MindStudio全新内存调试工具,快速定位内存泄漏问题
作者:昇腾实战派
你是否遇到过这样的情况:模型训练到一半突然 OOM,或者推理服务运行一段时间后性能急剧下降?这些问题的根因很可能是NPU 内存泄漏。在 AI 大模型时代,内存管理已成为影响系统稳定性和效率的关键因素,而内存泄漏则是其中最常见且棘手的问题之一。
- 现象:内存总使用量随时间持续上涨,始终无法收敛,经常周期性出现。
- 影响因子:内存分配算法、缓存机制
| 问题子类 | 定义 | 特征 | 常见原因 |
|---|---|---|---|
| 内存泄漏 | 已超出生命周期的内存长期不释放 | 内存使用量持续上涨,常见周期性 | 1. 代码中漏调用释放接口; 2. 不合理的引用关系导致长期持有无用对象引用 |
| 内存碎片 | 可用内存碎片化,无法申请连续大块内存 | 内存占用值持续上涨(或套件内存池持续扩容),但套件内存池已分配内存值未明显上涨 | 内存碎片过多导致无法分配连续内存 |
msMemScope 工具定位内存泄露问题
昇腾 MindStudio 提供了一套完整的内存泄漏排查指南,通过使用专业内存分析工具msMemScope,定位模型训练与推理过程中的内存问题,提供内存泄漏检测、内存对比、内存块监测、内存拆解和低效内存识别等功能,让模型训练和推理更加稳定高效。
1 数据采集方法
采集代码:
import msmemscope
# 配置采集参数
msmemscope.config(
call_stack="c:10,python:5", # 采集调用栈
analysis="leaks,decompose", # 开启泄漏分析和内存拆解
data_format="db" # 输出格式
)
msmemscope.start()
train()
msmemscope.stop()
2 问题排查方法
(1)缓存清理
部分 OOM 场景可能是由于 PyTorch 的缓存机制导致的——每次前向传播和反向传播都会产生临时张量,这些张量会被缓存起来但未及时释放。
在以下位置尝试清理缓存,消除缓存堆积导致的类似泄漏的表象:
- 训练场景:每个 epoch 结束后、每个 step 结束后
- 推理场景:每次推理请求处理完成后、批次处理完成后
- 服务化场景:每次请求处理完成后、配置变更前
这些位置是内存使用可能出现波动的关键点,清理缓存可以有效避免缓存堆积导致的内存占用持续上涨。
# 清除不可达的Python对象
gc.collect()
# 清除torch_npu的缓存
torch_npu.npu.empty_cache()
缓存清理是解决内存泄漏的第一步,但如果清理缓存后问题仍未解决,可能是存在内存碎片。接下来,我们将介绍如何排查和解决内存碎片问题。
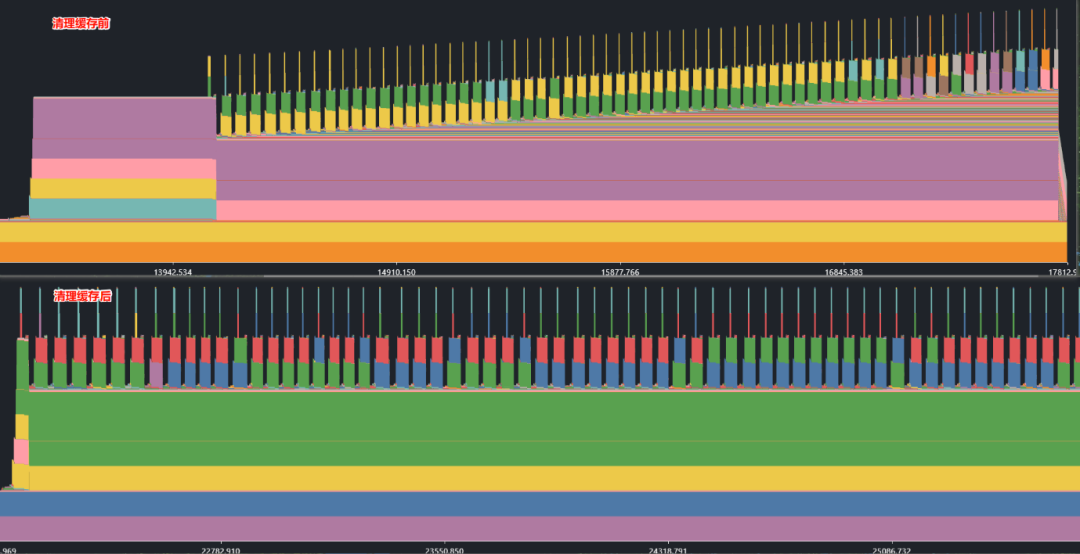
图1 缓存清理前后对比
(2)内存碎片排查
内存池中内存碎片的持续累计也会造成类似于内存泄漏的表象,其典型特征为内存池未分配完就继续扩容。此时有三种常用排查方法,如果出现以下情况,大概率是内存碎片堆积:
- 使用 msMemScope工具 (https://gitcode.com/Ascend/msmemscope) 采集内存数据并可视化,选择较靠后的时间点,查看内存占用拆解图,PyTorch Adaptation(PTA)预留 与 模型占用 两个块差距较大
- 使用 msProf工具 (https://gitcode.com/Ascend/msprobe) 采集内存数据并可视化,内存曲线中 operators allocated 没有明显上涨,但是 operators reserved 间歇性上涨
- 使用 Snapshot (https://docs.pytorch.org/docs/stable/torch_cuda_memory.html#torch_cuda_memory_snapshot) 采集数据并可视化,在 state history 页签选择一个内存占用总量较高的时间点,查看内存池状态图,存在大量白色(未分配)小块内存
以 Snapshot 数据为例,未开虚拟内存场景,内存碎片堆积情况呈下图状:
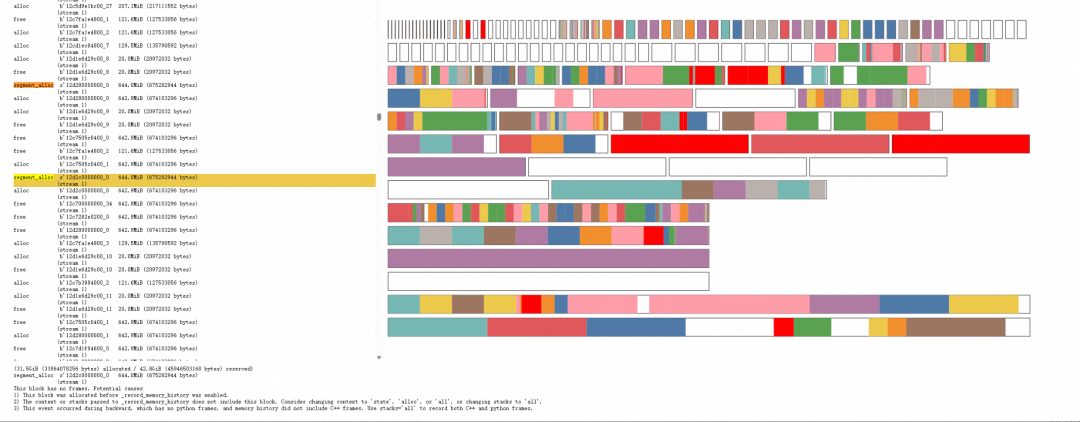
图2 Snapshot内存碎片示例
若出现 PTA 内存碎片,可尝试开启虚拟内存开关:
export PYTORCH_NPU_ALLOC_CONF=expandable_segments:True
若已开虚拟内存,仍存在较多内存碎片,Snapshot 结果呈下图状: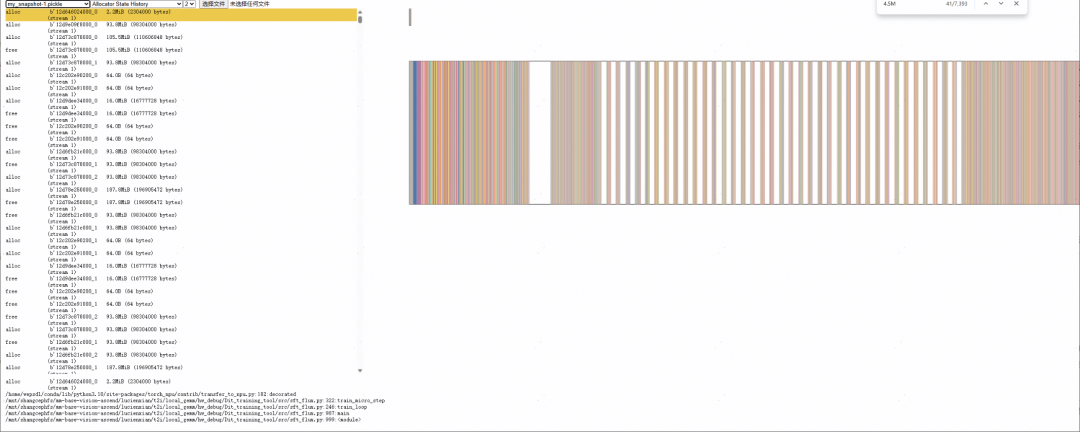
图3 虚拟内存开启后 Snapshot 示例
此时可在每个 epoch 结束后、请求处理低峰期等位置尝试触发内存重整。
torch_npu.npu.empty_cache()
解决了内存碎片问题后,若内存泄漏仍未解决,我们需要进一步筛选长期不释放的内存块。
(3)筛选长期内存
采集内存数据并分析,如果发现有大块内存长期不释放,可以通过查看这些内存块的申请调用栈,最终定位到引入内存泄漏的代码位置。
使用 msMemScope 工具采集内存数据时,建议打开调用栈采集、跳过初始化阶段和适当延长采集时间。
首先,准备采集脚本,开启泄漏检测、内存拆解功能,采集调用栈,执行数据采集。
import msmemscope
msmemscope.config(
analysis="leaks, decompose",
call_stack="python"
) # 开启泄漏检测、内存拆解、调用栈采集
得到如下结果,输出中每个 step 内部泄漏了多个约 1.5MB 小块内存,总共泄漏内存约 398MB,这是典型的内存泄漏现象。
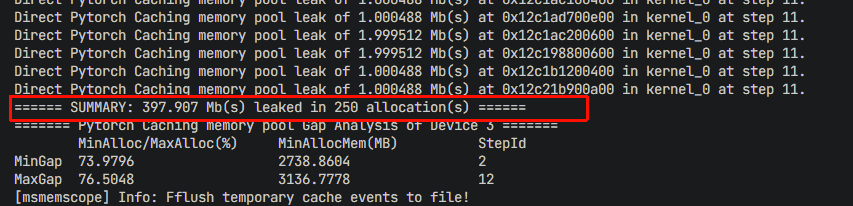
图4 msMemScope 输出示例
接下来,使用 MindStudio Insight (https://gitcode.com/Ascend/msinsight) 进行分析,在内存块图中,内存峰值随每个训练 epoch 增长,同时在每个 epoch 过程中,生成了一些不会释放的内存块,合理怀疑这些内存块为泄漏内存块,并顶高了内存峰值。
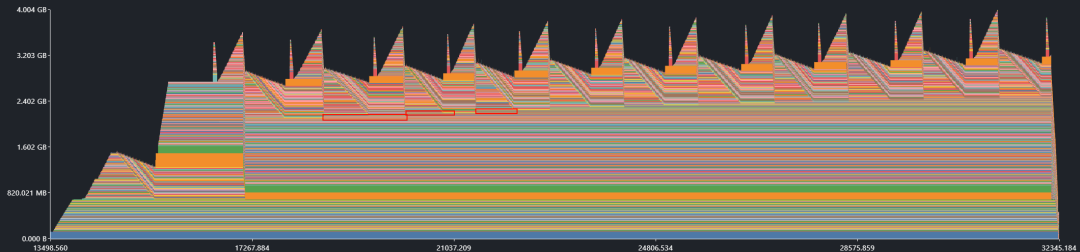
图5 MindStudio Insight 内存块界面
点击怀疑的泄漏内存块,查看详细信息,得到内存地址,大小等信息:
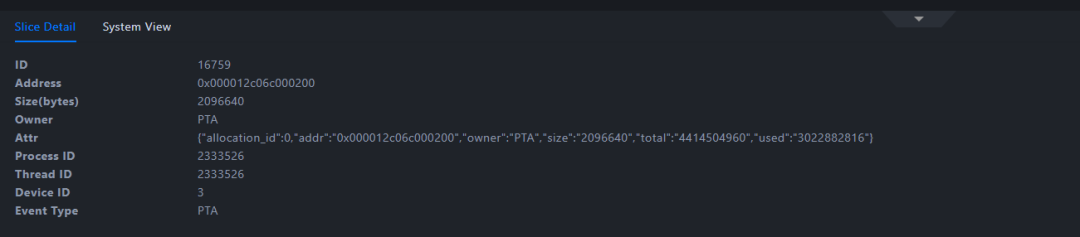
图6 内存块详细信息
在 System View 中,通过地址查看该内存块的申请调用栈:

图7 查找调用栈
得到调用栈信息:
<file_path>/site-packages/torch/_ops.py(723): __call__
<file_path>/msmemscope/Python/msmemscope/aten_collection.py(187): __torch_dispatch__
memory_leak_demo.py(99): create_memory_leak
memory_leak_demo.py(150): main
memory_leak_demo.py(163): <module>
查看内存拆解,在内存拆解视图中,框架层面占用包括:模型权重(weight)、梯度(gradient)、优化器状态(optimizer_state)。内存池层占用包括:PTA 预留内存池、模型占用(实际被模型使用的内存)。两者之间相差 1125MB,说明可能存在内存碎片的现象。
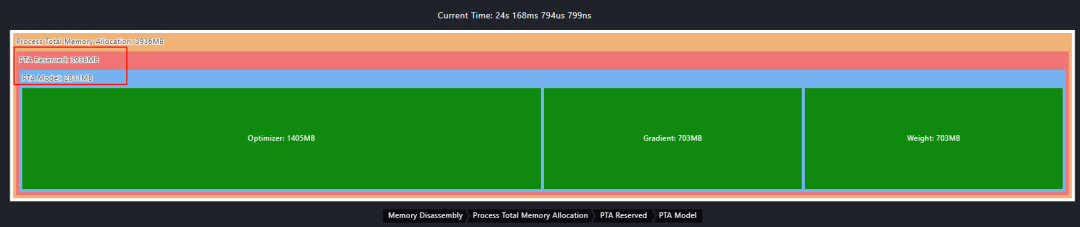
图8 内存拆解详情
通过调用栈信息,可以快速定位到泄漏代码位置:memory_leak_demo.py 第 99 行,即 leak_tensor = torch.randn(512, 512).to(device),泄漏大小为 398MB。通过拆解视图信息,发现预留内存比模型占用内存多,具有内存碎片。
(4)Python 对象泄漏排查
除了上述方法外,对于 Python 进程,我们还需要特别关注 Python 对象的泄漏问题。
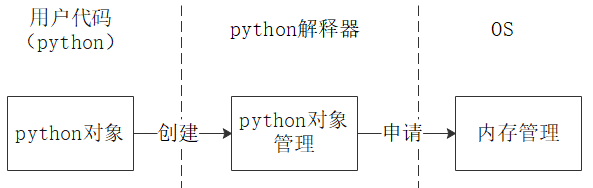
总的来说,排查流程为:确认 Python 对象泄漏 -> 定位泄漏对象 -> 查找对象申请点
详细排查过程请参考 Python 对象泄漏排查指南:https://gitcode.com/Ascend/msmemscope/tree/master/docs/zh/memory_issue_troubleshooting_guide/memory_debug/memory_leak.md
总结
本文介绍了一套完整的内存泄漏排查方法,包括:缓存清理、内存碎片排查、长期内存筛选、Python 对象泄漏排查。通过合理使用内存分析工具,开发者可以快速定位和解决内存泄漏问题,提升模型训练和推理的稳定性与效率。
4 内存分析工具开源社区
- msMemScope 内存分析工具代码仓库昇腾官方社区:https://gitcode.com/Ascend/msmemscope
- 内存问题反馈与讨论:https://gitcode.com/Ascend/msmemscope/issues
欢迎开发者加入社区,共同探讨和解决内存管理问题,推动 AI 系统的稳定性和性能提升。

扫描二维码直达开源社区
欢迎关注MindStudio社区!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)