AI修炼记3-RAG
一. RAG是什么?
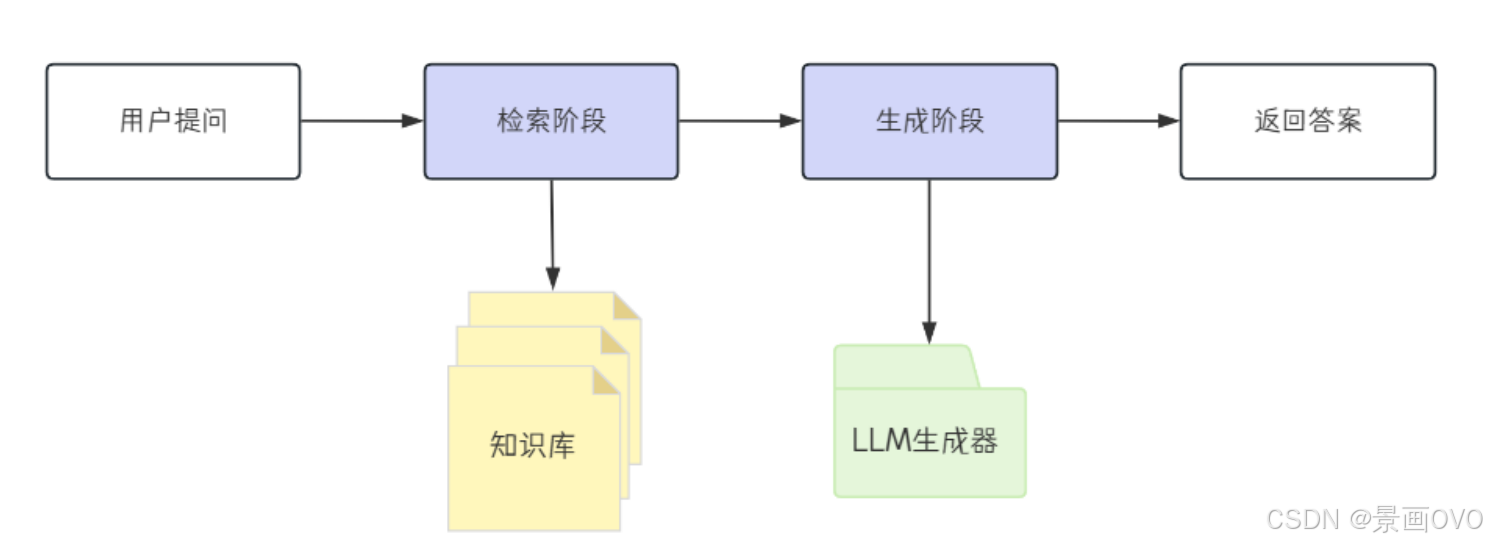
- 大模型训练后仍会有一些接触不到的隐私数据, 例如公司的机密文件等等, 而如果对这些相关知识进行提问时, 大模型就会产生幻觉, 以为自己知道, 从而给出错误答案
- RAG (检索增强生成) 用于构建外部的知识库, 客户端调用大模型进行回答之前, 会先去RAG知识库中检索相关内容, 然后添加到模型上下文, 大模型结合训练数据与上下文内容, 来给出更准确的答案
二. RAG知识库构建流程
参考文档 Spring AI Alibaba
1. ETL流程介绍
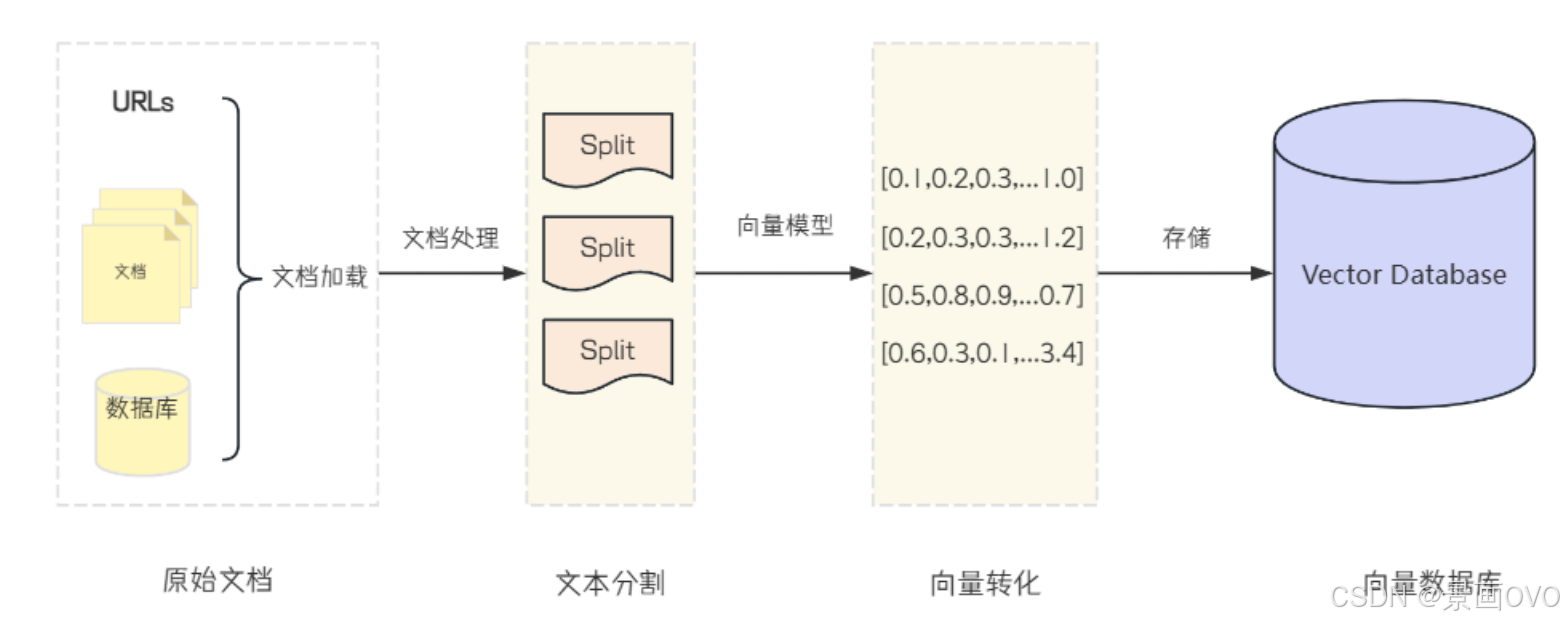
① ETL(Extract、Transform、Load)框架是 Retrieval Augmented Generation (RAG) 用例中数据处理的支柱, 即RAG知识库的构建遵循ETL流程
- Extract: 从原始数据中读取内容, 将源数据解析为基础结构Document, 原始数据可以是各种类型的文件
- Transform: 将数据读取后得到的Documents集合, 进行数据进行切割, 分块, 生成更精细更可用Documents集合, 如给每个Document块统一格式、去除乱码、添加标签等
- Load: 将转化后的数据向量化并存入向量数据库
② ETL的三大接口
- DocumentReader: 将不同的文件来源, 转化为相同的实体类文档
public interface DocumentTransformer extends Function<List<Document>, List<Document>> {
default List<Document> transform(List<Document> transform) {
return apply(transform);
}
}
- DocumentTransformer: 转换一批文档作为处理工作流的一部分, 对数据进行精细打磨
public interface DocumentTransformer extends Function<List<Document>, List<Document>> {
default List<Document> transform(List<Document> transform) {
return apply(transform);
}
}
- DocumentWriter: 管理 ETL 过程的最后阶段, 准备文档, 将文档写入到向量数据库
public interface DocumentWriter extends Consumer<List<Document>> {
default void write(List<Document> documents) {
accept(documents);
}
}
2. ETL实例类介绍
下面的实例类, 都是Spring AI 官方提供的👇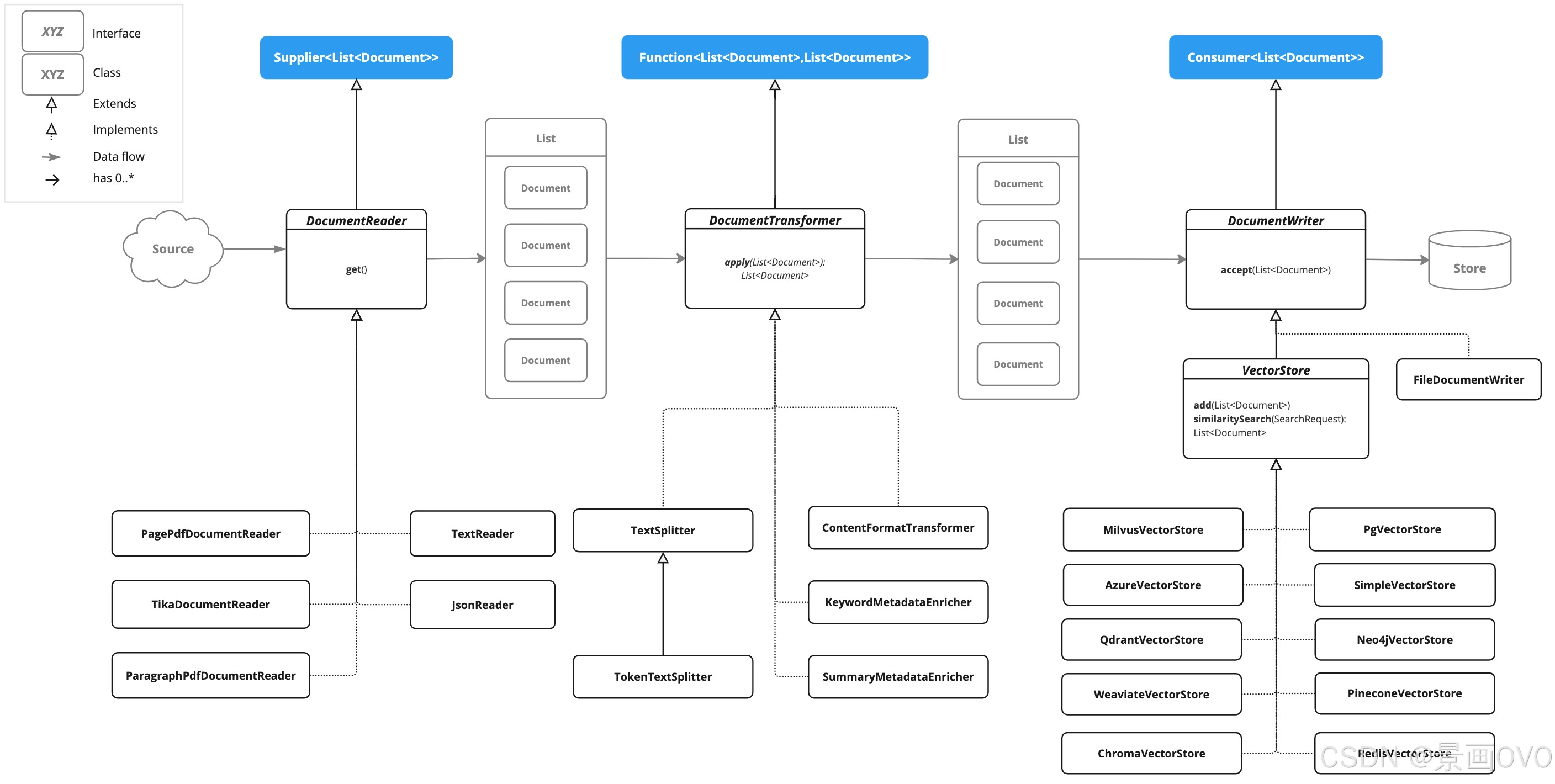
(1) Document
- Document: 文档的基本单位Document 是ETL API的核心数据模型, 它构成了整个数据处理流程的基本单元, 其中包含文本、元数据,以及可选的额外媒体类型,如图像、音频和视频
属性介绍:
- String id: 文档Document的唯一标识, 在一条ETL流程中, 传入的是一个Document集合, 每个文档之间用唯一id进行区分
- String content: 从原始文档提取的主要文本内容
- Map<String, Object> metadata: 键值对形式的元数据, 可以用来存储标签, 编码类型等, 后期检索时可以根据元数据中的内容来快速过滤和筛选
- media: 用于支持多模态的RAG, 如语音,图片等, 检索时可以同时利用文本和媒体特征, getMimeType() -> 媒体类型, getData() -> 媒体的数据

(2) Source
- Source: 数据源, 要为哪些文件/内容构建RAG知识库, 可以是PDF、Excel、Text、HTML、PPT等等多种格式的文件
(3) Reader
-
Reader: 数据源读取器, 将它们转换为 Document 对象列表
-
SpringAI 提供了很多开箱即用的阅读器, 都实现了DocumentReader接口, 如JsonReader(JSON阅读器)、TextReader(文本阅读器)、JsoupDocumentReader (HEML阅读器)、MarkdownDocumentReader(Markdown阅读器)、PagePdfDocumentReader(PDF按照页面阅读器)、ParagraphPdfDocumentReader (PDF按照目录的阅读器)、还有万能阅读器TikaDocumentReader, 参考Tika阅读器文档
-
阅读器类中主方法是List < Document >get(), 用来读取数据
-
当然 Spring-AI-Alibaba社区 也提供了更多的拓展阅读器, 还有相对应的 阅读器文档
-
对于Reader的各种类的使用示例在 Spring AI Alibaba 或 Spring AI 中
(4) Transformer
Transformer: 对文档进行打标签, 数据清洗, 分块等精细处理, 主要方法是List apply(List< Document > documents)
- TokenTextSplitter 是 TextSplitter(抽象类) 的实现,它使用 CL100K_BASE 编码基于 token 计数将文本拆分为块, TextSplitter 实现了 DocumentTransformer 接口, SpringAI还提供了一个按照句子分块的分割器 -> SentenceSplitter

- KeywordMetadataEnricher 使用生成式 AI 模型从文档内容中提取关键字并将它们添加为元数据, 同样实现了 DocumentTransformer 接口

- SummaryMetadataEnricher 使用生成式 AI 模型为文档创建摘要并将它们添加为元数据。它可以为当前文档以及相邻文档(上一个和下一个)生成摘要, 同样实现了 DocumentTransformer 接口

(5) Writers
Writers: 将文档列表向量化并存储起来, 实现了 DocumentWriter 接口
- FileDocumentWriter 是一个 DocumentWriter 实现,它将 Document 对象列表的内容写入文件, 主要方法是accept(List< Document > docs), 这个方法应用的很少, 一般都是存储到向量数据库中

(6) VectorStore
VectorStore: 向量数据库接口, 将文档列表向量化并存储到该数据库, 同时 VectorStore接口 继承了DocumentWriter 接口
- 向量数据库使用时可以自动将文档转化为向量, 需要传入 EmbeddingModel 模型
- SpringAI支持很多向量数据库, 如Redis, pinecone等, 同时SpringAI内置了一个内存数据库, 可以直接简单测试
- 主要方法是 void add(List< Document > documents)
// 在test运行前, 需要运行的方法
@TestConfiguration
static class TestConfig {
@Bean
public SimpleVectorStore vectorStore(DashScopeEmbeddingModel embeddingModel) {
return SimpleVectorStore.builder(embeddingModel).build();// SpringAI 自带的内存向量数据库
}
}
// 将上面静态类中创建的 SimpleVectorStore 注入
@Autowired
private SimpleVectorStore vectorStore;
// 在test方法运行前的启动方法
@BeforeEach
void setUp() {
// 1. 定义文本文件
Document doc1 = Document.builder()
.text("2025年夏季奥运会将于巴黎举行, 预计吸引全球数百万观众")
.build();
Document doc2 = Document.builder()
.text("对比学习框架下多语言BERT模型的语义表示分析")
.build();
Document doc3 = Document.builder()
.text("暮色中的老槐树在风中摇曳, 枯枝划破绯红的晚霞")
.build();
Document doc4 = Document.builder()
.text("基于Transformer的预训练模型在机器翻译中的迁移学习研究")
.build();
// 2. 将文本进行向量化, 并且存入向量数据库 (无需再手动向量化)
vectorStore.add(Arrays.asList(doc1, doc2, doc3, doc4));
System.out.println("向量数据库初始化完成");
}
三. RAG的使用
1. 向量数据库的相似度检索
VectorStore 可以进行相似度检索, 这也是大模型获取上下文的入口, 方法是List< Document > similaritySearch(SearchRequest request) 或者 List< Document > similaritySearch(String query)
SearchRequest 的主要参数介绍
- query(String query): 要检索的内容
- topK(int topK): 返回前 K 条相关的文档
- similarityThreshold(double threshold): 只返回等于或者等于 threshold 的文档
- similarityThresholdAll(): 返回所有的文档
// 在test运行前, 需要运行的方法
@TestConfiguration
static class TestConfig {
@Bean
public SimpleVectorStore vectorStore(DashScopeEmbeddingModel embeddingModel) {
return SimpleVectorStore.builder(embeddingModel).build();// SpringAI 自带的内存向量数据库
}
}
// 将上面静态类中创建的 SimpleVectorStore 注入
@Autowired
private SimpleVectorStore vectorStore;
// 在test方法运行前的启动方法
@BeforeEach
void setUp() {
// 1. 定义文本文件
Document doc1 = Document.builder()
.text("我是景画")
.build();
Document doc2 = Document.builder()
.text("对比学习框架下多语言BERT模型的语义表示分析")
.build();
Document doc3 = Document.builder()
.text("暮色中的老槐树在风中摇曳, 枯枝划破绯红的晚霞")
.build();
Document doc4 = Document.builder()
.text("基于Transformer的预训练模型在机器翻译中的迁移学习研究")
.build();
// 2. 将文本进行向量化, 并且存入向量数据库 (无需再手动向量化)
vectorStore.add(Arrays.asList(doc1, doc2, doc3, doc4));
System.out.println("向量数据库初始化完成");
}
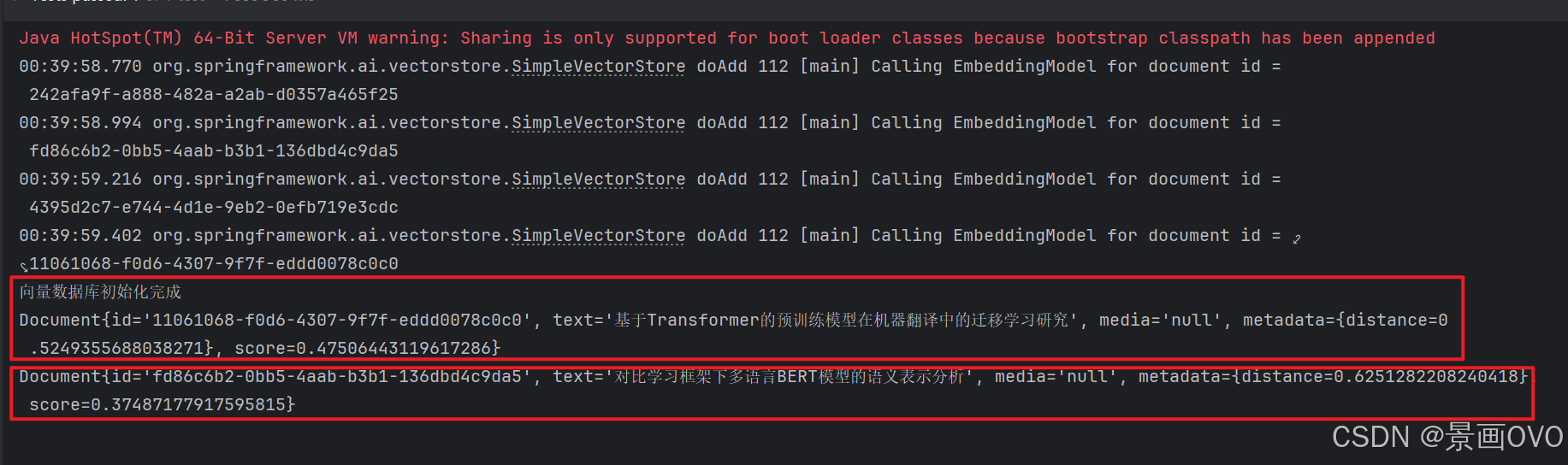
@Test // 通过SearchRequest去向量数据库中查询, 可以设置更多参数
void searchRequest() {
SearchRequest request = SearchRequest.builder()
.query("机器学习")
.similarityThreshold(0.3) // 相似度阈值 -> 分数,大于该分数的才会加入返回列表
.topK(5) // 取前几个
.build();
List<Document> documents = vectorStore.similaritySearch(request);
documents.forEach(System.out :: println);
}
2. Advisor
- Spring AI 使用 Advisor API 为常见的 RAG 流程提供开箱即用的支持, 用于实现检索增强生成, 向量数据库存储 AI 模型不知道的数据。当用户问题发送到 AI 模型时, QuestionAnswerAdvisor 会查询向量数据库以查找与用户问题相关的文档。
- 另一个实例类 RetrievalAugmentationAdvisor 更灵活可控, 可以设置的参数更多, 可以通过实现自定义的 Retriever 接口来控制检索逻辑, 比如结合关键词匹配与向量相似度的混合检索策略, 或者引入重排序 (re-ranker) 机制提升召回质量. 同时, 还可以通过 PromptTemplate 灵活定义上下文如何融入最终提示
- 通过构建 Advisor 时, 将向量数据库作为参数传入, 来使用外部知识
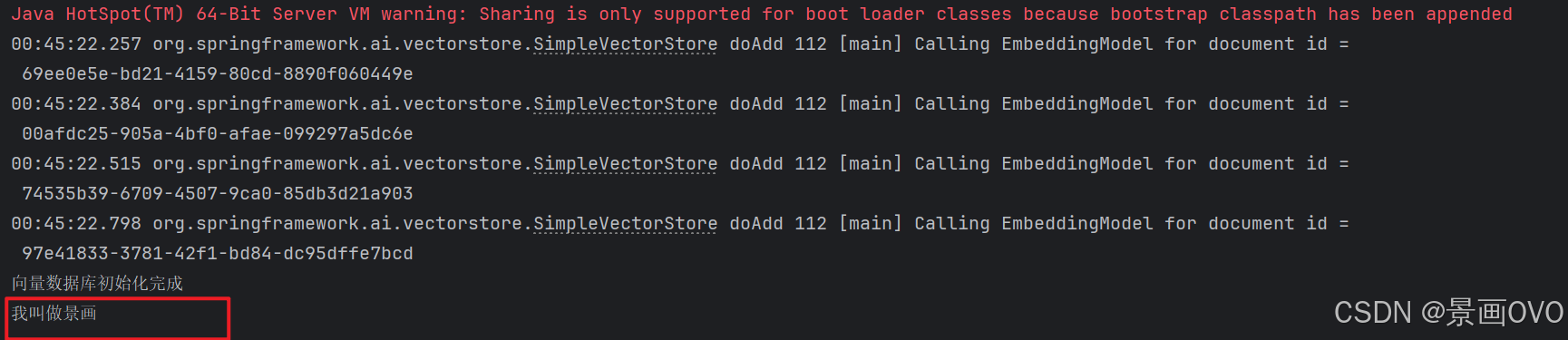
@Test // 设置返回条数和模版
void testRag2() {
ChatClient client = ChatClient.builder(chatModel).build();
String message="你的名字是什么?";
// 提示词模版
PromptTemplate template = new PromptTemplate(
"""
{query}
先面试上下文信息
---------------------
{question_answer_context}
---------------------
根据给定的上下文信息, 回答问题, 并遵循以下规则:
1. 相关知识在上下文时, 直接回答上下文信息
2. 相关知识不存在上下文中时, 直接说 "不知道"
3. 回复中避免使用"根据您提供的信息..."或者"根据上下文..."之类的语句
"""
);
QuestionAnswerAdvisor advisor = QuestionAnswerAdvisor
.builder(vectorStore)
.promptTemplate(template)
.searchRequest(SearchRequest
.builder()
.query(message)
.topK(5)
.similarityThreshold(0.4)
.build())
.build();
String content = client
.prompt()
.user(message)
.advisors(advisor)
.call()
.content();
System.out.println(content);
}
3. 重排序
Rerank(重排序) 指的是初步检索出一批候选文档后, 使用更专业的相关性判断模型, 重新计算候选文档总与查询条件的相似度, 来重新排序
重排序工作流程👇
- 粗排(Retrieve): 通过向量数据库快速搜索, 挑选候选文档
- 精排(Rerank): 调用专业RerankModel模型, 更细力度计算候选文档与查询条件的相似分数
- 根据精排后的得分重新排列文档, 再从中选取前 k 个高相似度文档
- 将优化后的文档内容, 加入提示词上下文, 交给大模型
package com.ran.rag;
import com.alibaba.cloud.ai.advisor.RetrievalRerankAdvisor;
import com.alibaba.cloud.ai.dashscope.chat.DashScopeChatModel;
import com.alibaba.cloud.ai.dashscope.embedding.DashScopeEmbeddingModel;
import com.alibaba.cloud.ai.dashscope.rerank.DashScopeRerankModel;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.document.Document;
import org.springframework.ai.reader.TextReader;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.SimpleVectorStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.boot.test.context.TestConfiguration;
import org.springframework.context.annotation.Bean;
import org.springframework.core.io.Resource;
import java.util.Arrays;
import java.util.List;
// 文本转向量
@SpringBootTest
public class RerankTest {
// 在test运行前, 需要运行的方法
@TestConfiguration
static class TestConfig {
@Bean
public SimpleVectorStore vectorStore(DashScopeEmbeddingModel embeddingModel) {
return SimpleVectorStore.builder(embeddingModel).build();// SpringAI 自带的内存向量数据库
}
}
// 将上面静态类中创建的 SimpleVectorStore 注入
@Autowired
private SimpleVectorStore vectorStore;
// 在test方法运行前的启动方法
@BeforeEach
void setUp(@Value("classpath:file/rule.txt") Resource resource) {
// 1. 读取文本
TextReader reader = new TextReader(resource);
List<Document> documents = reader.get();
// 2. 分割
TokenTextSplitter splitter = new TokenTextSplitter(200, 10, 5, 1000,true);
List<Document> apply = splitter.apply(documents);
// 3. 将文本进行向量化, 并且存入向量数据库 (无需再手动向量化)
vectorStore.add(apply);
System.out.println("向量数据库初始化完成");
}
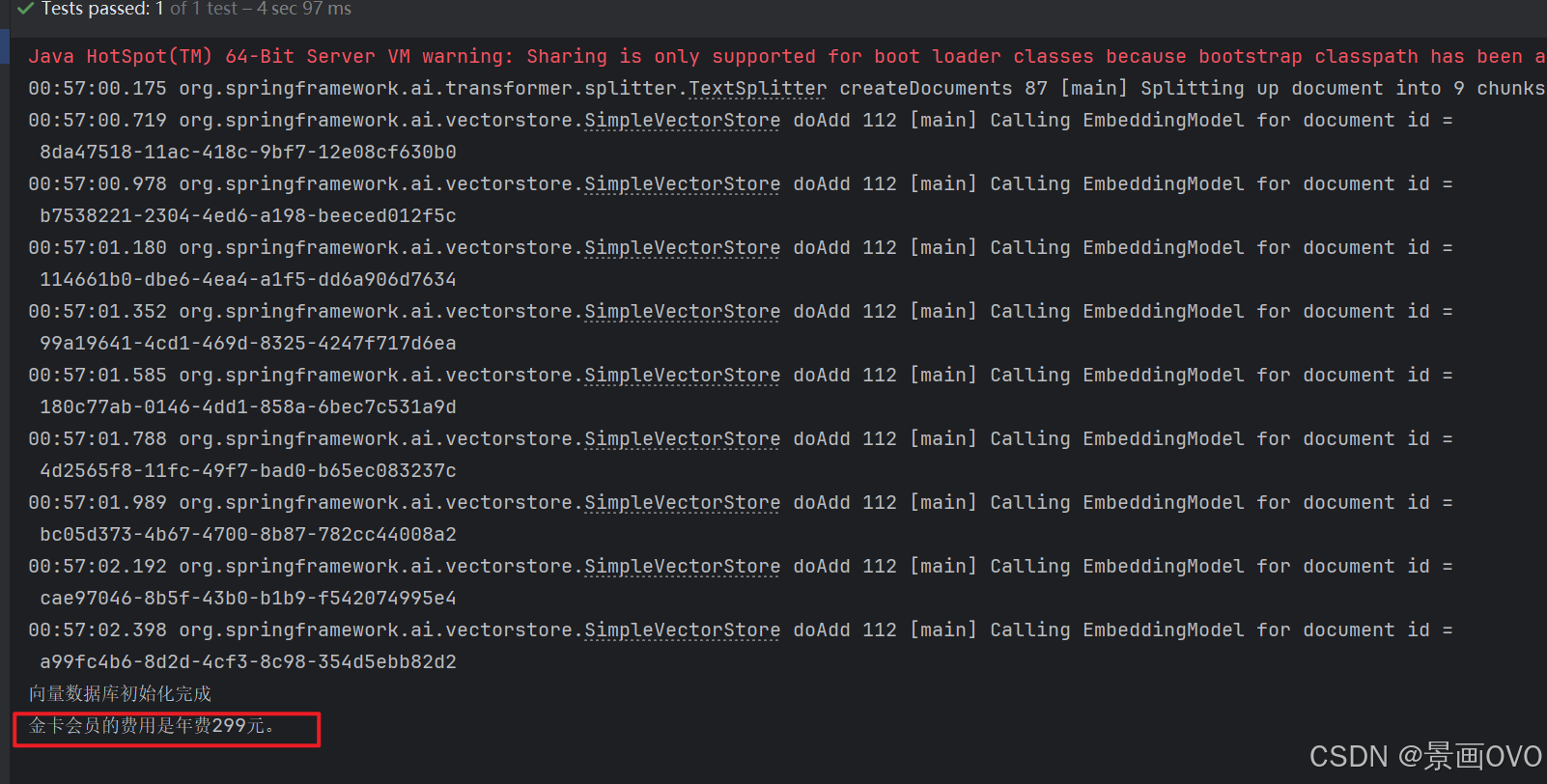
@Test // 通过字符串去向量数据库中查询
void testRerank(@Autowired DashScopeChatModel chatModel, @Autowired DashScopeRerankModel rerankModel) {
ChatClient client = ChatClient.builder(chatModel).build();
RetrievalRerankAdvisor rerankAdvisor = new RetrievalRerankAdvisor(vectorStore,rerankModel,
SearchRequest
.builder()
.topK(3)
.build());
String content = client.prompt().user("金卡会员的费用?")
.advisors(rerankAdvisor)
.call()
.content();
System.out.println(content);
}
}

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)