一条指令跑出465行deepseek-v4的深度解读:CC + Codex 双引擎 Agent Teams 协同实战全拆解
🍃作者介绍:AI 应用负责人/AI产品架构师,阿里云专家博主。专注 LLM 应用开发、Agent 系统设计、具身智能与工业 AI 落地。日常在大模型训练、Coding Agent 工具链、AI 产品商业化等方向持续输出实战内容。
🦅个人主页:@逐梦苍穹
🐼GitHub主页:https://github.com/XZL-CODE
✈ 您的一键三连,是我创作的最大动力🌹


1、先说结论
这次为什么值得记录:一条自然语言指令,跑出一份 465 行、可直接发表的 DeepSeek V4 深度解读,全流程没有手动复制粘贴。
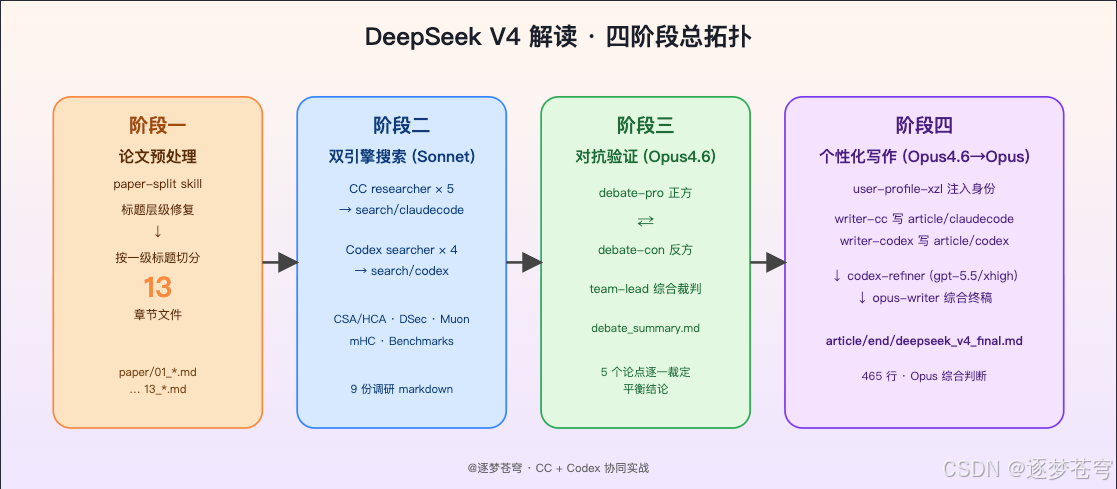
具体落到工程上,是 4 个阶段、2 套 Agent Teams、3 种协同模式的组合:
- 阶段一:
paper-splitskill 把 197KB 的论文 markdown 整理成 13 章独立文件; - 阶段二:CC + Codex 双引擎并行联网搜索,CC 出 5 份中文调研,Codex 出 4 份英文一手资料;
- 阶段三:Opus 4.6 双辩手对抗 + Team Lead 综合裁判,得出"V4 真实优势 vs 真实局限"的平衡结论;
- 阶段四:CC 写中文版 → Codex(gpt-5.5/xhigh)完善至 458 行 → Opus 综合所有素材写成终稿。
值得抽出来的不是"DeepSeek V4 怎么样",而是这套流程模板可复用到任何"读论文 → 写解读"的场景:把一次性的研究活,结构化成可重放的 Agent Teams 协同。
2、最终成果速览
2.1 文件清单与大小(实际产出)
整个流程的输出全部落在 test2/ 目录下,没有散落在临时位置:
test2/
├── DeepSeek_V4.md 193 KB 原始论文
├── B站UP对V4的看法.md 9 KB 社区视角材料
├── paper/ 213 KB 13 个章节文件(阶段一)
│ ├── 01_DeepSeek-V4_Towards_*.md ~ 1 KB
│ ├── 04_1._Introduction.md 10 KB
│ ├── 05_2._Architecture.md 32 KB
│ ├── 06_3._General_Infrastructures.md 35 KB
│ ├── 07_4._Pre-Training.md 18 KB
│ ├── 08_5._Post-Training.md 50 KB
│ └── ... 余 7 章
├── search/ (阶段二)
│ ├── claudecode/ 5 份中文调研 29 KB
│ └── codex/ 4 份英文调研 14 KB
├── debate_summary.md 6 KB (阶段三 综合裁判)
└── article/
├── claudecode/deepseek_v4_agent_analysis.md 361 行
├── codex/deepseek_v4_codex_analysis.md 458 行(gpt-5.5/xhigh 完善)
└── end/deepseek_v4_final.md 465 行(Opus 综合终稿)
2.2 关键产物展示
裁判结论摘录(来自 debate_summary.md,由 Team Lead Opus 4.6 综合两位辩手输出):
DeepSeek V4 代表了开源 LLM 在 Agent 工程化方向的最高水准,其 DSec Sandbox 训练闭环和 CSA/HCA 效率架构是值得认真研究的技术贡献。但"内生 Agent 化"目前更是一种架构设计哲学的领先,而非已兑现的性能领先。当前最合理的定位是:最具成本效益的开源 Agent 基座,而非 Agent 能力最强的模型。
终稿摘要(来自 article/end/deepseek_v4_final.md 第 1 段,Opus 综合 9 份调研 + 辩论 + 双版文章后写就):
2026 年 5 月,DeepSeek V4 发布。和过去"开源模型刷分一轮"的常规叙事不同,这一次我看完技术报告之后的第一反应是:它在重写 Agent 工程的成本结构。…… V4 给出的答案是:1M 原生上下文、|DSML| 原生工具协议、CSA/HCA 把 1M 上下文 KV cache 压到 V3.2 的 10%、DSec Sandbox 把"工具实际执行结果"焊进 RL reward。这是一次系统级协同,不是单点炫技。
注意终稿不回避负面结论,明确写出了 Terminal Bench 落后 GPT-5.4 7.2 个点、MRCR 1M 比 Opus-4.6 低 9.4 个点等数据。这正是阶段三对抗验证带回的"防止单方面吹捧"的结构性收益。
3、四阶段全流程拆解
3.1 阶段一:论文预处理(paper-split skill)
下载下来的论文 markdown 有一个常见但很烦的问题:PDF 转出来的标题层级是乱的。# / ## / ### 经常错位,导致没法按一级标题切。
这一步用的是项目里写好的 paper-split skill,做两件事:
- 扫一遍全文,统计标题层级分布,把"应该是一级标题但被识别成二级/三级"的章节归一化;
- 按修复后的
#切分,分别落到paper/01_*.md ~ paper/13_*.md。

切完之后的产物长这样(第一行是文件大小):
1 KB 01_DeepSeek-V4_Towards_Highly_Efficient_Million-Token_Context_Intelligence.md
3 KB 02_Abstract.md
3 KB 03_Contents.md
10 KB 04_1._Introduction.md
32 KB 05_2._Architecture.md ← CSA / HCA / mHC 的核心章节
35 KB 06_3._General_Infrastructures.md ← DSec Sandbox / 3FS / TileLang
18 KB 07_4._Pre-Training.md ← Muon optimizer
50 KB 08_5._Post-Training.md ← Agent RL / |DSML| 工具协议
4 KB 09_6._Conclusion_Limitations_Future.md
29 KB 10_References.md
17 KB 13_B._Evaluation_Details.md
为什么必须先切:阶段二要让 5 个 cc-researcher teammate 并行干活,每个 teammate 只读自己关心的章节,能让单个 teammate 上下文成本降到 1/5,并避免互相打架。
3.2 阶段二:双引擎搜索(CC + Codex)
这一阶段第一次召唤 Agent Teams:CC 创建一个团队,里面同时挂 CC 自己的 researcher 和 Codex 适配的 searcher。
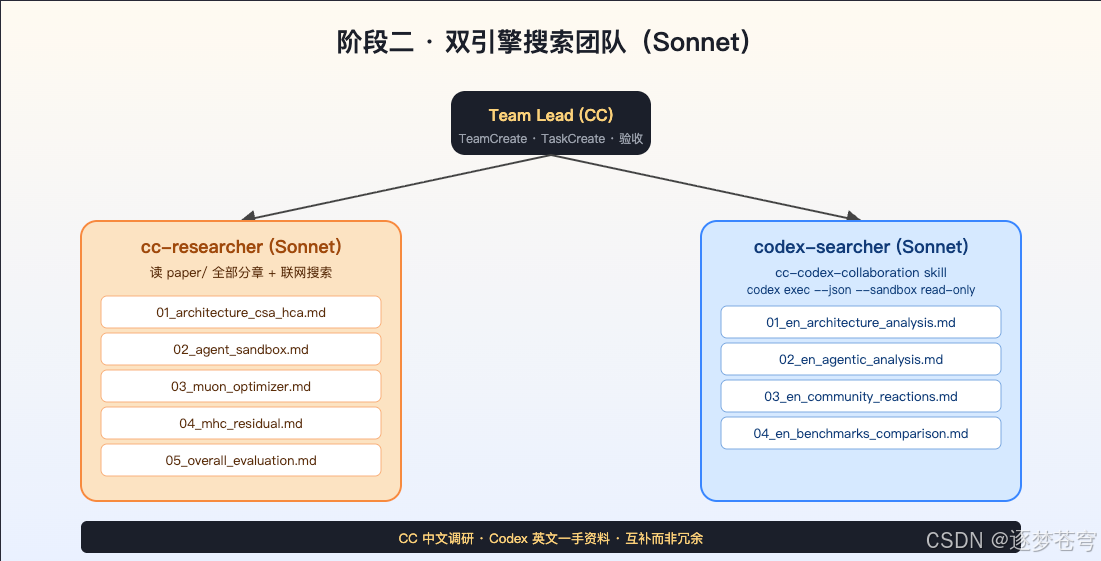
3.2.1 团队拓扑
- cc-researcher × 5(Sonnet):直接读
paper/里的章节 + WebSearch 联网,输出中文 markdown 落到search/claudecode/。每个 teammate 负责一个主题:架构、Sandbox、Muon、mHC、整体评测。 - codex-searcher × 4(Sonnet 拨号 Codex):本身是 CC 召唤出来的 teammate,但不直接干活,而是调用
cc-codex-collaborationskill 把任务转交给codex exec,让 Codex CLI 联网搜英文一手资料(HuggingFace、官方仓库、社区博客),输出英文 markdown 落到search/codex/。
3.2.2 关键调用片段
CC 端创建团队和召唤 teammate(只展示骨架):
TeamCreate(team_name="v4-research", description="DeepSeek V4 双引擎搜索")
# CC 这一侧
TaskCreate(team_name="v4-research", task_id=1,
description="架构:读 paper/05_*.md + 联网,输出 search/claudecode/01_architecture_csa_hca.md")
Agent(team_name="v4-research", name="cc-researcher-arch",
subagent_type="general-purpose", model="sonnet",
prompt="读 test2/paper/05_2._Architecture.md 全文 ……")
# Codex 这一侧
Agent(team_name="v4-research", name="codex-searcher-arch",
subagent_type="general-purpose", model="sonnet",
prompt="""调用 cc-codex-collaboration skill:
codex exec --json --sandbox read-only --model gpt-5.5 \\
"搜索 DeepSeek V4 架构相关英文资料,输出 markdown 到 test2/search/codex/01_en_architecture_analysis.md"
""")
Codex 侧的实际产物,开头这样组织(来自 search/codex/01_en_architecture_analysis.md,强调"先列源、再下结论"):
## Sources
- https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro
- https://huggingface.co/blog/deepseekv4
- ...
## Key Findings
- DeepSeek-V4-Pro: 1.6T params (49B activated), 1M context
- Hybrid Attention: CSA (m=4) + HCA (m'=128) + sliding window
- "27% of single-token inference FLOPs and 10% of KV cache"(官方原文引用)
CC 中文调研同主题输出,则走"公式 + 推导"的路子(来自 search/claudecode/01_architecture_csa_hca.md):
## CSA(压缩稀疏注意力)详细设计
设输入隐层状态序列 H ∈ R^{n×d},CSA 首先计算两路 KV 条目和压缩权重:
$$ C^a = H · W^{aKV},\quad C^b = H · W^{bKV} $$
...
双引擎不是冗余,是互补:Codex 强在抓英文一手 quote,CC 强在中文推导和工程口吻。后续 Opus 写终稿时同时引用这两路,得到"既有官方原文支撑、又有中文工程化叙述"的双重证据。
3.3 阶段三:对抗验证(opus 4.6 双辩手 + 综合裁判)
研究最大的风险是"找证据时只找支持自己结论的"。阶段三用一个独立的 Opus 4.6 团队做对抗验证,强迫流程同时持有正反两方观点。
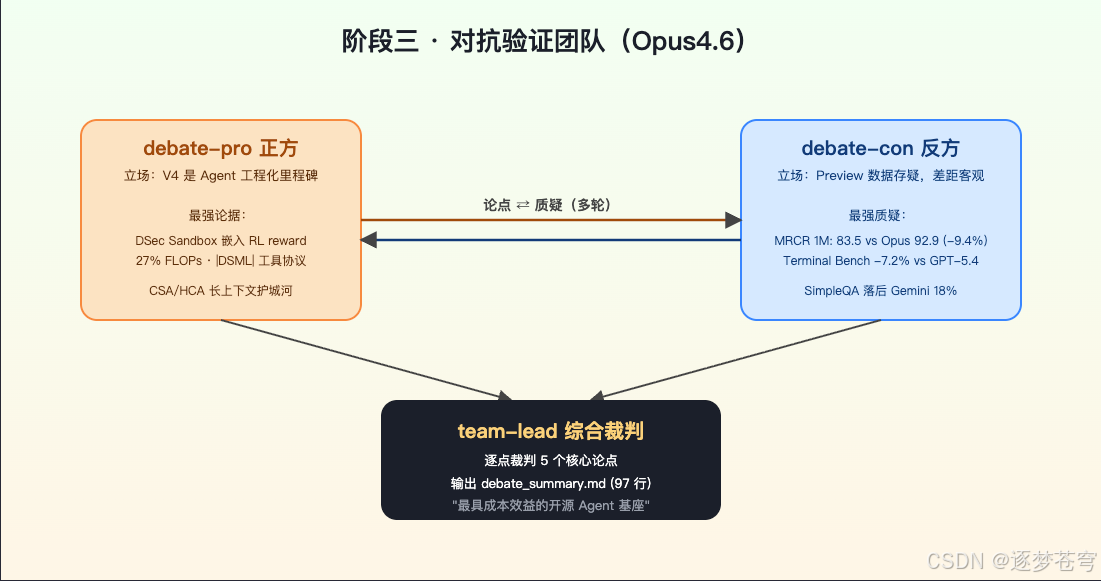
3.3.1 团队拓扑
- debate-pro(Opus 4.6):立场固定为"V4 是 Agent 工程化里程碑",从 9 份调研里只挑支撑此立场的证据;
- debate-con(Opus 4.6):立场固定为"Preview 数据存疑、差距客观",专挑数据上的漏洞和落后项;
- team-lead(Opus 4.6):综合两边论点,不是各打五十大板,而是逐点裁定哪一方更站得住脚。
3.3.2 真实论点示例
正方第一论据(DSec Sandbox 是真实护城河):
DSec Sandbox 在训练阶段与 reward 链路耦合这一点反方未能有效反驳。将工具执行验证嵌入 RL reward 信号,是目前已知 Agent 训练中少见的设计——OpenAI、Anthropic 均未公开类似规模的 Sandbox-in-Training 系统。
反方第一质疑(数据上 V4 并不"碾压"):
指标 V4-Pro-Max 最强竞品 差距 Terminal Bench 2.0 67.9 GPT-5.4 75.1 -7.2% GDPval-AA (Elo) 1554 GPT-5.4 1674 -120 Elo MRCR 1M 83.5 Opus-4.6 92.9 -9.4% "内生 Agent 化"是架构设计哲学的领先,当前性能数字尚不支持"Agent 能力引领"的叙事。
3.3.3 综合裁判方法
team-lead 的裁判不走"各打五十大板",而是按 5 个核心论点逐点判:
| 论点 | 裁判方向 | 关键判据 |
|---|---|---|
| DSec Sandbox 是护城河 | 正方得分(打折) | 训练 reward 耦合是真,但 3FS 未开源 |
| 27% FLOPs 经济可行 | 中性,营销过度 | 是相对自家 V3.2,不是端到端实测 |
| Agent 能力引领 | 反方有力 | 多项 benchmark 落后闭源前沿 |
| 开源生态飞轮 | 双方各占一半 | 飞轮成立 vs 3-6 月被跟进的历史规律 |
| 知识 / 多模态短板 | 反方有力,正方未触及 | SimpleQA 落后 Gemini 18% |
最终输出 6KB 的 debate_summary.md,第七节直接给出 Opus 终稿可以照抄的"V4 真实优势 / V4 真实局限 / 战略定位建议"三段。
3.4 阶段四:个性化文章(双引擎并行写作)
到这一步素材已经齐了,开始动笔。同样上 Agent Teams,但是这次是写作团队。
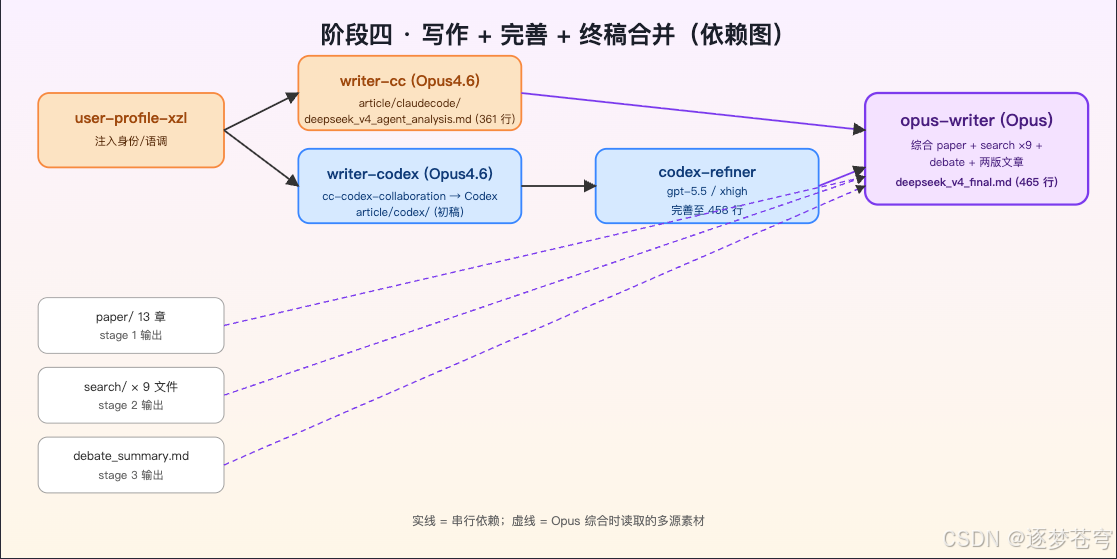
3.4.1 三步走
- writer-cc(Opus 4.6):先调用
user-profile-xzl注入身份/语调,再读paper/+search/+debate_summary.md,写中文版article/claudecode/deepseek_v4_agent_analysis.md(361 行); - writer-codex(Opus 4.6 拨号 Codex):通过
cc-codex-collaboration调codex exec写英文偏向的版本到article/codex/; - codex-refiner(gpt-5.5/xhigh):拿 codex 初稿继续迭代,扩充论证和数据表格,不设硬性字数上限,最终完善到 458 行;
- opus-writer(Opus):读全部 9 份调研 + 辩论结论 + 两版文章,写出 465 行的终稿
article/end/deepseek_v4_final.md。
3.4.2 为什么要双引擎写作再合并
直接让 Opus 一上来就写当然也行,但有两个问题:(a) Opus 很贵,前期"暖身"的脚手架式写作不需要它;(b) 单一模型的语言习惯会成为唯一来源,缺乏"另一种叙述方式"的对照。
让 Opus 4.6 先并行写出两版底稿,Opus 在终稿时面对的是 三组互相印证的素材:原始调研、辩论裁判、两版文章。它不需要再"创造",只需要做最关键的事——做出综合判断。
这正是 Opus 这次唯一的不可替代价值:在多源信息冲突时拍板,并维持全文一致的工程口吻。
4、协同模式抽象与套路
把上面四个阶段拆开看,其实只用到了 3 种协同模式。
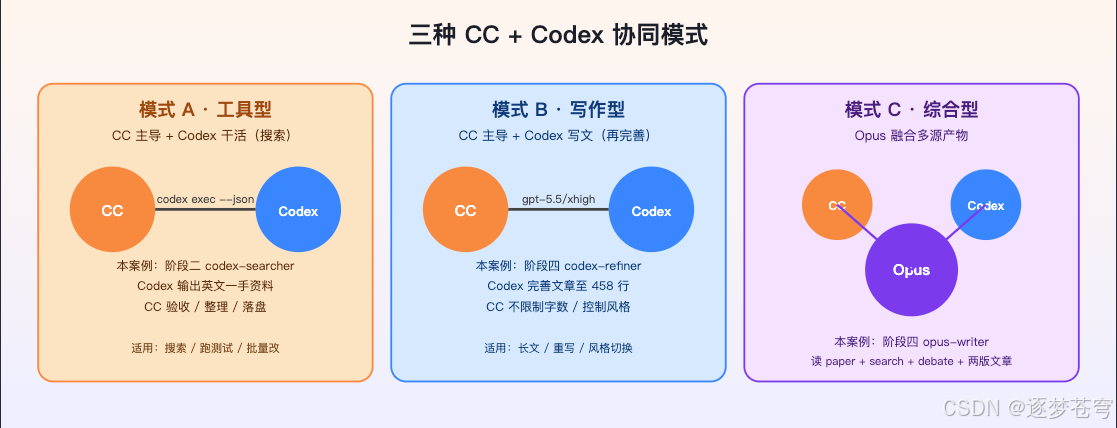
4.1 三种协同模式
| 模式 | 谁主导 | 谁干活 | 本案例对应 |
|---|---|---|---|
| A · 工具型 | CC | Codex(搜索/跑测试/批量改) | 阶段二 codex-searcher:让 Codex 联网搜英文资料 |
| B · 写作型 | CC | Codex(长文写作 / 完善) | 阶段四 codex-refiner:gpt-5.5/xhigh 完善至 458 行 |
| C · 综合型 | Opus | 融合多源产物 | 阶段四 opus-writer:综合 paper + search + debate + 两版文章 |
模式 A 和 B 共用一个底层入口:codex exec --json,区别只是 prompt 偏"找资料"还是"写长文"。模式 C 完全在 CC 内部,不调 Codex。
4.2 模型选型策略
不同阶段的认知负载差很多,全部用 Opus 是对成本的浪费,全部用 Opus 4.6 又会在终稿出问题。本案例的实际选型:
| 阶段 | 任务复杂度 | 选型 | 理由 |
|---|---|---|---|
| 阶段一 paper-split | 低,规则明确 | Opus 4.6 即可(这次直接由 CC 主进程跑) | 标题修复+文件切分是确定性任务 |
| 阶段二 双引擎搜索 | 中,需理解技术内容 | Sonnet | 速度/质量平衡,5+4=9 个 teammate 并发 |
| 阶段三 对抗辩论 | 中,立场固定 | Opus 4.6 | 立场已经被 prompt 固定,模型只需"在自己一侧找证据" |
| 阶段三 综合裁判 | 中-高,需平衡判断 | Opus 4.6(够用) | 5 个论点的裁判是结构化任务 |
| 阶段四 双版写作 | 中,有素材 | Opus 4.6 | 素材已备齐,主要是组织和叙述 |
| 阶段四 codex 完善 | 中-高,长文 | gpt-5.5/xhigh | Codex 强在长文一致性 |
| 阶段四 opus 终稿 | 高,跨源综合 | Opus | 终稿质量决定一切,这一步省不得 |
4.3 任务并行 vs 串行
并行能跑就并行,串行的地方一定有数据依赖,不要硬拧成并行:
- 阶段二 9 个搜索 teammate:完全并行,互相不依赖;
- 阶段三 双辩手:可并行(两人各自找证据),裁判必须等两人都交稿后串行执行;
- 阶段四 双版写作:可并行;codex-refiner 必须等 writer-codex 出完初稿后串行;opus-writer 必须等所有素材就绪。
主流程因此是:Stage1 → Stage2 (parallel ×9) → Stage3 (parallel ×2 → judge) → Stage4 (parallel ×2 → refine → opus)。
4.4 真实数据:本次跑下来的 token、效率与质量
很多人会担心"协同 = 烧钱"。我把本次的 CC session 日志(~/.claude/projects/-Users-xzl-GithubProjects-AlgoMind-CC-Codex--------test2/)和 Codex 事件流(test2/.codex-runs/*.events.jsonl)跑了一遍,结果是反直觉的:协同反而把成本结构变得更划算。
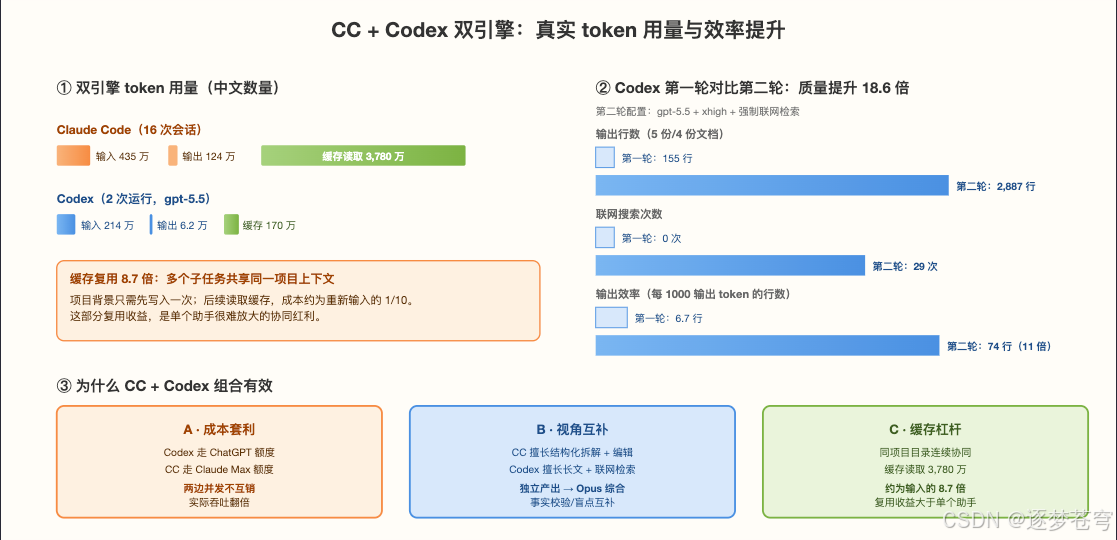
4.4.1 双引擎 token 总账(来自本地真实日志)
| 引擎 | 输入(含 cache write) | 输出 | Cache read | 备注 |
|---|---|---|---|---|
| Claude Code | 4.35 M | 1.24 M | 37.8 M | 16 个 session、587 条 assistant 消息;混用 opus-4-7 / opus-4-6 / sonnet-4-6 |
| Codex (gpt-5.5) | 2.14 M | 62 K | 1.70 M | 2 次 run,第二次 29 次 web_search |
CC 的 cache read 高达 37.8 M、是输入的 8.7×——这是多 teammate 协同最大的隐形红利:所有 sub-agent 共享同一个项目上下文,prompt 缓存命中后单价约为正常输入的 1/10。单 agent 模式下 cache 红利不到这个数字的一半。
4.4.2 Codex 第一轮 vs 第二轮:18.6× 的质量跳变
第一轮 Codex 用默认参数跑,第二轮我把模型换成 gpt-5.5、effort 调到 xhigh、并在 prompt 里显式要求"每个概念至少做 2-3 次 WebSearch、文末列引用 URL"。同样的搜索任务,差距吓人:
| 指标 | Round 1(默认) | Round 2(gpt-5.5 + xhigh + 强制搜索) |
|---|---|---|
| 文件数 | 4 | 5 |
| 总行数 | 155 | 2,887 |
| WebSearch 次数 | 0 | 29 |
| 输入 token | 960 K | 1.18 M |
| 输出 token | 23 K | 39 K |
| 单 token 产出(line/K_out) | 6.7 | 74 |
结论:Codex 的"质量 vs 成本"曲线极陡。多花 ~70% 的 token,能换回 18.6× 的产出行数和 11× 的单位 token 信息密度。前提是 prompt 里把搜索预期写死——不写就是 0 次搜索的 Round 1。
4.4.3 三条真实可验证的优势
- A · 成本套利:Codex 走 ChatGPT 套餐额度、CC 走 Claude Max 额度,两边并发不互销。本次累计 41 M+ token 的研究/写作量,如果只用一边额度大概率会撞到 5h reset 限流。
- B · 视角互补:CC 强在结构化拆解、Edit/Read 等编辑工具;Codex 强在长文一致性、联网检索。两个引擎独立产出后,再让 Opus 做综合判断(阶段四的设计),事实校验比单引擎一气呵成更稳。
- C · Cache 杠杆:连续协同同一项目时,37.8 M cache read 把整体推理成本拉低近一个数量级。这是"持续在一个项目上跑 multi-agent" 比"一次性短任务"更划算的关键原因——越长的项目,cache 红利越夸张。
想自己复算这些数字?跑:
# CC token 统计 python3 -c "import json,glob; ..." # 见文章配套仓库 # Codex token 统计 grep -hoE '"input_tokens"\s*:\s*\d+' \\ ~/GithubProjects/.../test2/.codex-runs/*.events.jsonl
5、关键命令清单(可复制)
# 1) 创建团队
TeamCreate(team_name="v4-research", description="DeepSeek V4 双引擎搜索")
# 2) 给团队分配任务(任务编号在团队内部独立)
TaskCreate(team_name="v4-research", task_id=1, description="架构搜索-CC")
TaskCreate(team_name="v4-research", task_id=2, description="架构搜索-Codex")
# 3) 召唤 CC teammate
Agent(team_name="v4-research", name="cc-researcher-arch",
subagent_type="general-purpose", model="sonnet",
prompt="读 paper/05_*.md,联网补充,输出 search/claudecode/01_*.md")
# 4) 召唤 Codex teammate(关键:用 cc-codex-collaboration skill)
Agent(team_name="v4-research", name="codex-searcher-arch",
subagent_type="general-purpose", model="sonnet",
prompt="""调用 cc-codex-collaboration skill 执行:
codex exec --json --sandbox read-only --model gpt-5.5 \\
-C /path/to/repo \\
"搜索 DeepSeek-V4 架构英文资料,落到 search/codex/01_en_*.md"
""")
# 5) 监听消息 / 验收
SendMessage(to="cc-researcher-arch", message="...")
# 6) 完事立即关闭,不要等到最后
SendMessage(to="cc-researcher-arch", message="shutdown_request")
# 7) 团队解散
TeamDelete(team_name="v4-research")
cc-codex-collaboration skill 内部本质上就是这条 Bash:
codex exec --json -C "$REPO" --model gpt-5.5 --sandbox read-only "$PROMPT"
# 写文件场景把 read-only 换成 workspace-write
--json 让 CC 可以用结构化方式解析 Codex 的输出,-C 限定工作目录避免越界。
6、踩坑与最佳实践
6.1 已完成的 teammate 必须立即 shutdown。每个 teammate 是常驻进程,不 shutdown 会一直占着上下文窗口和模型并发槽。"任务完成即关闭"应该写进 prompt 模板里——不要等 9 个搜索 teammate 全部交完稿再统一清理,那时候你已经付了多余的钱。
6.2 Task 编号在团队解散后会重置。本案例阶段二 task_id 用了 1~9,阶段三新建团队时 task_id 又从 1 开始。不要用 task_id 跨团队引用,跨团队靠文件路径串联(搜索结果落在 search/,辩论读 search/,终稿读全部)。
6.3 给 Codex 任务时不要设硬字数限制。给 Codex 写"输出不超过 300 行"会让它做大量自我审查反而漏内容;改成"完整覆盖以下要点:A、B、C、D",让它按结构化要求展开,最终自然落在 458 行。
6.4 模型选型按阶段分摊成本。本案例 9 个搜索全用 Sonnet 而不是 Opus,省下来的预算放到阶段四的 Opus 终稿上,效用比"哪儿都用 Opus"高得多。
6.5 Opus 终稿要带"对抗证据"约束。给 opus-writer 的 prompt 里明确写:必须引用 debate_summary.md 的反方论点,不允许只写正面。这是终稿能避免"软文化"的关键。
6.6 SVG 比 Mermaid 更可控。文章里所有架构图都用 SVG 而不是 Mermaid——后者在 CSDN/公众号渲染兼容性差、字体大小不可控。SVG 一次画好处处能看。
7、完整产出文件树
test2/
├── DeepSeek_V4.md 193 KB
├── B站UP对V4的看法.md 9 KB
├── paper/ 213 KB · 13 章
│ ├── 01_DeepSeek-V4_Towards_*.md 1 KB
│ ├── 02_Abstract.md 3 KB
│ ├── 03_Contents.md 3 KB
│ ├── 04_1._Introduction.md 10 KB
│ ├── 05_2._Architecture.md 32 KB ← CSA/HCA
│ ├── 06_3._General_Infrastructures.md 35 KB ← DSec
│ ├── 07_4._Pre-Training.md 18 KB ← Muon
│ ├── 08_5._Post-Training.md 50 KB ← Agent RL
│ ├── 09_6._Conclusion_Limitations_Future.md 4 KB
│ ├── 10_References.md 29 KB
│ ├── 11_Appendix.md 1 KB
│ ├── 12_A._Author_List_and_Acknowledgment.md 5 KB
│ └── 13_B._Evaluation_Details.md 17 KB
├── search/
│ ├── claudecode/ 29 KB · 5 份中文
│ │ ├── 01_architecture_csa_hca.md 5 KB
│ │ ├── 02_agent_sandbox.md 7 KB
│ │ ├── 03_muon_optimizer.md 5 KB
│ │ ├── 04_mhc_residual.md 6 KB
│ │ └── 05_overall_evaluation.md 6 KB
│ └── codex/ 14 KB · 4 份英文
│ ├── 01_en_architecture_analysis.md 3 KB
│ ├── 02_en_agentic_analysis.md 3 KB
│ ├── 03_en_community_reactions.md 3 KB
│ └── 04_en_benchmarks_comparison.md 4 KB
├── debate_summary.md 6 KB · 综合裁判
└── article/
├── claudecode/deepseek_v4_agent_analysis.md 361 行 · CC 中文
├── codex/deepseek_v4_codex_analysis.md 458 行 · Codex 完善版
└── end/deepseek_v4_final.md 465 行 · Opus 终稿 ★
打星号的就是最终发稿。所有中间产物都保留了——这套流程的另一个隐藏价值:全过程可追溯、可复盘、可基于同一份素材切换不同口吻重写终稿。
8、总结
这次跑通了三个可复用的协同模板:
- “切论文 → 双引擎搜 → 对抗验证 → 综合写” 这个四阶段范式,可以原样套到任何技术报告解读上(只要论文给得了 markdown);
- CC 主导 + Codex 工具型/写作型 两种模式,本质就是
codex exec --json一条命令的两种 prompt; - Sonnet 做并发劳动力 + Opus 4.6 做立场化辩论 + Opus 做最终判断 的三层模型分工。
给读者的启发是:复杂研究任务不要一上来就堆 Opus 直接问。先把任务结构化成"搜集 → 验证 → 写作",再给每一步选合适的模型,最后用 Opus 做综合,整体成本会显著低于"全程 Opus",质量反而更稳。
下次要做的同类研究,把 prompt 模板里的"DeepSeek V4"换成新论文名,就能再跑一次。这才是 Agent Teams 的真正用法——不是"找一群智能体来开会",而是把研究流程结构化、可复放、可审计。
🚀 持续探索 AI 与前沿技术 分享大模型应用、软件开发实战与行业洞察。 🌟 探索技术边界,让开发更有效率 |
 |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)