BERT的思路到底有多简单?简单到让人怀疑:这也行?

原文:
2018年10月,Google扔了一颗炸弹。
BERT在11项NLP基准测试上同时刷新纪录。这在当时是不可想象的——之前每个任务都有专门的模型,从来没有人用一个模型通杀所有任务。
整个学术界和工业界都震惊了。但当你真正理解BERT做了什么之后,你会发现它的核心idea简单到让人怀疑人生。
简单来说就是:把一句话里随机15%的词遮住,让模型根据上下文猜被遮住的是什么。
没了。
就这?就这居然能刷新11项纪录?
让我们慢慢拆开看,为什么这个看似幼稚的想法,实际上是NLP历史上最优雅的设计之一。
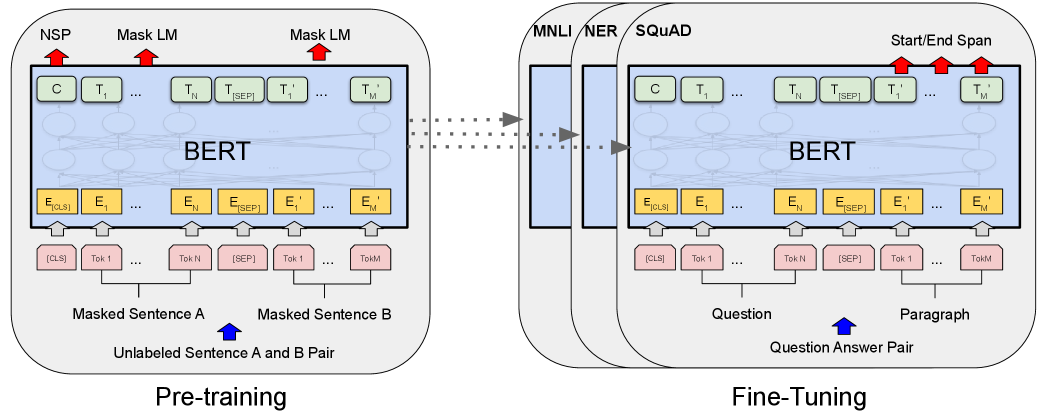
BERT预训练任务示意图(来源:原论文Figure 1)
一、先回到最根本的问题:怎么让机器理解语言?
在做任何具体的NLP任务之前,你首先要让模型获得"语言能力"。这个能力从哪来?
传统思路是监督学习:收集大量标注数据,让模型从标注中学习。但标注数据太贵了,而且每个任务都需要不同的标注。你不可能为翻译、问答、摘要、情感分析各标注几百万条数据。
BERT的思路是:互联网上有无穷无尽的文本,没有人标注,但这些文本本身就是最好的教材。因为每一句话都包含丰富的语言规律——只要你知道怎么"出题"。
怎么出题?
完形填空。
这是一种自监督学习:不需要人工标注,文本本身就是标签。你把一个词遮住,这个词就是"正确答案",模型的预测就是"学生的回答"。出题和批改都是自动的。
所以理论上,维基百科的全部文本、互联网上的所有新闻、所有书籍,都可以变成训练数据。数据量的天花板直接被掀掉了。
二、为什么"完形填空"能训练出语言理解能力?
这是最关键的问题。很多人知道BERT做了什么,但不知道为什么这样做能work。
想象一道英语完形填空题:
"The cat sat on the ____ and looked at me happily."
要填对这个空,你需要什么能力?
首先,你需要知道"cat sat on"后面通常跟着一个家具或平面——这是语义知识。
其次,你需要看到"happily"和"looked at me",推断这不是一个悲伤的场景——这是上下文理解。
最后,你需要综合"一个猫可以坐上去的、在这个场景中合理的物体"——这是推理能力。
发现了吗?做好完形填空,需要理解语义、把握上下文、进行推理。这不就是"语言理解能力"的定义吗?
而且,这道题还有一个巧妙的特性:被遮住的词在句子中间,所以你必须同时看前文和后文才能猜到。
这就是BERT名字里"Bidirectional"(双向)的含义。它不像GPT那样只从左到右预测下一个词,而是前后文同时看。
这个区别看起来小,但影响深远。
三、双向 vs 单向:不只是方向不同那么简单
理解BERT和GPT的区别,要从它们看到的"信息量"入手。
假设有一句话:"我昨天去了____,买了一件红色的外套。"
BERT的预测:模型可以看到"我昨天去了"(前文),也可以看到"买了一件红色的外套"(后文)。从"买了一件红色的外套"这个后文,模型可以直接推断出这是一个卖衣服的地方——商场、服装店等。
GPT的预测:模型只能看到"我昨天去了"。它需要根据前面的信息猜后面是什么。注意,GPT的训练目标是"预测下一个词",所以它不能用后文来辅助判断。
哪一个更容易?显然是BERT。因为可用的信息更多。
但这里有一个根本性的矛盾。
如果你同时用前后文来预测中间的词,那你在生成文本的时候就遇到了麻烦:生成下一个词的时候,后面的文本来还不存在,你不可能"看到后文"。
这就是为什么BERT擅长"理解"(做判断、分类、抽取信息),但不擅长"生成"(写文章、对话)。而GPT恰恰相反——它为了生成而放弃了双向理解。
这个矛盾至今没有完美解决方案。后来的T5、BART尝试了用不同的方式统一理解和生成,但本质上是在两个目标之间做权衡。
四、[CLS]:一个特殊token,怎么就能代表整句话?
BERT在做句子级别的任务(比如判断两句话是否相似、判断情感正负面)时,用了一个特殊token:[CLS]。
这个token放在句子开头,不对应任何实际的词。但在训练完成后,这个[CLS]位置的输出向量,就包含了整句话的语义信息。
听起来像魔法。为什么一个"空位"能学到整句话的意思?
因为自注意力机制。在Transformer的每一层,[CLS]都可以"看到"句子中的所有其他词。经过12层(或24层)的注意力计算,[CLS]的表示已经融合了整句话的信息。
但BERT不是只靠MLM训练的,它还做了另一个任务:NSP(Next Sentence Prediction)——给模型两句话,让它判断第二句是不是第一句话的下一句。
做NSP的时候,两句话之间插入一个[SEP]分隔符,开头放一个[CLS]。模型需要在[CLS]位置做出判断:是/不是。这迫使[CLS]必须理解两句话的含义以及它们之间的关系。
NSP后来被证明是多余的。RoBERTa的实验表明,去掉NSP对效果几乎没有影响。为什么?因为MLM本身已经足够强大——做完形填空的过程,已经让模型学到了足够的句子级表示。NSP这个任务太简单了(只是二分类),提供的信息增量有限。
但[CLS]这个设计保留了下来。它成了"句子级表示"的标准做法。
五、预训练+微调:一个改变了整个行业的范式
BERT最重要的遗产,可能不是模型本身,而是它确立的"预训练+微调"范式。
思路是这样的:
第一步:预训练。用海量无标注文本(比如整个维基百科),通过完形填空任务训练一个通用模型。这一步很贵,可能需要几十张GPU训练几天。但只需要做一次。
第二步:微调。拿预训练好的模型,用你的具体任务的少量标注数据继续训练。比如你有几千条标注了"正面/负面"的商品评论,就在BERT后面加一个分类层,用这些数据微调。这一步很便宜,单卡几十分钟搞定。
为什么这个范式work?
因为预训练阶段已经让模型学会了语言的"通用知识"——语法、语义、常识推理。微调阶段只需要教模型一个新技能:"把这些通用知识应用到具体任务上"。
这跟人类的学习方式很像:你先花十几年积累通用的语言能力和知识(预训练),然后去一个新的岗位,只需要学几天具体的业务规则就能上手(微调)。
在BERT之前,大家习惯为每个任务从零训练一个模型。BERT之后,"预训练+微调"成了标配。后来GPT-3更进一步,连微调都省了——直接在预训练阶段把任务能力学进去(in-context learning)。但追根溯源,BERT是与GPT几乎同时期将这一范式发扬光大的里程碑模型。
六、BERT留给了我们什么?
BERT今天已经不再是SOTA了。它只有3.4亿参数,在今天动辄千亿参数的大模型面前不值一提。
但它留下了几样东西:
完形填空式训练的有效性。后来几乎所有的预训练模型都沿用了MLM或其变体。
预训练-微调范式。虽然后来发展出了prompt tuning、in-context learning等更高效的适配方式,但"先通用预训练,再针对任务适配"的核心思路没有变。
双向理解的必要性。虽然生成模型(GPT系列)占据了今天的热度,但在理解型任务上(搜索、推荐、信息抽取),双向模型依然有不可替代的优势。
如果说Transformer提供了地基,那BERT就是在这块地基上盖的第一栋大楼。它证明了Transformer在NLP上的巨大潜力,也直接催生了后来轰轰烈烈的大模型竞赛。
回头看,BERT的idea确实简单。但最伟大的发明,往往就是那种"简单到让人怀疑:为什么我没想到?"的东西。
论文链接:https://arxiv.org/abs/1810.04805
kk的大模型论文学习笔记 · 第2篇 · BERT

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)