一张拍歪了的化验单,会让你的 AI 诊疗产品“失明”多久?
先问一个问题:一张被手机拍弯的化验单,你的系统是否能把数据完整地读出来?
这是做医疗 AI 的团队经常面对的现实情况:不是技术不行,是输入太“任性”。
患者上传的检验报告,可能是褶皱的、倾斜的、光线不均的,甚至是对着屏幕翻拍的,上面有明显的反光和摩尔纹。版式也五花八门——不同医院、不同设备、不同年代的报告,格式千差万别。
而你的下游任务,无论是医疗知识图谱建设,还是 AI 辅助诊疗,都需要从这些“不标准”的报告中,精准地提取出检验项目、结果值、参考范围、单位、异常标识……
这一步如果卡住了,后续所有的智能分析、健康建议、风险预警,都失去了依据。
一、医疗报告解析,到底难在哪?
难点一:文件质量参差不齐,甚至“不像文档”。
患者上传的报告,很少是扫描仪扫出来的高清 PDF。更多的是手机随手拍的照片——角度歪了、光线暗了、纸张皱了、手指挡住了一角。还有的是从微信聊天记录里下载的,被压缩得模糊不清。
传统 OCR 工具是为“规整文档”设计的,遇到这种输入,识别率断崖式下跌。
难点二:版式多样,没有统一标准。
不同医院的检验报告单,排版风格完全不同。有的用表格,有的用列表;有的项目名称在左、结果在右,有的上下排列;有的带边框,有的无线框。甚至同一家医院,不同年代的报告格式也不一样。
通用解析工具看不懂这些“方言”,只能机械地输出文字,无法区分“项目名称”和“结果值”。
难点三:特殊符号和单位,容易出错。
检验报告里有大量特殊符号:↑↓ 表示偏高偏低,± 表示加减,还有各种希腊字母(β、γ)、特殊单位(μg/L、mmol/L)。传统 OCR 经常把这些符号识别成乱码或普通字母,导致后续的数据解析完全错位。
难点四:结果溯源难,无法复核。
医疗场景对准确性的要求极高。一个结果的错误,可能导致误诊或漏诊。但很多解析工具只输出最终数据,不保留原始位置信息。当数据有疑问时,无法快速定位到原图中的对应位置进行人工复核。
这些难点叠加在一起,就成了医疗 AI 产品从“demo”到“生产可用”之间的最大鸿沟。
二、这些“小问题”,正在拖累你的产品落地
我们具体看看,解析环节出问题,会带来哪些连锁反应。
问题一:用户上传一张歪斜的报告,系统识别不出来。
一位患者用手机拍了一张血常规报告,角度偏了 15 度,还有轻微的卷曲。系统解析后,白细胞计数被读成了“1.0.3”,参考范围完全错位。用户收到的健康建议是“白细胞异常偏低”,而实际上他的指标是正常的。
这不是罕见情况。大量 C 端产品因为解析准确率不过关,不得不要求用户“重新拍摄”“保证光线充足”“请用扫描仪”——用户体验差,流失率自然高。
问题二:版式变了,解析规则就要重写。
某医疗科技公司对接了 50 家医院的检验报告。每种版式都写了一套正则表达式和字段映射规则。今天来了第 51 家医院的新版式,工程师又要花两天时间调试。而且医院还会更新报告模板,旧规则随时失效。
维护成本越来越高,产品迭代越来越慢。
问题三:特殊符号识别错误,数据直接作废。
一份生化检验报告上的“β-羟丁酸”,被识别成“B-羟丁酸”;“↑”被漏掉,导致“偏高”变成“正常”。这些错误如果不人工核对,直接入库到知识图谱,污染的是整个数据底座。
问题四:数据出问题,找不到源头。
某个检验项目的异常值引起了医生的质疑。团队想追溯原始图片确认,但解析工具没有输出坐标信息,只能重新翻找原始上传文件,一页一页地看。效率低下,响应缓慢。
这些麻烦导致医疗 AI 团队的研发资源大量消耗在“修解析”上,而不是打磨临床算法和用户体验。
三、为什么市面上的通用方案,总是搞不定医疗报告?
不是没有工具,而是大多数工具不是为“患者手机拍的报告”设计的。
通用 OCR 工具擅长印刷清晰的 A4 文档,但遇到倾斜、弯曲、低光照、反光、手抖模糊,效果大打折扣。而且它们对医疗报告里的特殊符号(如 ↑↓、μ、β)没有专项优化,识别错误率高。
开源解析库在标准表格上表现尚可,但面对无线框、无边框、不规则排版的检验报告,输出的是一堆杂乱文本,无法区分字段语义。更麻烦的是,它们没有“结果溯源”能力,无法满足医疗场景的复核需求。
自研方案听起来可控,但要搞定倾斜矫正、弯曲矫正、低光照增强、无线框表格解析、特殊符号识别、坐标溯源……至少需要一个算法团队投入一年以上。对于大多数医疗科技企业来说,这个投入产出比并不划算。
问题的本质是:医疗报告解析是一个“看起来简单、做起来极碎”的脏活累活。它需要的不是某个单点算法突破,而是一整套针对“手机拍照 + 多样版式”这个真实场景打磨过的工程化方案。
四、TextIn xParse 做了什么?简单说,就是让歪歪扭扭的化验单也能“好好读”
它能处理“不那么规整”的照片。
倾斜、弯曲、低分辨率、光线不均、手指遮挡……这些患者上传时的常见问题,在解析之前会被自动矫正和增强。你不需要写预处理代码,上传的是什么样,它都尽量给你识别清楚。
它能看懂不同版式的检验报告。
无论是表格型、列表型、上下结构还是左右结构,TextIn xParse 都能自动识别出“项目名称”“结果值”“单位”“参考范围”“异常标识”等关键字段,并输出结构化的 JSON。不需要为每一种版式写规则。
它能准确识别特殊符号和单位。
↑、↓、±、μ、β、mmol/L、μg/L……这些医疗报告里的“常客”,TextIn xParse 做了专项训练,识别准确率显著高于通用 OCR。符号不乱码,单位不丢失。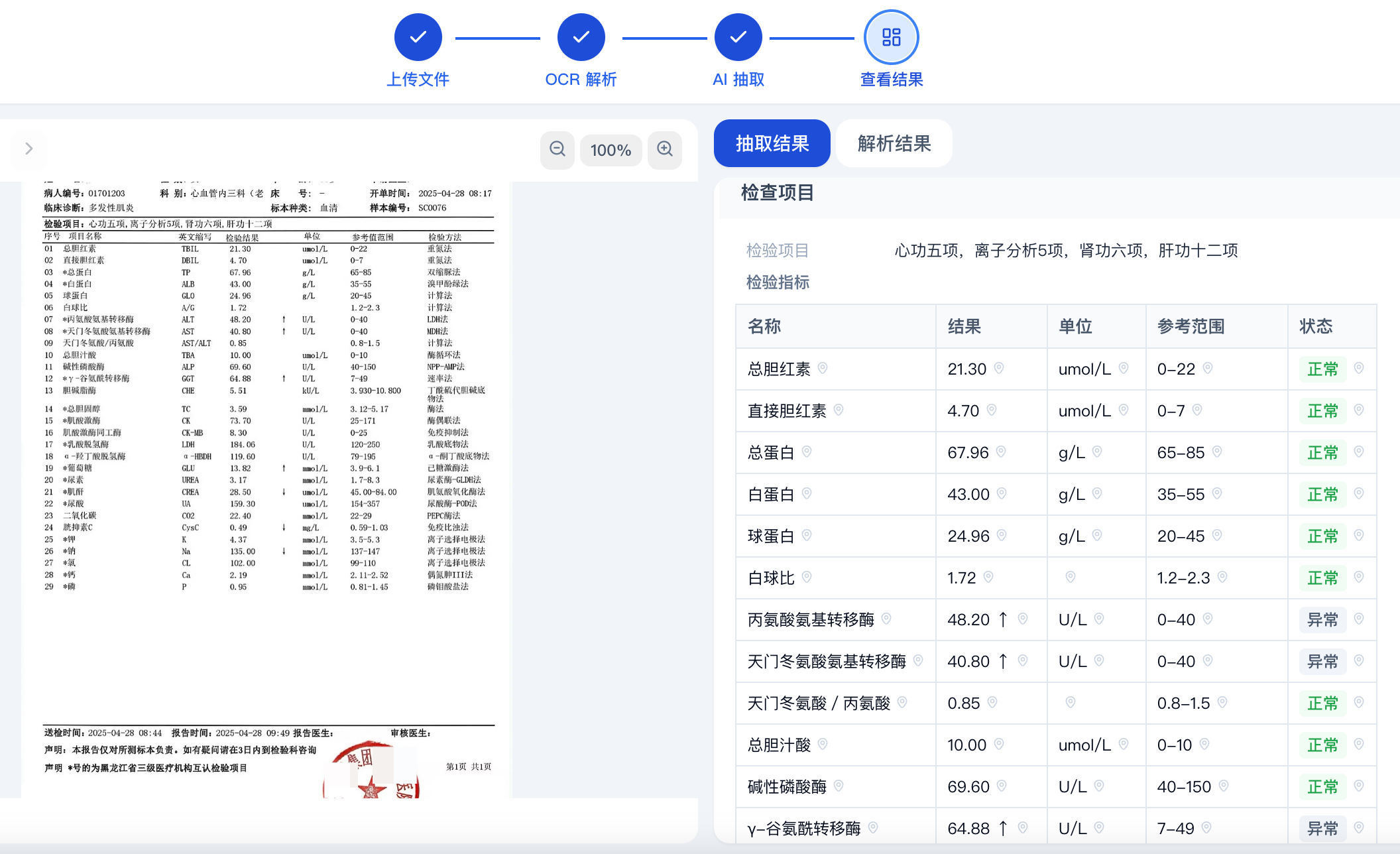
它能告诉你“这个数据是从哪里来的”。
每一个识别出的字段,都附带了在原图中的坐标位置(四角点、矩形框)。当数据有疑问时,可以一键跳转到原图对应区域进行人工复核。这对医疗场景的合规性和准确性来说,至关重要。
它对业务人员和开发者都友好。
不懂代码的业务经理,可以在线 Web 平台上传报告,直接预览解析结果,导出 JSON 或 Excel。开发者可以用标准 API 集成到自己的 C 端 APP、HIS 系统或知识图谱构建流程中,支持私有化部署,满足医疗数据的安全要求。
五、你的团队,还要在“解析”这件事上耗多久?
我们遇到过在解析环节“搁浅”了一段时间的医疗 AI 团队:调模型、写规则、修特殊符号、做图像预处理,花费了算法大量精力。
而那些把解析交给专业底座的团队,产品迭代速度明显更快。他们不用再为“某张化验单读不出来”的客诉头疼,可以把研发资源全部投入到真正创造临床价值的地方。
如果你的团队也在做医疗 AI,不妨问自己两个问题:
当前解析环节的准确率和稳定性,能不能支撑你对接第 100 家医院?
如果解析能力再提升一个台阶,你的产品体验能领先竞品多少?
六、试试看:拿一张手机拍的化验单,看它几秒能读完
我们提供免费测试额度。你可以上传一张真实的医疗报告——最好是那种手机拍的、有点倾斜、带特殊符号的“困难户”——亲自看看 TextIn xParse 的解析效果。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 16
16 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)