科研角色升维思考:协同多智能体,从执行者进阶指挥官|《AI4S实战派》第五期复习
作为业内首个多学科、系统化的AI4S工程实战宝典,“AI4S实战派”栏目立足开放生态、持续演进,致力于“手把手”带你率先跑通科学大模型,将复杂、多学科的AI模型转化为能跑、能用、能创新的生产力工具,帮助科研人员和开发者零门槛上手,加速科学新发现。
在AI正加速药物发现、天气预报、材料筛选的当下,一个更深层的问题在发酵着:AI只是在基于已有知识体系填补空缺,还是能进一步帮助人类触达未知规律和发现?
上周四晚,在《AI4S实战派》第五期直播中,香港中文大学助理教授、波动智能实验室负责人刘圣超以应用于科学智能(AI4S)的多模态与多智能体(Multi-agent)为主线,用贯通过去十年AI发展脉络的全景视角,带我们重新审视了这条赛道的来路、现状与卡点。
今天,我们来一起温故知新(可前往“上海科学智能研究院”视频号观看课程回放)或者点击下方链接:https://aistudio.ai4s.com.cn/partner/research-plaza/research-plaza-web/sais-community/course/2049756391557611520
密度估计:生成式AI十年进化主线
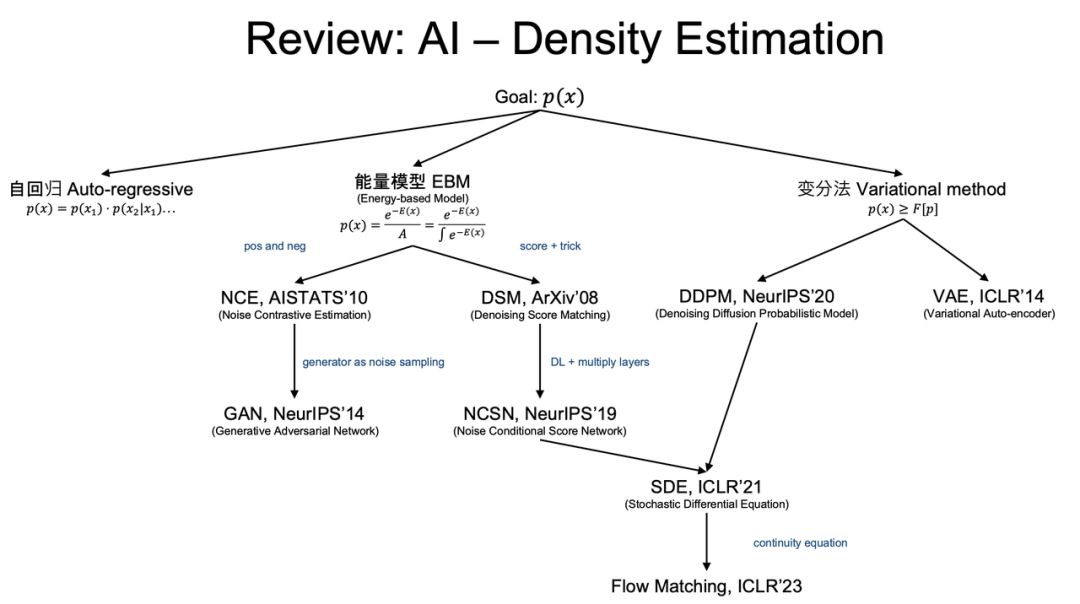
在进入“多模态”、“多智能体”这些热词之前,刘圣超把整个生成式AI的发展脉络,用一根主线串了起来。这根主线,叫做密度估计(Density Estimation),通俗来说就是:AI如何估计数据的分布。
从最早的自回归(Autoregressive)和能量模型(Energy-Based Model),到GAN(Generative Adversarial Network)的对抗学习、VAE(Variational Autoencoder)的变分推断,再到DDPM(Denoising Diffusion Probabilistic Models)的扩散模型,最后到今天的Flow Matching(流匹配)框架——这些看似迥异的技术路线,其共通点是都在死磕同一个问题:如何更精准地从海量数据中,学到其背后的真实物理或化学分布?
刘圣超特别提到,2021年宋飏(时任OpenAI战略探索团队负责人)团队发现,NCSN(Noise Conditional Score Network,噪声条件分数网络)和DDPM这两个看似独立的方向,其实是同一个随机微分方程(SDE)框架的两种特例。从此,生成模型进入了一个新阶段:用微分方程的语言来统一描述数据的生成过程。
这既是一段技术编年史,也是理解现今所有科学智能主流工具(如AlphaFold 3等)的底层密码。
研究者的视角,决定AI的力量边界
懂了底层语言,入门者可以如何理解科学智能?刘圣超指出:你站在哪里,你看到的世界就不一样。
1、从科学家的视角看:AI是现有范式的加速器。 无论是药物发现(如AlphaFold 3),还是气象预测(如“伏羲”、“盘古”等), AI在整体上扮演的是“超级计算器”,加速了传统研发管线中的某个特定环节。
2、从AI研究者的视角看:科学智能是三个叠加的技术难题——学什么(数据分布/密度估计)、怎么学(训练动力学,Training Dynamics)、学到了什么(隐空间语义解释,Latent Space Interpretation)。
3、从范式革命的视角看:曾经AI只能加速“假设检验”这一环节,如今的生成式AI带来了更大的可能性——同时承担“假设生成”和“假设检验”,从而重新定义科学发现的循环。
第三个视角,正是刘圣超如今所有工作的出发点。
隐空间中“跨界翻译”的科学多模态
要让大模型做科研,首先要解决它对物质世界的感知问题。科学领域的核心数据通常有三种形态:序列(1D,SMILES分子式、氨基酸序列等)、结构(3D,蛋白质的 Alpha Helix和晶体材料的周期性晶格等)和文本(Text,化学性质描述、蛋白质的功能注释等)。
当不同模态的数据被统一到一个框架下,科学研究的方式就开始变了。
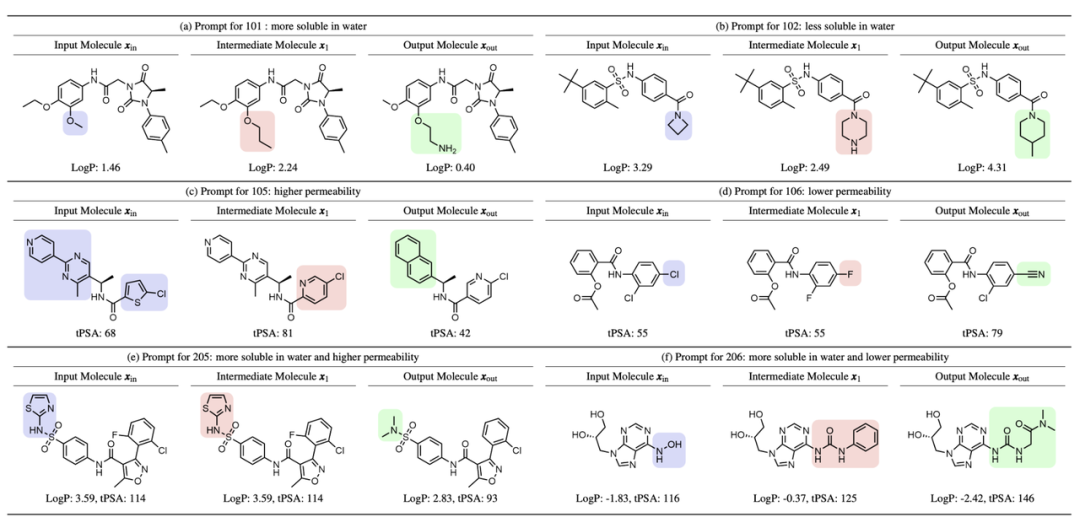
如何让只会处理文本的大模型听懂“化学的语言”?刘圣超团队提出了一种相当优雅的思路——隐空间对齐(Latent Space Alignment)。
将复杂的化学空间映射到隐空间,再与大语言模型擅长的“文本空间”对齐,那么文本空间就具有极强的“组合性”。
比如,当你需要一个新药分子时,不需要去调复杂的物理参数,只需输入一句指令:“让这个分子更溶于水,并且降低它的穿透性。” AI就能像修图一样,自动在分子的特定区域(如卤素或羟基)进行“文本引导的分子编辑”。通过隐空间的对齐,复杂的科学问题,被成功降维成了简单的文本生成问题。
一旦化学空间的问题被转化到文本空间,很多原本非常困难的分子优化任务,就变得像填写一行Prompt一样简单。
多智能体“狂飙”,科研全面加速
如果说多模态是在拓展AI理解科学数据的能力,那么多智能体要解决的是:谁来指挥AI完成一整条科研流程。近年来,多智能体系统在各科学领域被广为应用:
1、Coscientist(CMU)是最早引入智能体概念的工作之一。它设计了一套“大脑”:能调用Google Search、运行Python脚本、读写实验文档、甚至调度自动化实验室仪器。给定一个合成目标,系统能自主完成从方案规划、条件搜索、到真实化学实验的全流程。
2、ChatPathway(刘圣超团队的工作):零样本(Zero-shot)预测生物体内的代谢和调控通路。AI在预测出的多条路径中,有两条与同期发表的真实湿实验成果完全吻合。
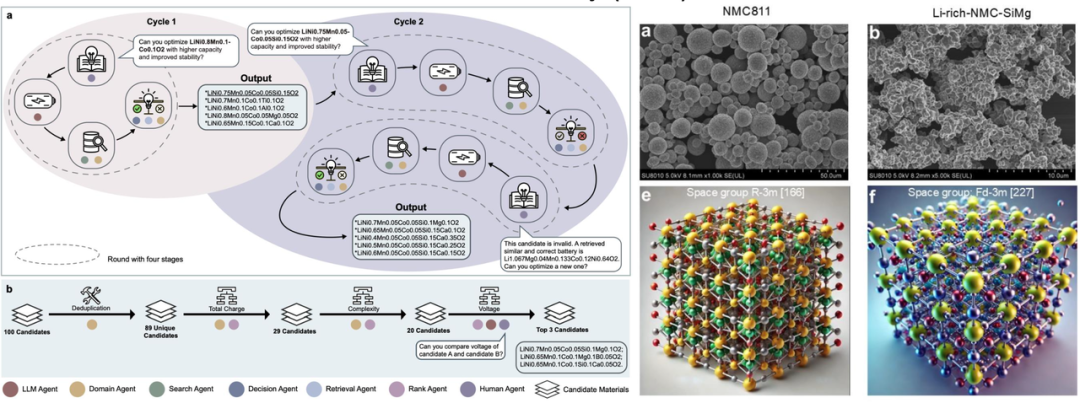
3、ChatBattery(实战演示):刘圣超团队展示了电池正极材料的优化。多个智能体各司其职,经过几轮内部对话与寻优,成功从传统的三元锂电池(NMC811)推演并优化出了新型的五元锂电池,并在实验室中完成了真实的合成与验证。完整 demo地址:https://github.com/chao1224/ChatBattery
冷静思考:大热背后的技术卡点
与此同时,刘圣超也泼了一盆冷水:当前大热的多智能体系统,其工程(Engineering)含量远大于科学(Science)含量。它们能帮助完成科研流程中便于自动化的劳动,但离“科学大发现”尚有距离。
大模型目前的卡点究竟在哪里?刘圣超用一个比喻给出了答案:大语言模型可以被视作为一个极度高效的搜索与插值算法。它非常擅长在人类现有的知识边界内“填写元素周期表上的空格”(Interpolation)。但科学发现的关键价值,在于“凸出元素周期表的边界”(Extrapolation/Discovery)。如何让AI具备探索未知边界的能力,是目前科学智能发展的核心挑战。
当大模型可以生成具有各种属性的分子,那么又要如何验证其可合成性和稳定性?缺乏快速、低成本、高精度的验证机制,是限制AI形成自主闭环的最大瓶颈。
🎉🎉🎉
感谢收看《AI4S实战派》前五期的6万小伙伴!
欢迎锁定接下来的物质科学模块课程!
在过去一个月里,在《AI4S实战派》的“Hello Universe”通识模块,来自浙江大学、复旦大学、上智院、耶鲁大学、香港中文大学的5位青年科学家,先后带领入门科学智能的社区成员初步掌握了用于科研的AI方法:
我们在方榯楷主讲的表征学习课程中,看到了AI用16维向量构建的流体宇宙;在章敏主讲的扩散模型课程中,见证了AI如何逆转熵增,在原子坐标系中精准捏出生命蛋白质的骨架;在陆路主讲的PINNs(物理信息神经网络)课程中,学会了把偏微分方程刻进神经网络的灵魂;在姜若曦主讲的层级表征和自回归模型课程中,领会了如何用“未来的影子”作锚点,在变幻莫测的湍流中精准“接龙”物理世界的下一秒;再到刘圣超主讲的多模态与多智能体课程中,看到了AI化身虚拟科学家,人机协同开启深度科研的可能。
感谢超过6万人次来自物理、化学、材料、计算机等专业的伙伴们的在线观看与真诚交流,是你们的热情与求知欲,让这个交叉融合的硬核实战营焕发出了强大生命力!
接下来,让我们开始对准领域科学的阵地。在聚焦物质科学的《AI4S实战派》第二大模块中,一线产研先锋将继续手把手带你实战:
用图神经网络精准预测分子的性质与材料的带隙;借助机器学习势函数运行千万倍加速的分子动力学模拟;通过生成式材料设计“点石成金”逆向生成新材料;系统运用前沿Skills,跑通药物研发、材料设计的流程……
单刀直入、高效上手、扎实基础,更多深度实战教学,敬请期待!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 13
13 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)