次生成全部到位。
场景二:活动宣传海报
提示词:
2026夏日音乐节宣传海报,竖版设计,国潮风格与现代音乐节融合,顶部大字标题“2026夏日音乐节”,采用书法或国潮设计字体,具有力量感与节奏感;下方小字“7月18日 | 北京·国家网球中心 | 票价从88元起”,中文排版清晰规整,层级分明。 整体风格:新国潮 + 音乐节视觉,融合传统文化与现代电音氛围,既有东方审美韵味,又有年轻、潮流、活力的表达。 画面元素: 中国传统元素(祥云、山水轮廓、国风纹样、印章、波纹纹理)与现代音乐元素结合(舞台灯光、音响、DJ台、音波、节奏线条);可加入飞鹤、锦鲤、龙纹或抽象东方神兽作为视觉焦点;背景可使用故宫红墙或抽象东方建筑剪影进行艺术化处理。 色彩方案: 主色调以中国红、鎏金、墨黑为核心,辅以霓虹渐变(红橙→紫)提升现代感;金色点缀增强高级感与节日氛围,对比鲜明但整体统一。 设计氛围: 热烈、节庆、潮流、东方美学与电音融合;画面具有流动感(云气、光线、音波流动),兼具传统厚重感与现代科技感。 设计细节: 金色烫金质感、纹理细节丰富,局部光效(灯光、光晕、粒子),空间层次分明;整体构图均衡,视觉中心突出。 排版要求: 标题醒目突出,小字信息清晰易读,适当留白,避免信息拥挤;整体视觉统一,有品牌海报质感。 风格参考: 国潮插画风 + 现代平面设计 + 轻微3D质感,类似东方潮流视觉、音乐节主视觉KV设计。 画质: 超清、4K分辨率、商业级海报设计、细节精致
生成效果:

这张图同时考验了多种能力:视觉风格的把控、插画元素的生成,以及中文标题+日期+地点等多行文字的清晰渲染,这也是此前大多数模型的集中失分区。
场景三:PPT配图/信息图
提示词:
设计一张简洁的信息图,主题是"咖啡的五种萃取方式",风格参考现代极简商业插画,白色背景,包含五个方块图标区域,分别标注:手冲、意式浓缩、冷萃、摩卡壶、法压壶,每个图标下方有对应的英文小字,整体配色为深棕色+米白色+浅橙色,适合PPT直接使用
生成效果:

它能在一次生成里同时处理"多个平行模块的排版逻辑",并且让每个模块的视觉权重保持一致,这本质上是在考验它理解"信息架构"的能力,而不只是"画一个好看的图"。
三个场景测试下来,大概可以得出一个结论:
ChatGPT Images 2.0 的商业落地能力,已经不是"勉强能用"的水平,而是在某些场景下,可以直接替代一部分基础设计工作。当然,它目前有可能还做不到100%完全精准地控制字体、间距、品牌色值等,这些仍然需要设计师在生成结果基础上进行二次调整。
但它解决的问题很明确:把"从零到草稿"这一段,从几小时压缩到了几分钟。
担忧:当"以假乱真"成为人人可用的工具
一方面,ChatGPT Images 2.0确实可以极大提高我们的生产力,但是在感叹它生图能力强大的同时,也给这个社会带来了一种深层的担忧,那就是造假门槛已低到普通人随手就能操作的地步。
前几天看到一段话,说得很直接:
这也许才是那个"强到不应该公开发布"的模型。今天之后,每个人都有了随意生成曾经都会被认作事实证据的图片,信息的判断变得前所未有的难。这个强到离谱的模型会在未来很长一段时间给人们带来恐慌,我们会看到因此而产生的各种冲突和讨论,人类必须一起严肃应对这种以假乱真的能力了。
这段话我觉得并不夸张。
它能"造"什么?
- 伪造社会实时/新闻现场:它可以生成看起来像"新闻照片"的图像,比如文章开头提到的那些案例:“库克在抖音直播间卖华为手机”、“雷军为特斯拉汽车做代言”、"马斯克入职小米汽车,这些图片的危险之处不在于内容有多荒谬,恰恰相反,是因为它们看起来足够真实。
- 伪造个人证据:这类场景有一个共同特征:受害者往往难以自证清白,因为"照片"在大多数人的认知里,依然等于"证据"。
- 一张伪造的转账截图,可以用于诈骗;
- 一张伪造的聊天记录配图,可以用于造谣或敲诈;
- 一张伪造的"某人在某地出现"的照片,可以用于不在场证明的反驳,或制造出轨、违规的假证据;
- 一张伪造的资质证书、荣誉奖状,可以用于简历造假或机构背书。
- 等等……我不敢再列,也不敢再想。
有人会说,假图一直都有,但过去的假图漏洞明显,普通人一眼就能分辨;现在的假图,破绽正在消失。普通人几乎没有任何工具可以在几秒钟内判断一张图是否为AI生成。而信息传播速度,远远快于事实核验的速度。
我们能做什么?
坦白说,目前没有完美的解决方案,但有几个方向值得关注:
-
技术层面,OpenAI 等机构已经在为AI生成图像添加不可见的数字水印(如 C2PA 标准),让图像携带"出身证明"。但依赖平台和设备的广泛支持,短期内难以覆盖所有传播链路。
-
平台层面,主流社交平台开始要求用户标注AI生成内容,部分平台已经引入自动检测机制。但对抗式的生成与检测,但本质上是一场军备竞赛,检测永远滞后于生成。
-
个人层面,也是最重要的一点:在图像面前,重建怀疑的本能。 看到震惊性的图片,先问一句"这是真的吗",再去找原始信源核实,而不是直接相信并转发。这个习惯,在接下来的几年里,会变得越来越重要。
Images 2.0 本身没有原罪,技术的进步从来是双刃剑。但我们需要清醒地看到:这把刃,比以往任何时候都更锋利,也更容易被普通人拿起来。
如何在享受技术红利的同时,建立与之匹配的信息素养和社会规范,是接下来每个人、每个平台都必须认真面对的问题。
注:本文所有内容均为作者个人观点,仅供技术探讨与学习交流,不代表任何机构立场。文中所涉及的"造假"风险分析,目的在于提示公众提高信息辨别意识,不构成任何操作引导。请勿将本文内容用于任何违法违规用途,由此产生的法律责任由使用者自行承担。转载请注明出处《ChatGPT Images 2.0五大硬核能力深度实测,以假乱真毫无破绽》 https://blog.csdn.net/huyuyang6688/article/details/160903254

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)