ACL 2026|AI for 聋哑群体,不止翻译,更懂语义:港理工思考型手语模型开源
很多开发者和研究员在做手语翻译(SLT)时,潜意识里都犯了一个致命错误:把视频片段强行等同于单词。
这种“视觉对齐”的逻辑,在处理简单的词汇时凑合,但在面对真实世界的复杂表达时会瞬间崩塌。手语不是静态符号的堆砌,它是利用空间、速度、重定向进行“即兴创作”的艺术。如果你的模型只是在做视频到文字的转换,那它本质上只是一个高级的翻译机,而不是一个真正的理解者。

为了给方便大家更好的复现,我给大家准备了完整版的技术资料、代码和复现路径,以及相关论文合集,如有需要可点击此链接!
行业误区 vs 真实问题
行业误区: 认为 SLT 是视频到文本的单纯“转换”,只要增加数据量和 Transformer 的层数,模型就能学会翻译。
真实问题: 手语具有极强的“生产性(Productive Forms)”。同一个手势,位置偏一点、动作快一点,意思就会从“停车”变成“撞车”。这种动态生成的含义,根本无法通过离散的词汇表(Gloss)来对齐。
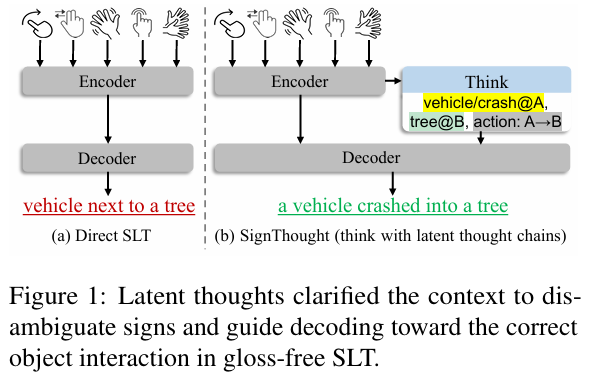
核心结论
👉 这篇论文,本质上做了:将手语翻译从“视频转文字”的工程问题,升级为“多模态潜在推理”的逻辑问题。
方法拆解:SignThought 的范式升级
这篇论文不再追求“对得准”,而是追求“想得清”。
- Stage 1:从“特征提取”到“语义抽象”。 不再把视频硬塞给解码器,而是引入“潜在思维链(Latent Thought Chain)”。模型先在内部生成一系列有序的、连续的隐藏状态,就像人在说话前先在大脑里打草稿。
- Stage 2:从“同步转换”到“先谋后动”。 采用“计划-接地(Plan-then-Ground)”机制。模型先决定“我要表达什么语义”,然后再回过头去视频里找证据(Evidence)。这种解耦彻底解决了模型在长句子中容易“胡言乱语”的顽疾。
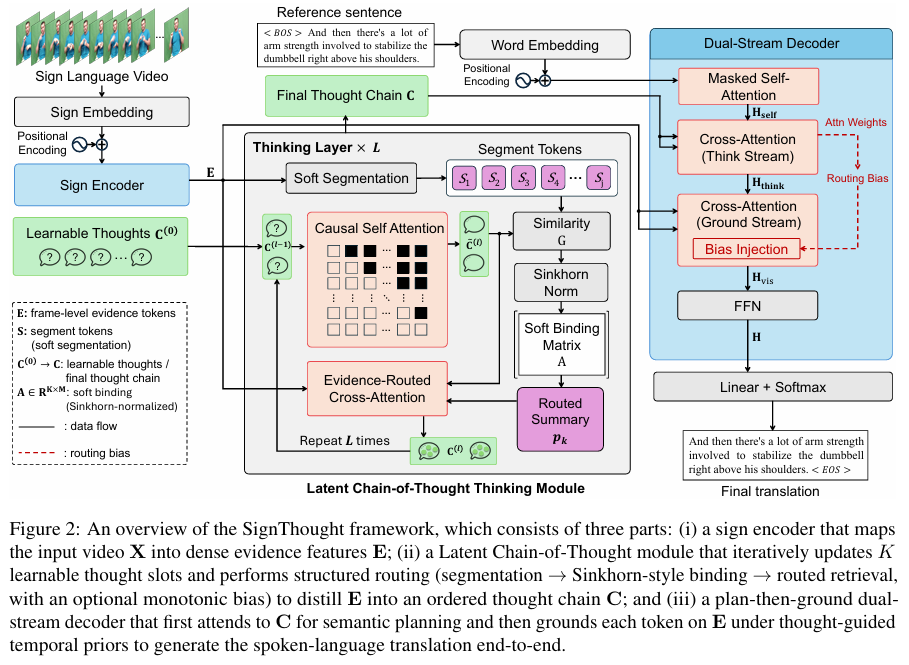
关键技术翻译
- 潜在思维槽(Thought Slots): > 人话: 给模型准备几个“思维记事本”,让它在看视频时先往里面记下关键线索,而不是急着翻字典。
- 证据路由(Evidence-Routed Attention): > 人话: 不再让模型看全场,而是根据“草稿”里的内容,精准定位视频里的特定动作。
- 双流解码器(Dual-Stream Decoder): > 人话: 左脑负责逻辑架构(想说什么),右脑负责细节填充(怎么说才通顺)。
即插即用代码:潜在思维链核心逻辑
这个 Thinking Layer 的设计思路非常超前,你可以直接迁移到任何需要“长视频理解”的任务中:
import torch
import torch.nn as nn
class ThinkingLayer(nn.Module):
def __init__(self, d_model, n_slots=8):
super().__init__()
# 初始化的“潜在思维槽”
self.thought_slots = nn.Parameter(torch.randn(1, n_slots, d_model))
self.causal_attn = nn.MultiheadAttention(d_model, num_heads=8, batch_first=True)
def forward(self, evidence_features):
# 1. 因果思考:前面的思维启发后面的思维
# 使用下三角掩码确保思维是有序的流式推理
thoughts, _ = self.causal_attn(self.thought_slots, self.thought_slots, self.thought_slots,
attn_mask=self.get_causal_mask())
# 2. 证据路由:思维去视频特征里“寻根溯源”
# 这里可以使用 Sinkhorn 归一化来实现更稳定的证据分配
updated_thoughts = self.routed_cross_attention(thoughts, evidence_features)
return updated_thoughts
可以放在哪里用? 任何长视频问答、复杂动作识别或需要多步推理的多模态任务。
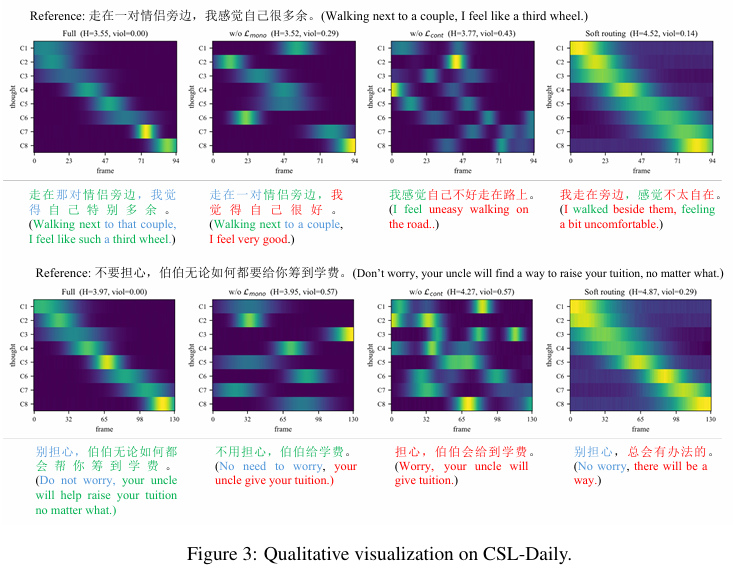
方法论升华
👉 这篇论文真正重要的不是手语翻译刷了多少分,而是证明了:对于高度动态的模态,中间必须有一层“非显式”的逻辑缓冲区。
👉 总结为一个“范式”:
LTC-SLT (Latent Thought-Chain Sign Language Translation)
一种“先规划语义路径,再检索视觉证据”的多模态处理新标准。

可延展方向
- 科研方向: 尝试将“潜在思维”转化为“可解释的文本(Rationale)”。既然模型已经在思考了,能不能让它把“草稿”写出来给我们看?
- 工程方向: 既然该框架在弱监督下(只有视频和文本)表现如此强劲,完全可以利用它在更多小语种或垂类行业(如手语医疗咨询)中快速冷启动。
“伟大的模型不应该只是视觉的复读机,而应该是逻辑的编织者。”

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)