数据治理是什么?数据治理怎么做?
最近我发现,身边越来越多企业老板开始焦虑了——
看着别人家的大模型玩得风生水起,自家AI项目却卡在数据这一关动弹不得。花大价钱买的算力设备在机房吃灰,高薪挖来的算法工程师天天吐槽数据没法用。
说到底,不是AI不给力,而是你的数据底子太薄。想卷AI?先把数据治理这堂课补上。
其实,做好数据治理没那么复杂,抓住一个清晰的思路就够了:理、聚、管、治、用。
今天咱就聊聊数据治理这五个步骤。跟着这个思路走,数据治理没那么玄乎。
一、梳理
做数据治理第一步,就是搞清楚自己到底有多少数据。很多企业的数据现状就像乱糟糟的仓库,东西不少,但找起来费劲,用起来更费劲。
1.数据盘点
把散落在各个业务系统的数据全部拎出来,CRM里的客户信息、ERP里的订单数据、财务系统的账目、IoT设备的日志,一个都不能少。
盘点的时候要记录清楚:数据存在哪、什么格式、谁负责、更新频率怎么样、每天产生多少量。建议用表格统一管理,形成数据资产清单。
2.数据分类分级
不是所有数据都一样重要,客户身份证号跟商品评论能一个待遇吗?分类就是按业务维度切分,比如分成营销数据、生产数据、财务数据等。
分级是按敏感程度划分,公开数据、内部数据、机密数据、绝密数据,每一级的访问权限和存储要求都不同。这一步直接决定你后面的安全策略怎么做。
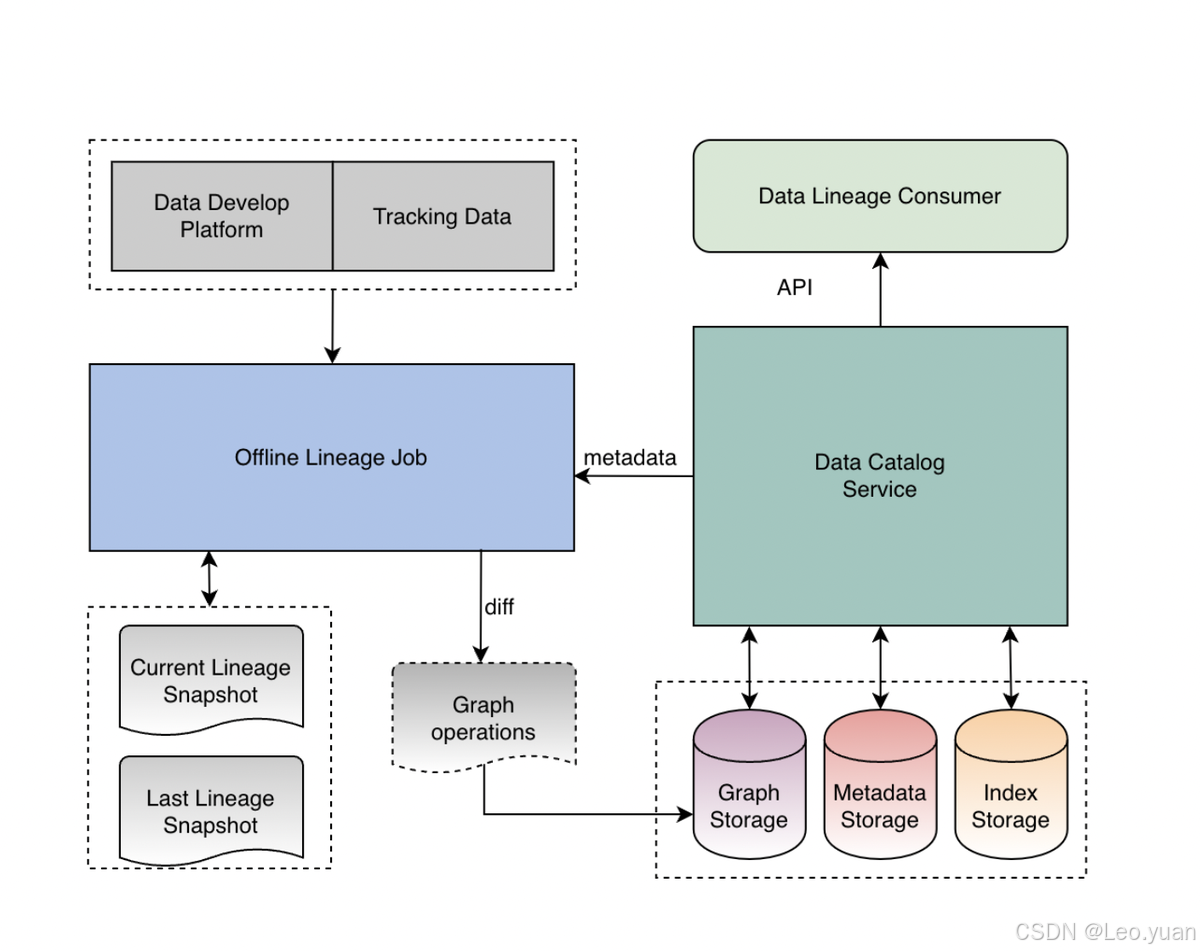
3.数据血缘梳理
数据从哪来、经过哪些加工、最终用到哪去,这条链路必须画得清清楚楚。血缘关系不清晰,出了问题根本没法定位。比如报表数据异常,是源头系统的问题还是ETL脚本的问题?有了血缘图谱,一眼就能看出来。
二、汇聚
数据理清楚了,发现它们各自为政,CRM是CRM的,ERP是ERP的,互相不说话。这就是典型的数据孤岛。数据不聚到一起,治理就是空谈。
数据汇聚分三步走:采集、存储、更新。
1.采集
分三种场景。业务数据库用JDBC直连抽取,日志文件用Flume或Logstash实时采集,API接口数据用定时调度拉取。采集的时候要注意增量还是全量,每天新增数据用增量同步,历史数据定期全量对账。
2.存储
汇聚来的数据先扔进数据湖,保持原始模样。结构化的放Hive,半结构化的放MongoDB,完全非结构化的直接存OSS或S3。数据湖是临时中转站,不是最终目的地,别在里面做复杂计算。
3.更新
这是个大坑。很多系统都是T+1更新,但业务要实时看数据怎么办?核心数据走实时链路,用Kafka+Flink方案;非核心数据走离线链路,用Spark批处理。两条链路要分开,别混用。
三、管控
数据聚起来后,必须立规矩。管数据就是管三件事:标准、元数据、质量。
1.数据标准管理
同一个客户编号,CRM系统是CUST001,ERP系统是KH2024001,财务系统又是C-00001,这种混乱必须终结。要制定企业级数据标准,包括命名规范、编码规则、字典值域。比如性别字段,统一用01男02女,不允许出现男女、M/F、先生/女士等各种写法。标准定了,老系统改造要排计划,新系统必须强制遵守。
2.元数据管理
技术元数据记录表结构、字段类型、存储位置,业务元数据说明指标含义、统计口径、责任人。很多企业的指标口径混乱,销售部门的营收和财务部门的营收永远对不上,就是业务元数据没管好。建议建一个元数据门户,所有数据资产统一查询,像查字典一样方便。每次修改元数据要走审批流程,防止随意变更。
3.数据质量管理
别再说数据质量还行这种模糊话,必须定义质量规则并量化评分。完整性:必填字段空值率不能超过5%。准确性:手机号码必须符合11位规则。一致性:订单状态在上下游系统必须同步。及时性:核心报表必须在早上8点前产出。每个规则配一个质量监控任务,每天跑批,生成质量报告。质量分低于80分的数据,不允许进入数据仓库。
四、治理
管理规矩定好了,但原始数据还是脏的。治数据就是清洗、转换、关联、质检、入库这一系列动作。
1.数据清洗
重复数据要合并,异常值要处理,缺失值要填充。客户表里有三条记录其实是同一个人,手机号一样,地址略有差异,这种要合并成一条。订单金额出现负数,明显是异常,要标记出来人工核查。清洗规则要可复用,别每次都手写SQL,建一个规则库沉淀下来。
2.数据转换
日期格式统一成YYYY-MM-DD,金额统一成两位小数,编码全部按之前定的标准转。转换逻辑要模块化,比如脱敏处理、加密解密、单位换算,做成公共UDF函数,到处都能调用。
3.数据关联
把客户基本信息、交易记录、行为日志、客服工单全部打通,形成360度客户视图。关联键的选择很重要,客户ID、手机号、设备号都可以,但要确保唯一性和稳定性。关联后的宽表是后续分析的基石。
4.数据质检
清洗转换后的数据,要再次跑质量规则,确保达标才能入库。建议设置三重质检:字段级质检、记录级质检、表级质检。字段级看格式,记录级看逻辑,表级看总量和波动。质检不通过,数据要退回源头系统,让业务方整改。
5.数据入库
原始数据放ODS层,清洗后的明细数据放DWD层,汇总数据放DWS层,应用数据放ADS层。每层数据保留周期不同,ODS保留永久,DWD保留三年,DWS保留一年,ADS保留三个月。分层存储既能节省成本,又能提高查询效率。
五、赋能
数据治理的最终目的是用起来。用数据分三个层次:共享、服务、赋能。
1.数据共享
解决内部数据获取难的问题。以前业务部门要个数据,得提工单给IT,排期一周才能拿到。现在要建自助数据平台,业务人员能自己查、自己导。共享要权限可控,敏感数据脱敏后开放,核心数据需要审批。共享平台要有使用审计,谁查了啥数据,什么时候查的,都得记录下来。
2.数据服务
把数据封装成API供业务系统调用。推荐系统需要用户画像接口,风控系统需要反欺诈评分接口,运营后台需要实时数据看板接口。数据服务要高可用,响应时间控制在100毫秒以内,QPS要能支撑业务峰值。服务上线前要压测,上线后要监控。
3.赋能业务
是数据价值的终极体现。数据驱动营销精准投放,转化率提升30%不是梦。数据驱动生产优化,不良率下降5个点很正常。数据驱动供应链,库存周转快一倍。这些场景都需要高质量数据支撑,否则就是空中楼阁。
六、总结
说了这么多,我想你应该明白了,数据治理并不是一锤子买卖,而是持续运营的过程。
所以,别再总说数据治理太虚了,照着这五个步骤一步步来,踏踏实实去做,不用急,三个月就能看见效果。
在这个AI加速发展的时代,数据就是你的石油。但别忘了,再好的石油也得炼化才能用。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)