π0.7深度解析:为什么它不是“更大的机器人模型”,而是机器人基础模型的一次方法论转向
前言
2026 年 4 月 17 日,Physical Intelligence 发布了 π0.7。如果只看新闻稿、演示视频和社交平台上的几段转述,读者大概会得到一个直观印象:这又是一个更强的机器人模型,能做更多任务、能听更复杂的指令、还能迁移到没见过的平台上。这个印象并不算错,但它明显还不够。因为 π0.7 真正值得分析的地方,不是“又会了几个新技能”,而是它在 PI 整条路线里,到底补上了哪一块此前始终没有被真正打通的能力。
如果继续往下追问,问题会马上变得更具体。π0 到底解决了什么,为什么说它是大规模通用机器人策略的起点;π0.5 为什么要把重点推进到开放世界泛化;π*0.6 为什么明显转向了经验学习和强化学习后训练;MEM 又为什么单独把“记忆”拿出来做成一篇重要工作;而到了 π0.7,它究竟是在做“把 0.6 和记忆拼起来”,还是在做一件更大的事?我对这篇论文的判断是:如果把 π0.7 仅仅理解成“π*0.6 加上记忆模块”,那就低估了它。更准确的说法是,π0.7 把 PI 前几代工作里分散出现的几个关键能力重新组织起来,并把研究重心从“统一任务”推进到“统一条件控制与组合泛化”。这也是本文想重点讲清楚的主线。
如果只用一句话概括 π0.7,那么最准确的说法不是“一个参数更多、任务更强的 VLA 模型”,而是“一个把任务目标、执行风格、行为质量、控制方式和视觉子目标统一写入 prompt 的可操控机器人基础模型”。这一定义比“更大”更重要,因为它改变了机器人学习问题的表达方式。过去许多视觉-语言-动作模型,核心关系仍然是“输入一句指令,输出一段动作”;而 π0.7 试图建立的是“输入任务、上下文、策略偏好与目标状态,再生成动作”的条件化控制框架。它的重点不只是会做更多事情,而是开始学会在更多约束下做事情。
这一步的价值在机器人领域尤其明显。语言模型之所以表现出强泛化能力,一个关键原因是它们不是在背诵固定答案,而是在条件空间里工作;同样地,机器人如果想摆脱对单任务、单平台、单风格数据的高度依赖,就必须从“动作模仿器”转向“条件化行为生成器”。π0.7 的真正突破,恰恰就在这里。它把 prompt 从一行自然语言扩展成了一个多模态控制接口,这个接口既定义目标,也定义过程;既传达“做什么”,也传达“怎么做”;既允许高质量专家示范进入训练,也允许过去常被视为噪声的自主策略数据、不同熟练度的人类演示与跨平台轨迹重新获得价值。

1. 为什么这篇工作值得认真看
机器人领域长期存在一个结构性难题:单点任务性能并不等于通用能力。一个模型在折衣服上表现很好,并不代表它能在厨房、储物间、清洁场景里保持同样的稳定性;一个模型能够执行语言指令,也不代表它能在换平台、换场景、换物体之后维持有效行为;一个模型即便覆盖了许多任务,也可能只是机械地记住了训练分布里的局部模式,而没有形成真正可重组的技能结构。过去很多机器人论文提高的是“某个任务上的成功率”,而 π0.7 更关心的是“模型能否像现代大语言模型那样,把已知能力重新组合,用于新的物理任务”。
这也是官方反复强调 “组合式泛化” 的原因。在语言模型里,所谓组合式泛化往往意味着模型能够把不同知识块重新拼接,例如同时满足格式要求、语言转换要求和内容约束要求;但在机器人领域,这个问题要困难得多,因为组合的不是离散 token,而是带摩擦、碰撞、迟滞和控制延迟的连续物理行为。机器人不能只“理解”任务,还要在实时闭环中把理解转成连续动作,并承受任何错误动作的物理后果。从这个角度看,π0.7 的贡献不在于“证明通用机器人已经实现”,而在于它给出了一条比过去更可信的方法路线:只要训练上下文足够丰富、数据组织足够清晰、系统设计能够支撑高层语义和低层控制协同,机器人模型也可能逐步出现类似语言模型那样的组合能力。
这里还有一层很实际的工程价值:单模型多任务高性能意味着系统部署复杂度会显著下降。如果每类任务都需要单独维护一个 checkpoint、单独调一套超参数、单独处理失败模式,那么模型能力越多,系统工程反而越复杂。π0.7 真正值得关注的地方,是它开始让同一个 checkpoint 在多类任务上接近甚至对标专精策略,这会直接降低测试、部署、维护和持续迭代的成本。换句话说,通用模型的意义不只是“会做更多事”,而是让机器人系统有机会从模型拼装式工程,走向更统一的基础能力平台。
2. π0.7 在 PI 技术路线中的位置
若把 π0.7 单独拿出来看,很容易把它误读为一篇“新模型发布稿”;但如果把它放回 Physical Intelligence 的连续技术路线里,整篇工作的真实定位会清楚得多。π0 代表的是大规模通用机器人策略的起点,核心目标是让一个模型覆盖更多任务和更多机器人。在那个阶段,PI 最重要的工作是先回答一个基础但关键的问题:机器人基础模型有没有可能像语言模型那样,不再被严格绑定在单任务、单平台、单场景上,而是通过更大规模的数据混合,获得一种“广覆盖”的通用控制能力。换句话说,π0 主要是在把“通用机器人策略”这件事立起来,它首先解决的是广度问题,而不是上限问题。它让大家看到,一套统一的视觉-语言-动作框架,确实有机会在许多机器人、许多任务和许多环境之间共享一个底层行为模型。
π0.5 则把问题往前推进了一步。它不再满足于“模型已经能覆盖很多任务”,而是进一步强调让策略能在更复杂、更自然的真实环境中工作,也就是把研究重心推向开放世界泛化。这个阶段最核心的变化,是模型开始更认真地面对真实环境的不规整性:新物体、新布局、新指令表达、新场景组合,以及更长的高层任务链条。也正是在这一阶段,PI 开始更明确地展示分层语义控制、高层子任务表达与开放式指令跟随这些能力的重要性。可以说,π0 解决的是“能不能做得广”,π0.5 则进一步追问“做得广之后,能不能在开放环境里仍然成立”。它让 PI 的路线不再只是一个更大的模仿学习器,而开始带上“开放世界机器人基础模型”的味道。
真正容易被读者混淆的是 π*0.6 和 MEM。很多人会下意识把它们看成同一阶段的连续小修补,但实际上两者各自回答的问题并不一样。π*0.6 更像专家化增强版本,通过强化学习和经验扩充,把若干难任务的吞吐和成功率进一步推高。它的关键词是经验学习、离线 RL、在线后训练和任务性能上限。说得更直接一点,π*0.6 的主要目标并不是解决“泛化解释力”问题,而是解决“模型明明已经会做,但为什么还不够快、不够稳、不够像一个真能长期跑产线和家庭任务的系统”这个问题。它把 VLA 从“能用”继续往“高性能、可打磨、能从经验里持续变强”推进了一截。相对地,MEM 单独把长短期记忆建模拎出来,补的是另一个短板:机器人在真实长时任务里不能只看眼前几帧,短期需要记住遮挡前的局部视觉细节,长期又需要记住已经完成了哪些步骤、哪些区域已经清理过、哪些动作尝试失败过。简言之,π*0.6 先解决的是经验与性能,MEM 解决的是时间尺度与记忆表示,这两条线在 π0.7 之前其实并没有被真正统一为同一个主命题。
所以,到了 π0.7,最需要讲清楚的一点恰恰是:**它当然可以被粗略地理解为“把 0.6 的强化学习成果和 MEM 的记忆能力合并到同一代模型里”,但这还不是它最重要的地方。0.7 的核心不是简单加模块,而是把 PI 过去几代模型里已经证明有效的能力,重新组织成一个面向泛化的新问题:如何让同一个机器人基础模型,在多样化、异构、甚至质量参差不齐的数据上学习,并通过更丰富的 prompt 与上下文条件,表现出更强的组合式泛化能力。**这也是为什么我更愿意把 π0.7 理解为一次研究重心的转换:它不只是继续提升任务上限,也不只是把记忆加回来,而是把“泛化能力为什么之前起不来”这个问题正面摆到桌面上,并给出一个系统性答案。这个答案的关键词不是单纯的 RL,也不是单纯的 memory,而是 richer context、steerable prompting、subgoal image、metadata conditioning,以及在这些条件下对大规模异构数据的重新利用。
如果再把这条路线压缩成一句最便于记忆的话,可以这样理解:π0 先把“通用机器人策略”做出来,π0.5 让它更像一个面向开放世界的系统,π*0.6 让它在难任务上真正变强,MEM 让它开始具备长时任务所需的多尺度记忆,而 π0.7 则把这些分散能力重新收束成一个新的中心命题,即让模型不仅 general-purpose,而且 steerable;不仅能执行任务,而且能在更丰富的条件约束下、从更复杂的数据结构中学会泛化。从这个角度看,π0.7 最主要的工作,确实如你所说,不是“终于把记忆也接进来了”这么简单,而是“在吸收前面各代能力的基础上,集中提升泛化能力,尤其是组合式泛化与条件化控制能力”。只有先把这一层关系看清,后面再去读它的 prompt 设计、世界模型、训练配方和实验结果,才不会把整篇论文看成一组零散技巧的堆砌。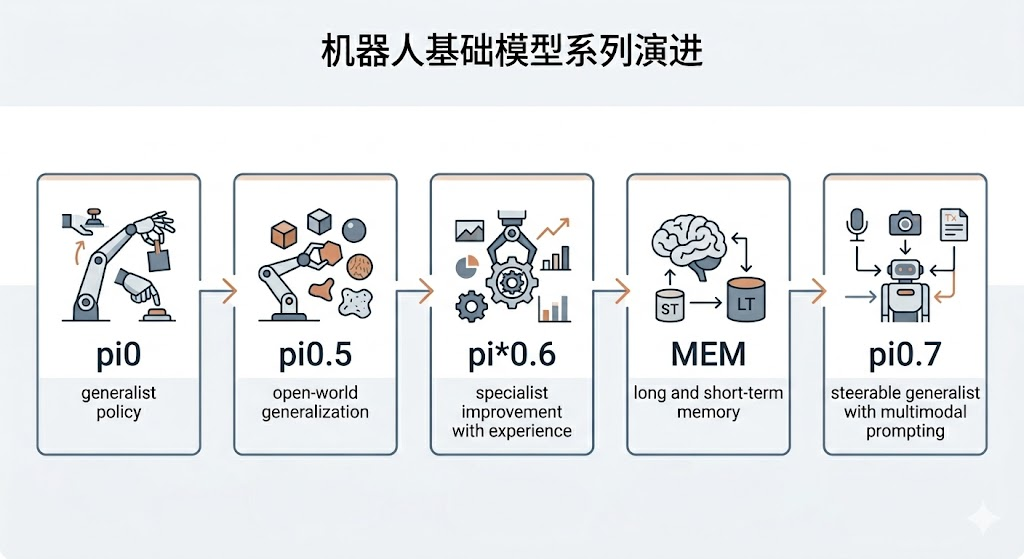
3. π0.7 到底是什么
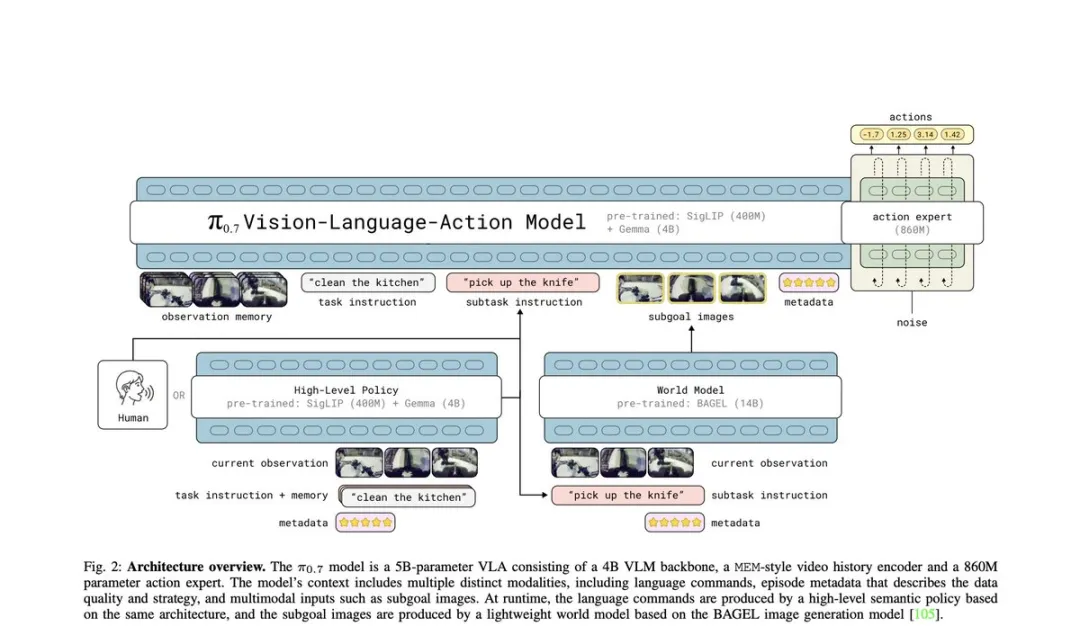
按照论文的定义,π0.7 是一个约 50 亿参数级别的视觉-语言-动作模型。其核心由三部分构成:第一是基于 Gemma 3 初始化的 40 亿参数视觉-语言主干;第二是继承自 MEM 思路的视频历史编码机制,用于在有限 token 开销下保留更长时域的观测信息;第三是一个约 8.6 亿参数的 flow matching 动作专家模块,用于在条件语义表示的基础上生成连续动作块。这种结构说明,π0.7 并不是把所有能力粗暴塞进一个统一头里,而是明确区分了“多模态条件理解”和“动作轨迹生成”这两类任务。
模型更重要的变化发生在输入端。与许多传统 VLA 模型只接收一句任务文本不同,π0.7 在推理时可以同时接收以下几类信息:完整任务指令、当前子任务语言描述、episode metadata、控制模式标签以及视觉子目标图像。于是,模型 不再只依据“clean the table”或“put the object in the container”这样的简短句子盲目推断整个动作序列,而是在更明确的上下文约束下生成行为。对于机器人控制来说,这个变化非常关键,因为动作本身往往是歧义极高的:同一项任务可以有不同速度、不同安全边界、不同抓取策略和不同空间路径。只靠一句任务描述,模型很容易学成“平均策略”;多模态条件化则为它提供了更窄、更明确的行为目标。
4. 真正的创新点:prompt 被重新定义了
很多读者第一次看 π0.7 时,会自然把注意力放在“4B 主干”“8.6B 动作专家”“world model”这些看起来更显眼的技术点上,但从方法论角度看,整篇工作最重要的一步 其实是 prompt 定义方式的改变。过去机器人模型里所谓 prompt,往往只是任务语句,最多附加一点环境说明;而在 π0.7 里,prompt 被扩展成一个完整的控制语境。它不是只回答“要做什么”,还要回答“以什么速度做”“质量标准是什么”“当前动作应当遵循哪类控制接口”“这一阶段结束后场景应当长成什么样”。一旦这些约束显式进入模型输入,训练数据的解释方式就被彻底改变了。
这件事之所以重要,是因为机器人数据天然异构。人类演示和自主策略数据质量不同,熟练操作员和普通操作员风格不同,不同机器人平台的控制空间不同,同一个任务在不同环境中又会产生大量细微差异。如果训练过程不把这些差异显式标出来,模型只能做一件事:对一切现象求平均。平均行为在语言模型里也许只是答得更平庸,在机器人里却会变成犹豫、迟钝、抓取点不稳定、路径选择含糊,甚至在关键接触瞬间出现不可恢复的失败。π0.7 的方案不是回避这些差异,而是把它们转化为上下文条件,让模型知道当前应该跟随哪一种行为模式。
下表可以帮助理解 π0.7 的 prompt 结构到底在解决什么问题:
| 组件 | 具体含义 | 作用 |
|---|---|---|
| 任务指令 | 最终任务目标 | 定义全局意图 |
| 子任务语言 | 当前阶段要完成的动作语义 | 支撑长任务分解与阶段切换 |
| 视觉子目标 | 当前阶段结束后“应看到的画面” | 提供语言无法精确定义的几何约束 |
| Episode metadata | 速度、质量、是否有错误等属性 | 让不同质量和风格的数据可共同训练 |
| 控制模式 | 关节空间控制或末端执行器控制 | 统一不同平台和不同控制接口的数据 |
从这个表可以看出,π0.7 的 prompt 已经不是“提示词工程”意义上的 prompt,而更接近“行为规范接口”。它把原本隐含在演示数据中的许多行为属性显式化,并且允许这些属性在训练和推理两个阶段都持续起作用。对于机器人学习来说,这本质上是一种数据治理方式,而不仅仅是一种模型输入方式。
5. 为什么 π0.7 能把“过去不好用的数据”重新变成资产
论文在数据层面的一个重要判断是:多样化数据并不会自动带来泛化,如果只是机械地把各种来源的数据混合在一起,结果往往是策略退化而不是变强。这个判断非常关键,因为机器人社区长期面临的现实就是,数据虽然越来越多,但可直接用于稳定训练的数据仍然有限。高质量双臂遥操作演示很贵,覆盖全任务全场景几乎不可能;自主策略评估数据虽然量大,却常常混有低质量片段;不同平台的开源数据控制空间不一致;人类第一视角视频虽有丰富任务知识,却没有可直接执行的机器人动作。传统做法往往是尽量筛数据、删噪声、保“纯净”,但这样又会把大量真实世界经验排除在外。
π0.7 试图改变这一局面。它的逻辑不是“只留完美数据”,而是“让模型知道每份数据的不完美体现在哪里”。例如,一段自主策略数据也许速度慢、质量一般、局部动作有瑕疵,但它依然可能包含有效的抓取、放置或开门片段。如果训练时附上速度档位、质量等级和是否犯错等 metadata,模型就不必把这段数据与高质量专家演示混为一谈,而可以在学习时保留其有用部分,并学会在不同条件下调用不同风格的行为模式。对于机器人数据而言,这种条件化学习比简单筛选更接近现实,也更具规模化潜力。
论文里的数据来源大致包括以下几类:高质量遥操作演示、自主策略评估轨迹、不同机器人平台的既有内部数据、开源机器人数据集、人类第一视角视频以及额外的网络多模态数据。真正新颖的地方不在于“用了很多数据”,而在于这些数据第一次被统一放进一个能解释它们差异的上下文系统里。换言之,π0.7 的泛化能力不只是规模带来的结果,更是数据条件化组织方式的结果。
Quan Vuong 在分享里提到的一个实验现象,可以把这个问题讲得更直观:如果只把训练数据从较高质量的 80% 扩到 100%,也就是把更多低质量轨迹直接混进来,未使用 metadata 的模型性能反而会明显下降;但在同样纳入低质量数据的情况下,带 metadata 的 π0.7 性能却能继续上升。这个对照非常关键,因为它说明 π0.7 并不是在重复“数据越多越好”的老叙事,而是在证明另一件事:机器人数据能否规模化,取决于模型有没有能力理解数据之间的质量差异、风格差异和执行条件差异。没有这套条件化机制,低质量数据会变成噪声;有了这套机制,低质量数据里仍然有机会被抽取出可复用经验。
这也能和 PI 之前的 RL Token 实验现象接上。分享里提到,仅用遥操作数据训练出的基础策略,执行速度反而低于人类遥操作本身;而经过在线强化学习优化后,策略速度可以超过人类基准。这个现象说明,机器人策略并不会天然复现数据里的最好行为,普通行为克隆很容易学到保守、迟疑、平均化的动作模式。π0.7 把速度、质量和错误信息写入 metadata,本质上是在给模型提供一种行为选择信号:不要只学习“数据里发生了什么”,还要知道“哪些行为更快、更稳、更值得在推理时被放大”。这也是 metadata 不应被理解成附属标签的原因。
6. metadata 不是附属标签,而是训练策略的核心
如果必须在 π0.7 的设计里选出一个最容易被低估的点,我会选 episode metadata。很多读者会天然把它理解成“可有可无的额外标签”,但从整篇论文的实验逻辑来看,它实际上是 π0.7 能够吸收混合质量数据的关键机制。论文中提到,metadata 至少包含三类信息:速度、质量和 mistake 标签。速度不是连续值,而是按 500 步分箱的离散信息;质量是 1 到 5 的打分;mistake 则标注轨迹中是否出现明显错误。这种设计看似简单,却有很强的工程含义:它把原本模糊的“这段轨迹好不好”“快不快”“稳不稳”转成了模型能直接利用的监督条件。
更重要的是,metadata 在推理阶段并不是摆设。论文明确写到,测试时会向模型指定理想的 metadata 条件,也就是“高质量、高速度、无错误”的目标属性,然后通过 classifier-free guidance 进一步强化这些条件信号。也就是说,π0.7 并不是训练时学过 metadata,部署时却忘掉它;相反,metadata 在训练和部署两端都参与行为塑形。这很像现代生成模型里的条件控制:你不是要求模型无条件生成“平均结果”,而是要求它在某类明确期望下生成特定结果。把这一思路放进机器人控制里,是 π0.7 相较许多早期 VLA 模型最值得借鉴的地方。
7. 视觉子目标为什么是整篇论文的另一根主轴
语言擅长表达抽象任务目标,但不擅长表达几何细节。对于机器人来说,很多决定成败的关键信息恰恰落在几何细节上。例如夹爪要从哪一侧接近杯柄、折叠衣服时边缘要如何对齐、把物体放入狭窄空间时末端姿态应当如何变化,这些信息如果全靠自然语言描述,不仅表达冗长,而且很难保持精确。π0.7 的做法是引入视觉子目标,让模型不仅知道“当前状态”,还知道“下一阶段结束时理想状态应当看起来像什么”。
从控制角度看,这会把动作生成问题从“根据一句任务描述猜整条轨迹”转成“在当前观测与目标观测之间求一段可行过渡”。这实际上大大缩小了动作搜索空间。论文进一步指出,加入子目标图像后,动作学习更接近 inverse dynamics 问题,因此训练速度明显提升。作者没有让所有样本都依赖子目标图像,而是只在约 25% 的训练样本中使用视觉子目标,以免模型在推理时过度依赖这一信号。这个细节很能说明团队的设计思路:它并不是简单把所有上下文堆满,而是在“有用”和“可缺省”之间维持平衡,使模型既能充分利用子目标,也能在子目标缺失时继续工作。

论文对视觉子目标的使用还体现出很强的系统意识。子目标并不是静态给定,而是由世界模型依据当前子任务语言和当前状态动态生成。对于环境视角相机,子目标画面描述的是下一阶段接近完成时的整体布局;对于腕部视角,子目标更接近抓取或接触瞬间的局部几何状态。这意味着子目标图像承担的不是普通插图作用,而是真正参与在线控制闭环的条件变量。
8. 从 VLA/WAM 之争退到表征学习
如果把视角再放大一点,π0.7 最值得讨论的地方并不是它到底属于 VLA 还是 WAM。这个二分法很容易把问题带偏,好像路线选择本身比模型到底学到了什么更重要。更本质的问题应该是:机器人策略到底应该基于什么样的中间表征做决策。一个好表征既不能只是当前图像的压缩,也不能只是语言指令的语义向量,更不能只是训练动作的统计平均;它必须包含与未来物理变化、任务阶段、可行动作和质量偏好有关的信息。
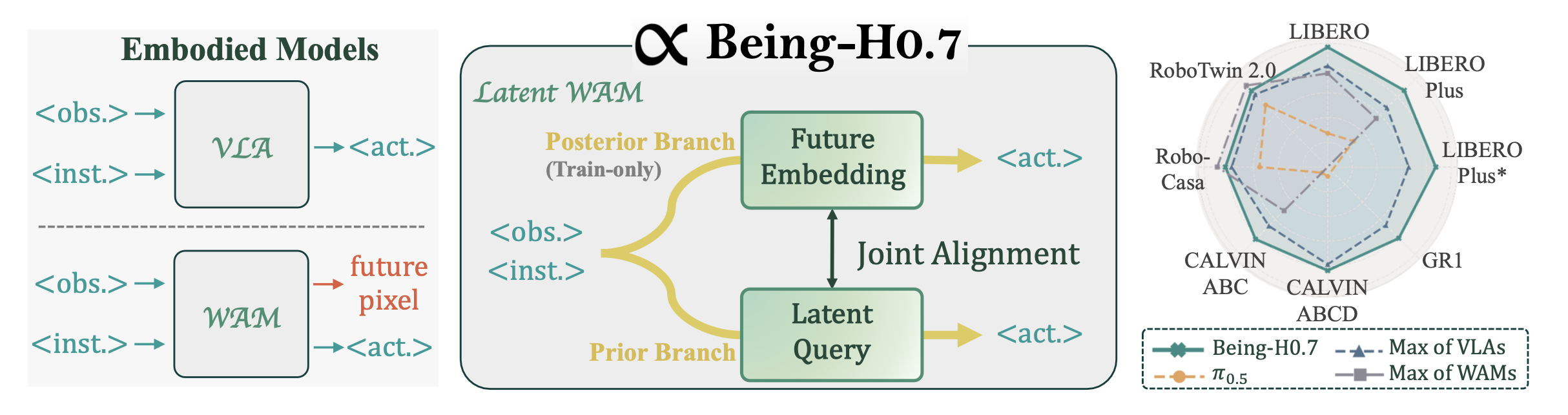
这也是近期几条路线正在收敛的地方。Being-H0.7、Fast-WAM 和 π0.7 表面上站在不同阵营:Being-H0.7 更像 latent WAM,Fast-WAM 讨论显式视频生成是否必要,π0.7 则仍然保留 VLA 主体。但如果从表征学习角度看,它们并不是三条完全分叉的路线,而是在用不同方式回答同一个问题:动作生成之前,模型内部到底应该形成什么样的状态表示。
Being-H0.7 的做法最直接。它在多模态上下文和动作 chunk 之间插入 learnable latent queries,让模型先把当前观测、语言、状态等信息整理成一个 latent reasoning space,再由这个 latent 去指导动作生成。更关键的是,它在训练期引入 posterior branch,让这个分支额外看到未来观测,并用 future embeddings 替换 latent queries。这样做的意义不是让推理时偷看未来,而是让 posterior branch 作为训练期老师,告诉 prior branch:未来观测中哪些变化真正和动作有关。推理时 prior branch 仍然只看当前上下文,但它学到的 latent 已经被未来信息塑形过。
Fast-WAM 则把问题推进了一步:如果未来视频只在训练期有用,那么推理时是否还必须真的生成视频?它的答案是否定的。Fast-WAM 的关键判断是,WAM 的主要收益可能来自 video co-training 对 shared representation 的塑造,而不是来自推理阶段显式滚动预测未来画面。也就是说,视频预测任务像一个辅助监督,把当前观测和语言编码成更懂时序、更懂物理后果的特征;一旦这个特征学好了,动作分支未必还需要在部署时先生成一段视频再转成动作。
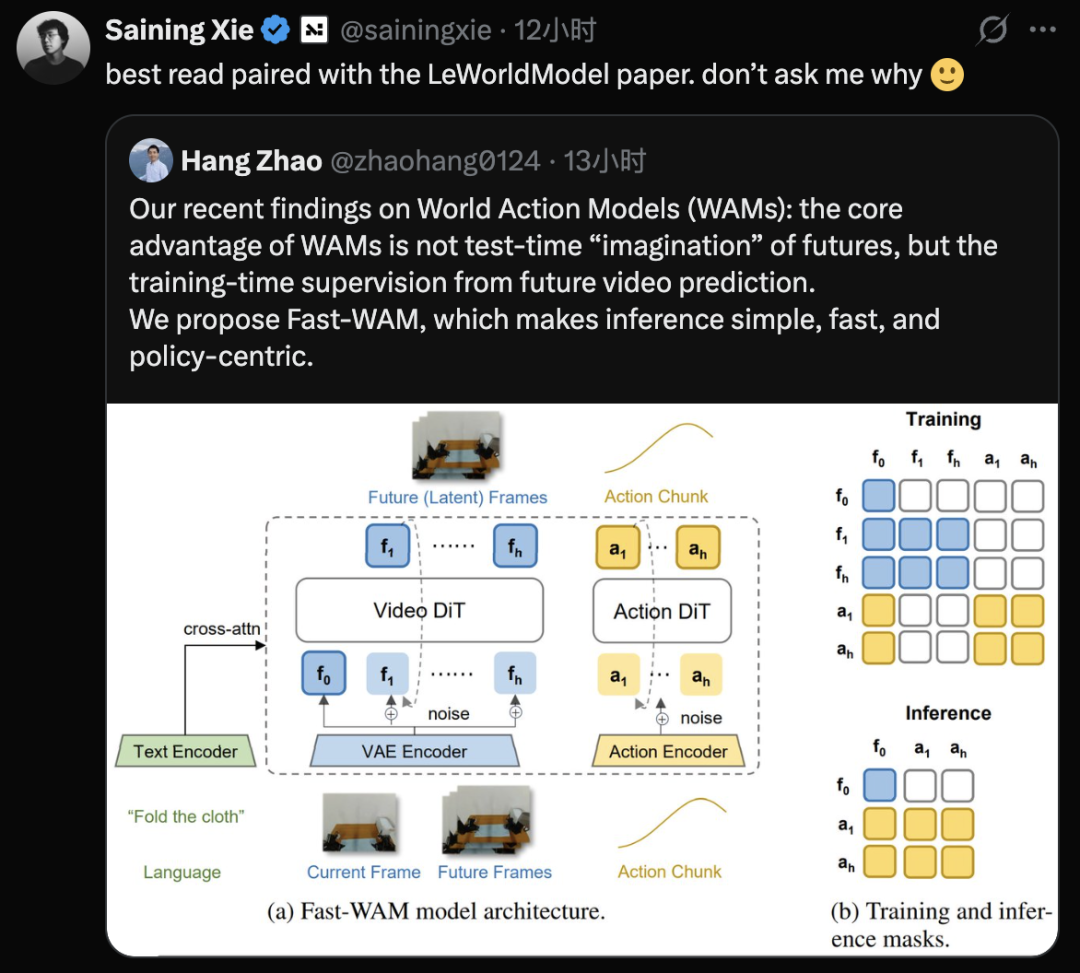
这一点可以从 Fast-WAM 的 attention mask 设计看出来。它让未来 video tokens 和 action tokens 互相不能 attend,避免未来图像信息直接泄漏到动作预测分支。动作分支不能简单抄未来帧,但当前观测、语言和历史上下文这些 shared tokens 会同时服务于视频预测和动作预测。于是训练时,视频任务迫使 shared context 学到“如果这样行动,世界大概会往哪个方向演化”的信息;动作任务则迫使同一组上下文特征保持可控性。最终得到的是一个被未来视频任务正则化过的中间表征,而不是一个必须在推理时完整输出视频的系统。
这就解释了为什么 Fast-WAM 对 π0.7 很有启发。π0.7 并没有把自己做成典型的 WAM,也没有要求主模型在每一步都生成连续未来视频;但它把世界模型生成的 subgoal images 放进 context,本质上是在用更稀疏、更关键的未来观测来约束动作。Fast-WAM 说明“完整视频生成未必是推理所必需”,π0.7 则进一步展示“关键未来状态可能已经足够”。两者共同指向一个结论:未来信息的价值,不一定体现在推理时生成多少帧,而体现在它是否帮助动作模型拿到了更好的决策表征。
因此,π0.7 的视觉子目标不是一个孤立技巧,而是对 WAM 思想的一种轻量化吸收。完整预测未来视频成本高、冗余大,也未必与控制目标强对齐;但预测或提供关键未来状态,尤其是任务阶段转换处的 subgoal image,往往已经足够给动作模型一个更明确的目标几何。它不是让机器人知道未来每个像素会怎样变化,而是让机器人知道“接下来这个阶段应该把世界推向什么状态”。这比单纯的语言目标更具体,又比全视频生成更经济。
这三类方法可以放在同一张表里理解:
| 方法 | 未来信息如何进入训练/推理 | 表征学习含义 |
|---|---|---|
| Being-H0.7 | 训练期 posterior branch 额外看到未来观测 | 用未来观测对 latent reasoning space 做监督和对齐 |
| Fast-WAM | 训练期联合视频预测和动作预测,推理时不一定生成视频 | 用视频任务塑造 shared context,使动作分支获得未来感知特征 |
| π0.7 | 世界模型生成 subgoal images,并与 metadata、子任务语言一起进入 prompt | 把关键未来状态显式变成条件,让动作生成接近目标状态迁移 |
从这张表可以看出,三者的共同点不是都要预测视频,也不是都要使用同一种 backbone,而是都在反对“只靠当前观测、语言和动作标签学习策略”。因为动作监督本身太稀疏,往往只告诉模型“这一刻做了什么”,却没有告诉模型“为什么这样做合理”“下一阶段应该让世界变成什么样”“哪些未来变化对成功最关键”。未来观测、关键帧、latent posterior、video co-training 和 subgoal image,都是在补这部分监督缺口。
从机器人 backbone 的划分也能帮助理解这一点。从零训练、VLA、世界动作模型并不是绝对替代关系,而是不同方式的表征学习入口。从零训练适合数据充足、任务边界清楚的场景;VLA 借助互联网规模视觉语言预训练获得语义接地和跨任务迁移;WAM 借助视频生成或视频预测学习直观物理与时间演化。π0.7 的位置恰好在中间:它保留 VLA 的语义与指令优势,又把世界模型生成的关键未来状态接入 prompt,使动作专家在更强的条件表征上做连续控制。
因此,判断 π0.7 的价值,不应只问“它是不是 VLA”,而应问“它有没有让动作模型拿到更好的决策表征”。如果答案是肯定的,那么 VLA 与 WAM 的边界反而会变得不那么重要。未来真正重要的竞争点,可能不是谁坚持了某个标签,而是谁能更稳定地构造出包含未来、物理、质量和任务阶段信息的可控表征。
9. 模型结构如何组织这些信息
…详情请参照古月居

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)