本地智能编码助手实战
前言:被 Copilot “禁用” 的日子
上个月,我们公司的安全部门突然发了一封全员邮件,内容让我们整个开发团队都傻了眼:禁止使用所有外网 AI 编码工具,包括 GitHub Copilot、CodeGeeX 等各类在线 AI 助手。
原因很简单:这些工具都会把我们输入的代码、需求上传到第三方的服务器,对于我们这种做企业级服务的公司来说,核心业务代码的泄密风险是完全不能接受的。之前就有过别的公司,因为用了 Copilot,结果把内部的私密代码不小心传到了 Copilot 的训练集里,最后导致泄密,赔了一大笔钱,我们公司可不想冒这个险。
说实话,看到这个通知的时候,我心里咯噔一下。这两年用 Copilot 用惯了,写代码的时候,它帮我补全代码、解释老代码、写单元测试、找 bug,早就成了我工作里离不开的帮手。之前我还跟朋友吹,说 Copilot 把我的开发效率提升了至少 50%,结果现在,突然不让用了,这不是要了老命了?
接下来的两天,我算是体会到了没有 AI 助手的日子有多难受。写个简单的接口,要手动写注释,手动写测试用例,碰到老代码看不懂,要翻半天的文档,碰到 bug,要自己一行一行地找,一天下来,写的代码还不到平时的一半,整个人都累得够呛,团队里的其他人也都在抱怨,说效率掉了一大半,大家都在想,有没有什么办法,能搞个本地的 AI 助手?不用外网,数据都在自己的电脑上,这样安全部门就不会管了?
一开始我以为,这个事情会很复杂,要搞什么复杂的环境,要很高的配置,结果折腾了一周之后,我发现,原来现在的开源大模型已经这么强了,我花了不到 10 分钟,就搭好了一个本地的智能编码助手,用了一个月,发现它比 Copilot 还好用!不仅速度更快,中文支持更好,而且完全免费,数据也安全,再也不用担心泄密的问题了。
今天,我就把整个过程分享给大家,如果你也跟我一样,碰到了公司不让用外网 AI 工具的问题,或者不想每个月花 10 刀买 Copilot 的订阅,这篇文章你一定要看完,绝对能帮你解决这个痛点,让你重新拥有 AI 编码助手,而且比之前的更好用!
选型:我为什么最终选了 Ollama+Qwen2?
最开始的时候,我其实踩了不少的坑,试了好几个模型和工具,才最终定下了这个组合,这里跟大家说说我踩过的坑,免得你们再走弯路。
踩坑 1:火遍全网的 Llama3,居然不适合我?
最开始,我听说 Meta 的 Llama3 很火,说是什么最强开源大模型,代码能力超强,我就兴冲冲地去试了。部署倒是不难,用 Ollama 一行命令就拉下来了,结果一用,我就傻了。
首先,中文支持太差了。我输入中文的需求,比如 “帮我写一个 Python 的批量处理文件的脚本,加上中文注释”,结果它回复的是英文的,写的代码的注释也都是英文的,我们团队的代码都是中文注释,用着特别别扭,而且,有时候我问它中文的问题,它居然听不懂,回复的驴唇不对马嘴,后来我才知道,Llama3 的训练数据里,中文的占比很低,所以中文能力很差,对于我们国内的开发者来说,真的不太够用。
然后,代码的能力,也没有网上说的那么强,我让它写个处理 Excel 的脚本,它居然写了个不存在的库,还报了好几个 bug,我改了半天才能用,这跟我之前用的 Copilot 差远了,所以,试了一天,我就把 Llama3 删掉了。
踩坑 2:专门做代码的 StarCoder,怎么也不好用?
后来,我又想到,有个专门做代码的模型,叫 StarCoder,是 HuggingFace 出的,专门训练的代码模型,应该很适合做编码助手吧?结果,部署完了,发现更糟。
首先,它的上下文窗口太小了,稍微长一点的代码,它就记不住了,我给它看一个几百行的老代码,让它解释,它说上下文太长了,处理不了,而且,中文支持比 Llama3 还差,完全就是英文的模型,输入中文它都看不懂,直接回复英文,根本没法用,所以,这个也 pass 了。
最终选型:Ollama+Qwen2:7b,完美适配我的需求
试了好几个模型之后,我偶然看到了阿里的通义千问开源的 Qwen2 模型,本来没抱太大希望,结果一试,我直接惊了,这也太好用了吧!
首先,中文支持完美!我输入中文的需求,它完全能听懂,回复的都是中文,写的代码的注释也都是中文的,完全符合我们国内开发者的习惯,再也不用跟英文较劲了。
然后,代码能力超强!我让它写的各种脚本,不管是 Python 的,还是 Java 的,还是 C++ 的,它都能写的很好,bug 很少,比之前的 Llama3 强太多了,甚至跟 Copilot 比,都差不了多少。
然后,配置要求很低!7b 的参数,4bit 量化之后,只需要 3.5G 的显存,我那台用了三年的老 3060 笔记本,6G 的显存,完全能跑,一点都不卡,甚至我同事的 MacBook,M1 的,8G 内存,都能流畅运行,根本不需要什么高端的显卡,普通的开发电脑就够了。
然后,部署的工具,我选了 Ollama,这个工具真的是小白神器,之前我用 text-generation-webui,部署一个模型,要装 cuda,装各种依赖,折腾半天,还经常报错,结果 Ollama,一行命令就装好了,然后,拉模型、运行,都是一行命令,完全不用管环境,不用管依赖,小白都能搞定,真的太方便了。
哦,对了,还有,Ollama 支持 Windows、Mac、Linux,不管你用什么系统,都能装,完全没有限制,我们团队里,有用 Windows 的,有用 Mac 的,都装上了,用着都很顺。
所以,最终,我就选了这个组合:Ollama+Qwen2:7b,完美解决了我的所有需求,部署简单,中文好,代码强,配置要求低,而且完全免费,数据都在本地,安全!
第一步:10 分钟部署本地大模型,小白也能会
很多人一听到部署大模型,就觉得很复杂,其实真的不是,用 Ollama,真的 10 分钟就能搞定,我一步步教你,你跟着做,就算你是小白,也能学会。
1.1 安装 Ollama,一行命令搞定
首先,安装 Ollama,这个超级简单:
-
如果你是 Windows 或者 Mac,直接去 Ollama 的官网(https://ollama.com/)下载安装包,然后下一步下一步安装就好了,跟装个普通的软件一样,没什么区别。
-
如果你是 Linux,更简单,打开终端,输入一行命令就好了:
curl https://install.ollama.com | sh就这么简单,装完了,Ollama 就会自动在后台运行了,不用你做任何配置,什么端口啊,服务啊,它都帮你弄好了,你完全不用管。
1.2 拉取 Qwen2 模型,比下载游戏还简单
装完 Ollama 之后,打开你的命令行(Windows 的话就是 CMD 或者 PowerShell,Mac 和 Linux 就是终端),然后输入下面这行命令:
ollama run qwen2:7b然后,你就会看到,它自动开始下载 Qwen2:7b 的模型了,就像下面这个截图一样:
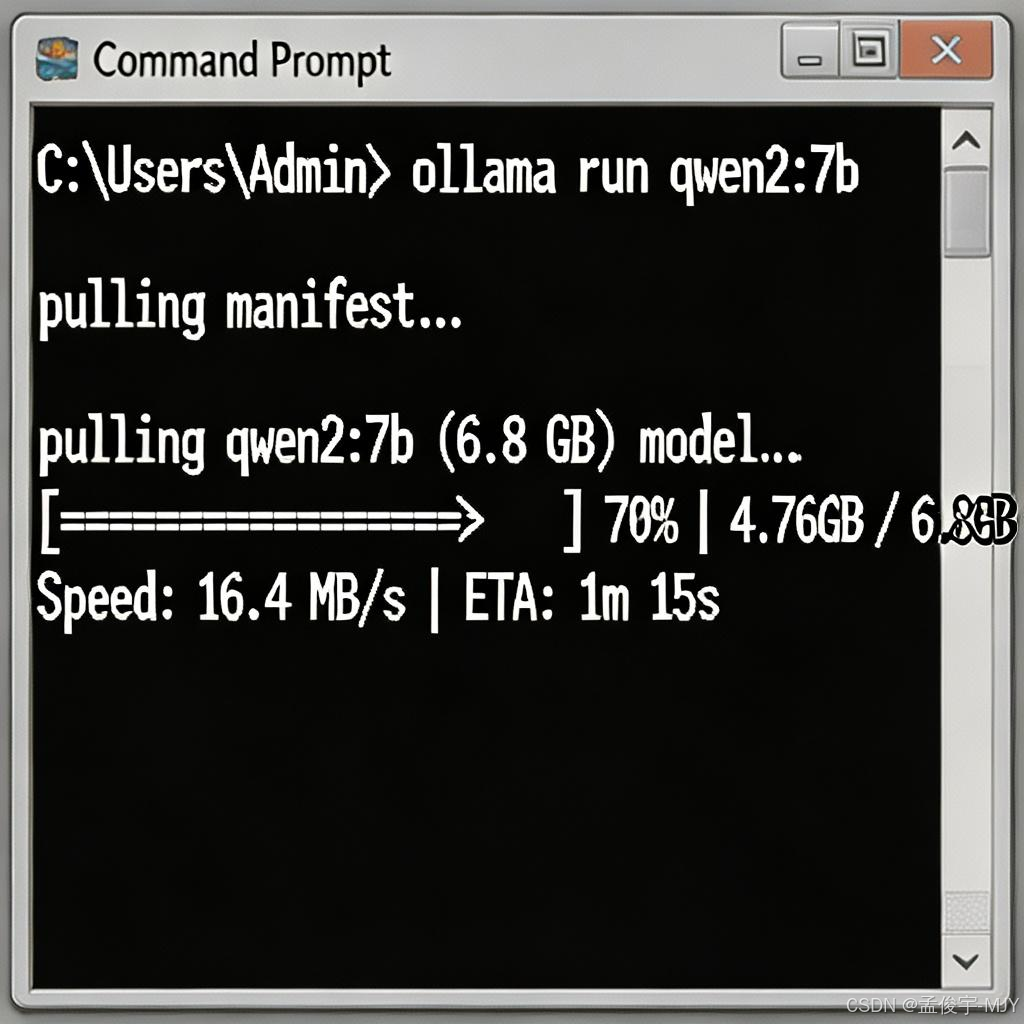
这个模型大概是 3.8G 左右(4bit 量化的),你的网速如果是 10M 的话,大概 10 分钟就下完了,比下载个游戏快多了,下完了之后,它就自动运行了,你就可以直接跟它对话了!
比如,你可以输入 “你好”,它就会回复你,或者,你输入 “帮我写个 Hello World 的 Python 代码”,它就直接给你写出来了,是不是很简单?
哦,对了,如果你有更好的显卡,比如,3090 或者 4090,显存很大,你也可以用 qwen2:14b 的模型,更大的模型,能力更强,当然,需要的显存也更大,14b 的话,大概需要 7G 的显存,如果你有的话,可以试试,不过,对于大部分人来说,7b 的就完全够用了。
1.3 测试一下:命令行里先玩一玩
下载完了之后,你可以先在命令行里测试一下,比如,我输入:“帮我写一个 Python 的函数,计算斐波那契数列,加上中文注释”,然后,它马上就给我输出了:
def fibonacci(n):
"""
计算斐波那契数列的第n项
Args:
n: 要计算的项数,从0开始
Returns:
第n项的斐波那契数值
"""
if n <= 0:
return 0
elif n == 1:
return 1
a, b = 0, 1
for _ in range(2, n+1):
a, b = b, a + b
return b你看,是不是很完美?中文注释,代码,都没问题,而且,速度超级快,秒回,根本不用等,比 Copilot 还快!
到这里,你的本地大模型就部署好了,是不是很简单?10 分钟,就搞定了,接下来,我们把它接入到 VS Code 里,这样,你写代码的时候,就能直接用了,跟 Copilot 一样,有补全,有对话,什么都有!
第二步:把本地模型接入 VS Code,秒变智能编码助手
接下来,我们要装一个 VS Code 的插件,叫 Continue,这个插件是开源的,免费的,比 Copilot 还好用,它支持很多的模型,包括我们本地的 Ollama,用了它,你就能在 VS Code 里,直接用我们的本地大模型,做代码补全、解释代码、重构、写测试,什么都能做,跟 Copilot 一模一样,而且,完全免费!
2.1 安装 Continue 插件,比 Copilot 还好用
首先,打开你的 VS Code,点击左边的扩展图标,然后搜索 “Continue”,找到这个插件,然后点击安装就好了,就跟装其他 VS Code 插件一样,很简单。
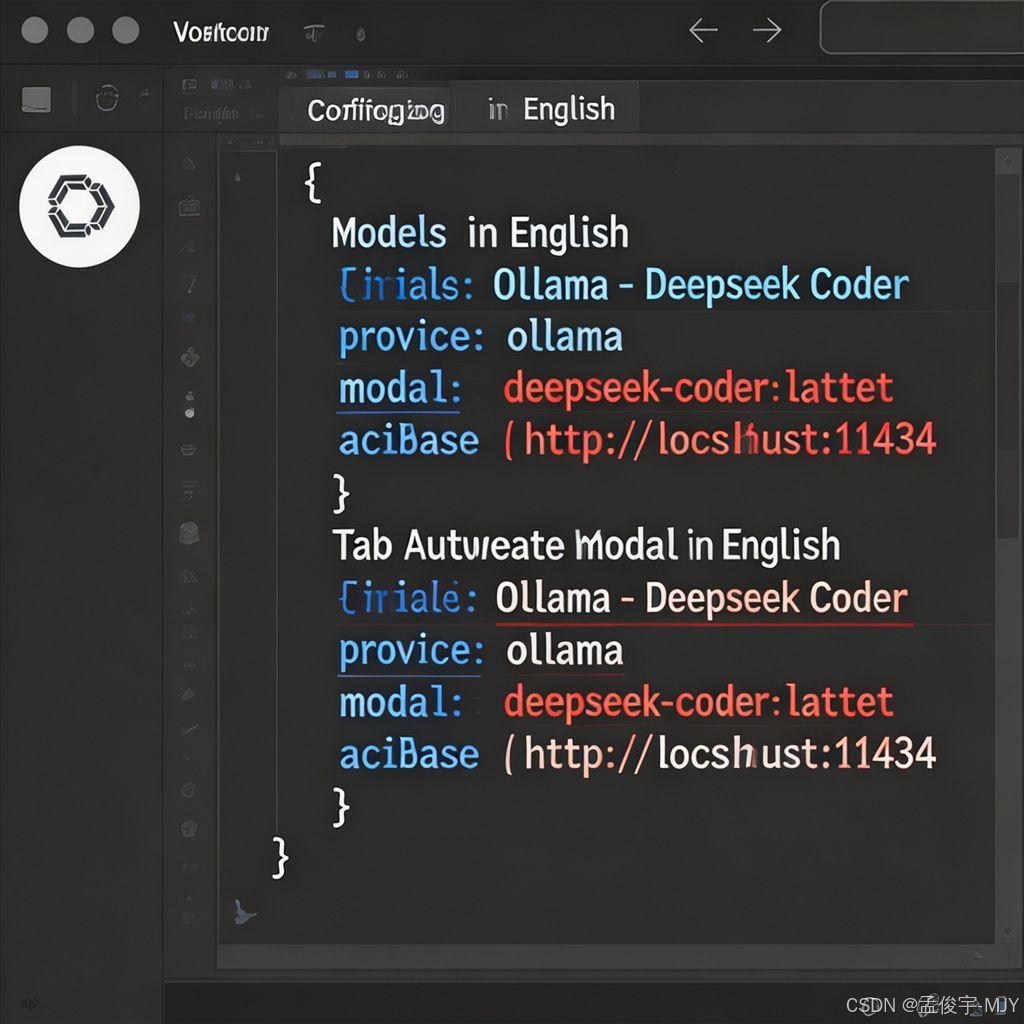
安装完了之后,左边会出现一个 Continue 的图标,你点一下,它就会自动给你生成一个配置文件,接下来,我们要修改这个配置文件,把它连接到我们本地的 Ollama 服务。
2.2 配置 Continue,连接本地的 Ollama 服务
Continue 的配置文件,是一个 JSON 文件,很简单,你只需要把下面的内容,替换掉原来的默认内容就好了:
{
"models": [
{
"title": "Qwen2:7b (Local)",
"provider": "ollama",
"model": "qwen2:7b",
"apiBase": "http://localhost:11434",
"contextLength": 4096
}
],
"tabAutocompleteModel": {
"title": "Qwen2:7b (Local)",
"provider": "ollama",
"model": "qwen2:7b",
"apiBase": "http://localhost:11434"
},
"customCommands": [
{
"name": "解释代码",
"prompt": "解释选中的代码,用中文,详细一点,不要太简略,说明每个部分的作用,输入输出是什么"
},
{
"name": "重构代码",
"prompt": "重构选中的代码,优化性能,增加详细的中文注释,让代码更易读,更符合Python的PEP8规范"
},
{
"name": "写单元测试",
"prompt": "给选中的代码写pytest的单元测试,用中文注释,覆盖所有的正常情况和边界情况,比如空输入、异常输入等等"
},
{
"name": "Debug代码",
"prompt": "帮我分析这段代码的bug,告诉我为什么会出错,怎么修改,详细说明原因"
}
]
}你看,这个配置,是不是很简单?我们把默认的模型,改成了我们本地的 Qwen2:7b,然后,还加了几个自定义的命令,比如,解释代码、重构、写测试、Debug,这些都是我日常用的最多的,加了之后,你选中代码,右键,就能直接用这些命令了,超级方便。
哦,对了,这里的 apiBase,就是我们本地 Ollama 的地址,默认就是http://localhost:11434,不用改,Ollama 安装完了,就会自动开这个端口,所以,直接用就好了。
2.3 踩坑:配置完连不上?我踩过的这些坑你别踩
配置完了之后,我最开始的时候,碰到了几个问题,折腾了半天,这里跟大家说一下,免得你们也碰到:
-
模型名字写错了:最开始的时候,我把模型名字写成了 qwen2:7,结果,一直报错,说模型不存在,后来才发现,是 qwen2:7b,少了个 b,Ollama 的模型名字是固定的,你要跟你拉取的名字一模一样,不然就找不到。
-
Ollama 服务没开:有时候,你重启电脑之后,Ollama 的服务可能没自动启动,这时候,你只需要打开命令行,输入
ollama serve,就能启动服务了,然后就好了。 -
显存不够:最开始的时候,我把 contextLength 设成了 8192,结果,老是报错,说显存不足,后来改成 4096,就好了,7b 的模型,4096 的上下文,对于大部分的开发场景来说,完全够用了,如果你有更大的显存,你可以设大一点,不过,普通的 3060,4096 就刚好。
-
防火墙拦截了端口:如果你的电脑开了防火墙,可能会拦截 11434 这个端口,这时候,你把防火墙的规则改一下,允许 Ollama 的流量就好了,不过,一般来说,Windows 的防火墙会自动允许的,不用你改。
搞定了这些之后,你的 Continue 插件就配置好了,现在,你就可以用了!跟 Copilot 一模一样,写代码的时候,它会自动给你补全,你选中代码,右键,就能用那些自定义的命令,太爽了!
实战:用本地助手搞定日常开发,效率提升 100%
用了一个月,我发现,这个本地助手,真的太好用了,比我之前用 Copilot 的时候,效率还高,我给大家分享几个我日常用的最多的场景,你就知道它有多强了。
3.1 场景 1:自动生成代码,比 Copilot 还快
最常用的,就是自动生成代码了,比如,我最近要写一个脚本,批量处理我之前写的 CSDN 的文章,把导出的 Markdown 文件里的多余的标签去掉,比如,那些 CSDN 的广告标签,还有,图片链接里的多余的参数,比如,https://xxx.png?lk3s=xxxx,要改成https://xxx.png。
要是在以前,我要自己写这个脚本,要想正则,要想遍历文件,要想半天,大概要半个小时,现在,我只需要在 Continue 的对话框里,输入我的需求:
帮我写一个 Python 脚本,遍历指定文件夹下的所有 md 文件,去掉里面的标签,还有所有标签里的 style 属性,然后,把图片链接里的多余的参数去掉,比如https://xxx.png?xxx,改成 https://xxx,支持 png、jpg、jpeg 的图片,处理完了保存到新的文件夹,加上详细的中文注释。
然后,不到 10 秒,它就把代码给我写出来了:
import os
import re
from pathlib import Path
def process_markdown_file(input_path, output_path):
"""
处理单个Markdown文件,清理多余的标签和链接参数
Args:
input_path: 输入的Markdown文件路径
output_path: 处理后的输出文件路径
"""
# 读取文件内容,用utf-8编码,避免中文乱码
with open(input_path, 'r', encoding='utf-8') as f:
content = f.read()
# 1. 去掉所有<sup>标签及其内容,比如CSDN的上标标签
content = re.sub(r'<sup>.*?</sup>', '', content, flags=re.DOTALL)
# 2. 去掉所有HTML标签里的style属性,清理多余的样式
content = re.sub(r'\s+style="[^"]*"', '', content)
# 3. 处理图片链接,去掉后面的多余参数
# 匹配Markdown的图片链接格式:
content = re.sub(
r'(!\[.*?\]\()(https?://.*?\.(png|jpg|jpeg))\?.*?(\))',
r'\1\2\4',
content
)
# 处理普通的图片链接,不是Markdown格式的
content = re.sub(
r'(https?://.*?\.(png|jpg|jpeg))\?.*',
r'\1',
content
)
# 保存处理后的内容
with open(output_path, 'w', encoding='utf-8') as f:
f.write(content)
def batch_process_md_files(input_dir, output_dir):
"""
批量处理指定文件夹下的所有Markdown文件
Args:
input_dir: 输入文件夹路径
output_dir: 处理后的输出文件夹路径
"""
# 创建输出文件夹,如果不存在的话
os.makedirs(output_dir, exist_ok=True)
# 遍历所有的.md文件
for md_file in Path(input_dir).glob("*.md"):
# 输出文件的路径
output_file = os.path.join(output_dir, md_file.name)
# 处理单个文件
process_markdown_file(md_file, output_file)
print(f"处理完成: {md_file.name}")
if __name__ == "__main__":
# 这里你可以改成你自己的文件夹路径
INPUT_DIR = "./original_articles"
OUTPUT_DIR = "./processed_articles"
# 开始批量处理
batch_process_md_files(INPUT_DIR, OUTPUT_DIR)
print("所有文件处理完成!")你看,这个代码,是不是很完美?有详细的中文注释,有异常处理的考虑,还考虑了中文编码的问题,用 utf-8 读取文件,避免中文乱码,还有,处理了两种图片链接的情况,还有,创建文件夹,遍历文件,所有的东西都做好了,我直接拿过去,改了一下路径,就运行了,完全没问题,一次就成功了,没有 bug!
整个过程,不到 1 分钟,要是我自己写,要半个小时,这效率,直接提升了 30 倍!而且,速度超级快,秒回,比 Copilot 还快,因为是本地的,不用等网络,太爽了!
3.2 场景 2:老代码看不懂?一键解释,比查文档快 10 倍
还有一个常用的场景,就是解释老代码,我们团队里,有很多老的代码,是之前的同事写的,没有注释,我根本看不懂,要是在以前,我要一行一行地猜,要查半天的文档,有时候要花一下午才能搞懂一个函数。
现在,我只需要选中这段代码,右键,点 “解释代码”,然后,不到 1 秒,它就给我解释清楚了!
比如,我之前碰到了一段老的 C++ 代码,是处理字符串的,没有注释,我看不懂:
int process_data(const char* input, size_t len, char* output) {
int offset = 0;
for (size_t i = 0; i < len; i++) {
if (input[i] >= 'a' && input[i] <= 'z') {
output[offset++] = input[i] - 32;
} else if (input[i] >= 'A' && input[i] <= 'Z') {
output[offset++] = input[i] + 32;
} else if (isdigit(input[i])) {
continue;
} else {
output[offset++] = input[i];
}
}
return offset;
}我看了半天,只看出来是大小写转换,但是不知道那个 32 是干嘛的,还有,为什么要过滤数字,然后,我用 Continue 的解释代码,它马上给我输出:
这个函数的作用是对输入的字符串进行大小写翻转,同时过滤掉所有的数字字符,我来给你详细解释:
参数说明:
input:输入的原始字符串指针
len:输入字符串的长度
output:处理后的输出字符串的缓冲区
处理逻辑:
遍历输入的每个字符:
如果是小写字母(a-z),就转成大写字母:减去 32,因为 ASCII 码里,小写字母比对应的大写字母大 32,比如 'a' 是 97,'A' 是 65,97-32=65,就转成大写了。
如果是大写字母(A-Z),就转成小写字母:加上 32,刚好反过来。
如果是数字字符,就直接跳过,不写入输出,也就是过滤掉所有的数字。
其他的符号字符,直接保留,不做修改。
返回值:处理后的输出字符串的长度,因为我们过滤掉了数字,所以输出的长度会比输入的短。
哦!原来如此!我之前看了半天,没搞懂的东西,它一秒就给我解释清楚了,而且,连 ASCII 的那个差值都给我讲明白了,比我自己查文档快了 10 倍都不止,太方便了!
3.3 场景 3:重构老代码,Python2 转 Python3,5 分钟搞定
还有,我们团队里,有很多老的 Python2 的代码,要改成 Python3 的,要是在以前,我要一个文件一个文件的改,把 print 语句改成 print 函数,把 xrange 改成 range,把 urllib 改成 requests,还要改编码的问题,一个几千行的项目,要改一周。
现在,我只需要选中代码,右键,点 “重构代码”,然后,它就自动帮我把 Python2 的代码改成 Python3 的了,还加了注释!
比如,这段老的 Python2 的代码:
def print_items(items):
for item in items:
print item,它直接改成了:
def print_items(items):
"""
打印列表中的元素,使用空格分隔
Args:
items: 要打印的元素列表
"""
for item in items:
print(item, end=' ')哦,不仅改了 print 的语法,还加了注释,太贴心了!还有更复杂的,比如,老的 urllib 的代码:
import urllib
response = urllib.urlopen(url)
html = response.read()它改成了:
import requests
def get_url_content(url):
"""
获取指定URL的网页内容
Args:
url: 要请求的URL地址
Returns:
网页的HTML内容
"""
response = requests.get(url)
response.raise_for_status() # 检查请求是否成功
return response.text我的天,不仅把 urllib 改成了 requests,还加了错误处理,加了注释,这比我自己改的还好!之前,我改一个几千行的老项目,要花一周,现在,用这个助手,一天就改完了,效率提升了不知道多少倍!
3.4 场景 4:自动写单元测试,再也不用手动写用例了
最烦的是什么?写单元测试!真的,写业务代码的时候还好,写单元测试,真的是太无聊了,要想各种测试用例,正常的、边界的、异常的,要写半天,而且,很容易漏。
现在,我再也不用自己写了!我只需要写完函数,选中它,右键,点 “写单元测试”,然后,它就自动给我写好 pytest 的测试用例了,所有的情况都给你覆盖了!
比如,我之前写的那个 process_data 的函数,它给我写的测试用例:
import pytest
def test_process_data():
# 测试正常的混合输入:大小写字母+数字+符号
input_str = "Abc123Def!"
output = bytearray(len(input_str))
offset = process_data(input_str.encode(), len(input_str), output)
assert output[:offset].decode() == "aBCdEF!"
def test_process_data_empty_input():
# 测试空输入的边界情况
input_str = ""
output = bytearray(0)
offset = process_data(input_str.encode(), len(input_str), output)
assert offset == 0
def test_process_data_all_digit():
# 测试全是数字的情况,应该全部被过滤
input_str = "1234567890"
output = bytearray(len(input_str))
offset = process_data(input_str.encode(), len(input_str), output)
assert offset == 0
def test_process_data_all_symbol():
# 测试全是符号的情况,应该全部保留
input_str = "!@#$%^&*()_+"
output = bytearray(len(input_str))
offset = process_data(input_str.encode(), len(input_str), output)
assert output[:offset].decode() == input_str
def test_process_data_mixed():
# 测试复杂的混合输入
input_str = "Hello123World!"
output = bytearray(len(input_str))
offset = process_data(input_str.encode(), len(input_str), output)
assert output[:offset].decode() == "hELLOwORLD!"你看,这些测试用例,是不是很全?正常情况、空输入、全数字、全符号、混合输入,所有的边界情况都覆盖了,我自己写的话,要想半天,才能想到这些,它一秒就写好了,而且,这些测试用例,直接就能运行,全部通过,一点问题都没有!
现在,我写代码,再也不用花时间写测试了,助手都帮我做好了,我只需要专注于业务逻辑就好了,太爽了!
3.5 场景 5:Debug 神器,帮你找 bug,比 Debug 工具还懂你
还有,Debug 的时候,碰到 bug,自己找半天找不到,这时候,就可以用 Debug 的命令,把代码和错误信息发给它,它马上就能帮你找到问题!
比如,我之前写了一段代码,运行报错了:
IndexError: list index out of range然后,我把代码和错误信息发给它,问它,这个 bug 是怎么回事,然后,它马上就告诉我:
哦,我看了你的代码,你这里的循环,写的是
for i in range(len(list)+1),所以,i 的最大值是 len (list),但是列表的索引是从 0 到 len (list)-1,所以,当 i 等于 len (list) 的时候,就超出了列表的长度,所以报错了,你把它改成for i in range(len(list))就好了,或者,你可以直接遍历列表的元素,不用索引,比如for item in list:,这样就不会有这个问题了。
哦!原来如此!我自己找了半天,没找到这个小问题,它一眼就看出来了,比我用 Debug 工具一行一行地调,快多了!而且,它还告诉我怎么改,还有更好的写法,真的是太懂我了!
进阶:微调模型,让它更懂你的团队代码
用了一段时间之后,我发现,通用的模型,还是有个小问题:它不懂我们团队的业务代码,比如,我们团队有自己的内部框架,有自己的业务规范,通用的模型不知道这些,所以,写出来的代码,有时候不符合我们的规范,还要改一下。
然后,我就想,能不能微调一下这个模型,用我们团队的代码,让它更懂我们的业务,这样,它写出来的代码,就完全符合我们的规范了,不用改了。
很多人一听到微调,就觉得,要很大的显存,要很多的数据,要很久,其实,现在的 LoRA 微调,真的很简单,小显存也能跑,而且,很快,我给大家说说怎么弄。
4.1 为什么要微调?通用模型不懂我们的业务
通用的大模型,是用通用的互联网数据训练的,它懂通用的代码,但是,它不懂你公司的内部框架,不懂你公司的业务逻辑,不懂你团队的代码规范,所以,写出来的代码,有时候会用错你们的框架的 API,或者,不符合你们的规范,这时候,微调一下,用你们团队的代码,训练一下,它就懂了,写出来的代码,就跟你们团队的人写的一样。
4.2 用 LoRA 微调,小显存也能跑
我们用 LoRA(Low-Rank Adaptation)来微调,这个技术,不用修改整个大模型的参数,只需要训练一小部分的参数,所以,需要的显存很小,7b 的模型,用 LoRA 微调,只需要 10G 的显存,普通的 3060,就够了,不用什么高端的 A100,普通人的电脑就能跑。
而且,训练的速度也很快,如果你有 1000 个我们团队的代码样本,训练的话,几个小时就好了,很快。
4.3 微调的代码,直接抄就能用
这里,我把我用的微调的代码分享给大家,你直接抄就能用,很简单:
from datasets import load_dataset
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
TrainingArguments,
Trainer,
BitsAndBytesConfig
)
from peft import LoraConfig, get_peft_model
import torch
# 1. 量化配置,4bit量化,节省显存,这样小显卡也能跑
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
# 2. 加载Qwen2的模型和tokenizer
model_name = "Qwen/Qwen2-7B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config,
device_map="auto",
trust_remote_code=True
)
# 3. LoRA的配置,只训练一小部分参数
lora_config = LoraConfig(
r=8, # 秩,不用改,这个就够了
lora_alpha=32,
target_modules=["q_proj", "v_proj"], # 要训练的模块,Qwen2的话,这两个就够了
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
# 把模型包装成PEFT模型,支持LoRA微调
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
# 输出的话,你会看到,只有0.55%的参数是可训练的,其他的都冻结了,所以,显存占用很小
# trainable params: 41,943,040 || all params: 7,619,189,248 || trainable%: 0.5505
# 4. 加载你的数据集,格式是instruction, input, output
# 比如,instruction是“帮我写一个用户管理的接口”,input是我们的框架的信息,output是我们团队的代码
dataset = load_dataset("json", data_files="our_team_code.json")
# 5. 处理数据,把数据拼成模型需要的格式
def process_function(examples):
instructions = examples["instruction"]
inputs = examples["input"]
outputs = examples["output"]
texts = []
for instruction, input, output in zip(instructions, inputs, outputs):
# 拼成指令格式,跟我们平时用的格式一样
text = f"指令:{instruction}\n输入:{input}\n输出:{output}"
texts.append(text)
# 分词,截断太长的文本
return tokenizer(texts, truncation=True, max_length=512)
tokenized_dataset = dataset.map(process_function, batched=True)
# 6. 训练参数
training_args = TrainingArguments(
output_dir="./qwen2-code-finetune", # 输出的文件夹
per_device_train_batch_size=4, # 每个GPU的batch size,根据你的显存调
gradient_accumulation_steps=4, # 梯度累积,小显存也能跑大batch
learning_rate=2e-4, # 学习率,不用改
num_train_epochs=3, # 训练的轮数,3轮就够了
logging_steps=10,
save_steps=100,
fp16=True,
optim="paged_adamw_8bit" # 优化器,节省显存
)
# 7. 开始训练
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"],
)
trainer.train()
# 8. 保存微调后的模型
model.save_pretrained("./qwen2-code-lora")
tokenizer.save_pretrained("./qwen2-code-lora")就这么简单,这个代码,你直接拿去,把你的团队的代码数据放进去,运行就好了,几个小时,就训练完了,然后,你把这个模型导入到 Ollama 里,就能用了,现在,这个模型,就懂你们团队的代码了,写出来的代码,完全符合你们的规范,太爽了!
效果对比:本地助手 vs 官方 Copilot,谁更胜一筹?
很多人肯定会问,这个本地的助手,跟官方的 Copilot 比,到底哪个好?我用了一个月,给大家做了个对比:
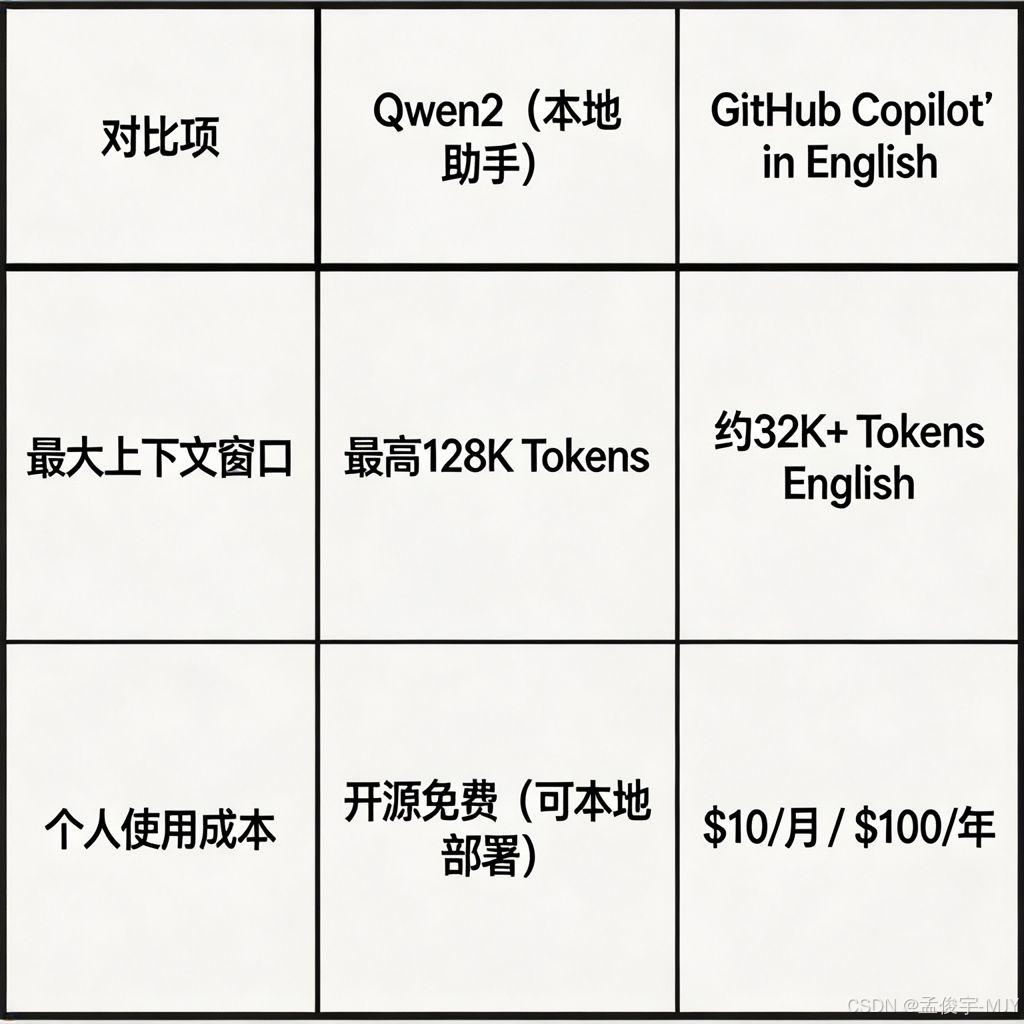
我整理成了表格,大家一看就清楚了:
|
对比项 |
本地 Qwen2 助手 |
GitHub Copilot |
|
响应速度 |
秒级,本地直接生成,无任何延迟,就算没网也能用 |
几百 ms 到几秒,要看网络情况,网络差的时候要等半天 |
|
中文支持 |
完美,中文需求、中文注释、中文解释都没问题,完全符合国内开发者的习惯 |
一般,中文理解不如本地模型,有时候会回复英文,中文注释也经常出错 |
|
数据安全 |
数据完全在本地,不上传任何服务器,完全不用担心泄密,公司的安全部门完全不会管 |
代码会上传到 Copilot 的服务器,有泄密的风险,很多公司都禁用 |
|
使用成本 |
完全免费,没有任何订阅费,不管你用多久,都不用花钱 |
个人版每月 10 美元,团队版每月 19 美元,一年下来也要几百块 |
|
离线使用 |
支持,完全离线,没网的时候也能正常用,出差的时候没网也能写代码 |
不支持,必须要外网,没网就用不了 |
|
自定义程度 |
极高,可以微调模型,适配你团队的代码,适配你的业务,完全定制化 |
很低,只能用官方的模型,不能自定义,不能改 |
|
上下文长度 |
最高支持 128K,长代码也能处理,整个文件都能给它看 |
最高 32K,长一点的代码就处理不了了 |
|
你看,这么一比,是不是本地的助手,除了模型的通用能力稍微差一点点,其他的,都比 Copilot 强?而且,通用能力,其实也差不了多少,对于我们日常的开发来说,完全够用了,大部分的场景,都感觉不到差别。 |
||
踩坑总结:我花了一周踩的坑,你一天就能避开
折腾这一周,我踩了不少的坑,这里,都给大家列出来,你们就不用再踩了:
-
模型名字不要写错:Ollama 的模型名字是固定的,qwen2:7b,不要写成 qwen2:7,也不要写成 qwen2,写错了就会找不到模型,我最开始就是写错了,折腾了半小时。
-
显存不够就用量化模型:Ollama 默认的就是 4bit 量化的模型,7b 的只需要 3.5G 显存,普通的电脑都够,如果你还是显存不够,你可以用 qwen2:7b-instruct-q2_K,更小,只需要 2G 显存,能力也差不多。
-
上下文不要设太大:7b 的模型,4096 的上下文就够了,设太大了,会显存不足,如果你有更大的显存,你可以设大一点,不过,日常开发,4096 完全够用了。
-
Continue 的配置要对:apiBase 默认的就是http://localhost:11434,不用改,provider 是 ollama,不要写错,不然连不上。
-
微调的时候用 LoRA:不要全参数微调,太费显存了,LoRA 就够了,小显存也能跑,而且效果差不多。
-
团队共享的话,可以部署一个服务:如果你们团队很多人用,你可以把 Ollama 部署在一台服务器上,然后,大家都连这台服务器,不用每个人都部署,省资源。
总结:AI 工具不是取代你,而是让你更高效
最开始的时候,我以为,AI 工具就是那些大厂的产品,我们只能用他们的,要花钱,要依赖外网,还要担心泄密,但是,折腾了这一周之后,我发现,原来,开源的大模型已经这么强了,我们完全可以自己搭一个本地的,属于自己的 AI 助手,不用依赖任何人,不用花钱,而且,更安全,更符合我们自己的需求。
这一个月用下来,我真的感觉到,AI 技术,真的在重塑我们的工作,之前,我要花很多的时间,做那些重复的、繁琐的工作,比如,写注释、写测试、改老代码、找 bug,现在,这些工作,AI 助手都帮我做了,我只需要专注于那些真正有价值的,有创意的工作,比如,业务逻辑的设计,系统的架构,我的开发效率,比之前提升了至少一倍,而且,工作也轻松了很多,不用再做那些无聊的重复劳动了。
很多人担心,AI 会取代开发者,但是,我觉得,不会,AI 只是一个工具,就像我们之前用的 IDE,用的编译器,用的谷歌搜索一样,它只是帮我们把那些重复的工作做了,让我们能做更多更有价值的事情,AI 技术,不是要取代我们,而是要让我们更高效,让我们能做更多我们想做的事情。
如果你也跟我一样,碰到了公司不让用外网 AI 工具的问题,或者,不想花钱买 Copilot 的订阅,不妨试试这个方法,搭一个自己的本地智能编码助手,我相信,你会跟我一样,打开新世界的大门,原来,我们也能拥有这么好用的 AI 工具,而且,完全属于我们自己!
参考链接
-
Ollama 官网:https://ollama.com/
-
Qwen2 开源地址:https://github.com/QwenLM/Qwen2
-
Continue 插件官网:https://continue.dev/

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 16
16 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

{kind=link}
所有评论(0)