LangChain是什么?为什么都在用它开发AI应用
引言:如果你还在用
requests.post()直接调用OpenAI API,这篇文章可能会改变你的开发方式。
一、从"裸调API"说起:那些让人崩溃的日常
去年夏天,我帮朋友做了一个AI客服Demo。需求很简单:接入DeepSeek R1,让它能根据产品手册回答用户问题。
我兴冲冲地打开OpenAI文档,复制了那段经典的Python代码:
import openai
openai.api_key = "sk-..."
response = openai.ChatCompletion.create(
model="deepseek-r1",
messages=[{"role": "user", "content": "你们的产品支持哪些支付方式?"}]
)
print(response.choices[0].message.content)
三行代码,AI就开口说话了。当时我觉得:AI开发不过如此。
但真正的噩梦从第二天开始。
产品经理说:"用户可能会追问,AI得记得刚才聊了什么。"好,那我得手动维护一个对话历史列表,每次请求前把历史记录拼进messages里。代码从3行变成了30行。
技术负责人提了个需求:"能不能接入我们内部的产品知识库?"于是我开始研究向量数据库、文档切分、Embedding——代码膨胀到了300行,而且全是胶水代码。
更崩溃的是两周后,老板说GPT-4太贵了,要换成Claude。我打开Anthropic的文档,发现参数格式完全不一样:messages变成了messages,但结构不同;温度参数不叫temperature叫别的;返回的JSON格式也变了。我花了整整一天,把300行代码重写了一遍。
这就像一个建筑工人,每次换一批砖头,都要重新学习怎么砌墙。
如果你也有类似的经历,恭喜你,你已经踩中了"裸调API"的三大坑:
第一坑:模型切换成本极高。 今天用OpenAI,明天换Claude,后天试试国产模型,每次迁移都等于半次重构。不同厂商的API参数、消息格式、错误处理机制千差万别,你的业务逻辑被牢牢绑死在某个具体模型上。
第二坑:上下文管理像一团乱麻。 多轮对话时,你需要自己维护历史记录、控制Token长度、处理上下文截断。提示词模板散落在代码的各个角落,改一个措辞要翻遍整个项目。
第三坑:功能扩展全靠"手搓"。 想加RAG检索?自己写文档加载和向量检索。想让AI调用工具?自己设计函数调用协议。想加日志监控?再写一套埋点代码。每个项目都在重复造轮子。
这些问题,本质上不是API不好用,而是API只解决了"调用模型"这一个点,但AI应用是一整条链路。
二、LangChain:AI应用的"脚手架"
如果把开发AI应用比作盖房子,直接调用API就像你手里只有一堆砖头和水泥——材料是顶级的,但没有脚手架、没有施工流程、没有安全网。
LangChain就是那个脚手架。

它不会替你生产砖头(它不训练模型),也不会替你设计户型(它不决定业务逻辑),但它提供了一套标准化的施工体系:统一的材料接口、模块化的建造流程、可复用的工具组件。让你无论用哪个品牌的砖头,都能按同一套规范把房子盖起来。
具体来说,LangChain解决的是AI应用开发中的工程化问题:
- 解耦模型依赖:无论底层是OpenAI、Claude、文心一言还是本地部署的Llama,上层业务代码几乎不用改。
- 标准化流程:把"接收输入→组装提示→调用模型→解析输出"这条链路抽象成可复用的组件。
- 模块化扩展:RAG检索、工具调用、记忆管理、日志监控,这些能力都以"插件"形式存在,按需取用。
用框架思维替代API调用思维,是AI应用开发从"手工作坊"走向"工业化生产"的必经之路。
三、六大核心模块:一张图看懂LangChain的骨架
LangChain的架构设计非常清晰,可以归纳为六大核心模块。理解这六块,你就掌握了LangChain的骨架。
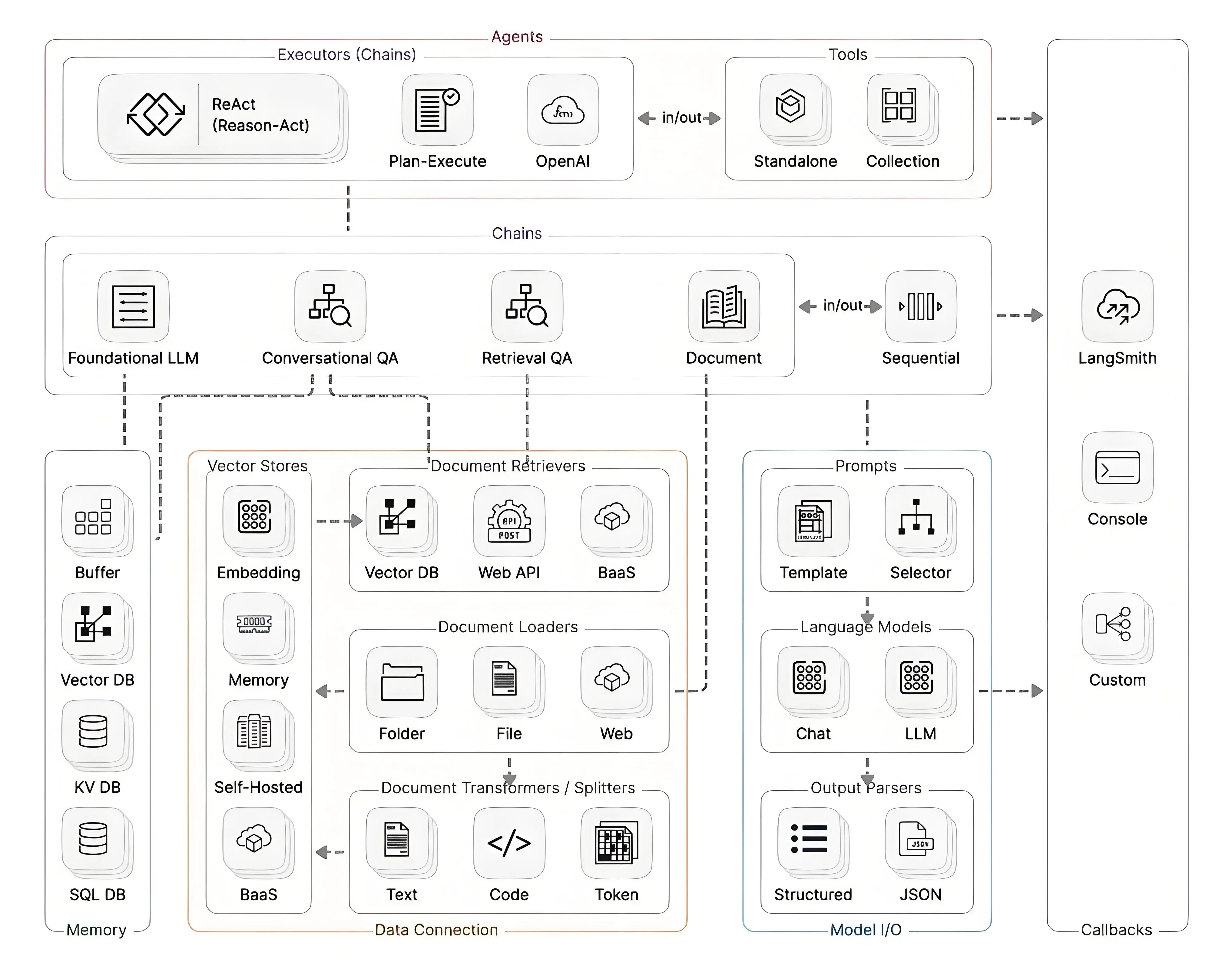
1. Model I/O:统一的大模型"翻译官"
这是LangChain最基础也最常用的模块。它负责三件事:提示词模板管理、模型调用标准化、输出结构化解析。
举个例子,直接调用API时,你的提示词可能是这样的:
prompt = f"你是一个专业的客服助手。用户的问题是:{user_question}。请用中文回答,控制在100字以内。"
提示词和代码完全耦合在一起,改个措辞都要动代码。而LangChain的Prompt Template把它变成了可复用的模板:
from langchain.prompts import ChatPromptTemplate
template = ChatPromptTemplate.from_messages([
("system", "你是一个专业的客服助手,请用中文回答,控制在100字以内。"),
("human", "{question}")
])
业务逻辑和提示词彻底解耦。更关键的是,无论你后面换OpenAI还是Claude,ChatPromptTemplate的用法完全一致——LangChain会在底层自动帮你翻译成对应模型需要的消息格式。
输出解析也一样。模型经常返回一大段文本,但你的程序需要的是结构化数据。LangChain的Output Parser可以把"模型说人话"转换成"程序能用的JSON",省去了大量字符串处理代码。
2. Chains:把零散步骤串成流水线
Chain(链)是LangChain的灵魂概念。它解决的是一个非常实际的问题:AI应用很少是"一问一答"就能搞定的,通常需要多步协作。
比如一个典型的RAG流程:用户提问→检索相关文档→把文档拼进提示词→调用模型→返回答案。这五步在裸调API时,你需要写五段独立的代码,手动传递中间结果。
LangChain的Chain把这五步封装成一条"流水线":
用户输入 → Retriever检索 → PromptTemplate组装 → LLM推理 → OutputParser解析 → 返回结果
每一步都是一个独立的组件,通过"管道"连接。你可以像搭积木一样,把不同的组件组合成不同的Chain。更高级的是LCEL(LangChain Expression Language),它用类似Unix管道的语法prompt | model | parser,让链的组装变得极其直观。
3. Retrieval:给AI装上"外接大脑"
大模型有一个致命缺陷:它的知识是"冻结"的。GPT-4的训练数据截止到某个时间点,它不知道你公司上周发布的新产品,也读不懂你电脑里的内部文档。
Retrieval模块就是解决这个问题的。它的核心思路是RAG(检索增强生成):先把你的私有文档切分成小块,转成向量存进向量数据库;用户提问时,先检索出最相关的文档片段,再把这些片段作为"参考资料"一起喂给模型。
LangChain把RAG的完整链路都封装好了:
- Document Loaders:加载PDF、Word、网页、数据库等各种数据源;
- Text Splitters:把长文档切成语义完整的小块;
- Embedding Models:把文本转成向量;
- Vector Stores:存储和检索向量;
- Retrievers:根据问题召回最相关的文档。
你不需要理解向量检索的数学原理,几行代码就能让AI"读懂"你的私有文档。
4. Memory:让AI记住你们聊过什么
裸调API时,每次请求都是独立的——模型就像一条金鱼,转身就忘了刚才的对话。要实现多轮对话,你得自己维护历史记录、控制长度、处理截断。
LangChain的Memory模块提供了多种开箱即用的记忆策略:
- ConversationBufferMemory:简单粗暴,把完整对话历史全部塞进上下文。适合对话轮数少的场景。
- ConversationBufferWindowMemory:只保留最近K轮对话,防止上下文过长。适合长对话场景。
- ConversationSummaryMemory:当历史太长时,自动让AI生成一段摘要替代原始对话。平衡了记忆完整性和Token成本。
- VectorStoreRetrieverMemory:把历史对话向量化存储,根据语义相似度检索相关记忆。适合需要"长期记忆"的场景。
你不需要自己写历史管理的胶水代码,选一个合适的Memory类型,Chain会自动帮你处理"读取记忆→拼进提示→保存新对话"的闭环。
5. Agents:给AI装上"手脚"
如果说Chain是"按固定剧本演戏",那么Agent就是"让AI自己决定下一步做什么"。
Agent的核心机制是ReAct(Reasoning + Acting):模型先"思考"(Reasoning)用户需要什么,再"行动"(Acting)调用合适的工具,然后根据工具返回的结果继续思考,直到完成任务。
比如用户问:“北京今天天气怎么样?适合穿什么衣服?”
一个Agent的处理流程可能是:
- 思考:用户问了两个问题,天气和穿衣建议。我需要先查天气。
- 行动:调用天气查询工具,传入"北京"。
- 观察:工具返回"北京今天晴,15-25°C"。
- 思考:天气已经拿到了,现在可以回答穿衣建议了。
- 行动:调用模型生成穿衣建议。
- 完成:返回最终答案。
LangChain的Agent框架让你可以定义各种工具(搜索、计算、数据库查询、API调用等),然后让模型自主决定什么时候用哪个工具。这是从"问答机器人"进化到"智能助手"的关键一步。
6. Callbacks:给AI应用装上"监控探头"
生产环境的AI应用,不能"黑盒运行"。你需要知道每次请求花了多长时间、消耗了多少Token、模型输出了什么、哪一步可能出错了。
Callbacks模块就是LangChain的"监控探头"。它允许你在Chain或Agent执行的各个阶段"插钩子":
- 模型开始推理前,记录输入的Prompt;
- 模型返回结果后,记录输出内容和Token消耗;
- 工具调用时,记录调用了什么工具、传了什么参数;
- 发生异常时,记录错误堆栈。
这些回调数据可以输出到控制台、写入日志文件、或者发送到LangSmith(LangChain官方的可观测性平台)进行可视化分析。对于需要上线运行的AI应用,这是必不可少的调试和监控手段。
四、30秒上手:一个极简Demo
说了这么多,不如直接看代码。下面这个Demo展示了LangChain最核心的用法——用Chain把"提示词模板→模型调用→输出解析"串起来:
from langchain_openai import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
# 初始化模型
model = ChatOpenAI(model="deepseek-r1")
# 定义提示词模板
prompt = ChatPromptTemplate.from_template("请用一句话解释什么是{concept}")
# 组装Chain:提示词 → 模型 → 输出解析
chain = prompt | model | StrOutputParser()
# 运行
result = chain.invoke({"concept": "LangChain"})
print(result)
这5行代码做了什么?
ChatPromptTemplate创建了一个带变量的提示词模板,把提示词从代码中抽离出来;ChatOpenAI封装了模型调用,你不需要处理API密钥、消息格式、重试逻辑;StrOutputParser自动把模型的消息对象转成纯字符串;|运算符把三者串成一条Chain,数据从左流到右;invoke()传入变量,Chain自动完成"填充模板→调模型→解析输出"的全流程。
如果你想换成Claude,只需要把ChatOpenAI改成ChatAnthropic,其他代码完全不变。这就是框架思维的价值:业务逻辑和底层实现解耦。
五、写在最后:从"调API"到"搭架构"
回顾AI应用开发的演进,我们可以看到一个清晰的路径:
- 阶段一:裸调API。适合快速验证想法,但代码难以维护和扩展。
- 阶段二:使用框架。用LangChain等框架组织代码,实现模型无关、模块化、可观测。
- 阶段三:工程化平台。结合LangSmith、LangGraph等工具,构建生产级的AI应用体系。
LangChain的意义,不在于它让你少写了多少行代码,而在于它帮你建立了一套AI应用开发的工程化思维:
- 提示词是配置,不是代码,应该模板化管理;
- 模型是接口,不是实现,应该抽象化封装;
- 流程是流水线,不是脚本,应该组件化组装;
- 应用是可观测的,不是黑盒,应该全程可追溯。
当你开始用这套思维去设计AI应用时,你会发现:换模型只是改一行配置,加功能只是插一个组件,调试问题只是看一条Trace。这才是AI应用开发该有的样子。
如果你还在直接用requests.post()调API,不妨花半小时装个LangChain,跑一遍上面的5行Demo。那个瞬间,你可能会和我一样感叹:原来AI开发可以这么干净。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 2
2 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)