从零实现Transformer:第 7 部分 - 集成组件搭建完整模型(Integrating Components to Assemble the Transformer Model)
从零实现Transformer:第 7 部分 - 集成组件搭建完整模型(Integrating Components to Assemble the Transformer Model)
flyfish
完整代码在文末
在前 6 部分构建了所有基础组件后,本部分将集成嵌入层、位置编码、编码器、解码器和投影层,实现完整 Transformer 模型。
看下图 3个注意力已经搞清楚了,如果概念还是不清楚,可以点击 这里理清概念
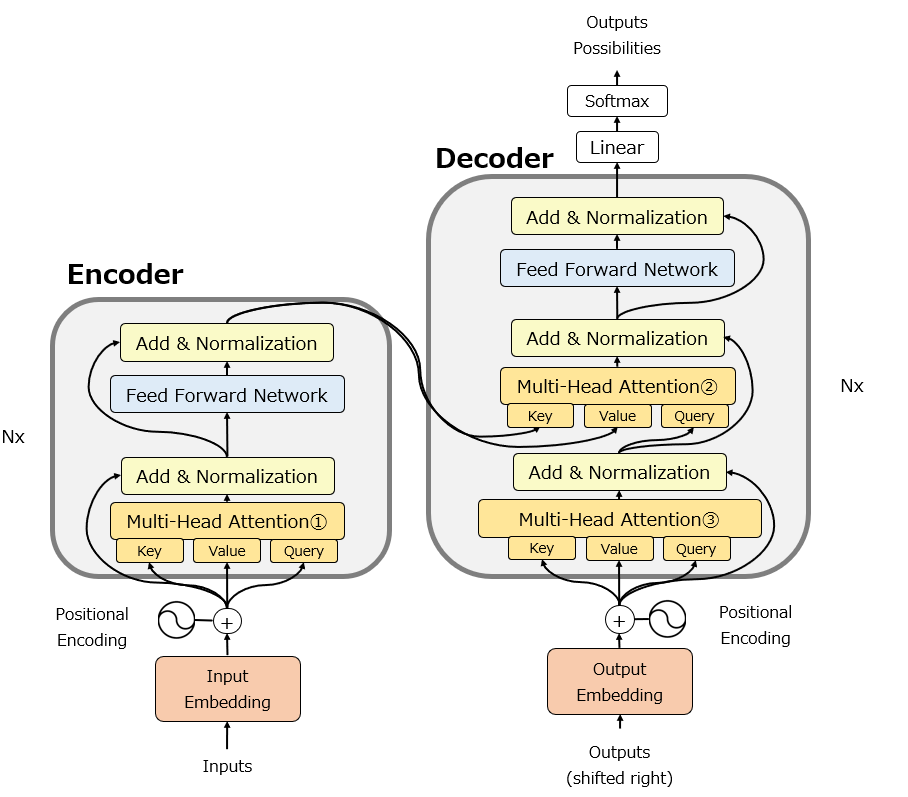
注意看Encoder 和 Decoder 怎么连接起来的
Encoder 和 Decoder没有直接拼接,而是通过 Decoder 里的 Cross-Attention 层做桥梁,经过Encoder (多层 Self-Attention + Feed-Forward)处理后,得到丰富的上下文表示(Encoder Output)。Decoder 的每一层都拿着这个 Encoder Output 当 K/V,和自己的 Q 做注意力计算,从而把源序列的信息传递到解码过程中
左侧(橙色框):Encoder(编码器)
右侧(绿色框):Decoder(解码器)
Encoder 负责理解输入序列(提取特征),Decoder 负责生成输出序列。
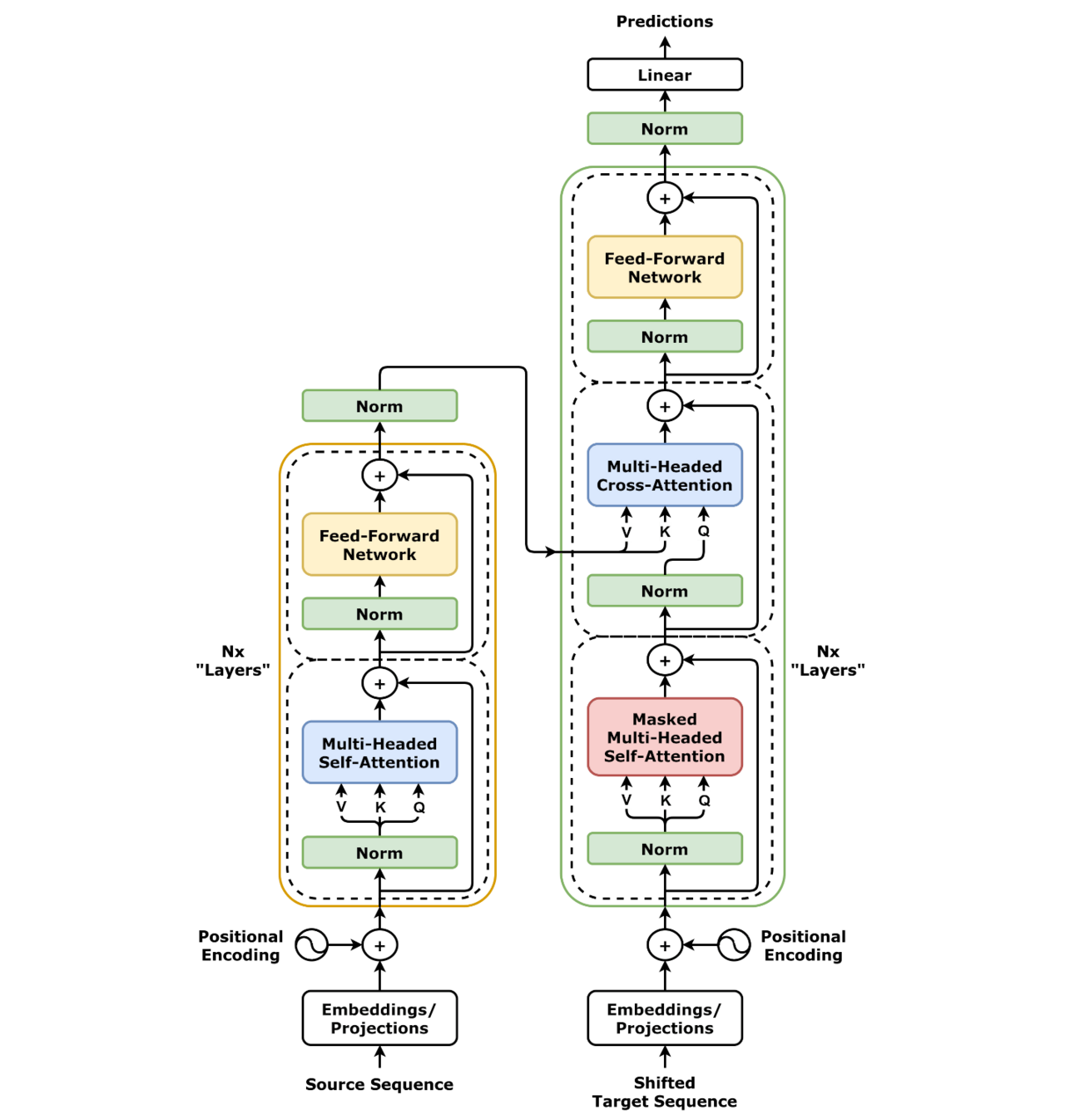
论文《Attention Is All You Need》在 3.2.3 Applications of Attention in our Model 这一节写道:
In “encoder-decoder attention” layers, the queries come from the previous decoder layer, and the memory keys and values come from the output of the encoder.
编码器的输出也可以用如下词表示
the output of the encoder
memory
encoder hidden states
states
encoder outputs
encoder representations 例如下图用states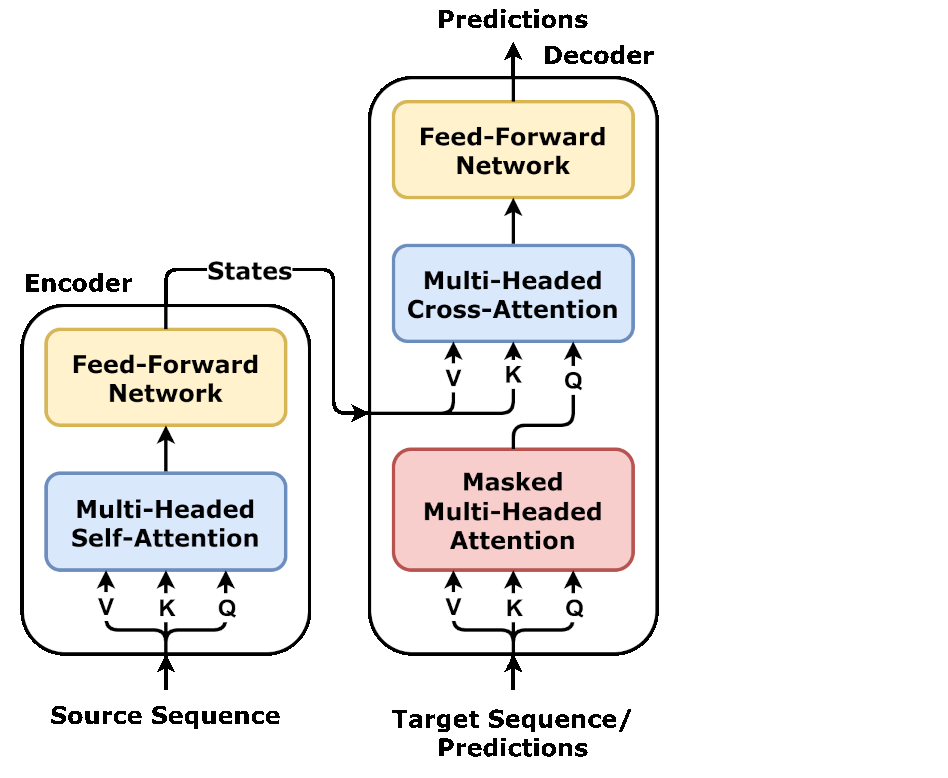
再详细一些涉及到层了
叫法可以是 EncoderBlock ,Decoder Block 或者 Encoder Layer,Decoder Layer
Encoder 的输出(States),直接连到了 Decoder 中每一层 Cross-Attention 的 K(Key)和 V(Value)输入。每一层 Decoder 的 Cross-Attention 使用的 K 和 V 都是相同的。
这份 States 会同时、直接、完全相同地 连接到 Decoder 每一层 的 Multi-Headed Cross-Attention 的 K(Key) 和 V(Value) 输入上。
也就是说:
Decoder 第 1 层 Cross-Attention 的 K、V = Encoder States
Decoder 第 2 层 Cross-Attention 的 K、V = 还是同一个 Encoder States
……(如果是 N=6 层,也全部一样)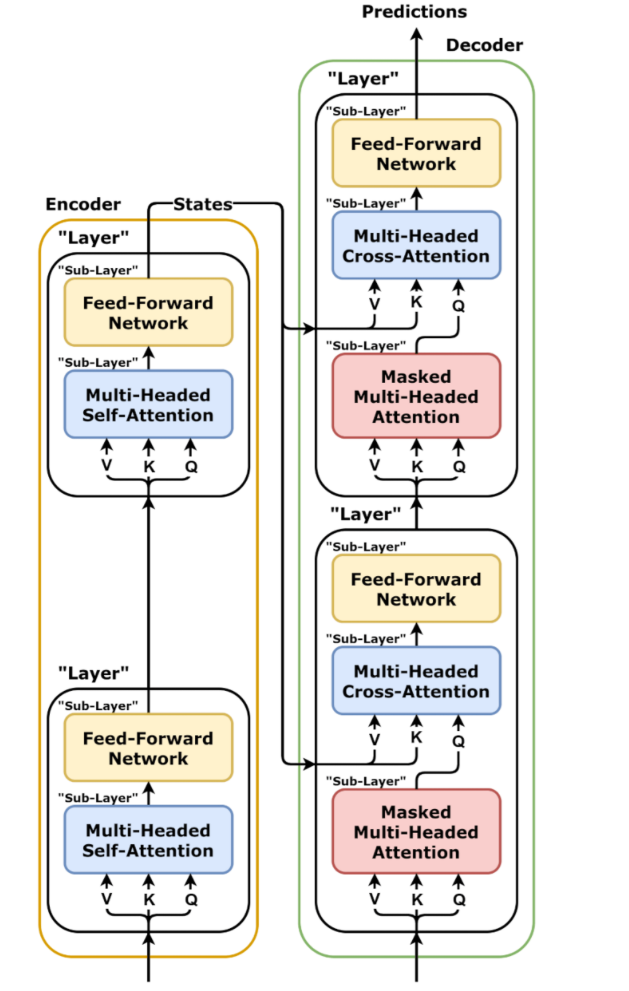
Encoder 是串行堆叠(N 层顺序执行)
Encoder 1 → Encoder 2 → Encoder 3 → … → Encoder N
Decoder 也是串行堆叠(N 层顺序执行)
Decoder 1 → Decoder 2 → Decoder 3 → … → Decoder N
只有 Encoder 的最后一层(Encoder N) 的输出会连接到 Decoder 的每一层 的 Cross-Attention 上。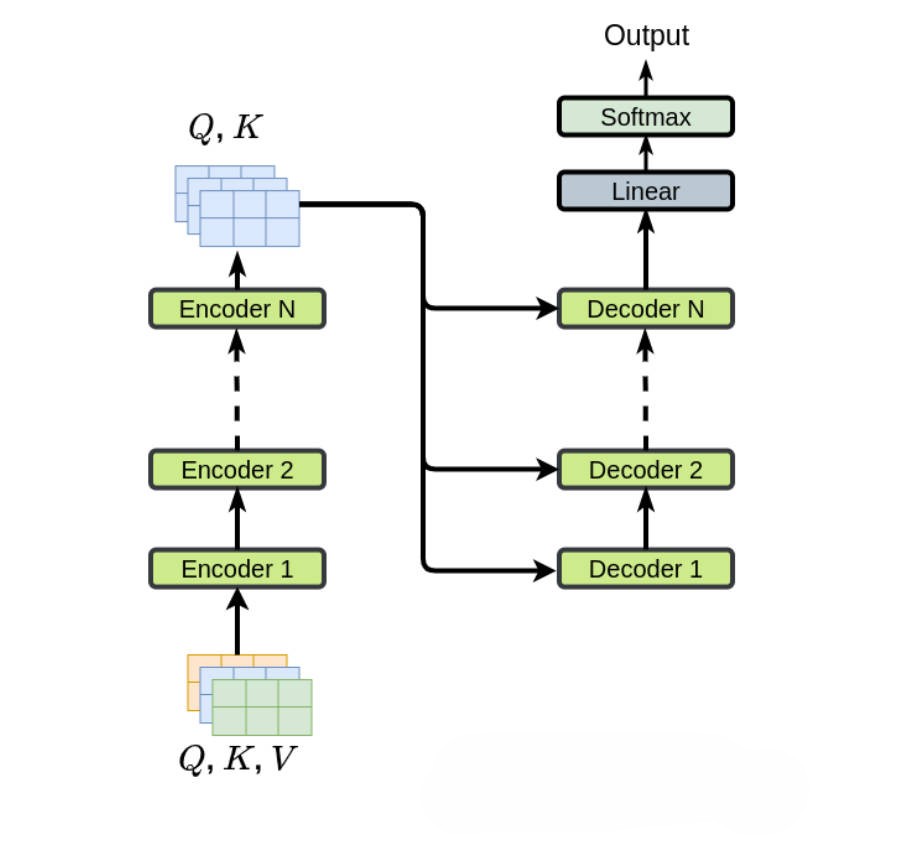
组件1:最终的投影层(Projection Layer)
作用
Decoder 输出的是 [batch, seq_len, d_model] 的特征向量,但需要预测词汇表中每个 token 的概率。投影层完成维度转换:ProjectionLayer 是 Transformer Decoder 的最后一步 —— 输出投影层(Output Projection)。
把 Decoder 输出的隐状态向量(hidden states)转换为词汇表上的 logits(预测分数)。logits 不是概率。它是模型输出的原始未归一化分数。只有经过 softmax(logits) 之后,才会变成真正的概率。
d_model 维特征 → vocab_size 维 logits
它就是一个线性层(Linear Layer):nn.Linear(d_model, vocab_size)
把每个位置的 d_model 维向量,线性映射到整个词汇表的大小。
输出结果称为 logits(未归一化的概率分数)。
后续通常会接 softmax(训练时用 CrossEntropyLoss 会自动处理)来得到每个 token 的概率分布。
PyTorch 实现
class ProjectionLayer(nn.Module):
def __init__(self, d_model: int, vocab_size: int):
super().__init__()
self.proj = nn.Linear(d_model, vocab_size)
def forward(self, x):
return self.proj(x)
加注释
import torch
import torch.nn as nn
class ProjectionLayer(nn.Module):
"""
最终线性投影层:将 Decoder 输出映射到词汇表空间
"""
def __init__(self, d_model: int, vocab_size: int):
"""
Args:
d_model: 模型特征维度(输入)
vocab_size: 目标词汇表大小(输出)
"""
super().__init__()
# 简单线性层:d_model → vocab_size
self.proj = nn.Linear(d_model, vocab_size)
def forward(self, x: torch.Tensor):
"""
Args:
x: Decoder 输出 [batch, seq_len, d_model]
Returns:
logits: [batch, seq_len, vocab_size],未归一化的分数
"""
return self.proj(x) # 线性投影
组件2:完整 Transformer 类
数据流向总览
源序列 src (token IDs)
│
▼
┌─────────────────┐
│ src_embed │ ← 词嵌入 [B, S, d_model]
└─────────────────┘
│
▼
┌─────────────────┐
│ src_pos │ ← + 位置编码 [B, S, d_model]
└─────────────────┘
│
▼
┌─────────────────┐
│ Encoder × N │ ← 使用 src_mask [B, S, d_model]
└─────────────────┘
│
▼ encoder_output
│
目标序列 tgt (token IDs)
│
▼
┌─────────────────┐
│ tgt_embed │ ← 词嵌入 [B, T, d_model]
└─────────────────┘
│
▼
┌─────────────────┐
│ tgt_pos │ ← + 位置编码 [B, T, d_model]
└─────────────────┘
│
▼
┌─────────────────┐
│ Decoder × N │ ← 使用 encoder_output + src_mask + tgt_mask
└─────────────────┘
│
▼ decoder_output [B, T, d_model]
│
▼
┌─────────────────┐
│ Projection │ ← 线性投影 [B, T, vocab_size]
└─────────────────┘
│
▼
logits → Softmax → 下一个 token 概率分布
Transformer 模型的顶层封装类,它把之前写的所有组件(Encoder、Decoder、Embedding、Positional Encoding、ProjectionLayer)组合成一个完整的 Transformer 模型。
Transformer 类实现
class Transformer(nn.Module):
def __init__(self, encoder, decoder, src_embed, tgt_embed, src_pos, tgt_pos, projection_layer):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.src_pos = src_pos
self.tgt_pos = tgt_pos
self.projection_layer = projection_layer
def encode(self, src, src_mask):
src = self.src_embed(src)
src = self.src_pos(src)
return self.encoder(src, src_mask)
def decode(self, encoder_output, src_mask, tgt, tgt_mask):
tgt = self.tgt_embed(tgt)
tgt = self.tgt_pos(tgt)
return self.decoder(tgt, encoder_output, src_mask, tgt_mask)
def project(self, x):
return self.projection_layer(x)
def forward(self, src, tgt, src_mask, tgt_mask):
enc_out = self.encode(src, src_mask)
dec_out = self.decode(enc_out, src_mask, tgt, tgt_mask)
return self.project(dec_out)
class Transformer(nn.Module):
继承 nn.Module,这是 PyTorch 中所有神经网络模型的基类。
def __init__(self, encoder, decoder, src_embed, tgt_embed, src_pos, tgt_pos, projection_layer):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.src_pos = src_pos
self.tgt_pos = tgt_pos
self.projection_layer = projection_layer
初始化函数 __init__:
接收 7 个已经构建好的组件,并把它们保存为类的属性:
| 参数 | 含义 | 作用 |
|---|---|---|
encoder |
Encoder 堆叠(6层) | 理解输入序列 |
decoder |
Decoder 堆叠(6层) | 生成输出序列 |
src_embed |
源语言(输入)的 Embedding 层 | 将 token 转为向量 |
tgt_embed |
目标语言(输出)的 Embedding 层 | 将 token 转为向量 |
src_pos |
源序列的位置编码 | 加入位置信息 |
tgt_pos |
目标序列的位置编码 | 加入位置信息 |
projection_layer |
输出投影层(Linear) | 把隐状态转成词汇表 logits |
def encode(self, src, src_mask):
src = self.src_embed(src) # [batch, src_len] → [batch, src_len, d_model]
src = self.src_pos(src) # 加上位置编码
return self.encoder(src, src_mask) # 通过多层 Encoder
encode 方法:负责编码阶段(Encoder 前向传播)
- 输入的 token ID 序列 → Embedding
- 加上位置编码
- 送入 Encoder 多层处理
- 返回 Encoder 的最终输出(Memory / States)
def decode(self, encoder_output, src_mask, tgt, tgt_mask):
tgt = self.tgt_embed(tgt) # Decoder 输入的 token 做 Embedding
tgt = self.tgt_pos(tgt) # 加上位置编码
return self.decoder(tgt, encoder_output, src_mask, tgt_mask)
decode 方法:负责解码阶段(Decoder 前向传播)
tgt:当前已生成的 target 序列(训练时是 teacher forcing)encoder_output:Encoder 输出的 Memory(K 和 V 来源)
内部会依次经过 Decoder 的每一层(Masked Self-Attention + Cross-Attention + FeedForward)
def project(self, x):
return self.projection_layer(x)
project 方法:把 Decoder 的输出 [batch, tgt_len, d_model] 映射到词汇表维度 [batch, tgt_len, vocab_size],得到 logits。
def forward(self, src, tgt, src_mask, tgt_mask):
"""端到端前向传播"""
enc_out = self.encode(src, src_mask)
dec_out = self.decode(enc_out, src_mask, tgt, tgt_mask)
return self.project(dec_out)
forward 方法(最重要):
这是 PyTorch 模型被调用时(model(...))实际执行的函数。它把整个流程串联起来:
完整流程:
src→ Encoder →enc_outtgt+enc_out→ Decoder →dec_outdec_out→ Projection → logits
完整代码
import torch
import torch.nn as nn
import math
import random
import copy
import time
# ====================== 基础组件 ======================
class InputEmbeddings(nn.Module):
def __init__(self, d_model: int, vocab_size: int):
super().__init__()
self.d_model = d_model
self.embedding = nn.Embedding(vocab_size, d_model)
def forward(self, x):
return self.embedding(x) * math.sqrt(self.d_model)
class PositionalEncoding(nn.Module):
def __init__(self, d_model: int, seq_len: int, dropout: float):
super().__init__()
self.dropout = nn.Dropout(dropout)
pe = torch.zeros(seq_len, d_model)
position = torch.arange(0, seq_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:, :x.shape[1], :].requires_grad_(False)
return self.dropout(x)
def scaled_dot_product_attention(query, key, value, mask=None, dropout=None):
d_k = query.shape[-1]
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask, float('-inf'))
attn = torch.softmax(scores, dim=-1)
if dropout is not None:
attn = dropout(attn)
return torch.matmul(attn, value), attn
class MultiHeadAttention(nn.Module):
def __init__(self, d_model: int, num_heads: int, dropout: float):
super().__init__()
assert d_model % num_heads == 0
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(dropout)
self.attention_weights = None
def forward(self, query, key, value, mask=None):
batch_size = query.shape[0]
Q = self.W_q(query)
K = self.W_k(key)
V = self.W_v(value)
Q = Q.view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
K = K.view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
V = V.view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
output, self.attention_weights = scaled_dot_product_attention(Q, K, V, mask, self.dropout)
output = output.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model)
return self.W_o(output)
class LayerNormalization(nn.Module):
def __init__(self, features: int, eps: float = 1e-6):
super().__init__()
self.eps = eps
self.gamma = nn.Parameter(torch.ones(features))
self.beta = nn.Parameter(torch.zeros(features))
def forward(self, x: torch.Tensor):
mean = x.mean(dim=-1, keepdim=True)
std = x.std(dim=-1, keepdim=True, unbiased=False)
normalized = (x - mean) / torch.sqrt(std ** 2 + self.eps)
return self.gamma * normalized + self.beta
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model: int, d_ff: int, dropout: float):
super().__init__()
self.linear_1 = nn.Linear(d_model, d_ff)
self.linear_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
self.activation = nn.ReLU()
def forward(self, x):
return self.linear_2(self.dropout(self.activation(self.linear_1(x))))
class ResidualConnection(nn.Module):
def __init__(self, features: int, dropout: float):
super().__init__()
self.dropout = nn.Dropout(dropout)
self.norm = LayerNormalization(features)
def forward(self, x, sublayer):
return self.norm(x + self.dropout(sublayer(x)))
# ====================== Encoder & Decoder ======================
class EncoderBlock(nn.Module):
def __init__(self, features: int, self_attention_block: MultiHeadAttention,
feed_forward_block: PositionwiseFeedForward, dropout: float):
super().__init__()
self.self_attention_block = self_attention_block
self.feed_forward_block = feed_forward_block
self.residual_connections = nn.ModuleList([ResidualConnection(features, dropout) for _ in range(2)])
def forward(self, x, src_mask):
x = self.residual_connections[0](x, lambda x_res: self.self_attention_block(x_res, x_res, x_res, src_mask))
x = self.residual_connections[1](x, self.feed_forward_block)
return x
class Encoder(nn.Module):
def __init__(self, features: int, layers: nn.ModuleList):
super().__init__()
self.layers = layers
self.norm = LayerNormalization(features)
def forward(self, x, mask):
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
class DecoderBlock(nn.Module):
def __init__(self, features: int, self_attention_block: MultiHeadAttention,
cross_attention_block: MultiHeadAttention, feed_forward_block: PositionwiseFeedForward, dropout: float):
super().__init__()
self.self_attention_block = self_attention_block
self.cross_attention_block = cross_attention_block
self.feed_forward_block = feed_forward_block
self.residual_connections = nn.ModuleList([ResidualConnection(features, dropout) for _ in range(3)])
def forward(self, x, encoder_output, src_mask, tgt_mask):
# Masked Self-Attention
x = self.residual_connections[0](x, lambda x_res: self.self_attention_block(x_res, x_res, x_res, tgt_mask))
# Cross-Attention (Q from decoder, K/V from encoder)
x = self.residual_connections[1](x, lambda x_res:
self.cross_attention_block(x_res, encoder_output, encoder_output, src_mask))
# Feed Forward
x = self.residual_connections[2](x, self.feed_forward_block)
return x
class Decoder(nn.Module):
def __init__(self, features: int, layers: nn.ModuleList):
super().__init__()
self.layers = layers
self.norm = LayerNormalization(features)
def forward(self, x, encoder_output, src_mask, tgt_mask):
for layer in self.layers:
x = layer(x, encoder_output, src_mask, tgt_mask)
return self.norm(x)
class ProjectionLayer(nn.Module):
def __init__(self, d_model: int, vocab_size: int):
super().__init__()
self.proj = nn.Linear(d_model, vocab_size)
def forward(self, x):
return self.proj(x)
class Transformer(nn.Module):
def __init__(self, encoder, decoder, src_embed, tgt_embed, src_pos, tgt_pos, projection_layer):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.src_pos = src_pos
self.tgt_pos = tgt_pos
self.projection_layer = projection_layer
def encode(self, src, src_mask):
src = self.src_embed(src)
src = self.src_pos(src)
return self.encoder(src, src_mask)
def decode(self, encoder_output, src_mask, tgt, tgt_mask):
tgt = self.tgt_embed(tgt)
tgt = self.tgt_pos(tgt)
return self.decoder(tgt, encoder_output, src_mask, tgt_mask)
def project(self, x):
return self.projection_layer(x)
def forward(self, src, tgt, src_mask, tgt_mask):
enc_out = self.encode(src, src_mask)
dec_out = self.decode(enc_out, src_mask, tgt, tgt_mask)
return self.project(dec_out)
# ====================== 测试完整 Transformer 模型 ======================
print("\n--- 测试完整 Transformer 模型 ---")
# 超参数配置
src_vocab_size = 10000
tgt_vocab_size = 11000
d_model = 512
num_layers = 6
num_heads = 8
d_ff = 2048
dropout = 0.1
max_seq_len = 100
# 创建组件
src_embed = InputEmbeddings(d_model, src_vocab_size)
tgt_embed = InputEmbeddings(d_model, tgt_vocab_size)
src_pos = PositionalEncoding(d_model, max_seq_len, dropout)
tgt_pos = PositionalEncoding(d_model, max_seq_len, dropout)
attention = MultiHeadAttention(d_model, num_heads, dropout)
feed_forward = PositionwiseFeedForward(d_model, d_ff, dropout)
# 构建 Encoder
encoder_blocks = nn.ModuleList([
EncoderBlock(d_model, copy.deepcopy(attention), copy.deepcopy(feed_forward), dropout)
for _ in range(num_layers)
])
encoder = Encoder(d_model, encoder_blocks)
# 构建 Decoder
decoder_blocks = nn.ModuleList([
DecoderBlock(d_model, copy.deepcopy(attention), copy.deepcopy(attention),
copy.deepcopy(feed_forward), dropout)
for _ in range(num_layers)
])
decoder = Decoder(d_model, decoder_blocks)
projection = ProjectionLayer(d_model, tgt_vocab_size)
# 组装完整模型
transformer = Transformer(
encoder=encoder,
decoder=decoder,
src_embed=src_embed,
tgt_embed=tgt_embed,
src_pos=src_pos,
tgt_pos=tgt_pos,
projection_layer=projection
)
# 参数初始化
for p in transformer.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
print(f"模型创建成功,参数量: {sum(p.numel() for p in transformer.parameters()):,}")
# ==================== 虚拟数据测试 ====================
batch_size, src_len, tgt_len = 2, 10, 12
dummy_src = torch.randint(1, src_vocab_size, (batch_size, src_len))
dummy_tgt = torch.randint(1, tgt_vocab_size, (batch_size, tgt_len))
# 掩码
src_mask = torch.zeros(batch_size, 1, 1, src_len, dtype=torch.bool)
look_ahead = torch.triu(torch.ones(tgt_len, tgt_len), diagonal=1).bool()
tgt_mask = look_ahead.unsqueeze(0).unsqueeze(0).expand(batch_size, 1, tgt_len, tgt_len)
print(f"\n输入形状:")
print(f" src: {dummy_src.shape}, tgt: {dummy_tgt.shape}")
print(f" src_mask: {src_mask.shape}, tgt_mask: {tgt_mask.shape}")
transformer.eval()
with torch.no_grad():
enc_out = transformer.encode(dummy_src, src_mask)
print(f"\nEncoder 输出: {enc_out.shape}") # [2, 10, 512]
dec_out = transformer.decode(enc_out, src_mask, dummy_tgt, tgt_mask)
print(f"Decoder 输出: {dec_out.shape}") # [2, 12, 512]
logits = transformer.project(dec_out)
print(f"最终 logits: {logits.shape}") # [2, 12, 11000]
full_output = transformer(dummy_src, dummy_tgt, src_mask, tgt_mask)
print(f"完整 forward: {full_output.shape}")
assert torch.allclose(full_output, logits)
print("\n完整 Transformer 测试全部通过!")
输出
--- 测试完整 Transformer 模型 ---
模型创建成功,参数量: 60,535,544
输入形状:
src: torch.Size([2, 10]), tgt: torch.Size([2, 12])
src_mask: torch.Size([2, 1, 1, 10]), tgt_mask: torch.Size([2, 1, 12, 12])
Encoder 输出: torch.Size([2, 10, 512])
Decoder 输出: torch.Size([2, 12, 512])
最终 logits: torch.Size([2, 12, 11000])
完整 forward: torch.Size([2, 12, 11000])
完整 Transformer 测试全部通过!
下一步预告:训练
第 8 部分 将实现完整的训练流程

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 17
17 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)