第 2 篇:第一次让 opencode 读懂一个项目
接下来,我不打算从零开始写一个项目。
我会选择一个已经开发了一半的开源项目,用 opencode 一步步接手、理解、改造它,最终把它打造成一个“微信公众号文章选题工具”。
这个系列不会只讲命令,也不会只讲概念,而是带大家一起动手,看一个普通开源项目如何被 AI 编程工具改造成真正可用的小产品。
我把那个开发到一半的开源项目 放到了这里,咱们所有的操作都围绕这个项目。
项目地址
不要急着让 opencode 写代码:先让它读懂你的项目
想象一个场景:你带一位新同事入职,第一天你就扔给他一个紧急 bug,让他立刻修。
会发生什么?
他大概率会修错地方——因为他还不知道这个项目的上下文,不知道你们的技术选型,不知道哪些是老代码,哪些是新写的。
opencode 也是如此。
第一次进入你的项目,最重要的不是让它写代码,而是让它理解项目。
一、为什么不要一上来就让 AI 改代码
我见过太多人用 opencode 的方式是这样的:
opencode "帮我修复这个bug"
然后得到一段看起来对、但实际上跑不通的代码。
原因很简单:AI 没有读懂你的项目。
就像新同事不知道你们的代码规范,不知道你们用什么框架,不知道数据库结构——opencode 第一次进来,也是一脸懵。
| 场景 | 让 AI 直接写代码 | 先让它理解项目 |
|---|---|---|
| 上下文 | ❌ 没有 | ✅ 完整理解 |
| 代码风格 | ❌ 猜测 | ✅ 匹配 |
| 架构逻辑 | ❌ 盲写 | ✅ 遵循 |
| 潜在风险 | ❌ 忽略 | ✅ 规避 |
第一次的"读题",决定后续所有答案的质量。
二、进入项目根目录启动 opencode
这一步很多人会忽略——直接在任意目录下启动 opencode,然后丢一个问题进去。
❌ 错误示范:
cd ~/下载
opencode "这个项目怎么运行"
✅ 正确姿势:
cd /path/to/your/project
opencode
# 或者带对话模式
opencode --chat
为什么重要?
opencode 只有在项目根目录下,才能准确识别:
- 你的
package.json/requirements.txt/go.mod - 你的目录结构
- 你的配置文件
把它想象成:带新同事参观办公室——先让他知道茶水间在哪,会议室在哪,他才不会走错门。
三、第一条提示词应该怎么写
进入项目后,很多人会问的第一个问题是:
“这个项目是做什么的?”
❌ 无效问题:
这个项目是干嘛的?
✅ 有效问题:
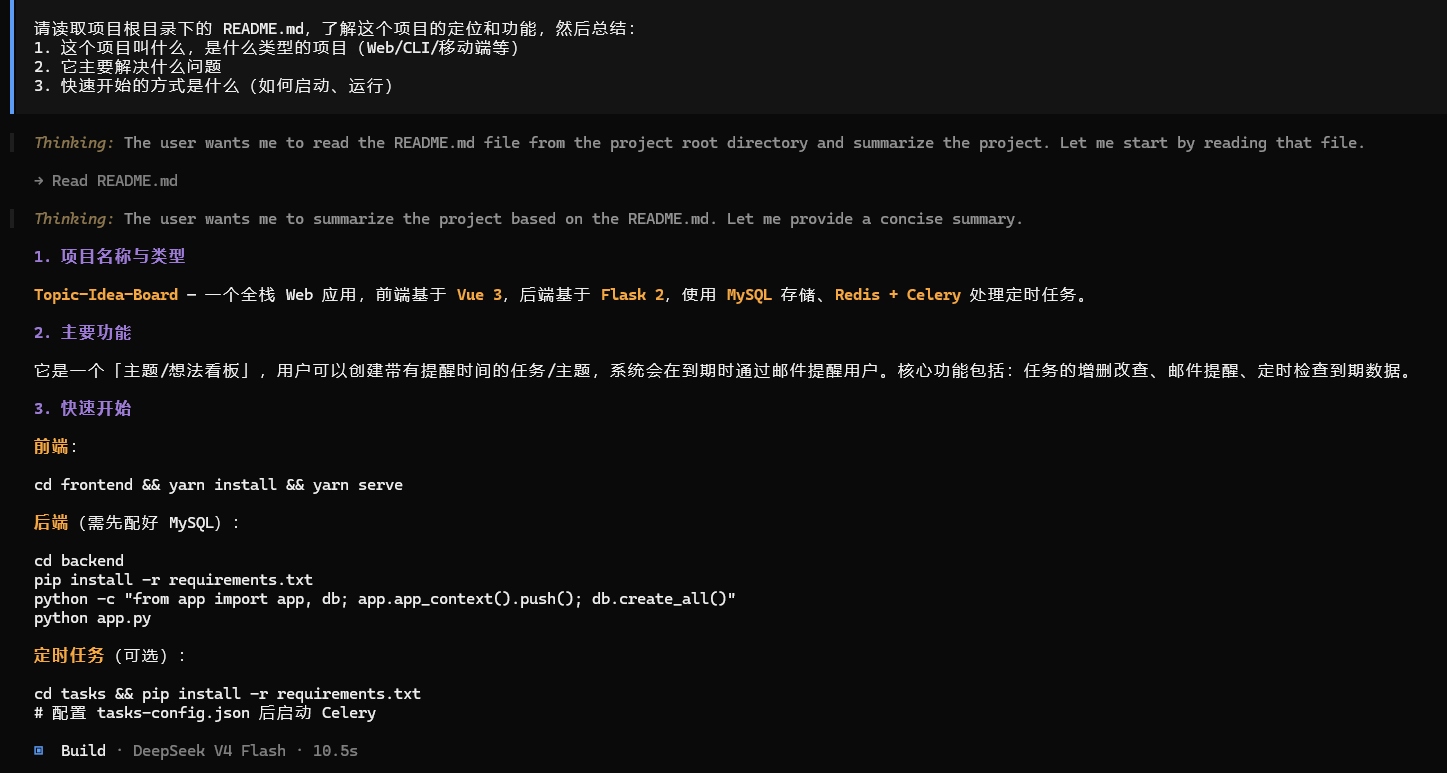
请读取项目根目录下的 README.md,了解这个项目的定位和功能,然后总结:
1. 这个项目叫什么,是什么类型的项目(Web/CLI/移动端等)
2. 它主要解决什么问题
3. 快速开始的方式是什么(如何启动、运行)
为什么这样问更好?
因为你的第一条提问,决定了 AI 建立"第一印象"的方式。
让它先读 README,是最直接、最高效的入口——README 里往往包含了:
- 项目定位
- 技术栈
- 运行方式
- 贡献指南
读懂了 README,就等于拿到了一把钥匙。
四、让 opencode 总结项目技术栈
接下来,让它系统性地"扫描"一遍项目。
✅ 推荐提示词:
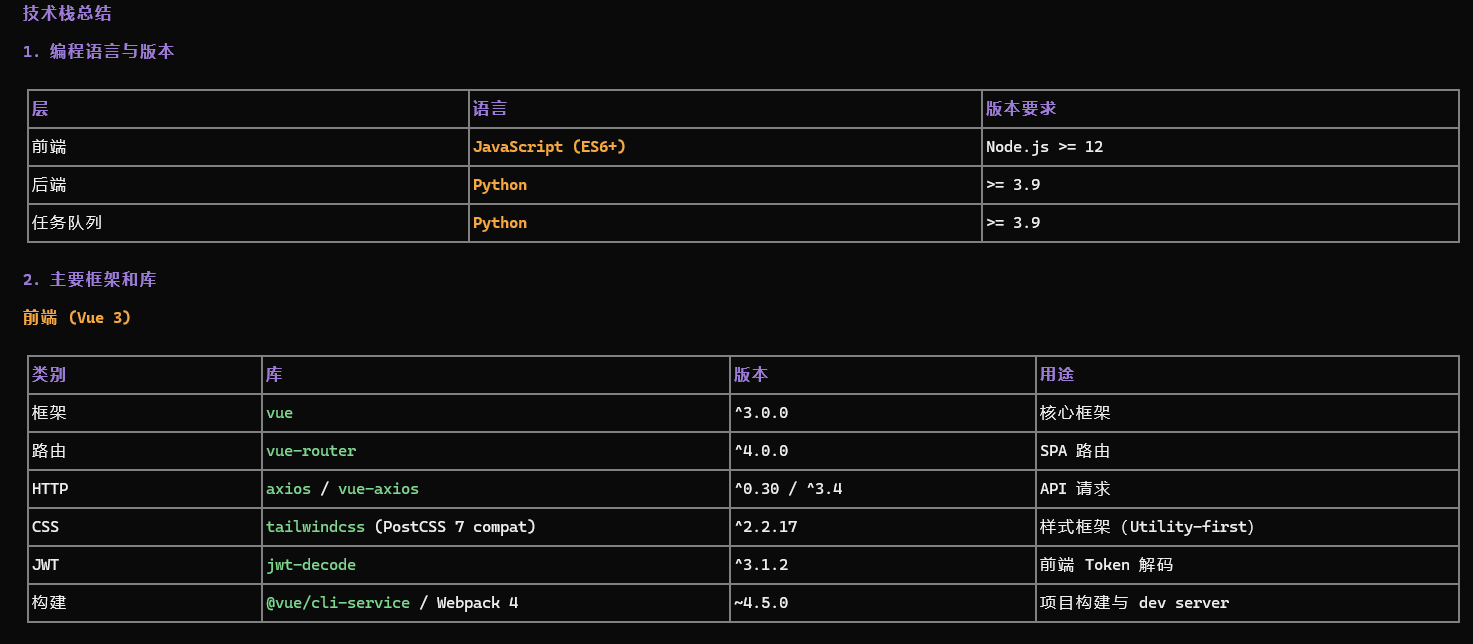
请分析这个项目的技术栈,读取以下关键文件:
- package.json / requirements.txt / go.mod / pom.xml 等依赖文件
- 主要的配置文件
- src 或 lib 目录下的核心代码结构
然后给我一个总结,包含:
1. 使用的编程语言和版本
2. 主要框架和库
3. 数据库类型(如果有)
4. 构建工具
5. 目录结构概览
这样你一眼就能验证:它读对了没有?
五、让它识别前端、后端、数据库和配置文件
复杂项目往往有多层结构。让 opencode 把"楼栋地图"画出来。
✅ 推荐提示词:
请识别并列出这个项目中的:
1. 前端代码位置和使用的框架
2. 后端/API 代码位置
3. 数据库相关文件(模型、迁移脚本)
4. 配置文件(环境变量、API密钥配置)
5. 部署相关文件(Dockerfile、docker-compose.yml)
用清晰的分类列表呈现。
这一步的价值是什么?
- 你能快速验证 AI 是否真的"看懂"了你的项目结构
- 后续让它写代码时,它会知道去哪里找参考代码
- 避免它把前端代码写到后端目录里
六、如何判断它是否真的读懂了项目
这是关键一步。很多人以为 AI 回应了,就算"理解了"。
❌ 不等于理解的表现:
- 回复很长、很专业
- 术语用得很溜
- 代码示例看起来很完整
✅ 真正读懂的判断标准:
| 验证问题 | 预期答案质量 |
|---|---|
| “你们的认证用的是 JWT 还是 Session?” | 能准确说出,并指出相关文件 |
| “这个项目的数据库表结构在哪里?” | 能指向具体的模型文件或 SQL 文件 |
| “部署这个项目需要哪些环境变量?” | 能列出 .env.example 或文档中的变量 |
核心原则:问它具体的问题,看它能不能指向准确的文件路径和代码位置。
如果它只能说概念,说不出具体文件——那它还没真正读懂。
七、项目理解提示词模板
这里给你一个可直接使用的模板,复制粘贴到 opencode:
请完成以下任务,帮助我理解这个项目:
1. 【读取README】读取项目根目录的 README.md,总结项目定位和快速开始方式
2. 【技术栈扫描】读取依赖文件(package.json/requirements.txt等),列出完整的技术栈
3. 【目录结构】用树形结构展示项目目录,标注每个目录的作用
4. 【关键文件定位】找到并列出:
- 配置文件(环境变量、密钥配置)
- 数据库模型/迁移文件
- 主要的 API 路由或页面组件
- 入口文件(main.py / index.js 等)
5. 【运行验证】告诉我如何本地启动这个项目,并验证它运行正常
完成以上步骤后,请用"项目理解摘要"的形式给我一个总结。
使用方法: 第一次进入项目,直接把这段模板扔给 opencode,等它输出完整的理解报告。
八、 让opencode记忆下来重要内容
opencode 扫描项目以后,它在当前会话里“暂时记住了”。
但如果会话变长、session 丢失、换新会话,或者上下文被压缩,它就可能忘。
所以正确做法不是只让它总结给你看,而是要让它把总结写进项目文件。
你已经扫描并总结了当前项目。
现在请把你的项目理解沉淀成项目文档。
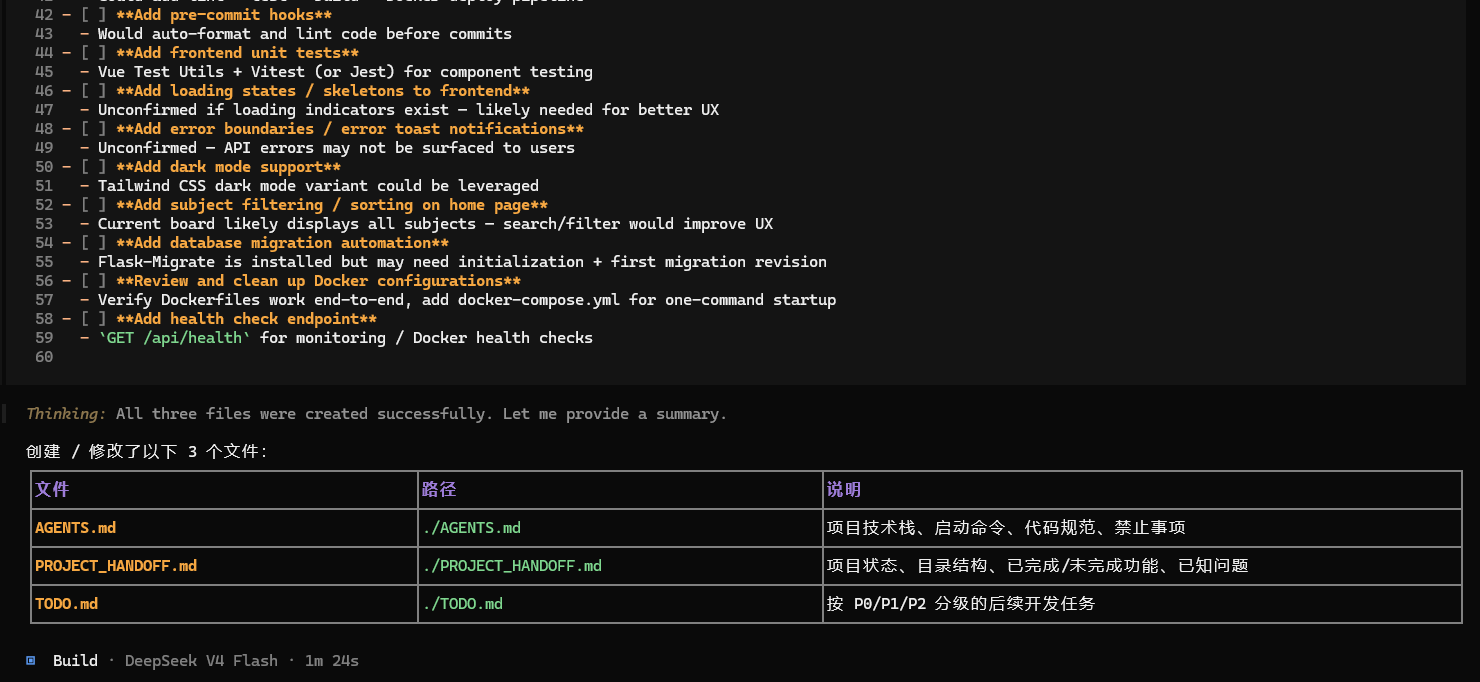
请只创建或更新以下 3 个 Markdown 文件:
1. AGENTS.md
2. PROJECT_HANDOFF.md
3. TODO.md
要求:
- 不要修改业务代码;
- 不要修改 src 目录;
- 不要改 package.json、requirements.txt;
- 只写 Markdown 文档;
- 内容必须基于当前项目真实情况;
- 不确定的地方标注“未确认”;
- 不要编造不存在的功能。
AGENTS.md 用来给后续 opencode 会话读取,说明项目规则、技术栈、启动命令、禁止事项。
PROJECT_HANDOFF.md 用来记录项目当前状态,包括项目目标、目录结构、核心模块、已完成功能、未完成事项、已知问题。
TODO.md 用来记录后续开发任务,按 P0 / P1 / P2 分类。
完成后请告诉我你创建或修改了哪些文件。
九、下一篇预告:先把半成品搞成成品
现在 opencode 已经"读懂"了你的项目。
下一步,你就要让它真正干活了——写代码、改功能、修 bug。
下一篇,我会给你一个实战场景,演示如何用opencode,把这个半成品先搞成一个成品。
总结
| 步骤 | 动作 | 目的 |
|---|---|---|
| 1 | cd 到项目根目录再启动 opencode | 让它有上下文 |
| 2 | 第一条提示词让它读 README | 建立基础认知 |
| 3 | 扫描技术栈和目录结构 | 掌握全貌 |
| 4 | 定位关键文件 | 验证理解准确性 |
| 5 | 用具体问题测试 | 判断是否真的读懂 |
记住:磨刀不误砍柴工。第一次让它读懂项目,后面每一次提问都会快 10 倍。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 20
20 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)