大模型算力成本管控与资源节流:GPU显存精细化管理、弹性扩缩容、资源回收.168
一、算力成本管控
1. 核心定义
算力成本:大模型训练、推理、部署全生命周期中,GPU/CPU等硬件资源、云服务、电力、运维产生的总费用,是大模型落地的核心成本项。
资源节流:在不降低大模型服务质量、响应速度、推理精度的前提下,通过技术手段减少资源占用、缩短资源使用时间、降低单位请求成本的操作集合。
GPU显存管控:对显卡显存的分配、释放、复用进行精细化管理,避免显存溢出、闲置浪费,提升显存利用率。
按需扩缩容:根据大模型实时请求量、负载压力,自动或手动调整算力资源规模,高峰期扩容、低峰期缩容,杜绝资源闲置。
闲置资源释放:自动识别并回收未使用、低负载、超时闲置的算力资源,避免空耗成本。
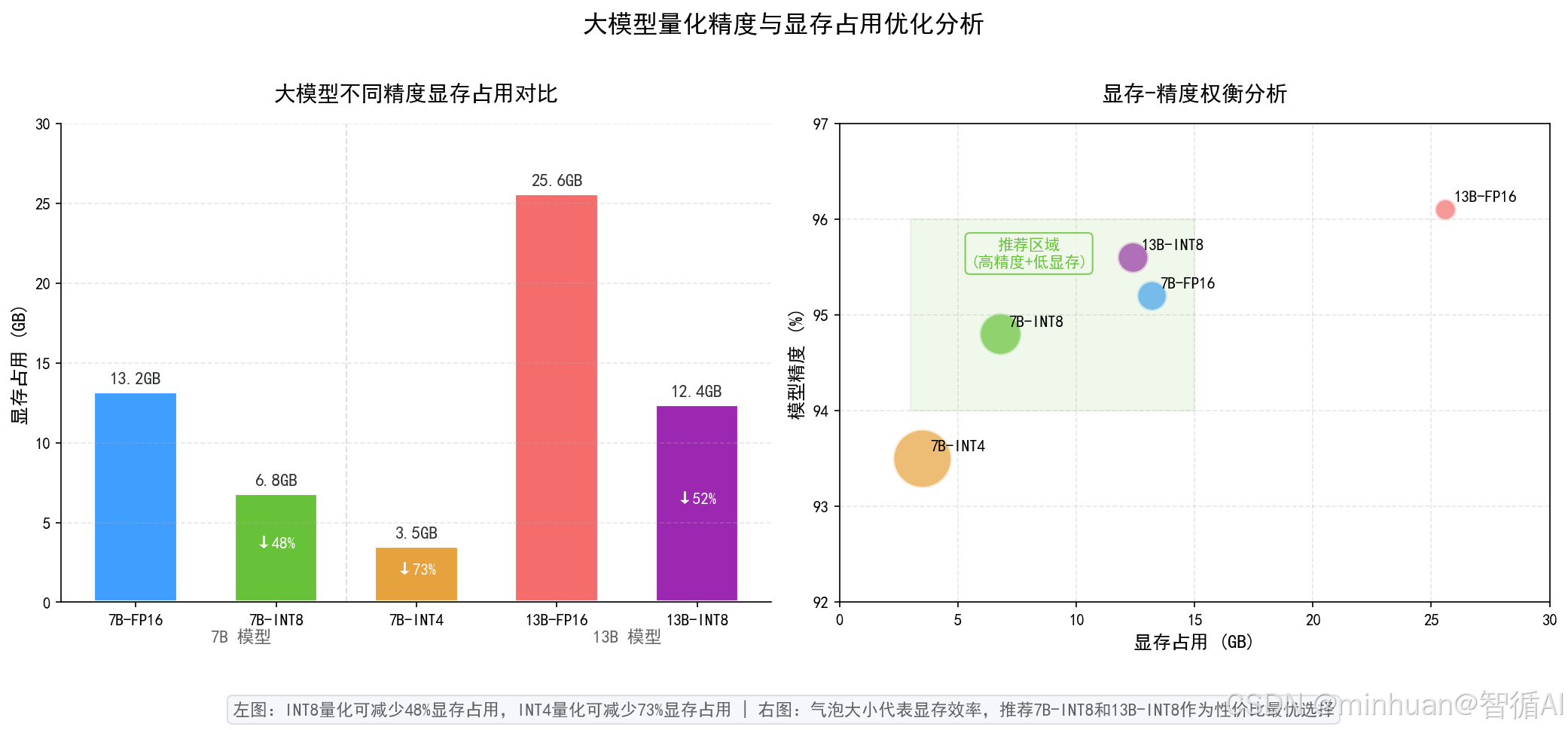
量化推理降本:将大模型高精度参数(FP32/FP16)转换为低精度参数(INT8/INT4),减少显存占用和计算量,降低推理成本。
API额度节流:对大模型API调用进行频率、次数、流量限制,避免超额调用、恶意刷量导致的成本失控。

2. 核心资源
GPU:是大模型运行的核心算力载体,消费级4090适合7B、13B规模模型推理与小场景微调,企业级A10、A100、L40适配34B、70B超大模型部署与高并发推理、大规模训练任务。
显存:承担模型参数存储、推理中间计算张量缓存、上下文窗口存储等关键作用,模型参数量越大、上下文长度越长、并发请求越多,对显存容量需求就越高,显存不足会直接导致模型加载失败与推理报错。
算力单元:云厂商标准化的GPU服务器资源,按配置规格、运行时长计费,是绝大多数企业线上部署大模型的主要载体。
API调用:属于无硬件部署模式,直接调用大厂封装好的大模型接口,按照Token消耗量、调用次数计费,适合轻量业务、初创项目快速接入AI能力。
3. 计费模式
包年包月:适合业务长期稳定、流量波动小的固定服务,一次性锁定资源单价,长期使用性价比高,但灵活性极差,无法跟随业务流量随时调整资源规模。
按需计费:随开随用、随时关停,按实际运行分钟或小时计费,适合临时测试、短期活动、突发流量场景,缺点是常规单价偏高,长期运行成本不占优势。
竞价实例:云厂商闲置富余算力资源,价格仅为常规按需实例的一到三成,缺点是平台可随时回收资源,只适合离线推理、数据预处理、非核心容错性高的任务。
API按量计费:无需搭建硬件、无需运维显卡,接入简单上手快,适合低并发、小流量业务,一旦业务规模扩张、调用量暴涨,长期费用会远超自建部署。
4. 成本浪费场景
- 显存浪费集中在模型常驻后台,服务部署完成后长时间无用户请求,但显存始终被模型参数占用,不主动释放,形成静态资源空耗。
- 资源超配项目初期为追求稳定性,盲目选用超高规格GPU实例,实际日常负载仅用到两三成算力,大部分硬件性能长期闲置。
- 扩缩容不及时会造成两端问题,高峰期资源不足引发排队超时、接口卡顿,低峰期不及时缩容,大量节点空转持续扣费。
- 测试环境、调试环境的GPU实例,开发完成后常常被遗忘关停,无人维护巡检,日积月累产生大量无效账单。
- API无任何限流与配额管控,内部服务循环调用、用户恶意批量请求、重复相同请求反复调用,都会造成Token额度快速透支。
- 全程使用FP32、FP16高精度推理,很多通用对话、文案生成、简单问答业务,完全不需要超高精度,白白浪费显存与算力开销。
5. 核心价值体现
5.1 降低大模型落地门槛
以往中小团队因高昂GPU算力成本无法自研部署,通过成本管控与资源节流,能用更低硬件配置、更少云资源开销完成大模型私有化部署与线上服务上线。
5.2 提升算力资源利用效率
很多业务场景普遍存在高配置部署、低流量运行的现状,资源闲置率常年居高不下,通过整套管控体系可把资源利用率从偏低水平拉升至合理区间。
5.3 保障大模型服务运行稳定
显存溢出、算力过载、节点资源耗尽、API额度超限,都是线上服务崩溃、响应超时的常见诱因,精细化管控可以提前规避这类故障风险。
5.4 实现成本可观测可治理
把模糊的算力开销拆解到显存占用、节点时长、推理调用、API消耗等维度,做到成本量化统计、异常成本告警、优化效果可对比。
6. 预期实施目标
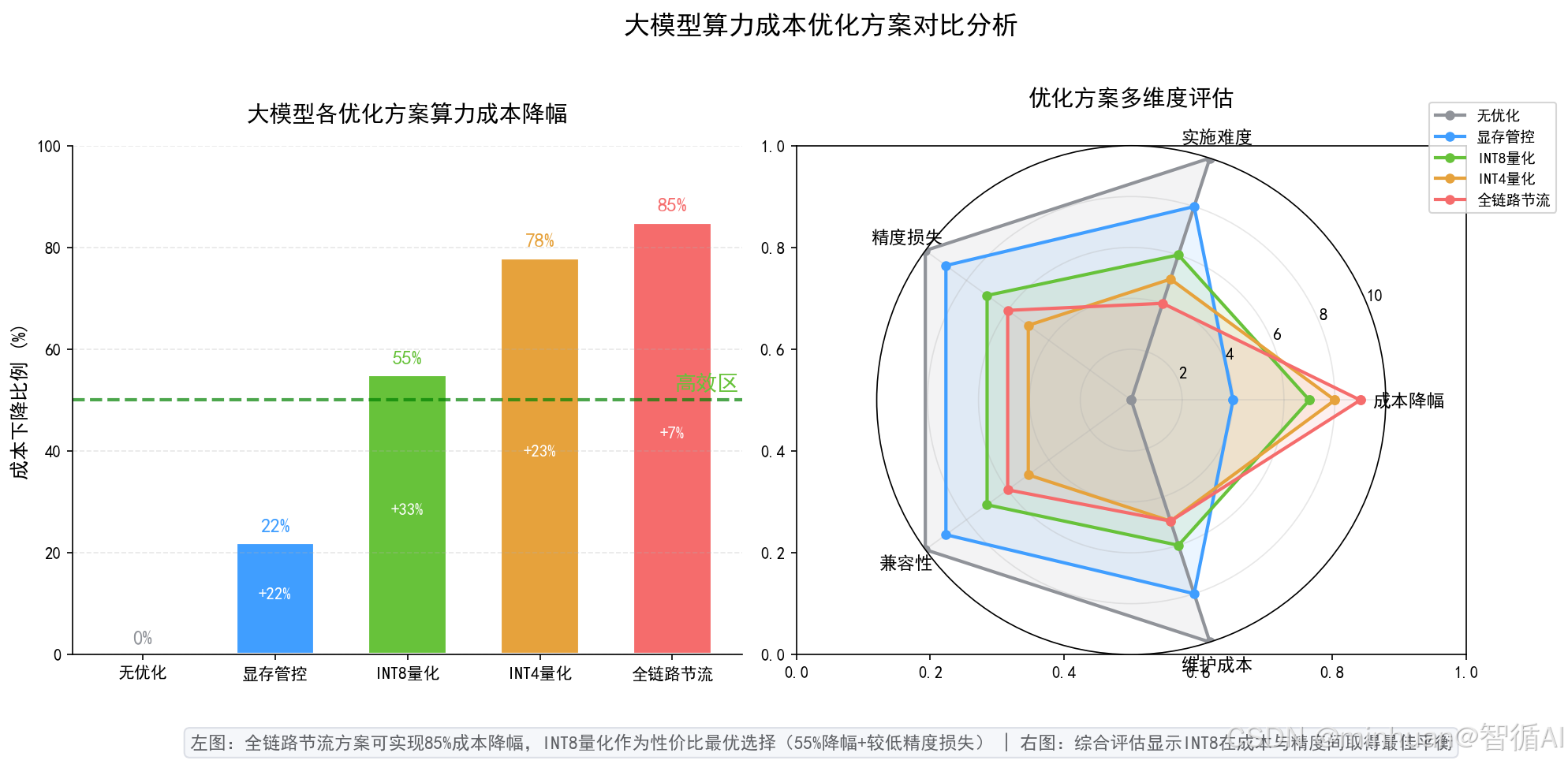
成本最小化:以业务需求为底线,不盲目砍配置、不降服务体验,通过组合优化手段实现综合算力成本大幅下降。
资源高效化:聚焦显存、算力、节点三类核心资源,减少空闲占用、碎片浪费和重复资源分配。
服务稳定化:坚持节流不降质,优化前后保持推理输出效果、接口响应速度、并发承载能力基本一致。
管控自动化:减少人工巡检、手动开关机、人工调整配置的工作量,让资源调度、闲置回收、额度风控全部自动运行。
7. 节流核心原则
非必要不高配:依据模型参数量、上下文窗口大小、业务并发量级匹配对应GPU规格,不追求硬件顶配冗余。
用完即释放:临时任务、测试任务、离线推理任务执行完毕,立刻自动休眠或销毁资源,不允许长时间挂起。
精度适配业务:按业务场景选择量化等级,简单业务选用INT4极致降本,专业文案、专业问答选用INT8平衡精度与成本。
自动化优先:所有资源监控、闲置判断、扩缩容调度、额度拦截全部脚本化、服务化,依靠程序规则代替人工操作,避免人为疏忽。
二、GPU 显存管控
1. 显存占用核心原理
大模型整体显存占用由三大部分叠加构成:模型基础参数字显存、单次推理产生的中间张量与激活值显存、CUDA运行环境与框架系统预留显存。
参数精度位宽直接决定基础显存大小,FP32单精度占用最大,FP16半精度减半,INT8、INT4量化后呈倍数下降,是显存优化最直接的切入点。
并发请求数量会线性拉升中间显存占用,并发越高,同时存在的推理上下文、中间计算数据越多,越容易触达显存上限引发OOM。
另外上下文窗口长度、批量推理大小、KV缓存复用策略,都会额外占用可观显存,也是显存管控必须优化的细节点。
2. 显存管控基础技术
显存动态分配:放弃一次性预占全部显存的模式,由框架随推理任务按需分配、用完即时释放,避免开机即占满显存造成资源浪费。
显存碎片整理:解决多次加载、多次推理后显存空间碎片化问题,零散空闲小块无法被新任务利用,通过整理合并空闲空间,提升显存实际可用容量。
模型分层加载:适合超大模型无法单卡部署场景,把模型权重拆分多块,推理时按需加载对应网络层,不用的层暂存内存,大幅降低单卡显存压力。
推理批处理优化:把零散小请求合并成批量统一推理,减少框架初始化、上下文创建的重复显存开销,提升单批次显存利用效率。
3. 显存管控执行流程

- 1. 持续监控采集:定时抓取GPU已分配显存、预留显存、空闲显存、显存峰值、碎片占比等关键指标,建立基线数据。
- 2. 识别显存瓶颈:做瓶颈定位,区分显存紧张是模型本身参数量过大、并发请求过高、KV缓存无限制增长,还是显存碎片堆积导致。
- 3. 匹配对应优化方案:参数偏大走量化压缩,并发过高做请求限流与批处理,碎片过多开启自动碎片整理与缓存清理。
- 4. 上线验证效果:观察优化前后显存峰值、平均占用、OOM 报错频次,同时校验推理输出精度、响应速度无明显波动。
4. 基础示例实践
通过动态显存分配配置、实时监控GPU使用情况、自动清理无效显存三个核心功能,解决大模型推理时的显存溢出问题。包含显存检查、垃圾回收、CUDA缓存清理等实用函数,实现高效管理GPU资源,提升模型部署稳定性。
import torch
import gc
import os
# 1. 启用PyTorch动态显存分配,避免一次性占满显存
torch.cuda.empty_cache()
torch.backends.cudnn.benchmark = True
os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "max_split_size_mb:128"
# 2. 显存监控函数
def check_gpu_memory():
"""实时监控GPU显存使用情况"""
if torch.cuda.is_available():
allocated = torch.cuda.memory_allocated() / 1024**3 # 已分配显存(GB)
reserved = torch.cuda.memory_reserved() / 1024**3 # 总预留显存(GB)
free = reserved - allocated # 空闲显存(GB)
print(f"已分配显存:{allocated:.2f} GB")
print(f"空闲显存:{free:.2f} GB")
return allocated, free
# 3. 自动显存清理函数
def auto_clean_memory():
"""自动清理无效显存,释放空闲空间"""
gc.collect() # 清理Python内存
torch.cuda.empty_cache() # 清理CUDA显存
print("显存清理完成")
# 4. 实战使用
if __name__ == "__main__":
# 加载模型前检查显存
check_gpu_memory()
# 加载大模型(示例)
model = torch.nn.Linear(1024, 1024).cuda()
# 推理完成后清理显存
auto_clean_memory()
# 清理后检查显存
check_gpu_memory()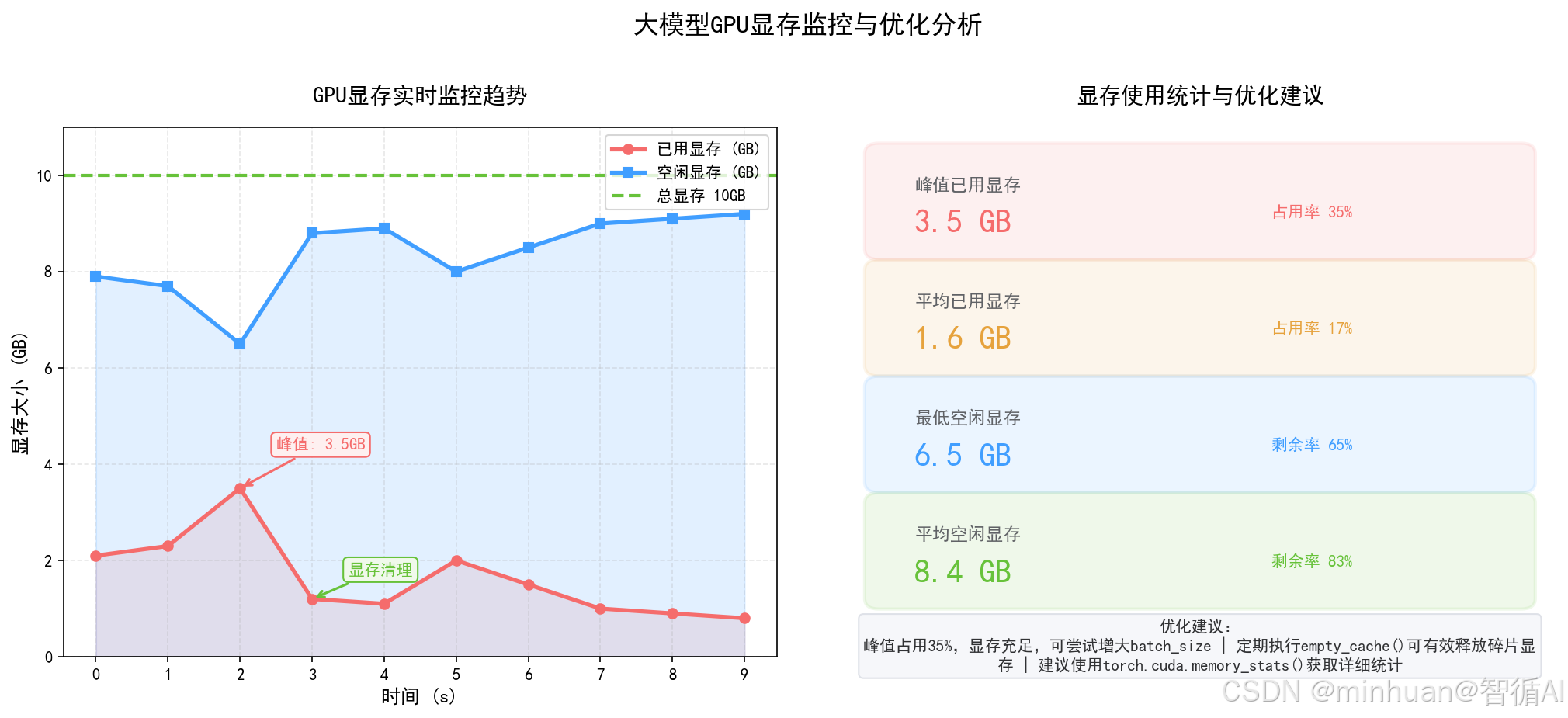
三、按需扩缩容
1. 扩缩容核心原理
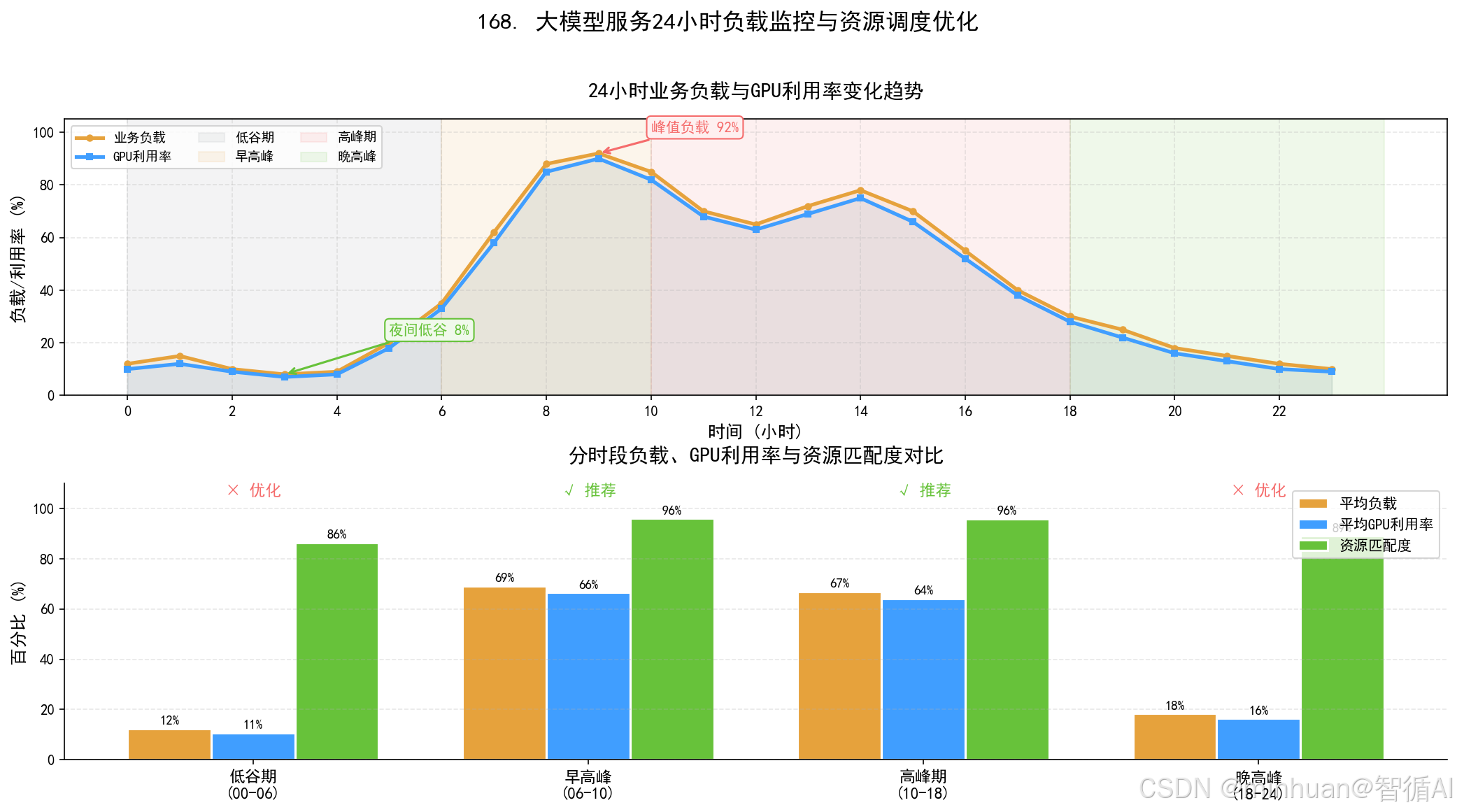
整套调度逻辑以实时业务监控指标为决策依据,不依靠人工经验判断。核心监测维度包含接口每秒请求量、并发连接数、GPU实时利用率、接口平均响应时延、队列堆积长度。
扩容逻辑在负载突破设定阈值后,自动调度创建新的GPU推理节点,自动拉取模型权重、完成服务预热、接入流量负载均衡,快速承接增量请求。
缩容逻辑在业务流量回落、算力利用率长期偏低时,逐步下线多余节点,优先关停闲置最久、负载最低的实例,保留最小可用集群保证基础服务不中断。
核心设计思路就是让算力资源规模跟随业务流量潮汐变化,做到峰期够支撑、谷期不浪费。
2. 扩缩容核心指标
GPU利用率:是最核心判定指标,常规设定低于30%持续5分钟触发缩容,高于80%持续3分钟触发扩容,避免瞬时波动造成频繁无效调度。
请求响应时延:面向用户体验,接口平均时延超出基准阈值,说明现有算力已承压,必须及时扩容缓解排队压力。
并发请求数:匹配单节点承载上限,当全局并发逼近集群最大承载力,提前扩容预防服务雪崩。
时间段策略:适配日常业务规律,凌晨低峰时段固定缩容至最小节点数,早高峰、晚高峰提前预备扩容节点,实现时间维度的预判调度。
3. 扩缩容执行流程

- 1. 预先配置阈值与边界:设定扩缩容上下限阈值、集群最小实例数、最大实例数,防止无限制扩容造成成本失控,无限制缩容导致服务宕机。
- 2. 定时采集监控数据:以分钟级频率抓取各节点负载、流量、时延数据,存入时序数据库做持续观测。
- 3. 调度策略逻辑判断:对比实时指标和预设阈值,同时规避短时流量抖动,增加持续时间判定,防止频繁启停节点。
- 4. 执行资源调度动作:调用云厂商开放API完成实例创建、启动、关机、销毁,同步更新负载均衡节点列表。
- 5. 新节点服务预热:自动加载大模型、初始化推理服务,等待模型加载完成后再接入流量,避免刚上线就出现响应超时。
- 6. 全流程日志记录:留存每一次扩缩容的触发时间、触发指标、变更节点数量,用于后续成本复盘与策略调优。
4. 基础示例实践
import time
import requests
import os
API_URL = os.getenv("api_url")
ACCESS_KEY = os.getenv("access_key")
SECRET_KEY = os.getenv("secret_key")
MIN_INSTANCES = 1 # 最小实例数
MAX_INSTANCES = 5 # 最大实例数
SCALE_UP_THRESHOLD = 80 # 扩容阈值:GPU利用率>80%
SCALE_DOWN_THRESHOLD = 30 # 缩容阈值:GPU利用率<30%
# 1. 获取实时GPU利用率
def get_gpu_utilization():
"""模拟获取GPU实时利用率(实际对接云监控API)"""
# 真实场景:调用云厂商监控API获取GPU使用率
mock_util = np.random.randint(20, 90) # 模拟数据
print(f"当前GPU利用率:{mock_util}%")
return mock_util
# 2. 扩容函数
def scale_up():
"""自动新增GPU实例"""
print("触发扩容:创建新的GPU实例...")
# 实际代码:调用云API创建实例
time.sleep(2)
print("扩容完成,服务已预热上线")
# 3. 缩容函数
def scale_down():
"""自动销毁闲置GPU实例"""
print("触发缩容:销毁闲置GPU实例...")
# 实际代码:调用云API销毁实例
time.sleep(2)
print("缩容完成,成本已降低")
# 4. 主调度逻辑
def elastic_scaling():
current_instances = 2
while True:
util = get_gpu_utilization()
# 扩容判断
if util > SCALE_UP_THRESHOLD and current_instances < MAX_INSTANCES:
scale_up()
current_instances += 1
# 缩容判断
elif util < SCALE_DOWN_THRESHOLD and current_instances > MIN_INSTANCES:
scale_down()
current_instances -= 1
# 每30秒检测一次
time.sleep(30)
if __name__ == "__main__":
elastic_scaling()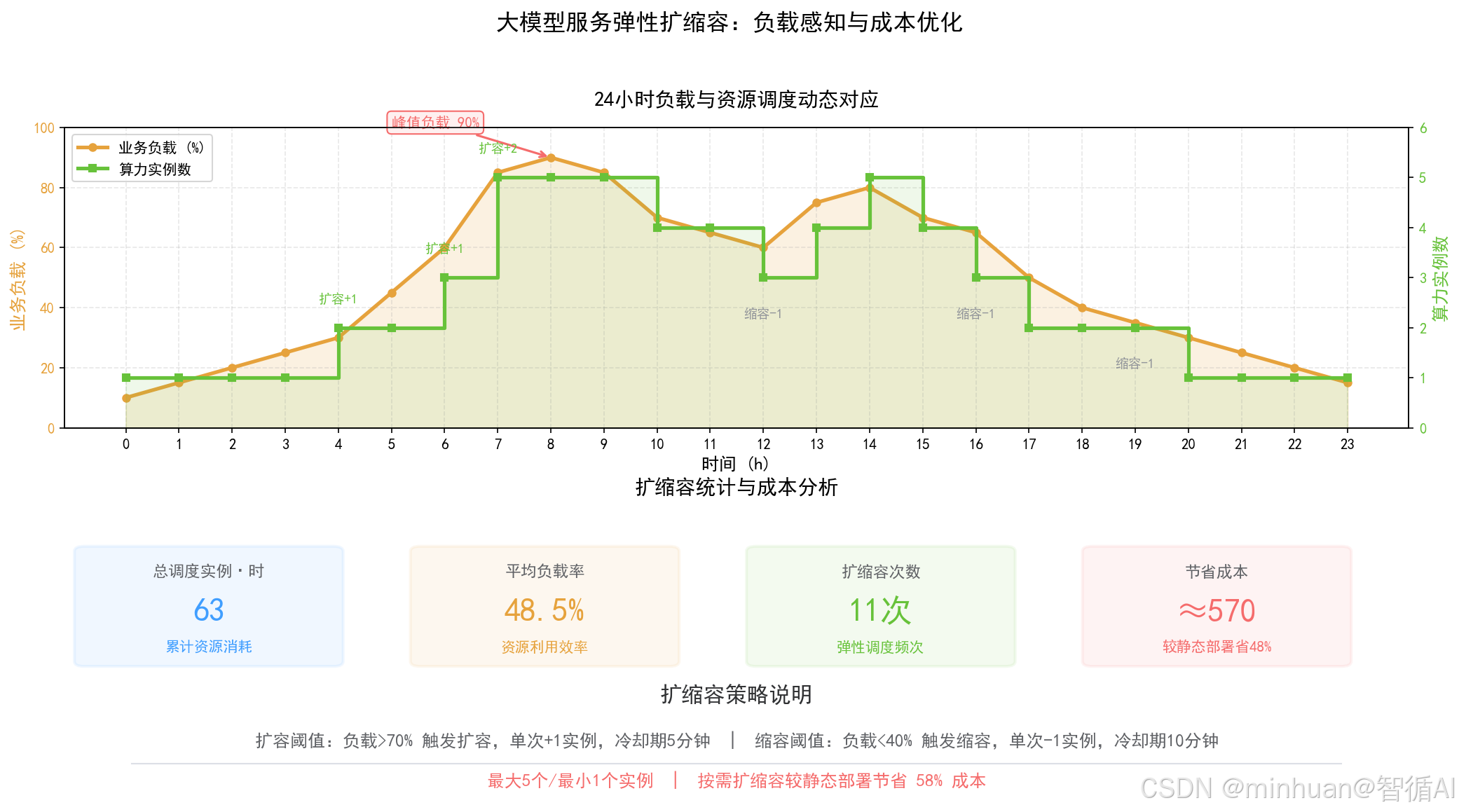
四、闲置资源释放
1. 闲置资源定义与识别
闲置资源涵盖所有已开机运行,但无实际业务负载的GPU实例、推理服务、离线任务节点。典型特征是连续一段时间无外部推理请求、网络出入流量近乎为零、GPU和CPU利用率长期处于极低水平。
识别方式分为三类:
- 流量监控识别,无网络交互流量判定为闲置;
- 硬件利用率识别,算力利用率长期低于阈值判定为闲置;
- 业务日志识别,服务访问日志长时间无新请求判定为闲置。
同时可区分临时闲置和长期闲置,短时业务波动不做处理,超过预设时长的长期闲置才纳入待释放列表,避免误杀正常服务。
2. 闲置资源释放核心价值
- 1. 切断人工遗忘关机带来的持续性扣费,很多测试资源、临时演示资源常年挂起,自动释放可每月减少可观无效成本。
- 2. 盘活闲置算力,回收后的资源可调度给离线训练、数据预处理等任务,提升整体集群资源周转效率。
- 3. 全程自动化巡检、自动判定、自动释放,无需运维人员逐台检查节点状态,降低人力运维成本,同时杜绝人为遗漏造成的浪费。
3. 闲置资源释放执行流程

- 1. 自定义闲置判定规则:配置闲置持续时长阈值、硬件利用率阈值,同时设置核心保护节点,避免业务主服务被误释放。
- 2. 定时全局资源扫描:每分钟遍历所有GPU实例与推理服务,采集利用率、流量、请求日志三类数据。
- 3. 标记分级闲置状态:将资源分为正常运行、短时闲置、长期闲置三个等级,仅对长期闲置执行后续操作。
- 4. 前置预警机制:正式释放前推送消息提醒,给运维预留手动干预时间,防止特殊场景自动释放影响业务。
- 5. 自动执行资源关停:按照优雅下线逻辑停止服务、销毁实例或休眠节点,保证数据不丢失、业务不中断。
- 6. 留存账单与操作日志:记录每一个释放资源的ID、闲置时长、预估节省成本,方便月度成本统计复盘。
4. 基础示例实践
import time
import datetime
# 闲置判定配置
IDLE_THRESHOLD = 10 # 闲置时间阈值(分钟)
IDLE_UTIL = 10 # 闲置利用率阈值(%)
# 模拟资源列表
resources = [
{"id": "gpu-01", "name": "大模型推理实例", "util": 5, "idle_time": 12},
{"id": "gpu-02", "name": "测试实例", "util": 8, "idle_time": 15},
{"id": "gpu-03", "name": "核心服务实例", "util": 60, "idle_time": 0}
]
# 1. 检查资源是否闲置
def is_idle(resource):
"""判断资源是否为闲置资源"""
return (resource["util"] < IDLE_UTIL) and (resource["idle_time"] >= IDLE_THRESHOLD)
# 2. 自动释放闲置资源
def release_idle_resources():
print(f"=== 闲置资源扫描开始 {datetime.datetime.now()} ===")
for res in resources:
if is_idle(res):
print(f"发现闲置资源:{res['name']},利用率:{res['util']}%,闲置时长:{res['idle_time']}分钟")
# 实际代码:调用云API释放资源
print(f"已自动释放资源:{res['id']},成本止损完成\n")
else:
print(f"资源正常:{res['name']},无需释放\n")
print("=== 闲置资源扫描结束 ===\n")
# 3. 定时执行释放
if __name__ == "__main__":
while True:
release_idle_resources()
time.sleep(60) # 每分钟扫描一次五、量化推理降本
1. 量化推理基础原理
量化本质是数值精度压缩转换,把大模型原生FP32 32位浮点参数,压缩为FP16半精度、INT8 8位整型、INT4 4位整型存储格式,用更低位宽表达模型权重。
显存占用随位宽降低成倍减少,INT8相比FP32显存节省四分之三,INT4可节省九成以上,直接降低部署所需GPU配置门槛。
计算量同步下降,低精度数值运算硬件执行速度更快,推理单条请求耗时缩短,同等硬件下可承载更高并发量。
主流GPTQ、AWQ、SmoothQuant等量化算法,通过校准数据做权重分布优化,把语义理解、逻辑推理的精度损耗控制在极低范围,普通业务完全无感知。
2. 量化推理适用场景
- 主要适用于大模型线上推理部署环节,模型训练、高精度微调场景不建议过度量化,避免损失训练收敛效果。
- 显存紧张、预算有限的团队,可通过量化把7B、13B模型下放至普通4090单卡部署,无需采购高端多卡集群。
- 对推理响应速度敏感的对话、客服、实时问答业务,量化可加速推理吞吐,提升用户交互体验。
- 边缘设备、本地终端私有化部署场景,硬件显存容量有限,量化是模型落地必不可少的优化手段。
3. 量化推理执行流程

- 1. 选择量化算法和精度:根据业务精度要求选定量化算法与精度等级,专业领域选择INT8平衡精度与成本,通用场景选择INT4极致降本。
- 2. 准备少量校准数据集:用于量化过程中权重分布校准,最大限度保留模型原有语义能力。
- 3. 加载原始模型权重:调用量化框架执行权重转换、校准、保存量化后模型文件。
- 4. 做多维度效果验证:对比量化前后显存占用、推理速度、输出内容一致性、长文本上下文稳定性。
- 5. 部署量化模型:把量化模型替换原有高精度模型上线,适配推理服务配置,完成低成本落地。
4. 基础示例实践
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# 模型名称(替换为实际模型)
MODEL_NAME = "Llama-2-7B-chat"
# 1. 加载量化配置:启用INT8量化
model = AutoModelForCausalLM.from_pretrained(
MODEL_NAME,
torch_dtype=torch.float16,
load_in_8bit=True, # 核心:开启INT8量化
device_map="auto",
trust_remote_code=True
)
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
# 2. 推理测试
def quantized_inference(prompt):
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens=100)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
return response
# 3. 验证效果
if __name__ == "__main__":
prompt = "请解释大模型算力节流的意义"
result = quantized_inference(prompt)
print("量化模型推理结果:", result)
# 查看显存占用
print(f"量化后显存占用:{torch.cuda.memory_allocated()/1024**3:.2f} GB")六、API 额度节流
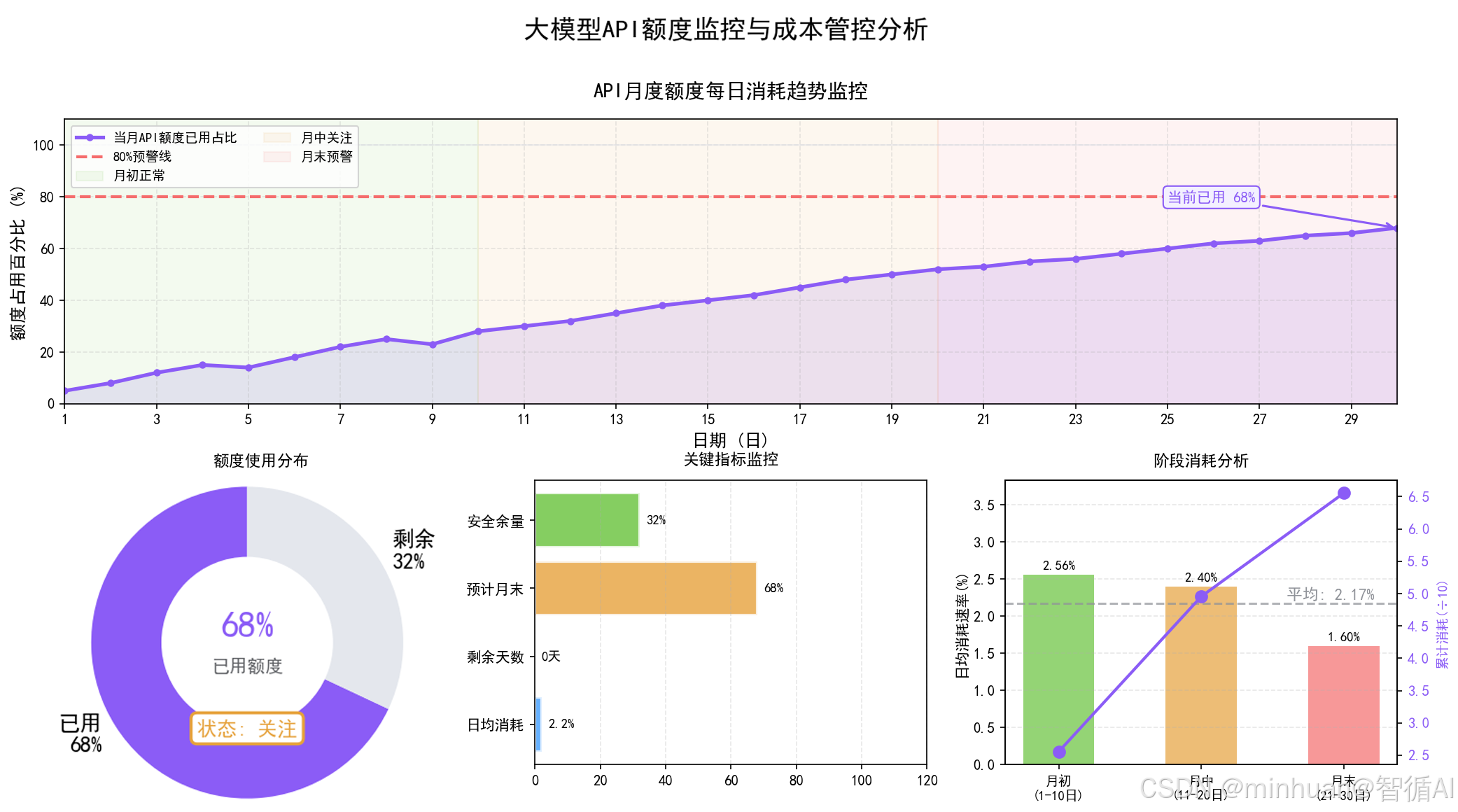
1. API额度节流目的
- 管控第三方大模型接口调用开销,避免无限制调用导致月度账单超预算,把API费用控制在预设成本区间内。
- 抵御恶意请求、批量刷取、爬虫循环调用等异常行为,防止短时间内Token暴涨引发费用暴增。
- 规范内部业务调用逻辑,剔除重复请求、无效空请求、无意义测试请求,让每一次API调用都产生实际业务价值。
- 建立可量化的调用管控体系,实现额度统计、消耗监控、超额预警、自动限流全链路治理。
2. API额度节流策略
- 调用频率限制针对单用户、单IP、单业务接口设置每秒、每分钟最大调用次数,抹平突发流量,防止瞬时并发冲垮额度。
- 月度额度配额设定全局总Token上限、各业务线分额度上限,按部门、按项目拆分配额,做到成本责任到人。
- 请求内容过滤拦截空请求、重复参数请求、无意义无效Prompt,直接拒绝不转发API,减少无效消耗。
- 结果缓存复用对高频相同问答、固定文案生成请求做本地缓存,重复请求直接返回缓存内容,不消耗API Token。
- 超额分级预警,额度消耗达到八成推送预警通知,耗尽额度后自动暂停调用并返回友好提示,杜绝超额欠费。
3. API额度节流执行流程

- 1. 配置节流规则:定义频率限制阈值、月度总配额、业务分配额、缓存有效期、预警触发比例。
- 2. 请求拦截:所有外部与内部请求统一经过节流中间件拦截,不直接对接大模型API。
- 3. 依次做规则校验:频率超限校验、额度剩余校验、缓存命中校验、无效请求过滤。
- 4. 执行策略:按校验结果执行对应逻辑,合规请求转发 API,超限请求拦截提示,命中缓存直接返回结果。
- 5. 日志统计:实时统计Token消耗、调用次数、拦截次数,定时生成消耗报表,超额触发预警通知。
4. 基础示例实践
import time
from functools import lru_cache
# API节流配置
MAX_REQUEST_PER_MINUTE = 60 # 每分钟最大调用次数
MAX_MONTHLY_TOKENS = 1000000 # 月度最大token额度
USED_TOKENS = 850000 # 已使用token
# 1. 频率限制装饰器
def rate_limit(max_calls, period):
calls = []
def decorator(func):
def wrapper(*args, **kwargs):
now = time.time()
# 清理过期调用记录
calls[:] = [t for t in calls if t > now - period]
if len(calls) >= max_calls:
return "错误:调用频率超出限制,请稍后再试"
calls.append(now)
return func(*args, **kwargs)
return wrapper
return decorator
# 2. 额度检查函数
def check_token_limit(tokens):
global USED_TOKENS
if USED_TOKENS + tokens > MAX_MONTHLY_TOKENS:
return False, "错误:月度API额度已用尽"
USED_TOKENS += tokens
return True, f"额度剩余:{MAX_MONTHLY_TOKENS - USED_TOKENS}"
# 3. 缓存复用函数
@lru_cache(maxsize=1000)
def get_cache_response(prompt):
return None # 缓存存储
# 4. 节流API调用函数
@rate_limit(max_calls=MAX_REQUEST_PER_MINUTE, period=60)
def api_call_with_throttle(prompt):
# 先检查缓存
cache = get_cache_response(prompt)
if cache:
return f"缓存结果:{cache}"
# 检查额度
tokens = len(prompt) * 1.3 # 估算token数
success, msg = check_token_limit(tokens)
if not success:
return msg
# 正常调用API
response = f"API调用结果:{prompt} - 大模型响应"
return response
# 5. 实战测试
if __name__ == "__main__":
print(api_call_with_throttle("大模型算力节流怎么做?"))
print(f"已使用token:{USED_TOKENS}")七、总结
大模型落地真正的难点不只是会部署模型、会跑推理,更难的是把算力、显存、资源开销管住、控稳、降下来。从GPU显存精细化管控、弹性按需扩缩容,到闲置资源自动释放、量化推理降本,再到API额度节流设计,这是一套从头到尾闭环的算力成本治理体系。通常我们做大模型部署只关注模型能不能跑、效果好不好,却忽略了显存浪费、资源超配、闲置挂机、无节制API调用这些隐形成本,久而久之算力开销会越堆越高,资源利用率却一直偏低。
其实大模型工程落地,七分靠优化、三分靠部署。单纯堆高配GPU根本解决不了成本问题,真正靠谱的做法是显存动态管理、流量弹性调度、闲置自动回收、量化压低占用、API限流节流组合使用,在不牺牲服务质量和推理精度的前提下,实现降本不降质。把监控、量化、限流脚本落地到实际项目,从理论到实战一步步积累,才能真正掌握大模型算力节流的核心能力。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 2
2 0
0- 0



 已为社区贡献58条内容
已为社区贡献58条内容

所有评论(0)