不夸张地说,这篇论文,改变了整个AI的历史走向


2017年,Google团队(含Google Brain和Google Research)与多伦多大学的八位研究者,发表了一篇论文。
标题很嚣张——"Attention Is All You Need"(你只需要注意力)。言下之意:那些复杂的循环网络、卷积网络,统统不需要。
当时没几个人当回事。RNN和LSTM统治了NLP十多年,谁信你靠一个"注意力机制"就能颠覆一切?
结果呢?这篇论文提出的Transformer架构,成了后来所有大语言模型的基石。GPT系列、BERT、Claude、Gemini——全是它的后代。
今天这篇文章,我们不讲公式,不背概念。我们只回答几个问题:Transformer到底做了什么?它为什么能work?那些设计选择背后的Why,到底是什么?
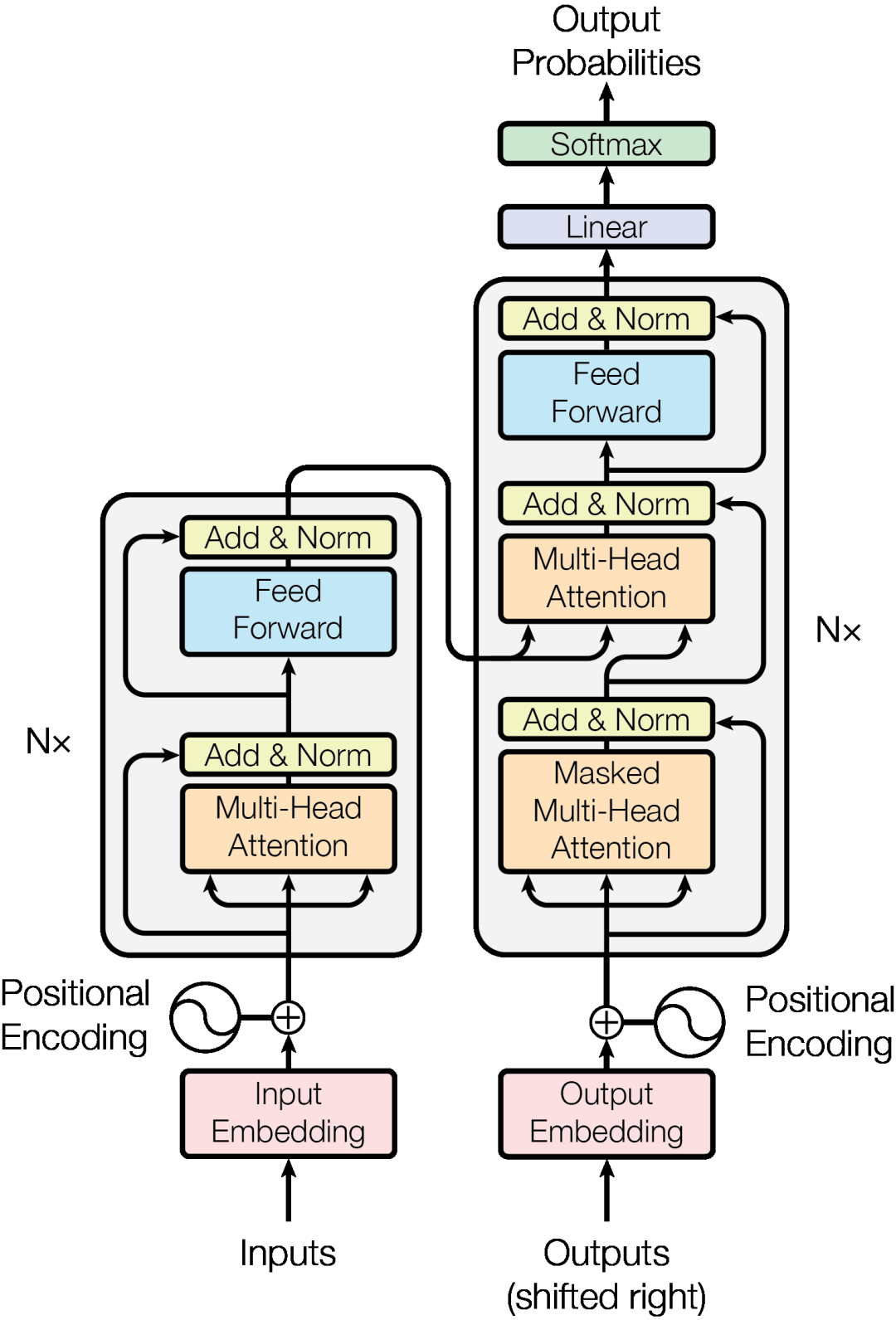
Transformer架构图(来源:原论文Figure 1)
一、先搞清楚:Transformer要解决什么问题?
在Transformer之前,NLP的主流架构是RNN和LSTM。它们的工作方式很直觉——像人读书一样,从左到右一个词一个词地处理。
但这个"从左到右"带来了两个致命问题。
第一个问题:记不住太远的东西。
RNN有一个叫"长期依赖"的毛病。句子一长,网络在处理后面内容的时候,前面信息的"信号"已经衰减得差不多了。就像你读一篇论文,读到第五章的时候,第一章讲了啥已经记不清了。
LSTM通过引入门控机制(遗忘门、输入门、输出门)缓解了这个问题,但只是缓解,没有根治。当你需要处理一段几千字的文章时,LSTM依然会"遗忘"。
第二个问题:没法并行计算。
这个对工程师来说更致命。RNN必须顺序处理:第i个词必须等第i-1个词处理完才能开始。这意味着你有一张价值几万块的GPU,也只能一个词一个词地算,算力完全浪费了。
这两个问题不是"不太方便",而是根本性的瓶颈。第一个问题限制了模型的理解能力,第二个问题限制了训练规模。不解决它们,就不可能训练出今天这样的大模型。
二、注意力机制:一个反直觉的想法
Transformer的核心创新,是提出了一个反直觉的问题:
为什么非要一个词一个词地读?
想象你在读一个句子:"那只猫坐在垫子上,它看起来很开心。"
当你读到"它"的时候,你的大脑不会去逐词回忆"那、只、猫、坐、在……"。你的注意力会直接"跳"到"猫"这个词——因为你瞬间就知道,"它"指的是猫。
这就是注意力机制的本质:不是按顺序处理所有信息,而是让每个词直接去"找"跟它最相关的其他词。
这个想法带来了一个巨大的好处:既然每个词都可以直接看所有其他词,那所有词就可以同时处理——完美并行。RNN的第二个问题,直接消失了。
第一个问题也解决了:不管两个词隔多远,注意力机制都可以直接把它们连起来。不存在"遗忘",因为根本不需要"记忆"——所有信息都在眼前。
三、Q、K、V:用程序员的方式理解
注意力机制的实现用了三个矩阵:Query(查询)、Key(键)、Value(值)。
很多教材会说这是从信息检索系统借鉴来的。但我觉得这个类比还不够直白。让我们换一种方式。
你写过数据库吧?想象一个系统,里面每个词都注册了三条信息:
Key:这个词的"标签"。比如"猫"的标签可能是"动物、名词、可以做主语"。"坐在"的标签可能是"动词、表示动作"。
Query:这个词发出的"查询请求"。比如"它"发出的请求可能是"找一个名词,在前面不远,可能是我的指代对象"。
Value:这个词真正携带的语义信息。这是当别人"查到你"的时候,你给别人看的东西。
计算过程就三步:
1. 每个词用自己的Query,跟所有词的Key做点积,得到一个相似度分数
2. 用softmax把分数变成概率(加起来等于1)
3. 用这些概率对Value做加权求和
最终,每个词都会得到一个新的表示,这个表示融合了整个句子中跟它最相关的上下文信息。
等一下,为什么是点积?
两个向量的点积,衡量的是它们的"方向一致性"。方向越一致,点积越大。所以Query和Key越相似(方向越接近),注意力分数就越高。
但这里有一个问题:如果向量维度很大,点积的值也会很大。值一大,softmax就趋向于"赢者通吃"——最大的那个分数接近1,其他全部接近0。这不是我们想要的。所以论文里除了一个根号d_k(Key的维度),相当于把分数拉回来。
这个细节虽小,但很关键。没有这个缩放,注意力分布会太"尖锐",模型只能关注一个词,失去了综合考虑的能力。
四、多头注意力:为什么要"分头行动"?
Transformer不只用了注意力,它同时用了8个"头"。
为什么不能只用一个头,把所有信息一起处理?
因为语言中的关系是多种多样的。同一个句子中:
"猫"和"它"可能是指代关系
"坐"和"垫子上"可能是动作-地点关系
"开心"和"猫"可能是情感关系
一个注意力头可能只能捕捉一到两种关系。但如果让8个头分别从不同角度去"看"这句话,每个头可以专注于一种关系模式,最后把结果拼起来,信息就更丰富。
一个常见的疑问:每个头的维度变小了(512/8=64),会不会丢信息?
不会。因为8个头的输出会拼接回512维。信息总量没变,只是被"分工"了。这就像把一个项目拆给8个工程师,每个人只需要深入了解一个方面,最后合在一起反而比一个人做所有事情更全面。
从工程角度讲,这还有一个好处:每个头独立计算,可以并行。计算量几乎没增加,但模型的表达能力大大提升。
五、位置编码:没有它,Transformer就是个"瞎子"
这里有一个很多人忽略的矛盾。
注意力机制本身,是完全不考虑词的顺序的。
"猫吃鱼"和"鱼吃猫",在注意力机制看来,词的集合一模一样,词与词之间的关系模式也一样。但意思完全相反。
所以Transformer必须通过额外的方式告诉每个词:"你在第几个位置。"
论文选择的方式是用sin和cos函数生成位置编码,然后加到词向量上。
为什么不直接用数字1, 2, 3...?
两个原因。
第一,简单整数会让模型误以为位置关系是线性的——位置1和2的"距离"等于位置100和101的距离。但语言不是这样工作的。在一句10个词的句子里,位置1和位置3的关系,跟一句100个词的句子里位置50和52的关系,重要性完全不同。
第二,也是更重要的原因:sin和cos有一个漂亮的数学性质。
对于任意固定的偏移量k,sin(x+k)都可以用sin(x)和cos(x)的线性组合来表示。也就是说,模型只需要学习一个线性变换,就能从"位置i的编码"推导出"位置i+k的编码"。
这意味着模型可以自然地理解相对位置关系,而不是死记绝对位置。这对语言的泛化能力非常重要。
一个思考题:后来很多模型(比如GPT-3)改用了"可学习"的位置编码,直接让模型自己学一组位置向量。哪种更好?答案是——可学习的更灵活,但sin/cos的方式有一个优势:遇到训练时没见过的更长序列,sin/cos可以自然外推,而可学习的位置编码会"不知道"第N+1个位置该怎么编码。这也是为什么后来的RoPE(旋转位置编码)试图兼顾两者的优点。
六、残差连接和LayerNorm:深层网络的"保命符"
Transformer的编码器和解码器各堆了6层,每层包含自注意力+前馈网络。GPT-3更是堆了96层。这么深的网络,怎么保证梯度不会在反向传播中消失?
残差连接(Residual Connection)的做法极其简单:把输入直接加到输出上。
也就是 y = F(x) + x
这样一来,即使F(x)学到的变换把信号"搞乱了",x那条直接通道永远在。梯度在反向传播时可以直接沿着x这条"高速公路"跳过中间层,不会消失。
打个比方:残差连接就像在每个楼层修了一个直达电梯。你可以走楼梯(通过F(x)学习),但如果楼梯坏了,电梯还在。
Layer Normalization做的事情更直白。它对每个样本的特征向量做三件事:
1. 减去均值
2. 除以标准差
3. 乘以一个可学习的gamma,加上一个可学习的beta
为什么要这样做?因为经过多层变换后,不同特征维度的数值范围可能差异巨大。就像你同时用"公里"和"毫米"来描述距离——数值差了六个数量级,优化器很难工作。LayerNorm把所有维度拉回到同一个尺度上。
为什么不用Batch Normalization?
BN依赖一个batch内的统计量(均值和方差)。问题在于:batch size小的时候统计量不稳定;而且NLP任务的序列长度不一,不同位置的统计量混在一起没有意义。LN对每个位置独立做标准化,完美避开了这些问题。
另外一个容易忽略的点:原始Transformer用的是Post-LN(先算F(x),再加x,最后做LayerNorm),后来的研究发现Pre-LN(先做LayerNorm,再算F(x),最后加x)训练更稳定。GPT-2之后就全部改成了Pre-LN。一个小小的顺序调整,影响了整个行业的实践。
七、Transformer到底改变了什么?
让我们退后一步,看看Transformer究竟带来了什么。
训练效率的质变。因为完全去掉了循环结构,所有位置可以并行计算。这意味着同样的算力,可以训练大得多的模型。这是GPT系列能够"scaling up"的前提条件。
长距离依赖的彻底解决。不管两个词隔多远,注意力机制一步到位。这比RNN靠"记忆"逐步传递信息的方式强了几个数量级。
架构的统一。在Transformer之前,NLP几乎每个任务都需要定制架构。Transformer出现后,同样的架构加上不同的训练策略,就能处理翻译、摘要、问答、分类……几乎所有NLP任务。这个"通用架构"的理念,直接催生了后来的预训练-微调范式。
2017年的那篇论文,正文不过寥寥数页。但它改变的不是某一个任务的效果,而是整个AI的走向。
从某种意义上说,今天所有的大模型公司,都在做同一件事:用更大的数据、更多的算力,去放大Transformer的潜力。架构本身,从2017年到今天,核心思想没有变过。
这不是夸张,这是事实。
论文链接:https://arxiv.org/abs/1706.03762
kk的大模型论文学习笔记 · 第1篇 · Transformer

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)