TPAMI 2025 | 突破域适应瓶颈!这款视觉-语言框架让模型跨域迁移更高效
在人工智能的世界里,让模型“举一反三”一直是研究者们追求的目标。比如训练好的图像分类模型,能从标注好的“源域”数据,无缝适配到没标注的“目标域”数据,这就是无监督域适应(UDA)的核心诉求。但长期以来,视觉-语言模型(VLM)在域适应任务中,始终被“模态间隙”这个难题绊住脚步。
最近,一篇名为《Unified Modality Separation: A Vision-Language Framework for Unsupervised Domain Adaptation》的论文,提出了全新的UniMoS++框架,不仅绕开了模态间隙的困扰,还让模型训练效率提升9倍,性能最高涨9%!今天就带大家读懂这项超实用的研究。
我们日常接触的CLIP这类视觉-语言模型,是在海量图像-文本对里训练出来的。它能把图片和文字的特征“拉近距离”,让模型理解“小猫图片”和“小猫文字描述”是一回事。
但问题来了——就算经过海量预训练,图片的视觉特征和文字的文本特征,本质上还是两套完全不同的分布(图1)。就像用两种不同语言描述同一件事,总有一些“专属表达”没法互相翻译,这就是“模态间隙”。
现有域适应方法,只盯着能互通的“模态不变知识”,却丢掉了视觉、文本各自的“模态特定知识”。比如一张“手绘小猫图”,视觉特征里的笔触、线条是独有的,文本特征里的“手绘、卡通”描述也是独有的,这些宝贵信息被浪费,模型自然没法做到最优适配。
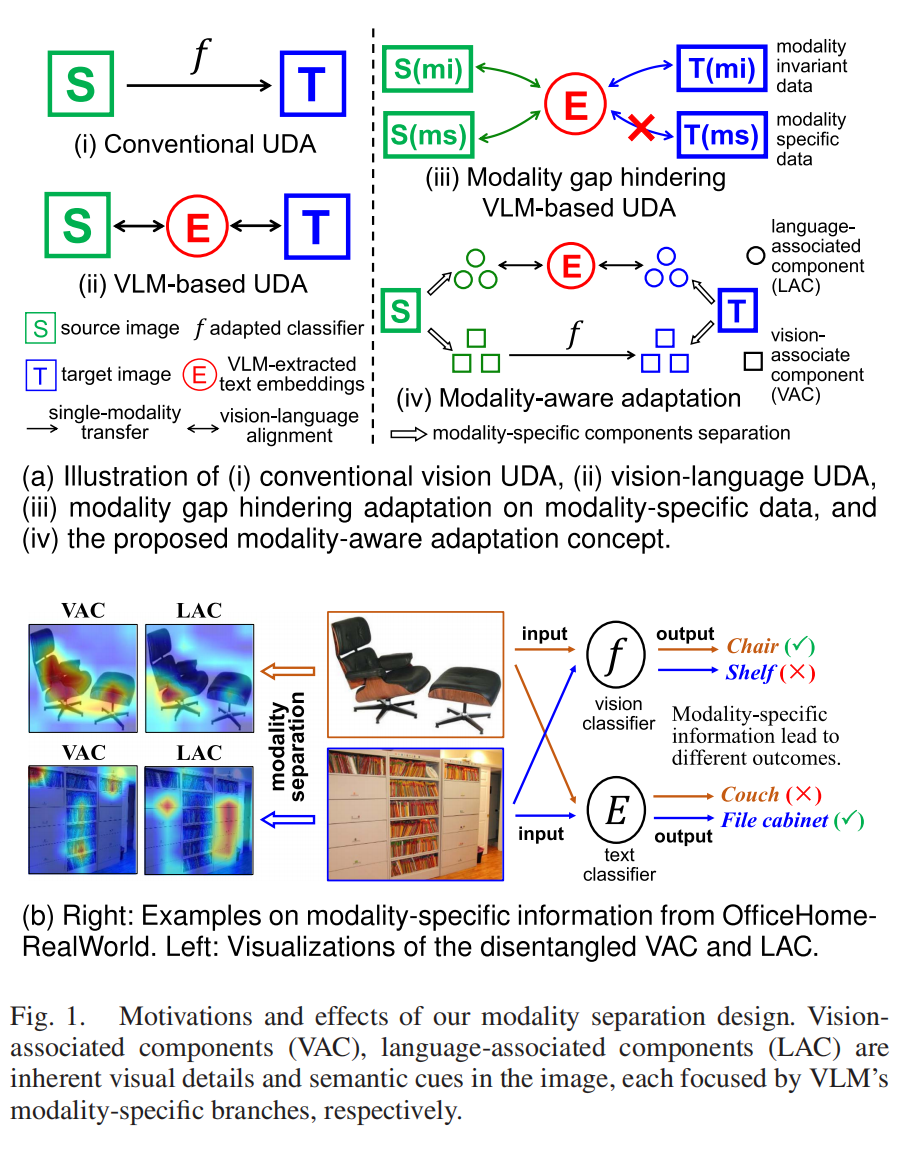
(图1:模态间隙示意图,右侧清晰展示了模态特定知识的存在)
UniMoS++的核心是模态分离网络(图3)。它就像一个智能分拣机,把CLIP提取的视觉特征,精准拆成VAC和LAC:
-
VAC:专属于视觉的特征,比如图片里的色彩、纹理、形状;
-
LAC:和文本关联的特征,比如图片对应的文字描述、语义信息。
为了让这两部分特征不“混为一谈”,研究团队设计了正交正则化损失,确保VAC和LAC各自独立,就像给两个抽屉做了分隔,互不干扰。
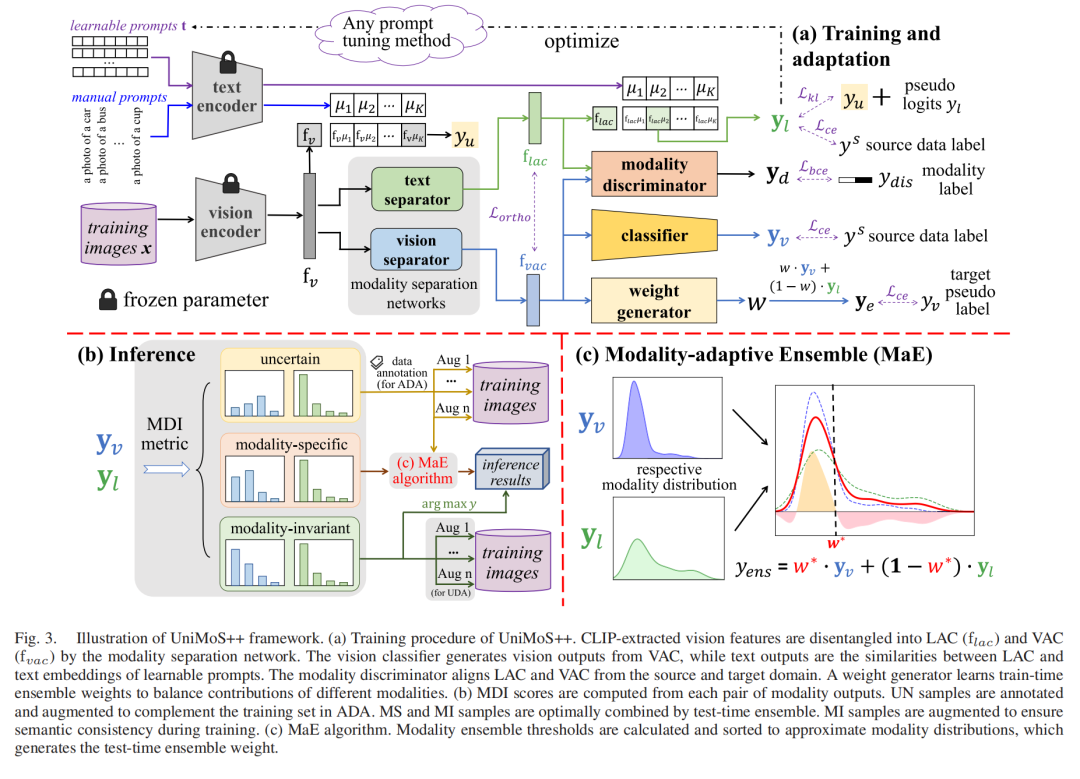
(图3:UniMoS++框架总体结构图,清晰展示了特征分离、训练、集成的全流程)
2. 分类:模态差异度量,给样本“贴标签”
不同样本的模态特性天差地别,有的好适配,有的难搞定。研究团队设计了模态差异(MDI)度量,给目标域样本分了三类(图2):
-
模态不变(MI)样本:视觉和文本特征高度一致,比如清晰的“真实小猫照片”,模型容易识别;
-
模态特定(MS)样本:视觉和文本各有优势,比如“手绘小猫图”,视觉特征能看出笔触,文本特征能强调“手绘”;
-
不确定(UN)样本:视觉和文本特征混乱,模型根本分不清,是适配的“老大难”。
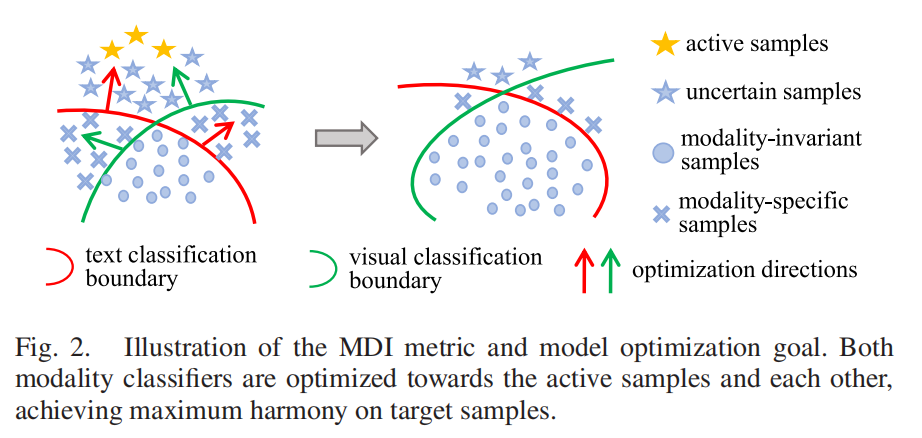
(图2:MDI度量下的样本分类示意图,不同类型样本对应不同适配策略)
真实数据验证了这个分类的有效性(图4):MI样本准确率最高,MS样本通过集成能涨7.9%的性能,UN样本准确率只有25%——这也说明,针对性处理不同样本,才能最大化模型效果。
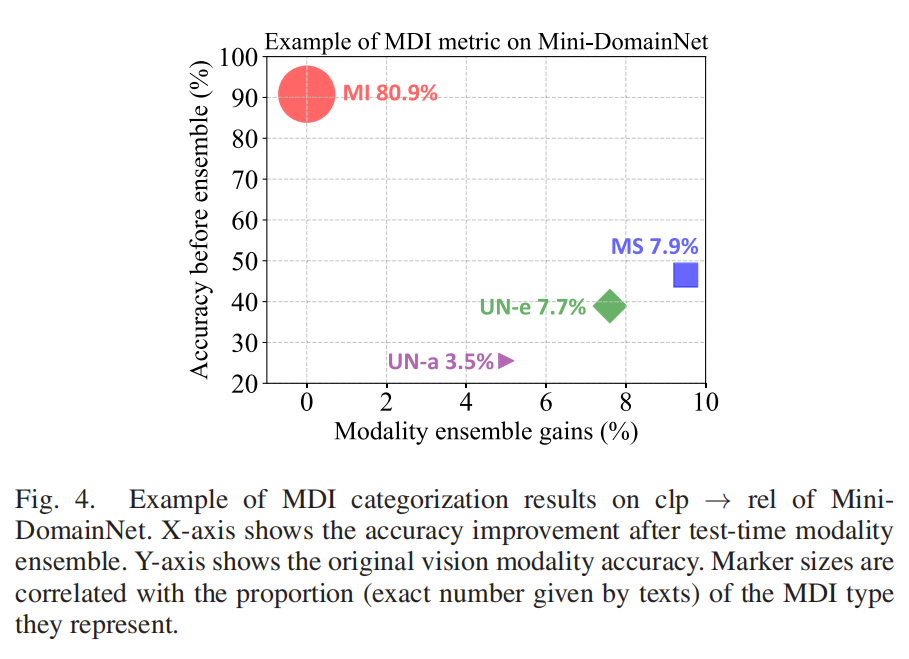
(图4:真实数据集上MDI各类样本的表现,直观体现分类价值)
3. 整合:模态自适应集成,给权重“找最优”
拆分开的特征,最终要整合起来做预测。以往的方法用固定权重,没法适配不同任务和训练阶段,就像用一把固定力度的勺子,舀不同稠度的粥,总有舀不好的时候。
UniMoS++提出的模态自适应集成(MaE)算法,能自动找最优权重(图5):它分析样本的模态分布,看视觉和文本哪个更靠谱,就给哪个更高权重。比如处理MS样本时,自动把权重偏向“更擅长”的模态,让预测更精准。
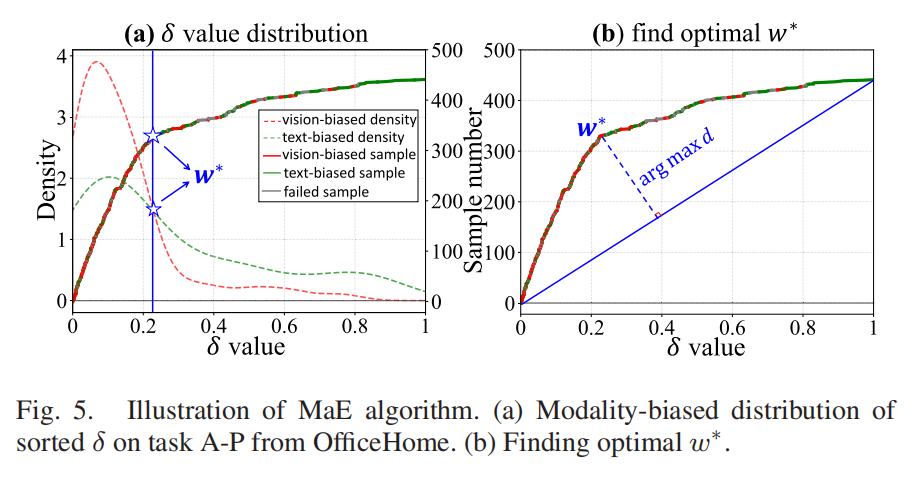
(图5:MaE算法找最优集成权重的示意图,红色为视觉偏置样本,绿色为文本偏置样本)
4. 训练:高效适配,成本降9倍
UniMoS++的训练方案特别“省成本”:全程冻结CLIP的预训练编码器,只训练线性层这类轻量模块。同时设计了模态感知训练策略,针对不同类型样本定制适配方案:
-
MI样本:用来强化跨模态对齐,让通用知识更稳;
-
MS样本:用MaE整合优势,最大化专属知识价值;
-
UN样本:主动标注少量最难样本,用低成本换高性能。
实验结果:全方位碾压,性能拉满
研究团队在OfficeHome、VisDA-2017、DomainNet等5个主流域适应数据集上做了测试,结果亮眼:
-
无监督域适应(UDA):在OfficeHome上,不用微调CLIP就超越了全微调的PADCLIP;在最难的DomainNet上,性能比现有CLIP基方法大幅提升,UniMoS++更是把准确率从21.3%涨到25%;
-
多源域适应(MSDA):面对多个源域的混合分布,MaE自动调整权重,在DomainNet上超越所有现有SOTA;
-
主动域适应(ADA):5%标注预算下,准确率甚至超过目标域全监督训练结果;无源ADA(不碰源数据)也刷新了SOTA;
-
效率:训练时间减少9倍,性能却最高涨9%,兼顾效果和成本。
为什么这项研究值得关注?
-
思路创新:不再“硬刚”模态间隙,而是“绕开”它,把被忽视的模态特定知识利用起来,给域适应研究打开了新方向;
-
实用性强:兼容CoOp、LoRA等主流提示调优、参数高效微调技术,不用大改现有框架就能落地;
-
泛化性好:能适配UDA、MSDA、ADA、无源ADA等多种场景,在不同数据集、骨干网络上都表现稳定;
-
效率拉满:冻结预训练编码器,只训练轻量模块,普通GPU就能跑,训练时间砍到原来的1/9
CSDN粉丝独家福利
这份完整版的 AI系统资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 3
3 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)