事件类公众号文章撰写Agent【附带源码】
在内容创作领域,文章撰写面临效率低、质量参差不齐的痛点。传统模式下,编辑需要手动搜集素材、构思大纲、撰写正文并配图,耗时耗力。事件类公众号文章撰写Agent系统应运而生,采用5个Agent串行流水线架构,实现从历史事件筛选、信息采集、大纲生成、正文撰写到润色升华的全流程自动化。系统具备智能事件筛选、搜索增强采集、AI配图生成等核心能力,最终输出精美的HTML可视化文章。该系统将传统数小时的工作压缩至分钟级完成,大幅提升内容生产效率,同时保证文章深度与专业性,为公众号运营者提供了强有力的内容创作工具。(本文以历史上的今天为例为大家进行系统讲解)
作者:百度 谭文涛
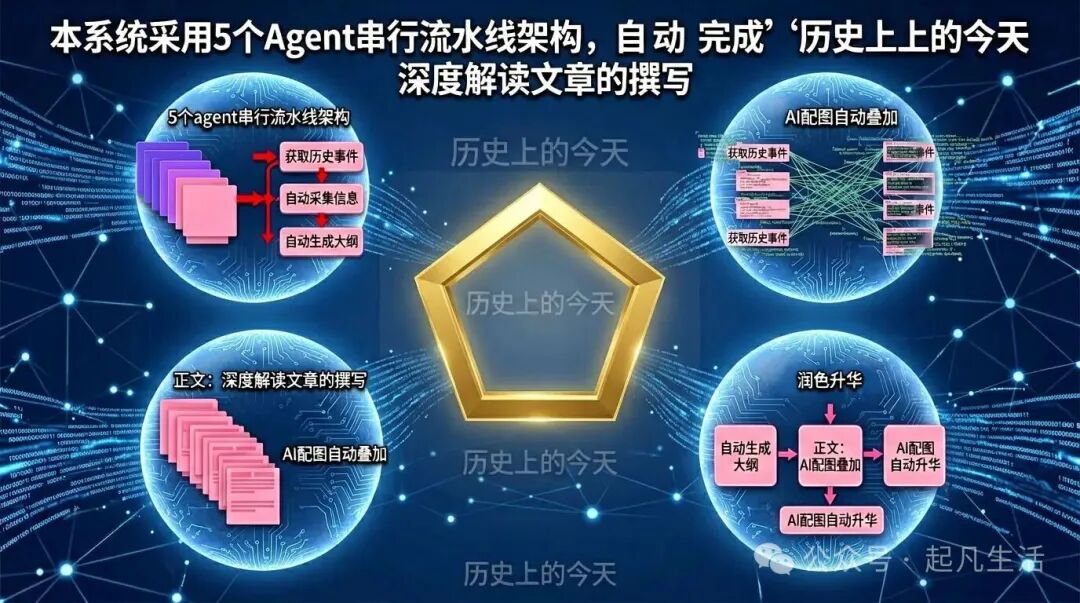
History Today Article Writer MAS — 基于大模型协同的深度历史文章自动撰写系统
📖 项目简介
本系统采用 5个Agent串行流水线 架构,自动完成"历史上的今天"深度解读文章的撰写。从获取历史事件、采集信息、生成大纲、撰写正文(含AI配图)到润色升华,全流程自动化,最终输出精美的HTML可视化文章。
核心能力
- 🔍
智能事件筛选:从当日历史事件中按优先级提炼2~3个重大事件
- 📊
搜索增强采集:拆解子主题,调用百度AI搜索深度采集素材
- 📝
结构化大纲:生成含章节、核心要点、配图位置标注的文章大纲
- 🎨
AI配图生成:撰写时调用千帆文生图API,为文章生成3~7张配图
- ✨
润色升华:LLM润色文字、提炼金句,生成响应式HTML文章
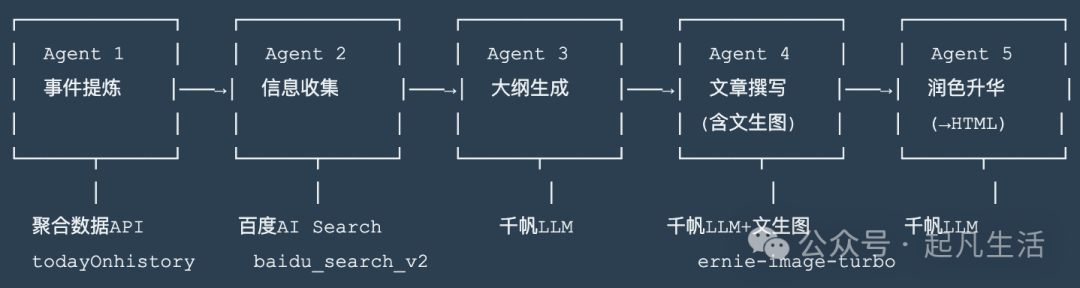
🏗️ 系统架构
🤖 Agent 详细说明
Agent 1:历史上今天重大事件提炼
|
项目 |
说明 |
|---|---|
| 输入 |
当天日期 |
| 处理 |
调用聚合数据 |
| 筛选优先级 |
爱国 > 科技 > 人物 > 社会 > 文化 |
| 输出 |
2~3个精选事件(含日期、标题、类别、关键词、选择理由) |
| 外部依赖 |
聚合数据 todayOnhistory API |
Agent 2:信息收集
|
项目 |
说明 |
|---|---|
| 输入 |
精选事件列表 |
| 处理 |
LLM拆解搜索计划(5维度)→ 百度AI搜索采集 → LLM整合素材 |
| 搜索维度 |
事件背景、核心过程、深远影响、鲜为人知、当代回响 |
| 输出 |
结构化素材库(关键事实、引用、争议点、叙事摘要) |
| 外部依赖 |
百度AI Search(baidu_search_v2) |
Agent 3:文章大纲生成
|
项目 |
说明 |
|---|---|
| 输入 |
精选事件 + 采集素材 |
| 处理 |
LLM生成结构化深度解读大纲 |
| 章节结构 |
引言 → 事件解读×2~3 → 结语 |
| 配图标注 |
标记3~7个 |
| 输出 |
文章标题、副标题、章节大纲、配图建议、叙事弧线 |
| 外部依赖 |
千帆/Ollama LLM |
Agent 4:文章撰写(含配图)
|
项目 |
说明 |
|---|---|
| 输入 |
文章大纲 + 采集素材 + 精选事件 |
| 处理 |
逐章节LLM撰写正文,在标记位置调用文生图生成配图 |
| 文生图规则 |
场景化描述、历史写实风格、中文提示词50~100字 |
| 输出 |
各章节正文(Markdown)+ 配图(PNG) |
| 外部依赖 |
千帆/Ollama LLM + 千帆 ernie-image-turbo |
Agent 5:润色升华
|
项目 |
说明 |
|---|---|
| 输入 |
撰写的文章正文 |
| 处理 |
LLM润色文字、提炼金句、优化排版 |
| 润色维度 |
文字润色、逻辑优化、情感升华、排版美化 |
| 输出 |
润色结果 + 金句 + 修改说明 |
| 最终输出 |
响应式HTML文章(配图base64内嵌) |
| 外部依赖 |
千帆/Ollama LLM |
📁 项目结构
history-today-writer/
├── config.py # 全局配置
├── main.py # 主入口(流水线编排)
├── html_builder.py # HTML报告生成器
├── clients/
│ ├── __init__.py
│ ├── llm_client.py # LLM双后端客户端(千帆+Ollama)
│ ├── search_client.py # 百度AI Search客户端
│ ├── history_client.py # 聚合数据todayOnhistory客户端
│ └── image_client.py # 千帆ernie-image-turbo文生图客户端
├── agents/
│ ├── __init__.py
│ ├── event_extractor.py # 事件提炼Agent
│ ├── info_collector.py # 信息收集Agent
│ ├── outline_generator.py # 大纲生成Agent
│ ├── article_writer.py # 撰写Agent(含配图生成)
│ └── polish_agent.py # 润色升华Agent
├── prompt/
│ ├── event_extractor.md # 事件提炼提示词
│ ├── info_collector.md # 信息收集提示词
│ ├── outline_generator.md # 大纲生成提示词
│ ├── article_writer.md # 撰写提示词(含文生图规则)
│ └── polish_agent.md # 润色升华提示词
└── output/
└── images/ # AI生成配图存放目录🚀 快速开始
环境要求
-
Python 3.10+
-
requests 库:
pip install requests
配置
编辑 config.py 或通过环境变量配置:
|
配置项 |
环境变量 |
说明 |
默认值 |
|---|---|---|---|
|
LLM后端 |
LLM_PROVIDER |
qianfan
或 |
qianfan |
|
千帆API Key |
QIANFAN_API_KEY |
百度千帆API密钥(bce-v3格式) |
内置默认值 |
|
千帆模型 |
QIANFAN_MODEL |
千帆模型名称 |
ernie-x1-turbo-32k |
|
Ollama地址 |
OLLAMA_BASE_URL |
Ollama服务地址 |
http://localhost:11434 |
|
Ollama模型 |
OLLAMA_MODEL |
Ollama模型名称 |
qwen2.5:7b |
|
历史API Key |
HISTORY_API_KEY |
聚合数据API密钥 |
内置默认值 |
|
搜索API Key |
BAIDU_SEARCH_API_KEY |
百度AI Search密钥 |
内置默认值 |
运行
# 默认模式(千帆后端,当天日期)
python3 main.py
# 指定日期(M/D格式)
python3 main.py --date 5/7
python3 main.py --date 10/1
# 切换到Ollama后端
python3 main.py --ollama
# 组合使用
python3 main.py --ollama --date 10/1
# 显示帮助
python3 main.py help输出
运行后在 output/ 目录生成:
history_today_*.html— 完整的可视化文章(响应式HTML,配图内嵌)
images/— AI生成的配图文件(PNG)
🔧 技术栈
|
组件 |
技术 |
说明 |
|---|---|---|
| LLM |
百度千帆 / Ollama |
双后端,零SDK,纯HTTP调用 |
| 文生图 |
千帆 ernie-image-turbo |
支持b64_image和url两种返回 |
| 搜索 |
百度AI Search |
baidu_search_v2数据源 |
| 历史事件 |
聚合数据 todayOnhistory |
M/D格式日期查询 |
| 提示词管理 |
Markdown文件动态加载 |
prompt/目录下5个独立文件 |
| 输出格式 |
HTML(响应式) |
base64内嵌配图,单文件可分享 |
📊 数据流
日期(月/日)
│
▼
┌──────────────────────────┐
│ 聚合数据 todayOnhistory │ ──→ 事件列表(JSON)
└──────────────────────────┘
│
▼ LLM筛选(爱国>科技>人物>社会>文化)
┌──────────────────────────┐
│ 2~3个精选事件 │ ──→ {date, title, category, keywords, significance}
└──────────────────────────┘
│
▼ LLM拆解搜索计划
┌──────────────────────────┐
│ 百度AI Search × N │ ──→ 搜索结果文本
└──────────────────────────┘
│
▼ LLM整合素材
┌──────────────────────────┐
│ 结构化素材库 │ ──→ {key_facts, notable_quotes, controversies, narrative}
└──────────────────────────┘
│
▼ LLM生成大纲
┌──────────────────────────┐
│ 文章大纲+配图位置标注 │ ──→ {outline, image_suggestions(3~7处)}
└──────────────────────────┘
│
▼ LLM逐章撰写 + 千帆文生图
┌──────────────────────────┐
│ 正文(Markdown) + 配图 │ ──→ chapters[].content + images[].png
└──────────────────────────┘
│
▼ LLM润色 + HTML构建
┌──────────────────────────┐
│ 最终HTML文章 │ ──→ output/history_today_*.html
└──────────────────────────┘⚠️ 注意事项
- API配额
:聚合数据每日有调用限额,百度AI Search和千帆API按量计费
- 文生图耗时
:每张配图生成约10~30秒,3~7张配图总耗时1~4分钟
- 搜索间隔
:批量搜索默认2秒间隔,避免触发限流
- Ollama要求
:使用Ollama后端需本地启动服务并拉取模型(
ollama pull qwen2.5:7b) - 输出大小
:HTML文件因base64内嵌配图,单文件可能2~10MB
项目源码
详见文章顶部绑定资源包

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 14
14 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)