2026年数维杯春季赛赛题浅析-助攻快速选题
本文将为大家带来2026年数维杯的赛题浅析,旨在通过5~10分钟帮助大家完成初步的选题工作。数维杯是上半年最火的数模竞赛之一,自称有“小国赛”的美誉。本文将会为大家具体介绍本次竞赛的ABC三个题目具体所涉及的模型、解题算法、可创新点以及未来解题中可能遇到的难点。
须知A题、B题为本科生、研究生组选做,ABC为高职高专组选做,其中本科生和研究生组的评分是分组评分,因此不必担心跨组导致竞赛的不公平性。
以下为官方原文
本竞赛的题目均以中文形式给出,竞赛分为研究生组、本科生组、专科生组。竞赛题目共3道 (A 题 、B 题 、C 题)。研究生组、本科组:从A、B题中任选一题;专科组:从A、B、C题中任选一题。竞赛题目一般是来源于各行业并经过适当简化的实际问题。

初步预估赛题难度A:B:C=4:5:3
初步预估选题人数A:B:C=2:1:0.5
A 题:抱轨式磁浮列车悬浮电磁铁故障检测
问题一:电磁力二元数学模型
问题简述
题目已给出理论上电磁力与电流、悬浮间隙的比例关系,但比例系数未知。问题一的核心任务就是利用附件1的实验数据,把这个比例系数定量确定出来,建立一个可以精确计算电磁力的数学模型。
求解思路
首先,理论关系告诉我们电磁力正比于电流的平方、反比于间隙的平方。这种幂函数形式可以通过对两边取对数,转化成一个标准的线性回归问题。转化之后,用最小二乘法对实验数据进行拟合,就能同时估计出比例系数和两个指数的实际值。

可用模型:对数线性化后的多元线性回归、非线性最小二乘(NLS)直接拟合
创新点:将两个指数都作为自由参数估计,而不是固定为理论值,通过统计检验判断理论假设是否成立。如果拟合得到的指数明显偏离2,说明实际电磁铁存在漏磁、边缘效应等非理想因素,可进一步引入修正项加以描述。
问题二:垂向运动微分方程及位移计算
问题简述
这道题要求对车体和悬浮架分别建立力学方程,形成一个耦合的动力学系统,然后以列车静止为起点,把附件2的电磁力数据作为外力驱动,数值求解整个运动过程。
求解思路
首先做受力分析。车体只受两个力:自身重力(向下)和空气弹簧传来的弹性力与阻尼力(向上)。悬浮架则受到自重加上16个电磁铁的重力(向下),以及16个电磁铁产生的电磁力(向上),还有弹簧对它的反作用力。两个方程通过弹簧力耦合在一起,构成一个二自由度系统。
初始条件的设定很关键。题目说列车静止时悬浮架停在轨道上,所以悬浮架初始位移和速度都为零。车体初始位移由弹簧静力平衡确定,即弹簧力恰好等于车体重力时的压缩量。
数值求解时,将两个二阶方程分别降阶为四个一阶方程,组成状态方程组,用经典的四阶Runge-Kutta方法逐步积分。附件2给出的是离散的电磁力时序数据,需要先对其做线性插值,才能在连续时间积分中使用。
悬浮间隙的计算方式为:初始最大间隙0.06米减去悬浮架的向上位移,因为悬浮架上升意味着它与轨道之间的距离减小。
定义向上为正方向。各部分质量:

问题三:全车统一η的定量计算与故障判断
问题简述
这道题假设16台电磁铁的功率放大系数 完全相同且不随时间变化,利用附件3的监测数据反推这个系数的具体数值,再与正常范围 比较,判断是否存在故障。
求解思路
整体思路是"正向计算理想值,逆向反推实际值,两者相比得到η"。
第一步,利用问题一建立的电磁力模型,把附件3中每个时刻的实测电流和悬浮间隙代入,计算出理想情况下全车16台电磁铁应该产生的合力,这是"应该有的力"。
第二步,利用车体加速度数据和运动方程,从力学角度反推出悬浮架实际受到的电磁合力,这是"实际有的力"。具体来说,由车体运动方程可以算出弹簧力,再代入悬浮架方程,结合悬浮架的加速度(由间隙数据二阶数值微分得到),就能反推出实际电磁合力。
第三步,用最小二乘法对所有时刻的数据进行拟合,得到η的估计值。最后判断η是否落在
的正常范围内,给出明确的故障判定结论。

问题四:16台电磁铁各自时变η的故障识别
问题简述
这道题难度大幅提升:16台电磁铁的η各不相同,且都随时间变化。首先需要从理论上分析这个问题是否"可解",再设计合理的方法识别哪台电磁铁在什么时间段出现了故障。
求解思路
第一步:论证欠定性。 每个时刻,系统只能提供一个力的平衡约束方程,但未知量有16个η,方程数远少于未知数,单时刻完全无法求解。这个欠定性必须在论文中明确指出,这是本题的核心难点。
第二步:加入合理假设降低欠定程度。 最直接的方法是滑动时间窗口假设——在一段足够短的时间窗口内,假设各台电磁铁的η保持不变。这样在窗口内就有多个时刻的方程,当方程数大于16时,可以用最小二乘法求解。窗口长度的选取需要在"时间分辨率"和"方程充足性"之间权衡。
如果进一步假设同一时刻只有少数几台电磁铁出现故障(稀疏性假设),可以引入L1正则化,让模型自动将正常电磁铁的偏差量压缩到零,只"保留"真正偏离的那几台,从而实现精准定位。
第三步:故障时间段检测。 对每台电磁铁得到的η时间序列,用CUSUM控制图检测均值的突变点。CUSUM的核心思想是:如果η持续偏向某一方向(持续偏大或偏小),累积偏差超过报警阈值时,就判定该时段发生了故障。报警后,记录故障开始和结束的时刻,给出具体的故障时间段和对应电磁铁编号。
B 题:智能办公场景下多源异构文件识别与治理优化
问题一:多源文件特征挖掘与分类
问题简述
数据集1中的文件来源多样、格式各异,没有预设的类别标签。任务是从这些文件中自动发现内在的主题结构,完成无监督聚类,并对每个类别总结出一个清晰的主题名称。
求解思路
第一步是特征提取,这是整道题的基础。对不同格式文件提取文本后,从三个层面构建特征:一是关键词统计特征,用TF-IDF衡量每个词对文件的代表性;二是语义特征,用预训练的中文BERT模型将文件编码为稠密向量,捕捉深层语义信息;三是结构特征,例如文件长度、文体类型、是否含有表格等,以离散编码方式加入。将三类特征拼接,形成每个文件的综合表示向量。
第二步是降维。高维向量直接聚类效果较差,用UMAP对向量降至低维,同时保留局部邻域结构,便于聚类和可视化。
第三步是聚类。用K-means对降维后的向量聚类,类别数K通过轮廓系数和肘部法则共同确定。聚类完成后,对每个簇提取最高频的关键词,结合人工判断为每类文件归纳出一个主题名称。
创新点:用BERTopic方法一体化实现主题发现,它将BERT嵌入、HDBSCAN密度聚类和改进的TF-IDF关键词提取融合在一起,不需要预先指定K,且对短文本和片段性内容的处理效果明显优于传统LDA。
问题二:新数据归类与模糊归属处理
问题简述
数据集2是半结构化的记录数据,数据集3是匿名原始文件,两者都需要归入问题一建立的类别体系。同时,对于同时具有多个类别特征、或归属不明确的文件,需要提出专门的处理方式。
求解思路
将问题一的聚类结果作为训练标签,训练一个文本分类器。分类器不只输出一个类别,而是输出属于每个类别的概率值,形成一个概率向量。
归属清晰的文件取概率最高的类别;对于模糊归属的文件,通过两个指标判断:一是最高概率是否低于某个阈值(例如0.5),二是概率分布的信息熵是否过高(熵越高说明模型越"不确定")。满足任一条件的文件,输出候选类别集合,标记为"待人工复核"。
评价指标的设计需要体现三个维度:分类置信度(最高概率值)、可解释性(模型判断依据中有多少命中该类别的关键词)、迁移适用性(新数据的特征分布与训练数据是否差异过大)。
创新点:引入零样本分类作为辅助,将每个类别的主题描述直接输入大语言模型,让模型判断文件归属,不依赖任何标注数据。将零样本结果与监督分类结果加权融合,对于训练数据覆盖不足的边缘文件效果更好。
问题三:人工复核必要性判断与优先排序
问题简述
并非所有文件都需要人工复核,需要从紧急程度、错分风险、复核必要性三个维度给文件打分、分级,再结合资源约束确定哪些文件优先复核。
求解思路
首先构建三个维度的量化指标。紧急程度通过文件中出现的时效性关键词(如"今日""截止""紧急")以及明确的时间字段来判断。错分风险直接用分类模型输出的最高概率的补数来衡量,置信度越低说明错分的可能性越高。复核必要性则对涉及资金分配、重要政策的文件赋予更高权重。
三个维度通过加权求和得到综合得分,权重用层次分析法(AHP)确定,再设置两个阈值将文件划分为高、中、低三个复核等级。
资源约束下的排序是一个优化问题:在有限的人力、时间或成本预算下,选择哪些文件进行复核,使得总收益(综合得分之和)最大化。这本质上是一个0-1背包问题,可用动态规划求解。数据集4提供三种约束场景,分别求解后比较结果差异,分析约束收紧对漏检高风险文件数量的影响。
创新点:引入主动学习机制,每次人工复核的结果反馈给分类模型进行增量训练,使错分风险评分随着时间推移逐渐降低,整个系统边使用边进化,而不是静态的一次性决策。
C 题:我国碳排放数据分析与研究
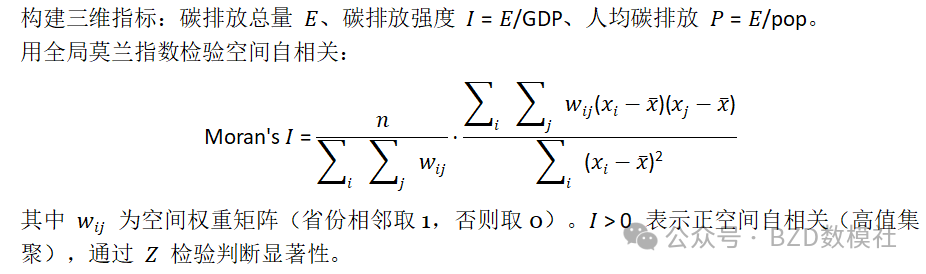
问题一:各省碳排放空间差异与分类分级
问题简述
检验各省碳排放核心指标是否存在显著空间差异,构建多维指标体系对省份分类分级。
空间差异检验
问题二:碳排放影响因素识别与预测模型
问题简述
结合能源结构数据,识别影响碳排放的基本因素,建立预测模型。
因素分解(LMDI)
对碳排放
做对数均值迪氏分解:

问题三:三情景碳达峰预测(2026—2045)
问题简述
设定三种发展情景,预测碳排放趋势,判断达峰时间与峰值。
情景设定
|
情景 |
GDP增速 |
能源强度年降幅 |
非化石能源占比2030 |
|
基准 |
5% |
2%/年 |
25% |
|
低碳 |
4.5% |
3.5%/年 |
35% |
|
强化低碳 |
4% |
5%/年 |
45% |
预测方法
将三种情景下的参数代入问题二最优模型,逐年滚动预测:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)