无需标注,模型也能“三人行必有我师”:哈佛、斯坦福提出对等预测自训练框架

让大型语言模型(LLM)在没有持续人工监督的情况下实现自我提升,是通往更强人工智能的关键瓶颈。 目前主流的后训练方法,如监督微调(SFT)或基于人类反馈的强化学习(RLHF),都高度依赖高质量的标注数据或人工反馈。 这不仅成本高昂,也限制了模型在现实世界中持续学习和适应新知识的能力。
ArXiv URL:http://arxiv.org/abs/2604.13356v1
近期,来自哈佛大学和斯坦福大学的研究者们提出了一种名为 “对等预测自训练” (Peer-Predictive Self-Training, PST) 的新框架,为解决这一难题提供了全新的思路。 PST 的核心思想是,让多个不同的小型语言模型组成一个“学习小组”,在完全没有外部标签和固定“老师”的情况下,通过相互协作和预测来共同进步。实验表明,在多个数学推理基准测试中,PST 能够让 Gemma-2B、LLaMA-1B 和 Qwen-1.5B 等模型在不依赖任何外部监督的情况下,将准确率稳定提升 2.2 至 4.3 个百分点。
这项工作最引人注目的地方在于,它证明了模型可以从彼此的生成结果中提取出有效的监督信号,实现完全自举的、去中心化的学习。它不依赖于更强大的“教师模型”,也不需要预先训练奖励模型,仅凭模型间的互动,就能在公认困难的推理任务上取得稳定进步。
PST 的核心机制:群体智慧与对等预测
PST 框架的设计灵感来源于两个经典概念:群体智慧 (wisdom of crowds) 和 对等预测 (peer prediction)。 群体智慧认为,聚合多个独立或弱相关的预测,通常能得到比单个预测者更准确的结果。 而对等预测则指出,即使没有“标准答案”,通过分析群体内部的一致性,也能评估每个个体答案的质量。
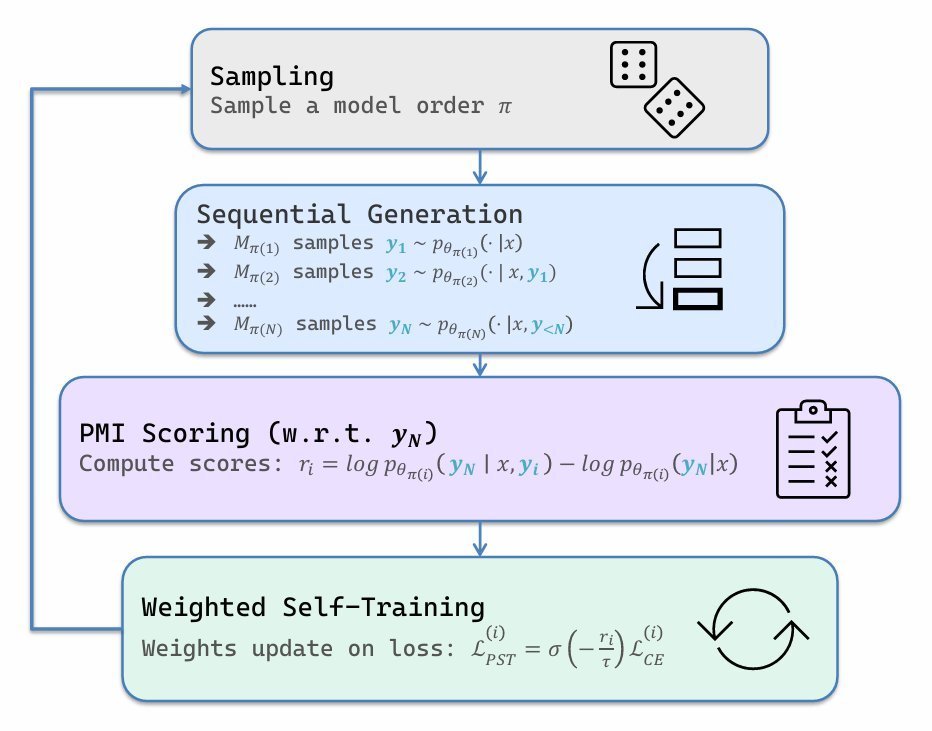
PST 将这两个思想巧妙地结合到了语言模型的自训练中。其具体流程可以分解为以下几个步骤,如下图所示:
-
异构模型组队:首先,选择多个不同架构或规模的语言模型(例如,Gemma-2-2B、LLaMA-3.2-1B 和 Qwen-2.5-1.5B)组成一个学习小组。 这种异构性是关键,因为它能带来多样化的“视角”和推理路径。
-
序贯生成答案:给定一个问题(例如一道数学题),小组内的模型会按照一个随机顺序依次生成答案。后一个模型可以看到前面所有模型的回答,并在此基础上生成自己的答案。
-
聚合答案作为“临时真理”:当最后一个模型生成答案后,它的回答 yNy_NyN 被视为一个“聚合答案”。由于该模型见证了所有“同伴”的思考过程,它的输出可以看作是对群体信息的一次综合,因此通常比任何单个模型的初始回答更可靠。 这个聚合答案 yNy_NyN 在当前训练步骤中,将扮演“伪标签”或内部参考信号的角色。
-
用 PMI 衡量贡献:接下来是 PST 最具创意的部分。对于每一个中间模型 MiM_iMi 生成的答案 yiy_iyi,系统会计算这个答案对于最终聚合答案 yNy_NyN 的信息量。这个信息量是通过 逐点互信息 (Pointwise Mutual Information, PMI) 来度量的。其计算公式为:
ri=logp(yN∣x,yi)−logp(yN∣x) r_i = \log p(y_N \mid x, y_i) - \log p(y_N \mid x) ri=logp(yN∣x,yi)−logp(yN∣x)
直观地解释,PMI ($r_i$) 衡量的是:在已知模型 $M_i$ 的答案 $y_i$ 后,最终聚合答案 $y_N$ 出现的概率提升了多少。如果 $r_i$ 很高,说明 $y_i$ 与最终的“共识”高度一致,是一个很有价值的中间步骤。如果 $r_i$ 很低甚至为负,则说明 $y_i$ 对达成共识没什么帮助,甚至可能是错误的。
- 自适应调整学习强度:最后,PST 利用 PMI 信号来动态调整每个模型的学习权重 αi\alpha_iαi。权重由以下公式给出:
αi=σ(−ri/τ) \alpha_i = \sigma(-r_i / \tau) αi=σ(−ri/τ)
其中 $\sigma$ 是 Sigmoid 函数,$\tau$ 是一个温度超参数。这里的负号是关键:
* 当 PMI ($r_i$) **高**时,意味着模型 $M_i$ 的回答已经很“靠谱”,与群体共识一致。此时,权重 $\alpha_i$ 会变得很**小**,模型在这一步的更新幅度也就很小。这避免了模型在已经掌握的知识上进行不必要的重复学习。
* 当 PMI ($r_i$) **低**时,说明模型 $M_i$ 的回答“离群”或信息量不足。此时,权重 $\alpha_i$ 会变得很**大**,模型会以更大的力度从这次经验中学习,从而被“拉回”到与群体共识更一致的方向。
- 角色轮换:为了保证公平性并避免位置偏见,每个训练周期(epoch)开始时,模型在序列中的顺序都会被重新随机打乱。 这意味着每个模型都有机会扮演最终的“聚合者”角色,也都有机会作为中间的“贡献者”接受评估和更新。
通过这一系列精巧的设计,PST 构建了一个完全自洽的闭环学习系统。它不直接评判答案的对错,而是通过衡量每个“同伴”的回答与最终“集体智慧”的距离,来决定各自应当学习的强度。
实验结果:在数学推理上稳定提升
为了验证 PST 的有效性,研究者在三个主流的数学推理基准数据集上进行了实验:SimulEq(解方程组)、MATH-500-Numeric(数值计算)和 MultiArith(多步算术)。 他们选用了三个不同家族的小尺寸模型:Gemma-2-2B、LLaMA-3.2-1B 和 Qwen-2.5-1.5B。
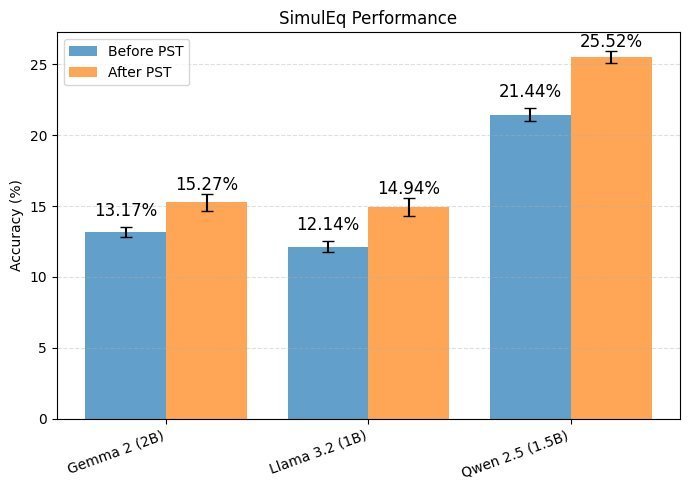
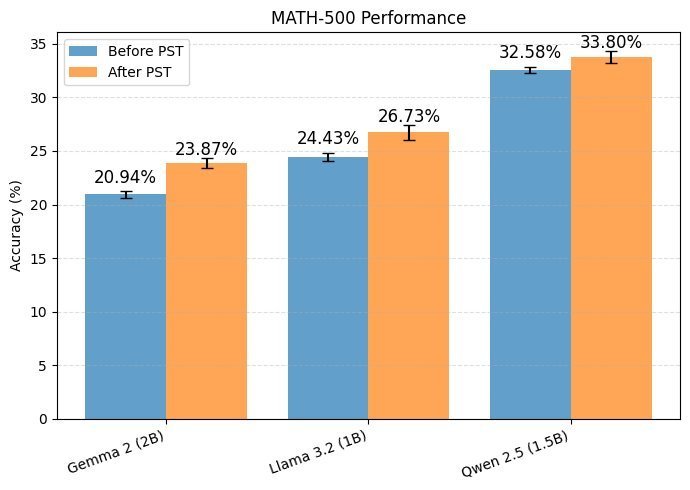
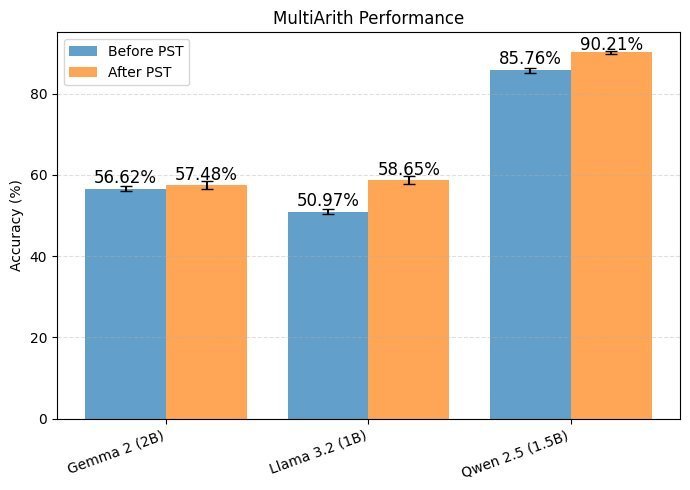
实验结果清晰地展示了 PST 的效果。如上图所示,经过 5 个周期的 PST 微调后,所有模型在三个数据集上的准确率都获得了稳定提升。
-
在 SimulEq 数据集上,模型平均准确率提升了约 3.0 个百分点。
-
在 MATH-500-Numeric 数据集上,平均提升了 2.2 个百分点。
-
在 MultiArith 数据集上,则取得了最显著的进步,平均提升了 4.3 个百分点。
虽然绝对数值的提升看起来不大,但考虑到这是在没有任何外部标注、完全依赖模型间互动的情况下实现的,这一结果相当可观。它证明了 PMI 驱动的对等预测信号足以提供稳定且有效的训练方向。
此外,研究还引入了 生成器-验证器差距 (Generator-Verifier Gap, GV-Gap) 这一指标,用以衡量模型生成正确答案的能力(生成器)和判断一个答案是否正确的能力(验证器)之间的差距。结果显示,PST 训练将这一差距平均减少了 26% 到 40%。 这意味着,通过对等学习,模型不仅提升了答题能力,也增强了自身的“判断力”或“品味”,使其生成和验证能力更加对齐。
PST 为何有效?从生成-验证不对称性说起
PST 的成功可以从“生成与验证的不对称性”这一理论视角来理解。对于许多复杂的推理任务,语言模型“从头生成一个正确答案”的难度,要远大于“判断一个给定的答案是否正确”。PST 巧妙地利用了这一点:即使单个模型难以直接生成正确解,但由多个模型共同合成的聚合答案 yNy_NyN,实际上扮演了一个高质量的“内部验证器”角色。
PMI 权重的调节机制,本质上是在鼓励每个模型去生成那些能够得到“内部验证器”(即群体共识)认可的答案。如果一个模型的回答与最终共识相去甚远,它就会受到更强的“惩罚”(更大的梯度更新),从而学习如何调整自己的推理路径,以更好地对齐群体中最优的验证信号。
论文中的理论分析进一步支撑了这一观点。一个简化的动态系统模型表明,在 PST 框架下,系统的整体“验证能力” v(t)v(t)v(t) 是单调不减的。 这意味着学习过程是稳定的,不会因为错误累积而导致性能退化,从而克服了许多传统自训练方法的主要障碍。
为了进一步证明 PST 的独特优势,研究者还进行了一系列消融实验和基线对比。例如,他们将 PST 与标准的监督微调(SFT)和另一种多模型优化方法 GRPO 进行了比较。结果发现,在所有基准测试中,PST 的性能提升都比这些基线方法更加一致和显著。 这表明 PST 的收益并非简单来自多模型知识蒸馏或更好的奖励设计,而是源于其独特的、基于对等预测的协作学习动态。
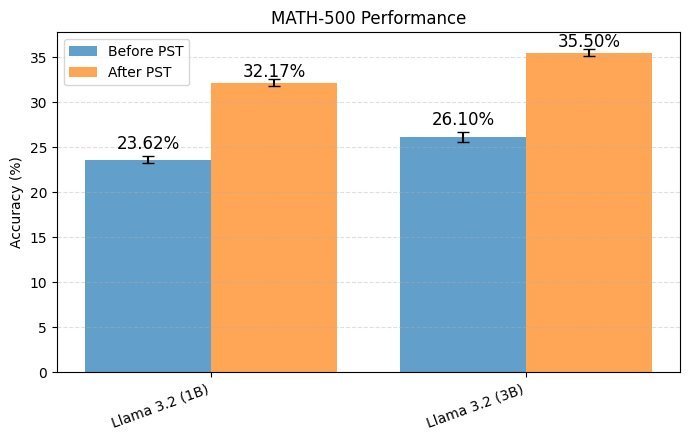
上图展示了一个有趣的消融实验,研究者使用 LLaMA-3.2-1B 和 LLaMA-3.2-3B 两个同家族但不同规模的模型进行 PST 训练。结果显示,即使是较小的模型(1B)也获得了性能提升。这排除了“收益仅仅是小模型从大模型处单向学习”的可能性,证明了 PST 框架中存在真正的双向协作改进。
结论与展望
“对等预测自训练”(PST)为语言模型的无监督自我提升提供了一个简洁而强大的新范式。 它通过聚合多个异构模型的序贯生成,并利用 PMI 信号自适应地调节学习强度,成功地将“对等预测”转化为有效的内部监督信号。
这项研究最重要的贡献在于,它展示了一条完全无需人工标签、无需中心化教师、无需预设奖励模型的模型持续改进路径。 这对于降低大模型训练成本、增强模型在动态环境中的适应能力具有重要意义。虽然目前实验主要集中在中小规模模型和数学推理任务上,但其核心思想具备扩展到更大模型和更广泛任务领域的潜力。
未来的研究方向可以包括探索除 PMI 之外的其他对等预测信号,或者研究更复杂的动态调制机制,以进一步挖掘模型群体协作学习的潜力。PST 的出现,让我们看到了一个由模型自身构成的、能够自我演化和迭代的“学习生态系统”的雏形。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)