CLIP深度解析:从原理到落地,解锁多模态AI的核心密码 (1)
CLIP 深度解析:从原理到落地,解锁多模态 AI 的核心密码
一、引言:为什么 CLIP 能颠覆计算机视觉?
在 2021 年 OpenAI 发布 CLIP 之前,计算机视觉领域长期面临两大瓶颈:
-
监督信号局限:模型依赖人工标注的固定类别数据集(如 ImageNet 的 1000 类),泛化到新场景需重新标注训练;
-
跨模态割裂:视觉与语言模型各自为战,无法直接理解 “图文语义对应”(如 “红色的苹果” 与红色苹果图像的关联)。
CLIP(Contrastive Language-Image Pre-training)的核心突破的是:用自然语言作为监督信号,训练通用视觉模型。它证明了 —— 无需人工标注,仅通过互联网海量图文对,就能让模型学习到 “视觉概念” 与 “语言描述” 的对齐关系,从而实现零样本迁移到任意视觉任务。
论文关键数据佐证其革命性:
-
零样本迁移 ImageNet,Top-1 准确率 76.2%,追平原版 ResNet-50(76.1%),却未使用 1.28 万标注样本;
-
30 + 下游任务中,21 项超越传统有监督基线,覆盖 OCR、动作识别、地理定位等多场景;
-
分布鲁棒性显著提升:在 ImageNet-R(渲染图)、ObjectNet(真实场景物体)等数据集上,准确率较传统模型提升 35%-75%。
二、核心原理:对比学习如何实现图文对齐?
2.1 核心目标:学习 “图文匹配” 的统一表征
CLIP 的训练目标极其简洁:让匹配的(图像,文本)对在向量空间中距离更近,不匹配的更远。
-
摒弃 “预测具体类别标签” 的传统思路,转而学习 “语义相关性”;
-
这种目标天然适合跨模态:图像和文本无需统一格式,只需学习 “是否相关” 的二元关系。
2.2 模型架构:双编码器的极简设计(附架构图解析)
CLIP 的架构堪称 “极简主义的胜利”—— 仅由图像编码器、文本编码器和跨模态对齐模块三部分组成,无复杂交互层(如注意力融合),却能实现高效的图文语义对齐。
(1)CLIP 整体架构图
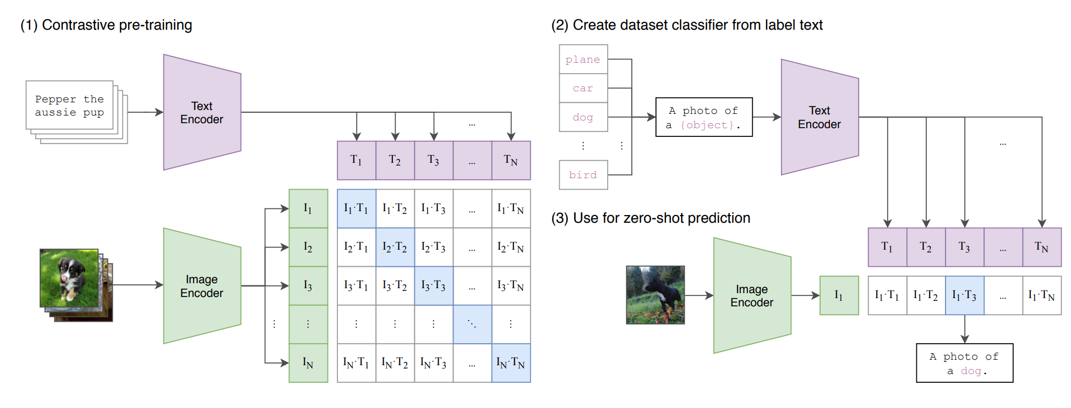
(2)架构模块细节拆解
① 图像编码器:两种选型的设计差异
| 架构类型 | 核心模块流程 | 关键改进点 | 参数量 / 计算量权衡 |
|---|---|---|---|
| ResNet 系列(RN50/RN101/RN50x64) | 图像 → Conv 层 → 残差块 → 抗锯齿池化 → 注意力池化 → 特征输出 | 1. ResNet-D:优化 shortcut 连接(降维时用 1×1 Conv); 抗锯齿模糊池化:减少下采样时的高频信息丢失;>3. 注意力池化:用单层多头注意力(Query 由全局平均池化引导)替代传统 AvgPool,动态聚焦图像关键区域 | RN50:23M 参数 / 6.1 GFLOPs;RN50x64:150M 参数 / 265.9 GFLOPs |
| ViT 系列(ViT-B/32/ViT-L/14) | 图像 → Patches + 位置嵌入 → Transformer 编码器 → 特征输出 | 1. 无 Conv 层:直接对分块图像做自注意力,捕捉长距离依赖;. 新增层归一化:在 Patches + 位置嵌入后添加,稳定训练; 高分辨率微调:ViT-L/14@336px 提升细粒度识别能力 | ViT-B/32:86M 参数 / 15.4 GFLOPs;-L/14:307M 参数 / 197.8 GFLOPs |
注意力池化工作原理(ResNet 系列专属):
-
输入:ResNet 最后一层特征图(如 RN50 为 2048 维);
-
计算过程:
-
对特征图做全局平均池化,得到全局特征向量(作为注意力 Query);
-
特征图的每个空间位置作为 Key/Value,与 Query 计算注意力权重;
-
加权求和得到最终图像特征,实现 “动态聚焦”(如识别 “猫” 时,权重向头部、身体等关键区域倾斜)。
② 文本编码器:适配图文对齐的轻量 Transformer
-
基础结构:12 层 Transformer 编码器,无解码器(仅做特征提取);
-
关键设计:
-
BPE 分词:词表大小 49152,平衡词汇覆盖度与计算效率;
-
序列长度限制:76 个 Token(含 [SOS] 和 [EOS]),适配互联网图文对的短文本特性(标题 / 简短描述);
-
[EOS] 特征提取:仅取最后一个 Token([EOS])的输出作为文本表征,因为 Transformer 编码器的最后一层能捕捉整个序列的语义信息;
-
掩码自注意力:支持对 Padding Token 做掩码,避免无效信息干扰,同时预留预训练语言模型初始化接口(论文中未使用,后续可扩展)。
③ 跨模态对齐模块:确保图文向量 “可比较”
-
线性投影层(W_i/W_t):
-
作用:将图像 / 文本编码器的输出(维度可能不同,如 RN50 的 d_i=2048,文本编码器 d_t=512)映射到同一 d_e 维空间(默认 512 维),实现 “维度统一”;
-
设计选择:仅用线性层,未加激活函数,避免引入额外非线性干扰语义对齐。
-
-
L2 归一化:
-
数学表达:对向量 v 做归一化 → v’ = v / ||v||₂;
-
核心作用:将所有嵌入向量映射到单位超球面,此时余弦相似度等价于点积,计算更高效,且能避免向量模长差异导致的相似度偏差。
-
-
可学习温度系数 τ:
-
作用:缩放相似度矩阵的数值范围,控制 Softmax 分布的 “陡峭程度”;
-
训练逻辑:τ 初始化为 0.07(参考 SimCLR),训练中以 log 参数化形式优化(避免 τ 为负),最终稳定在 0.01-0.1 之间;
-
直观影响:τ 越小,相似度矩阵的 “峰值越尖”,模型对匹配对的区分度要求越高;τ 越大,分布越平滑,训练更稳定但可能降低区分度。
-
2.3 训练流程:对比学习的数学细节
假设训练批次大小为 N(论文中 N=32768),核心步骤如下:
-
批次构建:采样 N 个独立(图像,文本)对,组成批次;
-
特征提取:
-
图像编码器输出:I_f ∈ R^(N×d_i) → 投影 + 归一化 → I_e ∈ R^(N×d_e)
-
文本编码器输出:T_f ∈ R^(N×d_t) → 投影 + 归一化 → T_e ∈ R^(N×d_e)
-
相似度计算:生成 N×N 相似度矩阵 S,其中 S_ij = cos (I_e_i, T_e_j) × exp (τ);
-
损失函数:对称交叉熵损失(双向对齐):
-
以图像为锚点:损失 L_i = CrossEntropy (S, 对角标签) → 让模型为每个图像找到匹配文本;
-
以文本为锚点:损失 L_t = CrossEntropy (S^T, 对角标签) → 让模型为每个文本找到匹配图像;
-
总损失:L = (L_i + L_t) / 2
为什么用对称损失? 确保图像→文本和文本→图像的对齐能力均衡,避免单向偏置(如只学好 “图找文”,学不好 “文找图”)。
三、数据集:4 亿图文对的构建艺术
CLIP 的成功,离不开其海量且多样的预训练数据集 ——WIT(WebImageText),这是论文未开源但至关重要的部分。
3.1 数据集构建流程
- 查询词设计:
-
基础词库:维基百科中出现≥100 次的英文单词;
-
扩展词库:高互信息二元组(如 “red car”)、维基百科高搜索量词条名、WordNet 同义词集;
-
总查询词数:50 万,确保覆盖广泛视觉概念。
- 数据采集:
-
来源:互联网公开图文数据源(未明确具体网站);
-
过滤:仅保留英文自然语言标题 / 描述(剔除自动生成的文件名、相机参数等无意义文本);
-
平衡:每个查询词最多保留 2 万条数据,避免类别偏置;
- 最终规模:4 亿图文对,总词数与 GPT-2 的 WebText 数据集相当。
3.2 与传统数据集的对比
| 数据集 | 规模 | 文本质量 | 适用场景 |
|---|---|---|---|
| MS-COCO | 10 万图文对 | 高(人工标注 caption) | 小样本多模态研究 |
| YFCC100M | 100 万图文对 | 低(含大量无意义文本) | 弱监督预训练 |
| WIT(CLIP) | 4 亿图文对 | 中(自然语言文本) | 通用跨模态预训练 |
关键优势:WIT 的文本是 “自然语言描述”,而非标签或关键词,这让模型能学习到 “概念的语言表达”(如 “a fluffy dog” 与 “a small canine” 的同义关系),而非仅学习 “标签与图像的映射”。
四、关键技术:让 CLIP 性能翻倍的 Tricks
4.1 Prompt Engineering(提示工程):零样本性能的核心杠杆
CLIP 的零样本分类能力,依赖于 “用文本提示词定义类别”,论文通过大量实验发现:
-
基础提示模板:
A photo of a {class}.是通用最优模板,较直接使用类别名(如 “dog”)提升 1.3% ImageNet 准确率; -
任务定制模板:
-
细粒度分类:
A photo of a {class}, a type of {category}.(如 “a photo of a boxer, a type of dog”); -
OCR 任务:
A photo with the text "{class}"(给文本加引号,明确任务); -
卫星图像:
A satellite photo of a {class}.;
-
-
集成提示:用多个相关提示词生成文本嵌入,平均后作为类别表征,ImageNet 准确率再提升 3.5%(如 “a big {class}”“a small {class}” 等 80 个提示词集成)。
本质:通过提示词为模型提供 “任务上下文”,弥补预训练文本与下游任务类别名的分布差异。
4.2 模型缩放策略:性能与计算的平衡
论文训练了 8 个不同规模的模型,验证了 “性能随计算量平滑增长” 的规律:
| 模型 | 图像编码器 | 计算量(GFLOPs) | ImageNet 零样本准确率 |
|---|---|---|---|
| RN50 | ResNet-50 | 6.1 | 63.2% |
| RN101 | ResNet-101 | 9.9 | 66.4% |
| RN50x4 | ResNet-50×4 | 21.5 | 72.0% |
| ViT-B/32 | ViT-Base/32 | 15.4 | 68.1% |
| ViT-L/14@336px | ViT-Large/14 | 197.8 | 76.2%(最优) |
关键发现:
-
ViT 架构的计算效率是 ResNet 的 3 倍(相同性能下,ViT 所需 GFLOPs 仅为 ResNet 的 1/3);
-
联合缩放模型宽度、深度、输入分辨率(参考 EfficientNet),比单独缩放某一维度更高效;
-
高分辨率微调(如 ViT-L/14 从 224px 提升到 336px)能显著提升细粒度识别能力。
4.3 训练优化:突破大规模训练瓶颈
CLIP 的训练规模(4 亿数据 + 32768 batch size)对工程实现要求极高,论文采用的核心优化:
-
混合精度训练:FP16 计算,节省显存同时提升速度;
-
梯度 checkpointing:牺牲少量计算量,减少激活值存储,显存占用降低 50%;
-
半精度 Adam 统计:Adam 优化器的一阶 / 二阶矩用 FP16 存储,进一步节省显存;
-
相似度矩阵分片计算:N=32768 时,N×N 矩阵无法存入单卡显存,采用多卡分片计算,每张卡仅计算局部相似度;
-
温度系数可学习:τ 作为可训练参数(log 空间优化),避免手动调参,稳定训练过程。
五、实验深度解析:CLIP 到底强在哪?
论文通过 30 + 数据集的全面评测,从零样本迁移、表征质量、鲁棒性三个维度验证了 CLIP 的优势。
5.1 零样本迁移:超越有监督基线的边界
(1)核心结果:与 ResNet-50 线性探针的对比
| 任务类型 | 代表性数据集 | CLIP 零样本准确率 | ResNet-50 有监督准确率 | 差异 |
|---|---|---|---|---|
| 通用分类 | ImageNet | 76.2% | 76.1% | +0.1% |
| 细粒度分类 | Stanford Cars | 82.3% | 53.4% | +28.9% |
| 动作识别 | Kinetics700 | 41.4% | 26.9% | +14.5% |
| 地理定位 | Country211 | 64.4% | 56.7% | +7.7% |
| 情感识别 | FER2013 | 62.0% | 59.0% | +3.0% |
关键洞察:
-
CLIP 在 “语言相关” 任务(如动作识别、地理定位,涉及动词 / 地名等语言概念)上优势显著;
-
细粒度分类任务中,CLIP 通过自然语言理解类别差异(如 “宝马 3 系” 与 “宝马 5 系” 的文本描述差异),远超依赖视觉特征的传统模型。
(2)零样本 vs 少样本:数据效率的颠覆
论文发现:CLIP 的零样本性能,相当于 4-shot 有监督线性探针(在同一特征空间上)。
-
原因:自然语言直接 “传达” 视觉概念,而少样本学习需从示例中 “推断” 概念,存在歧义(如单张猫图可能包含 “猫”“动物”“宠物” 等多个概念);
-
数据效率估算:在 ImageNet 上,零样本 CLIP 的效果≈16-shot 有监督模型;在 Stanford Cars 上,≈184-shot 有监督模型。
5.2 表征质量:线性探针的全面领先
线性探针(Linear Probe)是评估表征质量的黄金标准:冻结预训练模型,仅训练一个线性分类器,衡量表征的判别能力。
(1)与 SOTA 模型的对比(27 数据集平均)
| 模型 | 平均准确率 | 计算量(GFLOPs) |
|---|---|---|
| Noisy Student EfficientNet-L2 | 78.4% | 370 |
| CLIP ViT-L/14@336px | 83.4% | 197.8 |
| CLIP RN50x64 | 80.1% | 265.9 |
结论:CLIP 的表征质量不仅超越传统有监督模型,且计算效率更高(ViT-L/14@336px 准确率比 EfficientNet-L2 高 5%,计算量仅为其 53%)。
(2)任务覆盖范围的突破
CLIP 的表征能支持多种 “非分类” 任务,这是传统视觉模型无法做到的:
-
OCR:Rendered SST2(文本分类)准确率 88.0%;
-
面部情感识别:FER2013 准确率 62.0%;
-
视频动作识别:UCF101 准确率 65.3%;
-
地理定位:Country211 准确率 64.4%。
5.3 鲁棒性:对抗分布偏移的能力
传统视觉模型的致命弱点是 “分布偏移”(如训练集是清晰图像,测试集是模糊图像),而 CLIP 表现出极强的鲁棒性:
| 分布偏移数据集 | ResNet-101 准确率 | CLIP 零样本准确率 | 提升幅度 |
|---|---|---|---|
| ImageNetV2(重标注) | 64.3% | 70.1% | +5.8% |
| ImageNet-R(渲染图) | 32.6% | 72.3% | +39.7% |
| ImageNet-Sketch(草图) | 25.2% | 60.2% | +35.0% |
| ObjectNet(真实场景) | 2.7% | 77.1% | +74.4% |
核心原因:
-
预训练数据的多样性:4 亿图文对覆盖不同场景、分辨率、风格的图像;
-
自然语言的抽象性:语言描述的是 “概念本质”(如 “猫” 是 “有毛、四条腿、会喵喵叫的动物”),而非表面特征(如颜色、纹理),因此对分布偏移不敏感。
六、局限与挑战:CLIP 不是万能的
尽管 CLIP 表现惊艳,但论文也客观指出了其局限性,这也是后续研究的方向:
6.1 任务能力边界
-
细粒度区分弱:花卉品种(Flowers102)、飞机型号(FGVC Aircraft)等任务,零样本准确率仅 50%-60%,远低于有监督模型;
-
抽象 / 逻辑任务差:计数(CLEVRCounts)、距离估计(KITTI Distance)等任务,准确率接近随机;
-
小众领域泛化弱:医学影像(PatchCamelyon)、卫星图(EuroSAT)等专业领域,效果不如领域内微调模型。
6.2 数据与偏见问题
-
数据偏见:训练数据来自互联网,存在性别、种族、文化偏见(如论文测试发现,零样本 CLIP 在 FairFace 数据集上,对 “白人” 种族分类准确率 58.3%,对 “非白人” 达 91.3%);
-
数据重叠风险:预训练数据可能包含下游评测数据集的样本,但论文检测发现重叠率极低(平均 3.2%),对性能影响可忽略(最大提升 0.6%)。
6.3 计算与效率瓶颈
-
训练成本极高:最大模型 ViT-L/14@336px 需 256 张 V100 GPU 训练 12 天,显存占用依赖梯度 checkpointing、混合精度等优化;
-
推理速度慢:ViT-L/14@336px 单张图像推理需 197.8 GFLOPs,远超 ResNet-50(6.1 GFLOPs),边缘设备部署困难。
6.4 少样本学习的反直觉现象
CLIP 的零样本性能优于 1-shot/2-shot,这与人类学习规律相反(人类从少量示例中快速学习):
-
原因:CLIP 的零样本分类器是 “语言引导” 的,而少样本是 “示例引导” 的,两者未有效结合;
-
解决方案:未来需探索 “零样本 + 少样本” 的融合方法,如用零样本分类器作为少样本学习的先验。
七、产业落地:CLIP 的典型应用场景
CLIP 的 “零样本 + 通用” 特性,使其在多个行业具有落地价值,以下是最成熟的场景:
7.1 跨模态检索(核心场景)
-
应用:电商商品检索(文本搜图 / 图搜文本)、图库管理、内容推荐;
-
优势:无需标注检索标签,直接用自然语言描述(如 “黑色连帽卫衣,带印花”),检索精度远超传统 CNN 特征;
-
案例:Pinterest 用类似 CLIP 的模型优化图像检索,用户点击率提升 30%+。
7.2 零样本图像分类与审核
-
应用:缺陷检测(如 “手机屏幕划痕”“汽车漆面凹陷”)、内容安全(如 “暴力图像”“违规广告”)、异常识别;
-
优势:快速上线新类别,无需标注样本(如新增 “虚假宣传” 类别,仅需添加提示词);
-
落地技巧:结合少量标注样本做线性微调(Few-shot Fine-tuning),进一步提升精度。
7.3 AIGC 生态基石
-
应用:文生图(Stable Diffusion、DALL-E)的文本编码器、图生文、多模态对话;
-
核心作用:提供图文对齐的统一表征,让生成模型理解 “文本描述” 与 “视觉特征” 的关联;
-
延伸:CLIP 的对比学习范式,也启发了语音 - 文本、视频 - 文本等跨模态生成任务。
7.4 视觉特征工程
-
应用:为下游任务提供高质量视觉特征(如目标检测、分割的预训练 backbone);
-
优势:特征泛化性强,在小样本目标检测任务中,CLIP 特征比 ImageNet 预训练特征提升 15%-20%。
八、进阶实践:CLIP 部署与优化技巧
8.1 模型选型建议
| 场景 | 推荐模型 | 理由 |
|---|---|---|
| 快速验证原型 | ViT-B/32 | 速度快(15.4 GFLOPs),准确率足够(68.1%) |
| 追求高精度 | ViT-L/14@336px | 最优性能,ImageNet 零样本 76.2% |
| 边缘设备部署 | RN50 | 轻量(6.1 GFLOPs),支持 INT8 量化 |
8.2 部署优化方案
-
量化:INT8 量化后,模型体积缩小 4 倍,推理速度提升 2-3 倍,准确率下降≤2%;
-
模型蒸馏:用 ViT-L/14 蒸馏到 RN50,在保持 95% 性能的同时,推理速度提升 10 倍;
-
ONNX/TensorRT 加速:
-
转换为 ONNX 格式,支持跨框架部署;
-
TensorRT 优化(FP16),GPU 推理速度提升 3-5 倍;
- 批量推理:利用 CLIP 的批次并行特性,批量处理时吞吐量提升显著(batch size=32 时,吞吐量是 batch size=1 的 20 倍 +)。
8.3 Prompt 优化实战
针对不同任务的最优 Prompt 模板(来自论文及工业实践):
| 任务类型 | 最优 Prompt 模板 | 示例 |
|---|---|---|
| 通用分类 | “A photo of a {class}.” | “A photo of a cat.” |
| 细粒度分类 | “A photo of a {class}, a type of {category}.” | “A photo of a golden retriever, a type of dog.” |
| OCR 文本识别 | “A photo containing the text “{class}”.” | “A photo containing the text “OpenAI”.” |
| 场景分类 | “A photo of a {class} scene.” | “A photo of a beach scene.” |
| 缺陷检测 | “A photo of a {class} defect.” | “A photo of a screen scratch defect.” |
九、技术演进:CLIP 之后的多模态模型
CLIP 开启了 “自然语言监督的视觉预训练” 时代,后续涌现出一系列改进模型:
| 模型 | 核心改进 | 性能提升 |
|---|---|---|
| ALIGN(Google) | 1. 更大数据集(18 亿图文对);2. 更简单的文本编码器 | ImageNet 零样本 77.6%(略超 CLIP) |
| BLIP(Salesforce) | 1. 融合生成式目标(图文生成);2. 多任务预训练 | 图生文、VQA 任务超越 CLIP |
| FLAVA(Facebook) | 1. 支持图像、文本、音频跨模态;2. 统一预训练框架 | 多模态理解任务 SOTA |
| CLIP-Dissect(UC Berkeley) | 1. 可解释性优化;2. 去除偏见 | 公平性提升 20%,性能无损 |
演进趋势:
-
更大规模的多模态数据(融合音频、视频);
-
生成式 + 对比式混合目标;
-
更强的可解释性与公平性;
-
高效小型化模型(适配边缘设备)。
十、总结:CLIP 的历史地位与未来
CLIP 不仅是一个模型,更是一种 “用自然语言解锁通用视觉能力” 的范式革命:
-
打破了 “视觉模型依赖人工标注” 的固有认知;
-
定义了 “双编码器 + 对比学习” 的多模态预训练框架;
-
成为 AIGC、跨模态检索、通用 AI 的核心基石。
未来方向:
-
解决细粒度、抽象任务的能力短板;
-
降低训练与推理成本,推动边缘部署;
-
缓解数据偏见,提升模型公平性;
-
融合更多模态(音频、视频、3D 点云),迈向通用多模态 AI。
CLIP 证明了:自然语言是连接不同模态的通用桥梁。当 AI 能像人类一样,用语言理解视觉世界,通用人工智能的大门,正被缓缓推开。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)