SubQ 与 SSA 架构深度解析:Transformer 的敌人不是更大模型,而是更便宜的长上下文
文章目录
🍃作者介绍:AI 应用负责人/AI产品架构师,阿里云专家博主。专注 LLM 应用开发、Agent 系统设计、具身智能与工业 AI 落地。日常在大模型训练、Coding Agent 工具链、AI 产品商业化等方向持续输出实战内容。
🦅个人主页:@逐梦苍穹
🐼GitHub主页:https://github.com/XZL-CODE
✈ 您的一键三连,是我创作的最大动力🌹
1、Transformer 真正的敌人,不是另一个更大的 Transformer
术语速查(可选阅读)
本文涉及的技术概念较多,这里集中解释核心术语,帮助非架构背景读者快速建立上下文。
注意力机制相关
- Attention(注意力):Transformer 的核心计算方式。模型在生成每个 token 时,会"回看"上下文中所有其他 token,计算它们之间的相关性权重。看的越多,相关性计算越密集。
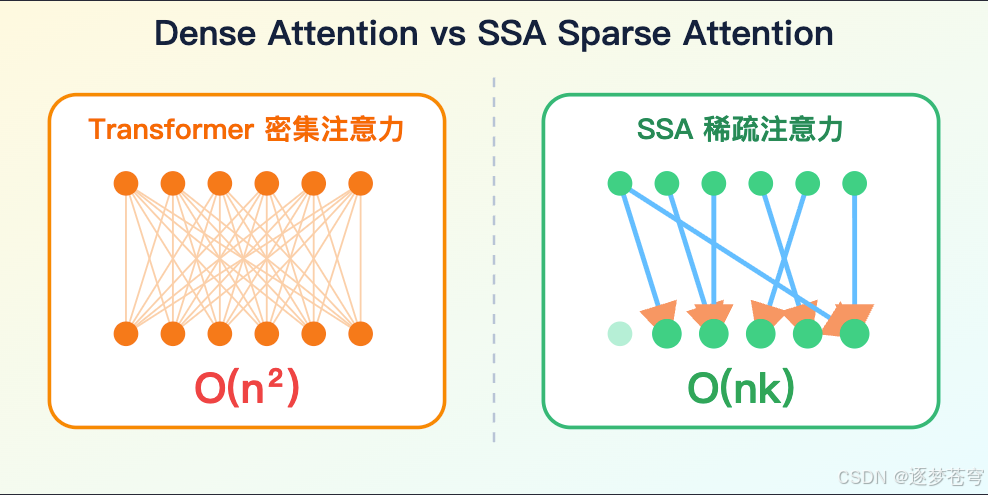
- Dense Attention(密集注意力):标准注意力模式——每个 token 都要和上下文中所有其他 token 计算相关性,一个不漏。好处是信息无遗漏,坏处是计算量随序列长度平方增长(O(n²))。
- Sparse / Selective Attention(稀疏/选择性注意力):不让每个 token 盲目看全场,而是只挑重要的位置计算注意力。SubQ 的 SSA 就走这条路。
- KV Cache(键值缓存):模型推理时,已经处理过的 token 的中间结果会缓存起来(key 和 value),避免重复计算。上下文越长,这个缓存越大,吃显存越多。
- MLA(Multi-head Latent Attention,多头潜在注意力):DeepSeek 提出的技术。把 key/value 压缩到低维"潜在表示"来存,大幅减少 KV cache 体积,让 decode 阶段更省显存。
- GQA(Grouped Query Attention,分组查询注意力):一种注意力变体,多个 query 共享同一组 key/value,减少计算量和缓存大小。Llama 2/3 等模型采用。
- MoE(Mixture of Experts,混合专家):模型内部有多组"专家"子网络,每次推理只激活其中一部分。好处是参数量大但计算量可控,坏处是路由(决定激活哪些专家)本身有开销。
推理阶段相关
- Prefill(预填充):把输入上下文一次性"吃进去",建立内部状态。长上下文的首次处理瓶颈在这里,因为要对所有输入 token 做注意力计算。
- Decode(解码/生成):模型逐个 token 生成输出。每生成一个新 token,都要访问历史 KV cache。上下文越长,KV cache 越大,这里越慢。
- FLOP(浮点运算次数):衡量计算量的单位。"FLOP 减少 62.5 倍"意思是计算量降到原来的 1/62.5。
- TPOT(Time Per Output Token,每输出 token 耗时):衡量生成速度的指标,数值越小生成越快。
算法复杂度相关
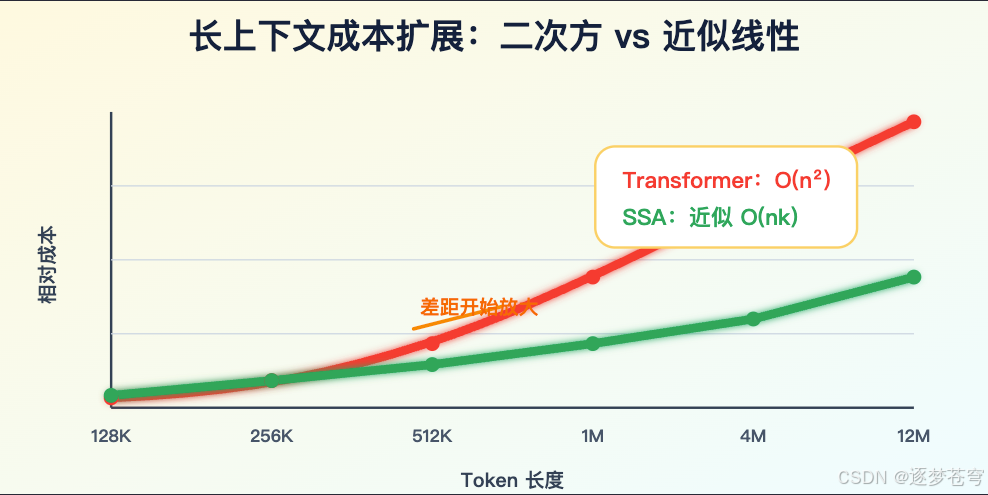
- O(n²)(平方复杂度):计算量随序列长度 n 的平方增长。n 翻倍,计算量涨 4 倍。密集注意力就是这个量级。
- O(nk)(线性×常数):如果每个 token 只看 k 个重要位置(k 远小于 n),计算量就接近线性。这是稀疏注意力的理想目标。
- O(n log n):比平方低、比线性略高的复杂度。排序算法的常见量级,一些高效 selector 的理论目标。
检索/选择机制相关
- Selector(选择器):SSA 的核心组件。模型用来判断"哪些 token 值得关注"的机制。如果 selector 本身太贵,整体加速就会打折扣。
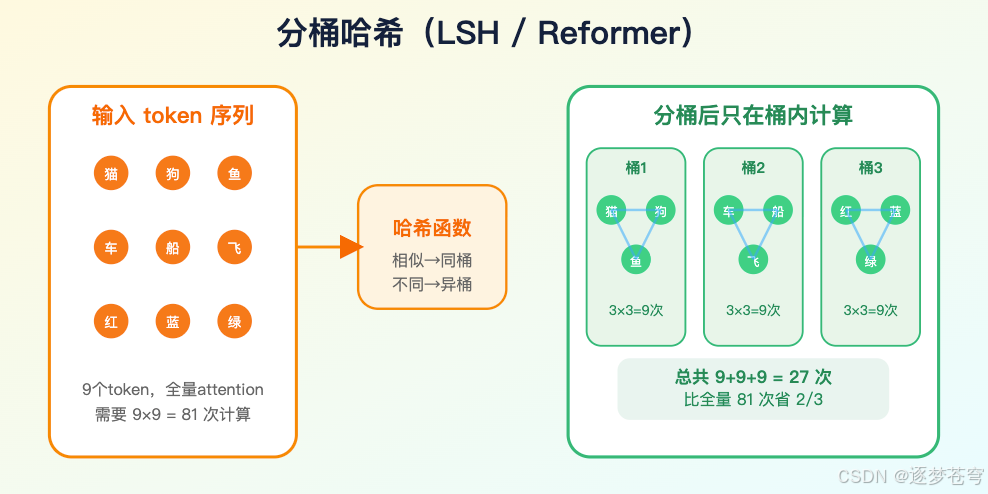
- LSH(Locality-Sensitive Hashing,局部敏感哈希):一种近似检索算法。把相似的 token 用哈希函数分到同一个"桶"里,只在桶内做精细计算。Reformer 用的就是这种思路。
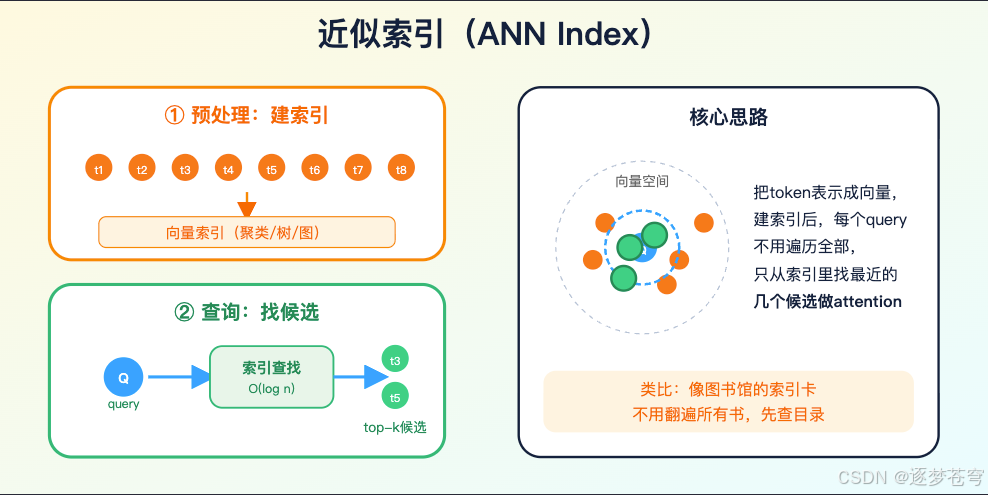
- ANN(Approximate Nearest Neighbor,近似最近邻):向量检索的基础技术。不找精确最近的,而是找"差不多最近的",速度快很多。向量数据库的核心算法。
- Block Proxy(块代理):不逐个 token 判断重要性,而是把 token 分成块,用块的统计特征(比如某条对角线的注意力分数)估计整个块是否重要。XAttention 用的思路。
评估基准相关
- RULER:长上下文评估基准,比简单的"大海捞针"难得多,包含多跳检索、变量追踪、聚合等任务。
- MRCR v2:更接近真实场景的长上下文任务,要求模型找到多个非相邻证据并组合起来。
- SWE-Bench Verified:代码能力评估,让模型自动修复真实 GitHub issue,是 Coding Agent 的标准测试。
- POC(Proof of Concept,概念验证):小规模试用,验证技术可行性,不等于生产部署。
- SLA(Service Level Agreement,服务等级协议):服务提供商承诺的可用性、延迟、故障恢复等指标。生产系统的核心约束。
1.1 一句话结论
截至 2026 年 5 月 7 日,SubQ 还不是一个已经被独立验证的“Transformer 终结者”。
但它盯上的问题是对的:长上下文的真正瓶颈,不是窗口数字不够大,而是密集注意力太贵。
这两年,大家看 AI 新闻已经有点麻了。
今天 100 万上下文,明天 200 万上下文;今天某模型超过 Claude,明天某模型又超过 GPT。看多了会发现,很多“突破”其实还是同一条路上的堆料:更多 GPU、更大数据、更长训练、更复杂的后训练。
SubQ 刺激行业神经的地方不完全一样。
它不是只喊“13 人挑战巨头”,也不是只喊“1200 万 token 上下文”。真正关键的是,Subquadratic 这家公司把矛头对准了 Transformer 最贵的那块:attention。
一个 token 要和上下文里的其他 token 都看一遍。序列越长,计算量不是线性增长,而是平方级增长。上下文长度翻倍,注意力计算理论上接近涨到 4 倍。
这就是为什么长上下文一直像“豪车配置”:看起来很爽,真正跑生产,账单会让人冷静。
1.2 SubQ 到底宣称了什么
Subquadratic 在 2026 年 5 月 5 日公开发布 SubQ 1M-Preview,宣称其核心架构是 SSA,也就是 Subquadratic Sparse/Selective Attention。官方文案里同时出现了 Sparse Attention 和 Selective Attention 两种表述,本质都指向同一件事:
模型不再让每个 token 盲目看全场,而是根据内容动态选择真正值得关注的位置,然后只在这些位置上做精确 attention。
如果这句话成立,意义非常大。
因为这不是把 FlashAttention 再优化 20%,也不是把 KV cache 再压缩一点,而是把注意力计算图改了。
我先把本文判断放前面:
SubQ 的方向值得认真看,公开证据还不够硬。它现在更像一个高风险、高信息量的架构信号,而不是一个可以直接下结论的产业拐点。
2、先把 SubQ 的产品状态看清楚
2.1 API、Code、Search 仍在 private beta
SubQ 这次不是只发了一篇论文式博客,而是同时推出三条产品线:
SubQ API,面向开发者和企业团队的长上下文 API。
SubQ Code,命令行 coding agent,主打把整个代码库放进单一上下文。
SubQ Search,长上下文 research/search 工具,官方说法是用聊天速度提供 Deep Research 能力。
但关键状态只有一个:private beta / early access。
官方页面目前要求申请 SubQ API 和 SubQ Code early access。SubQ Search 在发布文中出现,但公开可复核的使用文档、稳定价格表、rate limit、真实调用日志、失败案例,都还没有摆出来。
这决定了我们不能按成熟云服务去评价它。
更准确的说法是:SubQ 已经公开了产品方向和等待名单,但还没有公开到足以让开发者做严肃采购决策。
2.2 1M-Preview 和 12M research result 不是一回事
这里最容易被传播稿带偏。
官方明确发布的是 SubQ 1M-Preview。12M token 更准确应理解为 research result 或官方宣称的研究能力,不是普通开发者已经稳定可调用、可计费、可复现的生产能力。
这点很重要。
如果你是开发者,现在最该问的不是“它是不是 12M”,而是:
我能不能拿到 API?
价格表在哪里?
超长输入怎么计费?
百万 token 下首 token 延迟是多少?
长上下文 decode 吞吐是多少?
tool use、structured output、streaming、重试、上下文缓存、企业数据隔离怎么做?
这些问题没有回答之前,它不能算一款可以直接迁移生产的基础模型服务。
2.3 它的价值先放在 POC,而不是替换
SubQ 现在最适合被放进高优先级 POC。
不是因为它已经证明自己全面强于 OpenAI、Anthropic、Google,也不是因为“稀疏注意力”四个字天然先进。
而是因为它对应用层有真实冲击:如果一个模型能以可接受成本读完整个代码库、合同集合、长期 agent 状态、数据库导出和研究资料,RAG、chunking、摘要压缩、多 agent 编排的设计重心都会变化。
注意,是“设计重心变化”,不是“RAG 消失”。
权限控制、数据更新、结构化检索、可解释引用、审计留痕,这些仍然需要外部系统。长上下文再便宜,也不能替代数据工程。
3、SSA 的核心,不是快,而是少算
3.1 从 dense attention 到 selective attention
很多人看到“52 倍加速”“计算量暴减千倍”,第一反应是:是不是又搞了一个更强的 CUDA kernel?
不是。
至少从公开描述看,SSA 的核心思想不是“把密集注意力算得更快”,而是“干脆别算那么多没用的注意力”。
FlashAttention-2/3、Ring Attention 这类技术,本质上是在 dense attention 框架内,把内存访问、分块计算、并行通信做得更好。它们很强,也非常工程化,但没有改变一个事实:理论上仍然是 all-pairs,每个 query 还是要面对大量 key。
SSA 想做的是另一件事。
假设一个 query 只需要关注 k 个重要 token,而不是 n 个 token,那么主体 attention 就可以从 O(n^2) 变成 O(nk)。如果 k 能稳定控制在一个小范围,长上下文成本就会接近线性。
说白了,模型不应该每次回答问题都把整本书逐页重读。
真正聪明的模型,应该知道问题问的是哪一章,先翻到相关位置,再精读。
3.2 selector 才是 SSA 的胜负手
SSA 的生死问题只有一个:selector 怎么做?
也就是,模型如何在不先做全量 query-key 比较的情况下,知道自己该关注哪些 token。
如果 selector 本身还是要对所有 query 和所有 key 做一轮复杂打分,主体 attention 虽然变稀疏了,总体复杂度仍然绕不开 O(n^2) 的影子。这个问题不解决,“线性扩展”就容易变成发布页上的漂亮曲线。
3.2.1 selector 必须先省下来
一个真正有价值的 selector 至少要满足四个条件:
第一,selection 本身必须是 sub-quadratic,最好接近 O(n log n) 或 O(nk),否则只是把成本从 attention 矩阵挪到 routing 矩阵。
第二,selection 必须 content-dependent。固定窗口、固定 stride、dilated pattern 可以省算力,但如果关键信息落在模式之外,模型就看不到。
3.2.2 selector 还要选得准
第三,selection 不能只适合 needle-in-a-haystack。真实任务往往需要多跳证据、变量追踪、跨文件引用、远程约束组合。
第四,selection 必须能训练稳定。稀疏路由如果不可微、噪声大、负载不均,最后会把问题转移到训练工程和后训练上。
3.3 可能的 selector 路线和公开空白
从研究经验看,selector 大概有几类可选路线。
一种是分桶哈希(hashing/LSH),典型参照是 Reformer(一种用哈希加速的注意力变体)。它用局部敏感哈希把相似 token 分到同一桶里,再在桶内做 attention。好处是近似检索清晰,坏处是哈希质量和桶划分会决定召回上限。
一种是近似索引(clustering 或 ANN index),把 token 表示放进近似索引里,对每个 query 找候选 key。它看起来像把向量检索嵌进模型内部,但难点在于训练时如何保持可微、如何跨层更新、如何控制索引构建成本。
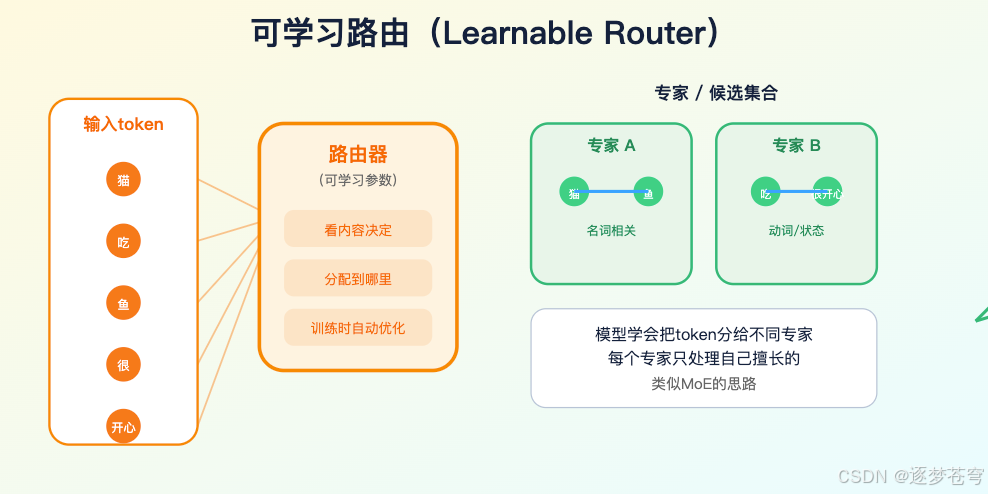
一种是可学习路由(learnable router),让模型学习给 token 或 block 分配专家、路由或候选集合。MoE 和稀疏 attention 都会遇到类似问题:路由越聪明,训练越复杂;路由越便宜,召回越可能丢。
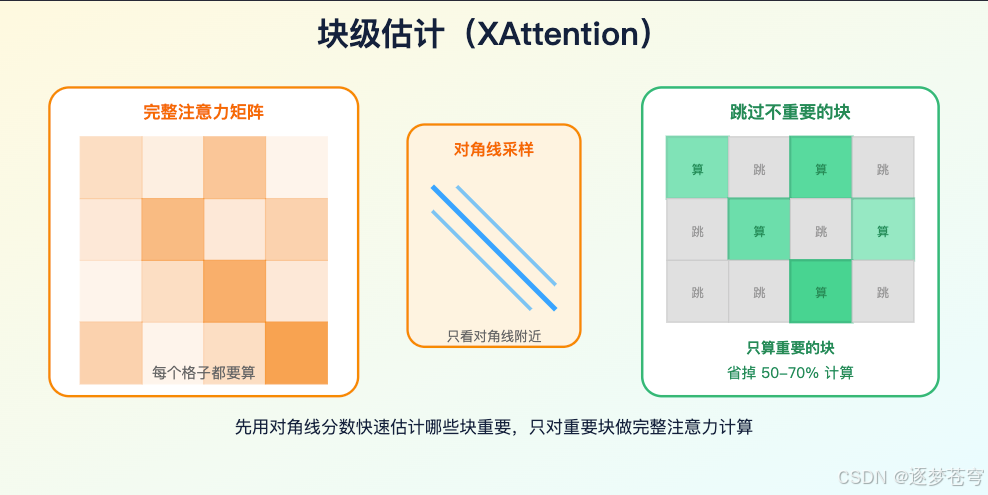
还有一种是块级估计(block-level proxy),比如 XAttention(一种注意力加速方法)用注意力矩阵的对角线分数估计整块重要性,减少非关键 block 的计算。这类方法更像存量 Transformer 推理加速插件,优点是工程落地相对直接,缺点是它通常是在已有 attention 结构上做稀疏化,不等于从第一性原理重写 attention。
SubQ 目前没有公开到这个粒度。
官方技术页讲的是"根据内容动态选择"(content-dependent selection)、“线性扩展”(linear scaling)、“任意位置检索”(arbitrary-position retrieval),但没有公开 selector 具体是上述哪种路线,还是完全不同的新机制。
所以我对 SSA 的第一层判断很明确:
方向对,问题真,潜在收益极大;但关键算法还没摆上桌。
如果 selector 做得足够优雅,这件事是架构级突破。
如果 selector 只是一个包装漂亮的近似检索工程,它仍然有价值,但很难支撑“Transformer 王座崩塌”这种叙事。
3.4 它和 NSA、XAttention、HyperAttention 的差异
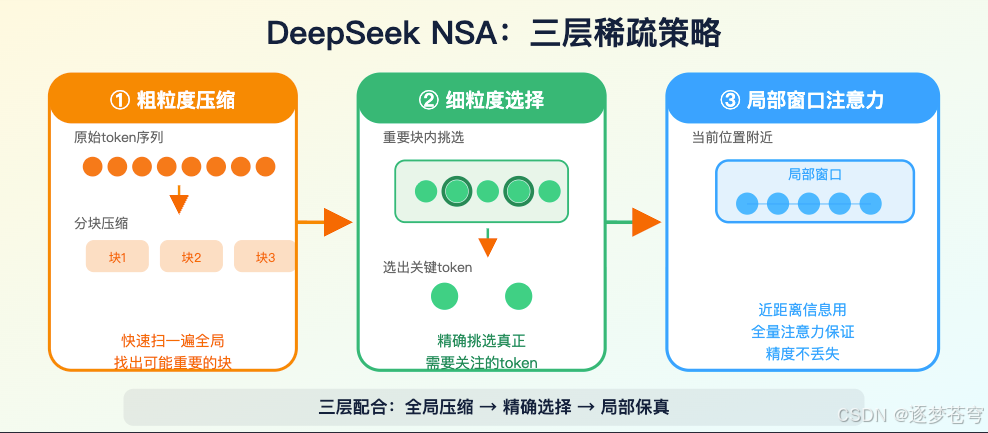
DeepSeek 的 NSA 更强调"原生可训练"(natively trainable)和"硬件友好"(hardware-aligned)。公开论文里讲的是三层策略:先把 token 分块压缩(粗粒度压缩),再从压缩结果里挑重要的(细粒度选择),最后保留局部窗口做精确注意力。它的价值在于训练阶段就适配稀疏,而不是推理时临时砍掉部分计算。
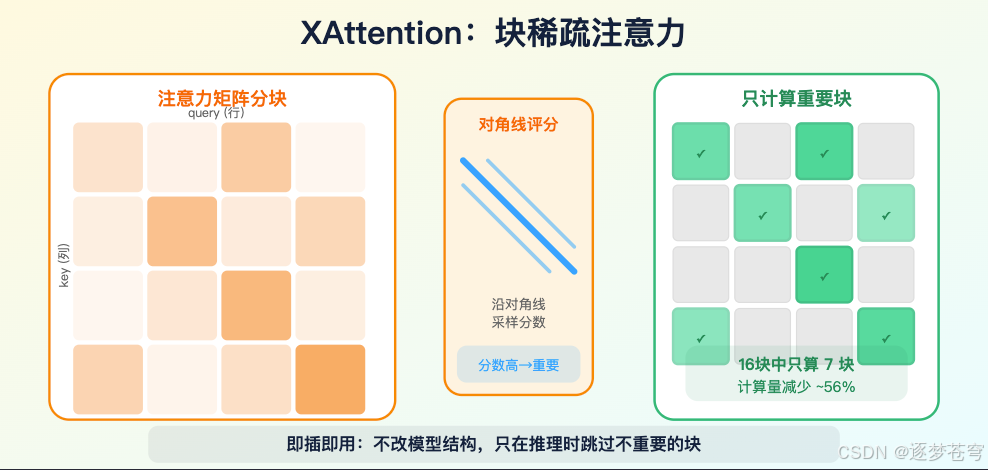
XAttention 更偏"即插即用"(plug-and-play)的推理加速。它用块稀疏注意力和对角线分数来判断哪些块重要,在 RULER、LongBench、VideoMME 等长上下文任务上报告接近全量注意力的质量,同时最高实现 13.5 倍加速。
HyperAttention、Reformer 这类方法更早就在尝试用哈希分桶、随机采样、低秩近似、分块计算等方式绕开全量注意力,但过去的问题一直是:理论上复杂度降下来了,实际用在大模型上,生成质量、底层计算效率、训练稳定性、复杂任务的信息召回不一定站得住。
SubQ 的叙事更激进:它说自己不是固定模式的稀疏,不是把历史信息压缩进循环状态(Mamba/RWKV 那条路),也不是混合架构里保留部分全量注意力,而是根据内容动态选择 + 精确检索。
这正是它值得看的原因,也是它必须拿出技术报告的原因。
4、百万 token 真正难在哪里
4.1 上下文窗口只是门票
过去我们聊长上下文,喜欢看一个数字:支持多少 token。
128K、256K、1M、10M、12M。
但做过 RAG、代码助手、企业知识库、Agent 记忆系统的人都知道,窗口长度只是门票,不是胜负手。
真正难的是四件事:
第一,能不能稳定找回远处信息。
第二,长输入下首 token 延迟会不会崩。
第三,decode 阶段吞吐和 KV cache 能不能扛住。
第四,用户愿不愿意为这次调用付钱。
一个模型能“接收”百万 token,不等于它能“使用”百万 token。能过单 needle 测试,也不等于能做跨文件修改、合同条款归因、多跳证据组合。
4.2 prefill 快,不等于整次调用都快
长上下文调用通常分成两段看。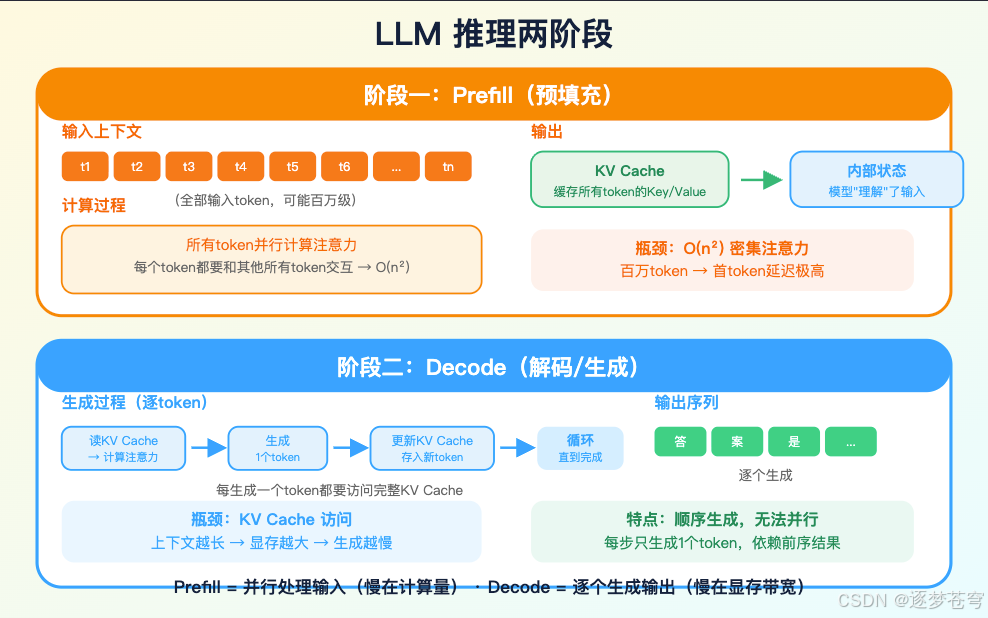
prefill(预填充)是把输入上下文一次性"吃进去",建立内部状态的过程。百万 token 的痛点首先在这里。dense attention 的 O(n^2) 成本会把首 token 延迟推高,让交互式产品变成离线批处理。
decode 是模型逐 token 生成输出。这里的痛点不完全一样:每生成一个新 token,都要访问历史 KV cache。上下文越长,KV cache 越大,显存峰值、显存带宽、batching 和并发都会变成瓶颈。
SubQ 官方最硬的速度数字,是在 B200 上相对 FlashAttention-2 的 prefill speedup:128K 约 7.2 倍,256K 约 13.2 倍,512K 约 23 倍,1M 约 52.2 倍。
这个数字很有信息量,但要注意边界。
它不是“端到端 API 快 52 倍”,也不是“所有 decode 场景快 52 倍”,更不是“真实 agent 工作流快 52 倍”。它首先是长输入 processing/prefill 维度的架构级对比。
这已经很重要,但不能偷换概念。
4.3 KV cache 是另一张账单
DeepSeek MLA 为什么重要?
因为它主要打的是 decode 阶段的 KV cache。DeepSeek-V2 论文里,MLA 通过把 key/value cache 压缩到 latent 表示,报告 KV cache 减少 93.3%,最大生成吞吐提升 5.76 倍。DeepSeek-V3 延续了 MLA + DeepSeekMoE 的路线。
Kimi Linear 为什么也重要?
因为它不是只压缩 KV cache,而是用 Kimi Delta Attention 这类线性 attention 模块承担多数层,再保留少数 MLA 层做全局检索。Moonshot 公开的 Kimi Linear 48B-A3B 模型卡写得很具体:1M context,KV cache 最多减少 75%,1M 下 decode/TPOT 相比 MLA 最高约 6 倍到 6.3 倍,3:1 KDA-to-global MLA 混合比例。
SSA 和它们的切入点不同。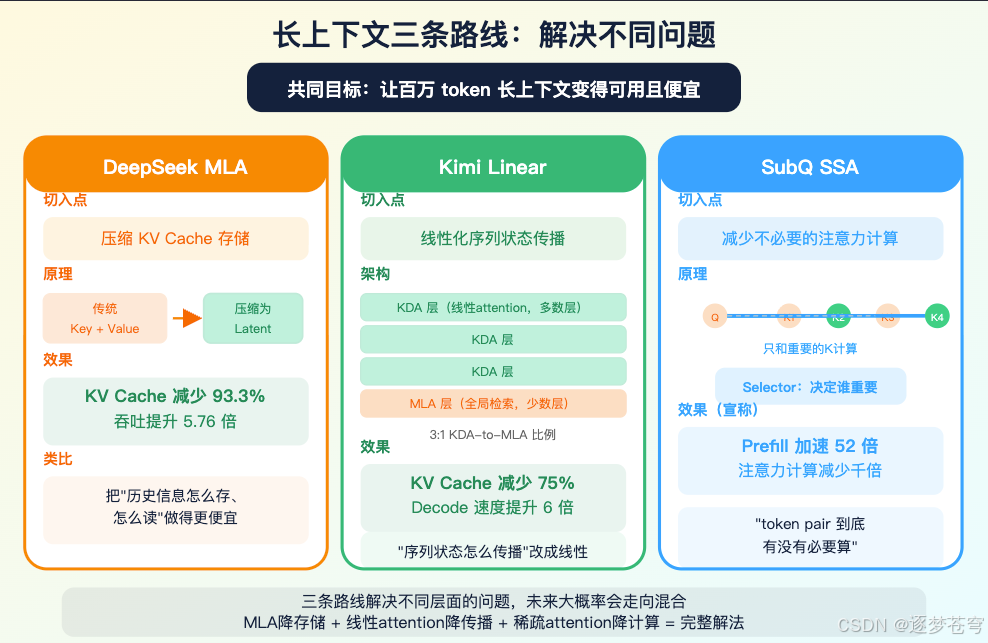
MLA 更像把”历史信息怎么存、怎么读”做得更便宜。
Kimi Linear/Mamba/RWKV 更像把”序列状态怎么传播”改成线性或近线性。
SSA 则试图回答”这些 token pair 到底有没有必要算”。
所以,SubQ 真要证明自己,不能只证明 prefill 加速。它还要回答 decode 期间 selector 如何工作、KV cache 是否仍然保存全量 token、百万上下文下输出 5K/20K token 时吞吐如何、并发 batch 下显存怎么涨。
5、benchmark 的信息量和水分
5.1 RULER 128K 很亮眼,但不够
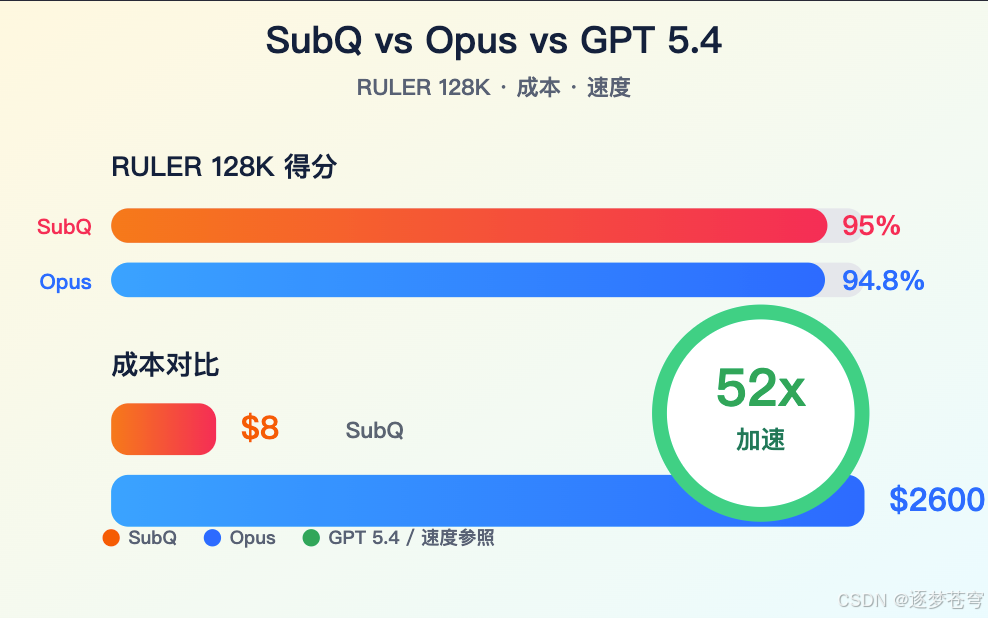
官方给出的 RULER 128K 结果是 SubQ 1M-Preview 95.0%,Claude Opus 4.6 94.8%。这说明 SubQ 在长上下文检索和推理类任务上确实打出了很强的公开成绩。
但 RULER 不是现实世界。
RULER 比简单 needle 测试强很多,包含多跳检索、聚合、变量追踪、选择性过滤等任务。它能筛掉不少“只会找针”的模型。
但真实业务更脏:文档结构不一致,代码库有历史债,合同条款互相引用,数据库字段命名混乱,用户问题还经常带歧义。
所以 RULER 可以证明“值得测”,不能证明“可以上生产”。
5.2 8 美元 vs 2600 美元要拆开看
媒体报道和 SubQ 对外沟通里出现过一个很抓人的成本对比:RULER 128K 上 SubQ 约 8 美元,Claude Opus 约 2600 美元,差距约 300 倍。
5.2.1 这个数字为什么击中痛点
这个数字击中了行业痛点。
今天很多 Agent 产品为什么做不深?不是因为大家不会写 tool call,也不是因为不会做 workflow,而是上下文和记忆太贵。
Coding Agent 如果每次都读完整个仓库、提交历史、测试日志、issue、设计文档,成本会迅速失控。企业研究 Agent 如果每次都读几百份合同、几十万行内部资料、跨部门知识库,也会遇到同样问题。
5.2.2 为什么还不能当采购 ROI
但这个成本对比目前必须降级成“官方/媒体口径”。
原因很简单:SubQ 还没有公开正式 API pricing,也没有公开可复现实验脚本。不同模型的输入价格、缓存价格、批处理策略、上下文缓存命中率、硬件成本、运行次数、失败重试、输出长度都会改变最终账单。
如果没有这些细节,8 美元 vs 2600 美元是一个很强的方向性信号,不是采购级 ROI。
5.3 MRCR v2 暴露了 production 与 research 的距离
MRCR v2 更接近真实长上下文任务,因为它要求模型在长上下文中找到多个非相邻证据,并把它们组合起来。
SubQ 官方技术页给出的 MRCR v2 表格里,SubQ production verified score 是 65.9。它低于 Opus 4.6 的 78.3,也低于官方表格里的 GPT 5.5 74.0,但高于 GPT 5.4 36.6、Gemini 3.1 Pro 26.3 和 Opus 4.7 32.2。
更关键的是,官方同时提到 research result 是 83。
这中间有明显落差。
这个落差反而让结果更真实:SubQ 不是全面碾压,它是在自己擅长的长上下文方向展现了潜力,但 production 模型还没有把 research 能力完整带出来。
对技术判断来说,这比一句“千倍降本”更有价值。
5.4 SWE-Bench 不能只看分数
SubQ 官方给出的 SWE-Bench Verified 是 81.8,对比 Opus 4.6 的 80.8、DeepSeek 4.0 Pro 的 80.0。这个数字很漂亮,因为 coding agent 是 SubQ 最想打的场景。
但 SWE-Bench 这种任务,分数不只反映模型,也反映 harness、工具调用、文件定位策略、patch 生成、测试重跑、失败恢复。
如果 SubQ Code 真能把整个 repo 放进上下文,理论上它能减少“读文件策略”的复杂度。
但这也会带来新问题:模型读得更多,是否真的改得更准?它会不会因为上下文太多而抓错约束?它生成 patch 的速度和成本是否仍然可接受?它在 monorepo、大型前端、微服务、多语言仓库里的表现是否稳定?
现在还没有足够公开实测回答这些问题。
5.5 最怕偏科
长上下文模型最怕只赢一类任务。
prefill 很快,但 decode 很慢。
单 needle 很好,但多跳推理掉得厉害。
检索题很好,但真实代码库幻觉增加。
成本曲线好看,但首 token 延迟让用户等不住。
RULER 打平旗舰模型,但数学、常识、多语言、安全、工具使用没有公开。
SubQ 现在最需要补的,不是更炸的营销数字,而是更完整的 eval matrix。
6、长上下文路线并不只有 SubQ
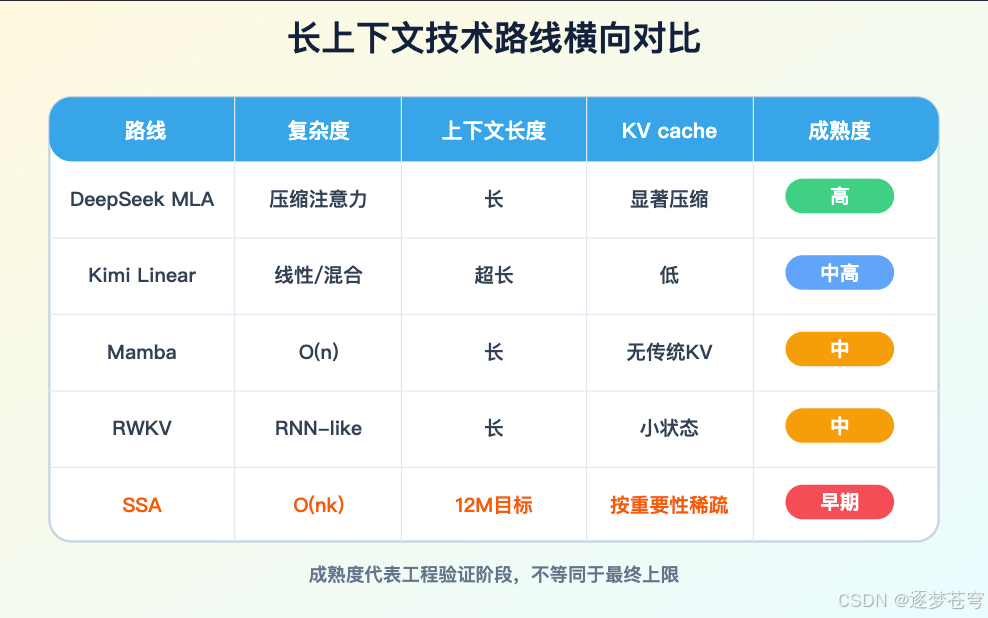
6.1 FlashAttention 和 Ring Attention:让 dense attention 更能跑
FlashAttention-2/3 的价值不用低估。
它们没有改变 all-pairs attention 的理论复杂度,但通过 IO-aware、tiling、kernel 优化,把 dense attention 的实际可用性大幅往前推。
Ring Attention 的重点是把超长序列分布到多设备上,通过环形通信和 blockwise attention 扩展上下文训练与推理。它同样没有从根上消灭二次复杂度,而是在系统层让 dense attention 更能承受。
这些技术是生产系统里的硬地基。
SSA 如果成立,也不会替代所有 kernel 优化。稀疏 attention 仍然需要极强的 kernel、并行和内存工程,否则理论复杂度赢了,墙钟时间也可能输。
6.2 DeepSeek MLA:先解决 KV cache
DeepSeek V2/V3 的 MLA 是当前最值得尊重的工程路线之一。
它不宣称消灭 attention,而是压缩 key/value cache,把 decode 阶段的显存和带宽压力打下来。对在线 serving 来说,这非常现实。
缺点也清楚:MLA 对 prefill 的二次复杂度不是根治。超长输入第一次吃进去时,dense attention 的成本仍然存在,只是后续 decode 更便宜。
所以 MLA 和 SSA 不是同一个答案。
MLA 更像“让 Transformer 长得更省内存”。
SSA 更像“让 Transformer 少做无意义 attention”。
6.3 Kimi K2、Kimi Linear:不要混成一个概念
Kimi 这条线要拆开看。
Kimi K2/K2.5/K2.6 是 Moonshot 面向 agent、coding、工具调用的 MoE 模型线。Kimi API 文档显示,K2 系列有 128K 到 256K context,支持 ToolCalls、JSON Mode、互联网搜索、自动上下文缓存,并且截至 2026 年 5 月 7 日,文档已经提示 Kimi K2 系列将在 2026 年 5 月 25 日停止维护,建议迁移到 Kimi K2.6。
Kimi Linear 是另一条架构研究线。它公开了 KDA kernel、vLLM 实现和模型权重,48B total / 3B activated,1M context,混合 KDA 与 MLA。它的重点是百万 token decode 吞吐和 KV cache,而不是像 SubQ 一样宣称 12M research context。
所以,如果有人把“SubQ 很可能基于 Kimi”直接等同于“SubQ 就是 Kimi Linear 换皮”,这是过度推断。
目前更稳妥的表述是:SubQ CTO 据报道承认使用开源模型权重作为起点,但外部没有确认具体底座、SSA 改动范围、训练配方和 benchmark 贡献拆分。
6.4 Mamba、RWKV、Jamba:线性状态不是免费午餐
Mamba 的核心是 selective state space model。它通过输入相关的状态更新,让模型选择性保留或遗忘信息,并获得线性序列复杂度。Mamba-2 又用 state space duality 把 SSM 和 attention 的关系讲得更清楚,核心层相对 Mamba 报告 2 到 8 倍加速。
RWKV 走 RNN-Transformer 融合路线,训练期可并行,推理期像 RNN 一样维护常数状态。长输出、流式、边缘部署很有吸引力。
Jamba-1.5 则是更工程化的 hybrid:Transformer + Mamba + MoE,公开论文给出 256K effective context,并通过 ExpertsInt8 支持 94B active 模型在 8 张 80GB GPU 上处理 256K 上下文。
这些路线共同说明一件事:
纯 dense attention 的默认地位正在被围攻。
但它们也都有代价。固定状态会压缩信息,压缩就会有遗忘;线性 attention 的状态容量有限,精确复制、任意位置检索、复杂 in-context learning 不一定稳;hybrid 架构保留 dense attention 后,又会把一部分二次成本带回来。
公开主线里,Mamba-2 和 Jamba-1.5 是更清楚的参照。至于“Mamba-3”这类后续说法,公开可核验资料还不如 Mamba/Mamba-2/Jamba 系统,不能写成已经成熟交付的长上下文路线。
6.5 Llama 4 已经把“超长窗口”推到产品页
Llama 4 也必须放进这张图里。
Meta 的 Llama 4 Scout 模型卡写着 10M context,Maverick 写着 1M context。这说明“超长窗口”已经不再只是闭源 API 的宣传词,开权重生态也在把窗口数字推上去。
但 Llama 4 的问题和其他模型一样:标称上下文不是功能上下文。
Scout 写 10M,不等于每个真实任务都能稳定利用 10M。SubQ 写 12M research result,也不等于每个开发者都已经能调用 12M。
下一阶段竞争不会只看谁的窗口最大,而会看谁在同等质量下把 prefill、decode、显存、价格、并发和失败率一起压下来。
7、13 人公司让巨头紧张,靠的不是故事,而是算力账本
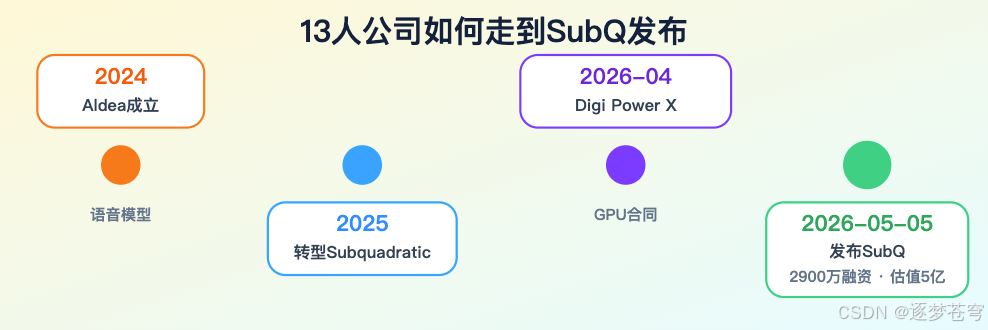
7.1 团队故事适合传播,但要分清已确认与据报道
Subquadratic 的公司故事很适合传播。
迈阿密,13 人,11 名 PhD researchers/research engineers,2026 年 5 月 5 日走出隐身模式,种子轮 2900 万美元。官方介绍称投资方包括 Javier Villamizar、Justin Mateen、Grant Gittlin、Jaclyn Rice Nelson,以及 Anthropic、OpenAI、Stripe、Brex 的早期投资人。
CEO Justin Dangel 是连续创业者,公开履历更偏商业和组织搭建。
CTO Alexander Whedon 公开履历包括 Meta software engineer 和 TribeAI Head of Generative AI,官方称其领导过 40 多个企业 AI 实施项目。
媒体报道还提到 Subquadratic 前身是 Aldea,早期做 speech/voice models,后来转向长上下文 attention 架构。
估值约 5 亿美元来自媒体报道,不是公司官网直接披露。这个数字可以写,但要写成“据报道”。
7.2 Digi Power X 合同是现实信号,不是技术证明
比融资故事更值得看的是算力合同。
Digi Power X 在 2026 年 4 月 20 日披露,已与 SubQ AI 签署 bare metal GPU rental agreement。合同期限 24 个月,预计总合同价值约 1960 万美元,约 295 万美元预付款,约定 2026 年 5 月 15 日生效,提供最新一代 NVIDIA Blackwell GPU 专属访问。
注意日期。
截至 2026 年 5 月 7 日,这是一份已经披露、即将生效的合同安排,不能写成“已经交付满负载集群并完成长期稳定运行”。
但它仍然很重要。
至少说明 SubQ 不是只拿一个 landing page 在讲故事。它在投入算力,而且投入不小。
当然,有算力不等于有突破。
大模型行业里,算力合同只能证明公司在准备训练和验证资源,不能证明 selector 复杂度真的成立,不能证明 12M 推理质量真的稳定,也不能证明 API 经济账已经跑通。
7.3 最值得盯的是 SubQ Code
三条产品线里,SubQ Code 最有想象力。
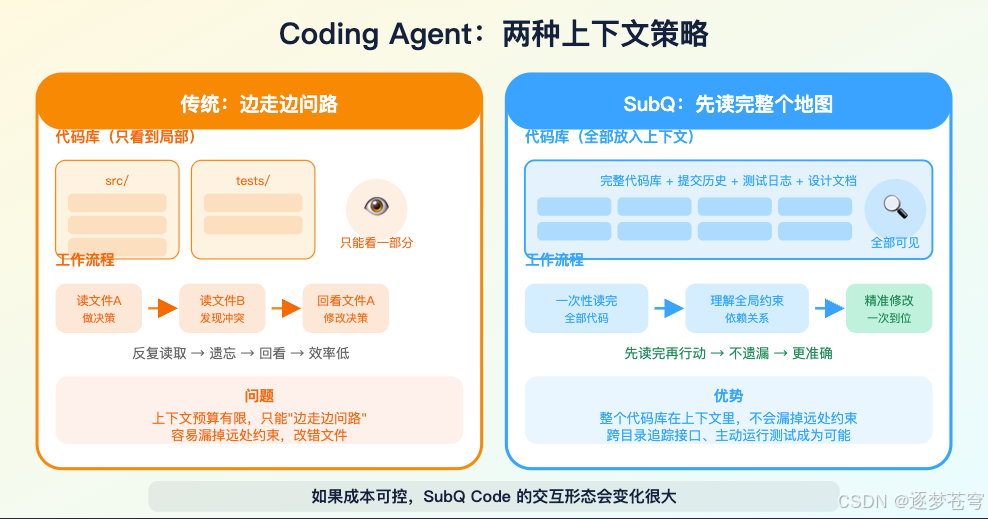
现在 Coding Agent 的一个核心瓶颈,就是“看不全”。Claude Code、Codex、Cursor、Devin 这类工具,本质上都在做上下文预算管理:什么时候读文件,读多少,怎么压缩,怎么避免遗忘,怎么让模型别在局部信息里做错决策。
如果一个模型真能把整个代码库、提交历史、测试日志和设计文档一次性放进去,而且成本可控,Coding Agent 的交互形态会变化很大。
它不再只是边走边问路,而是先把地图读完再行动。
但这句话要靠真实 repo 说话。
SubQ Code 需要公开大仓库实测:百万行代码、多语言 monorepo、历史 PR 约束、失败测试定位、跨模块 API 修改、迁移任务、性能回归定位。最好还能给出完整 trace,而不是只给最终 benchmark 分数。
8、最大疑点:没有论文、没有权重、没有复现
8.1 社区为什么分裂
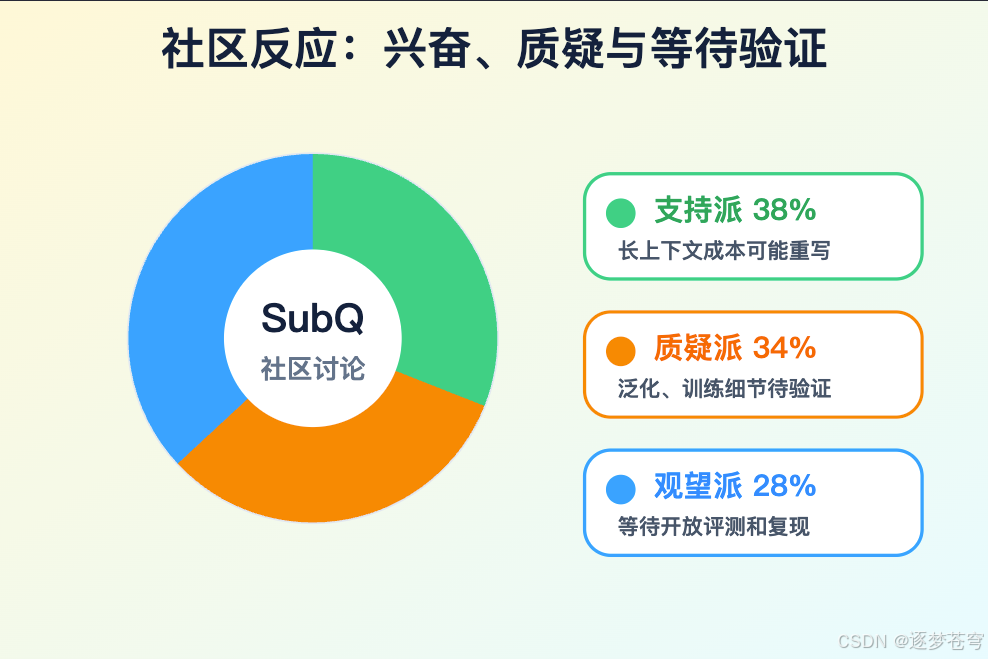
社区分裂很正常。
SubQ 的 claim 太大,而证据还不够。
支持者说,这是 Transformer 以来最大的突破之一。怀疑者说,这可能是 AI 版 Theranos。
两边都有情绪化成分。
把它直接捧成“OpenAI 和 Anthropic 估值归零”,太夸张。巨头的护城河不是某一个 attention trick,而是数据、后训练、产品生态、推理基础设施、分发渠道和企业信任。
把它直接打成骗局,也太早。稀疏注意力本来就是合理研究方向,长上下文降成本也是行业真实需求。没有公开论文,不等于一定是假的;只是不能要求大家按“已验证突破”来相信。
8.2 最硬的三类质疑
8.2.1 证据链还不够完整
第一,无完整技术报告、无完整 model card、无开放权重、无公开复现实验。
官方 SSA 技术页写着 comprehensive model card coming soon。VentureBeat 也提到 technical report 仍是 coming soon。模型权重没有开放,API 仍是 early access,外部研究者无法判断 SSA 到底是不是全新机制,也无法确认 benchmark 设置是否公平。
8.2.2 底座来源需要讲清楚
第二,模型起点问题。
OpenAI 前研究员 Will Depue 质疑 SubQ 很可能是基于 Kimi 或 DeepSeek 的稀疏注意力微调。VentureBeat 报道称,SubQ CTO Alexander Whedon 随后在 X 上承认公司使用开源模型权重作为起点。
这件事本身不丢人。
今天很多模型研究都会从开源权重起步,这能节省大量预训练成本。但如果宣传口径给人一种“完全从零打造新基础模型”的感觉,就需要说清楚:哪些能力来自底座,哪些能力来自 SSA,哪些 benchmark 提升来自后训练,哪些来自 harness。
目前能确认的是“使用开源权重作为起点”这个层级。具体是不是 Kimi、DeepSeek,外部没有公开证据可以定论。
8.2.3 数字口径需要对齐
第三,数字口径需要对齐。
52.2 倍 prefill speedup、1M 62.5 倍 attention FLOP reduction、12M almost 1000x attention compute reduction、RULER 成本 8 美元,这些数字都很炸裂。
但它们分别对应什么硬件、batch size、精度、上下文长度、prefill 还是 decode、是否包含 selector 成本、是否包含端到端 API 延迟、是否包含失败重试和输出长度?
不说清楚,就很难比较。
还有一个细节值得注意:SubQ 官方不同页面对 compute 的表述并不完全严谨。一处写“52x faster than FlashAttention”并提到“63% less compute”,技术页又写 1M 下 attention FLOP reduction 是 62.5x。百分比减少和倍数减少不是一个量纲。
这不一定说明 claim 错,但说明传播文案还需要更精确。
8.3 独立验证应该怎么做
真正能让争议降温的不是更多截图,而是可复现验证。
至少需要四类东西。
第一,技术报告。selector 的复杂度、训练方式、稀疏模式、召回机制、误差边界、kernel 和分布式实现都要讲清楚。
第二,model card。训练数据范围、上下文长度、功能上下文、已知失败场景、安全边界、价格和 serving 限制都要列出来。
第三,独立 benchmark。RULER、MRCR v2、LongBench、SWE-Bench Verified、真实 repo 任务、法律合同、多跳金融报告、长表格推理都要跑,而且要多次运行给置信区间。
第四,开发者真实账单。128K、512K、1M,甚至 12M,如果可用,要给出输入 token、输出 token、缓存命中、首 token 延迟、总耗时、失败率、重试成本。
截至 2026 年 5 月 7 日,我没有看到公开独立复现能把这些补齐。所谓 third-party verified benchmarks 目前更多是官方和媒体口径,不等于开源 harness、公开 leaderboard、社区可重复实验。
9、我的判断与给开发者的建议
9.1 Transformer 不会突然倒下
如果只问一句:SubQ 会不会终结 Transformer?
我的答案很明确:不会以今天这种方式突然终结。
大模型架构的替换不是社交媒体热搜决定的。真正能改变产业格局的技术,必须经历论文公开、独立复现、工程部署、极端场景验证、生态接入和成本模型验证。
SubQ 现在还差几步。
但如果换一个问题:密集注意力作为长上下文默认方案,会不会继续稳坐十年?
我的答案也很明确:不会。
原因很简单,经济账不允许。
未来的 AI 应用会越来越“上下文饥渴”。Coding Agent 要读仓库,研究 Agent 要读资料,企业 Agent 要读权限内的历史系统,具身智能要维护长期状态,工业 AI 要理解设备日志、工艺参数和异常记录。
这些任务都不是 8K、32K、128K 能舒服解决的。
但也不可能永远用平方复杂度硬砸。
9.2 长上下文会走向混合系统
未来长上下文模型大概率会走向混合路线: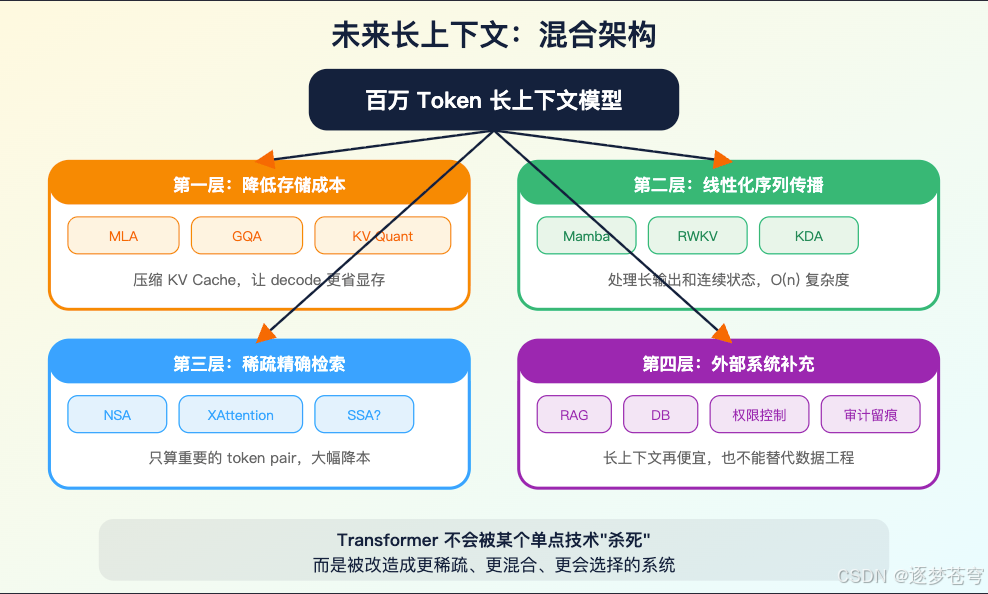
一部分用 MLA、GQA、KV quantization、context cache 降低 decode 成本。
一部分用 Kimi Linear、Mamba、RWKV 这类线性或状态空间路线处理长输出和连续状态。
一部分用 NSA、XAttention、SSA 这类稀疏/选择性 attention 做精确检索和长上下文降本。
一部分继续交给外部 RAG、工具系统、数据库、权限控制和可解释引用。
也就是说,Transformer 不会被某个单点技术“杀死”,而是会被改造成一个更稀疏、更混合、更会选择的系统。
SubQ 的价值就在这里。
它不一定是最后赢家,但它把行业讨论从“窗口长度军备竞赛”拉回到了正确问题:
模型到底有没有必要看所有 token?
如果没有,谁能证明自己可以少看、看准、还不掉质量?
这个问题一旦被认真追问,很多产品路线都会变化。
9.3 开发者现在要不要接 SubQ API
我的建议很直接:要申请 POC,不要直接替换生产。
适合优先测试的场景有三类。
第一,大代码库任务。把完整 repo、README、架构文档、历史 issue、失败测试、目标需求放进去,测它是否能定位真正该改的文件,而不是只生成局部合理 patch。
第二,多文档证据任务。用合同、研报、会议纪要、政策文件做多跳问题,要求答案给出证据位置和引用,不允许只给总结。
第三,长运行 agent 任务。把连续几小时的操作日志、计划变更、工具结果、失败重试放进上下文,测它是否能保持一致约束。
不适合马上迁移的场景也很清楚:对稳定 SLA、数据合规、价格可预测、失败恢复要求很高的生产核心链路。
SubQ 现在还缺公开价格、公开服务等级、完整 model card 和足够多独立验证。
9.4 A/B 测试应该怎么设计
不要只跑“把一本书塞进去问一个事实”。
真正有价值的 A/B,至少要拆四张表。
第一张表测质量:答案正确率、证据召回率、多跳完整率、引用准确率、代码 patch 通过率、幻觉率。
第二张表测速度:首 token 延迟、总耗时、prefill 时间、decode tokens/s、长输出吞吐。
第三张表测成本:输入 token、输出 token、缓存命中、失败重试、单任务总账单、同等质量下成本。
第四张表测鲁棒性:128K、256K、512K、1M 不同长度下是否退化;相关证据放在开头、中间、末尾是否影响结果;干扰信息增加后是否还能召回。
对 Coding Agent,额外加三项:
是否能跨目录追踪接口约束。
是否能在修改后主动运行相关测试。
是否能解释为什么没有改某些看似相关文件。
如果 SubQ 在这些任务上能用更低成本打平或超过现有模型,它就值得继续投入。
如果它只在 RULER 或单 needle 上漂亮,真实 repo 和多证据任务里不稳,那就先观望。
9.5 最后的判断
SubQ 不是已经登基的新王,但它确实敲响了密集注意力的警钟。
如果技术报告公开后,selector 复杂度、端到端延迟、独立 benchmark、真实 API 账单都能站住,那这会是 2026 年最值得认真复盘的架构事件之一。
如果站不住,它也会留下一个重要提醒:
AI 行业已经不再满足于“更大模型”,大家开始逼问“更便宜的智能”到底怎么来。
而这,才是真正的变化。
🚀 持续探索 AI 与前沿技术 分享大模型应用、软件开发实战与行业洞察。 🌟 探索技术边界,让开发更有效率 |
 |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)