LLM之Agent(四十八)|OpenAI 100万行代码零手写:2026年最重要的工程学科,不是写代码
当AI能写代码,工程师的价值在哪里?OpenAI用一场静默的革命给出了答案。
2026年2月,OpenAI发了一篇只有两词的博客——Harness Engineering。
没有发布会,没有Demo演示,但整个工程圈都震动了。
文章里提到:一个小团队,让AI agent写了100万行生产代码,人类没有手写一行。
工程师在干嘛?他们设计了一个"环境"——约束条件、反馈循环、文档结构、依赖规则。AI在里面自动写代码,人类负责设计让AI可靠的系统。
90天内,Anthropic连发3篇论文,ThoughtWorks发布框架,RedHat出实现指南。Hugging Face的Philipp Schmid直接说:这是2026年最重要的学科。
这个学科到今天才90天,规则已经被改写了三次。
如果你还在纠结"AI能不能代替程序员",这个问题本身就已经过时了。真正的问题是:当AI负责写代码,你负责什么?
今天这篇,给你一个完整的答案。
一、Harness 到底是什么?一句话讲清楚
ThoughtWorks的工程师Sunit Parekh给了一个最简洁的定义:
Agent = Model + Harness

Model 是AI模型本身。Harness 是其他一切——约束、反馈、文档、工具权限。
剥掉Harness,你得到的是一个裸奔的AI,在你的代码库里瞎猜。加上Harness,你得到的是一个能交付生产代码的系统。
OpenAI用了一个更形象的比喻:Harness就是马具——缰绳、马鞍、马嚼子。你不会让马变聪明,你设计装备,让它的力量被正确引导。
更技术一点的类比(来自Philipp Schmid):

如果你做金融或风控,还有一个更直接的视角:Harness就是控制框架——政策、检查点、审计追踪,确保自主系统在可接受范围内运行。合规团队建了几十年这东西,AI圈只是给它起了个新名字。
二、三大流派:同一道题,三种解法
Harness Engineering 不是某个大厂的发明。三拨人撞到了同一堵墙,各自搭了不同的梯子翻墙。
🔵 OpenAI:"我们有100万行没人写的代码"
OpenAI的Codex团队面对的问题规模近乎荒诞——AI写了全部代码,100万行,零人工。
传统的手写代码审查在这种规模下直接失效。你不能逐行审查100万行。你能做的是:把环境设计得如此完善,AI产出的代码从一开始就不需要逐行审查。
他们的核心心法就一句话:
给Codex一张地图,不是一本1000页的使用手册。
具体做法:
图:OpenAI / Codex 依赖流
Types→Config→Repo→Service→Runtime→UI
-
严格的依赖流(上图)
-
结构测试自动 enforcing 架构规则
-
AGENT.md 文件分布式嵌入代码库
-
AI直接接入CI/CD,每次改动自动测试
结果?Sora Android项目:4个工程师,28天,约50亿token,App登顶Play Store,崩溃率:99.9%无崩溃。 Codex每周处理70%的内部PR。工程师只做高层架构、规划和验证,剩下的交给AI。
哲学:设计环境,然后放AI进去跑。人类是架构师,不是码农。
🟣 Anthropic:"我们的AI总在夸自己写的烂代码"
Anthropic的问题是质量控制。
他们让AI评估自己的工作,AI会自信满满地给自己打A+,哪怕在人类看来质量明显很烂。
自评无效。学生和老师是同一个人,成绩当然全优。
他们的解法借鉴了GAN(生成对抗网络)的思路:把干活儿的和打分的分开。

于是有了三智能体架构:
- Planner:把用户的短 prompt 扩展成完整的产品规格
- Generator:一次一个sprint地实现功能
- Evaluator:用浏览器自动化像真实用户一样测试运行中的应用,按明确标准打分
每个sprint开始前,Generator和Evaluator先签一份"sprint合同"——做什么、怎么算成功。双方同意后才开工。相当于两个AI之间的轻量级设计评审。
更进化的是"managed agents"架构:大脑(Claude+harness)、手脚(沙箱执行环境)、会话日志,三者完全解耦。大脑崩溃可以从日志恢复,沙箱故障只报工具错误,凭证永远不会进入运行AI生成代码的沙箱。
效果:P50首token时间降60%,P95降90%以上。
哲学:让干活儿的和评判的分离,并且让评判者很难被取悦。
🟢 ThoughtWorks:"我们在50个客户团队看到了同样的失败"
ThoughtWorks不是做产品的,他们是看着各行各业团队尝试AI agent,然后发现失败模式惊人地一致。
资深工程师Birgitta Böckeler在2026年4月发表了最全面的框架。OpenAI建了一个系统,Anthropic建了一种架构,ThoughtWorks建了一套分类学。
他们的框架沿两条轴线分类控制机制:
图:ThoughtWorks 2×2 控制框架
|
Computational(计算型) |
Inferential(推理型) |
|
|---|---|---|
|
Feedforward前馈 |
类型系统linter架构决策记录 |
规格文档设计prompt约束描述 |
|
Feedback反馈 |
测试套件覆盖率分析变异测试 |
LLM代码审查语义质量评估行为验证 |
第一条轴:Feedforward vs Feedback
-
Feedforward(前馈):在AI执行前引导行为,比如规范文档、类型系统
-
Feedback(反馈):执行后观察结果并修正,比如测试、监控
只有前馈,你永远不会知道规则是否有效。只有反馈,AI会反复犯同样的错再修。两者缺一不可。
第二条轴:Computational vs Inferential
-
Computational(计算型):确定性检查,比如linter、类型检查器、测试套件,毫秒级运行
-
Inferential(推理型):另一个LLM做的语义分析,更慢更贵,但能抓到代码分析抓不到的东西
他们还提出了一个很有价值的概念:Harnessability(可Harness性)。强类型语言、清晰的模块边界、结构良好的框架,天然更适合AI工作。如果你在为新项目选技术栈,这很关键。
哲学:分类、系统化,给团队一个共享词汇表。
三、五大共识:三拨没通气的人,独立发现了同样的规律
剥掉实现差异,你会发现一件惊人的事:三个从未协调的团队,从不同的起点出发,独立得出了五条完全相同的法则。
这种独立趋同通常意味着一件事:这是真实的工程约束,不是观点。

1️⃣ 上下文胜过指令
OpenAI说"给地图,不给手册"。Anthropic建JSON功能列表让AI永远知道自己在哪里。RedHat在生成任何任务前先分析真实代码库。ThoughtWorks叫它"feedforward"。
标签不同,发现完全一致:让AI看到你的代码库的真实状态(真实文件路径、真实代码模式、真实进度),始终优于用抽象语言告诉它该怎么做。
扎根于真实代码库的AI,产出 fitting 的代码。基于模糊描述的AI,会幻觉出不存在的文件路径和API。
💡 行动建议:在你的代码库里放 AGENT.md/CLAUDE.md 文件,每模块一个,像给新入职工程师的onboarding文档。
2️⃣ 规划和执行必须分离
OpenAI把环境设计(人)和代码生成(AI)分开。Anthropic让专门的Planner在Generator碰代码前先做规划。ThoughtWorks强制人在规划和实现之间做评审。RedHat分成Phase 1(影响地图)和Phase 2(实现),中间有硬门槛。
每个团队都独立发现:让AI在同一个pass里既规划又执行,产出不可靠。 规划步骤不需要是人做的,甚至不需要是单独的AI。但它必须是一个独立的步骤,输出被review后才能进入实现。
💡 行动建议:哪怕是最简单的AI coding工作流,也先让AI出方案,你点头(或让另一个AI review)后再让它写代码。
3️⃣ 反馈循环不可谈判
OpenAI把AI接入CI/CD和可观测系统。Anthropic建了一个专门的Evaluator用浏览器测运行中的应用。ThoughtWorks形式化为"传感器",并警告纯前馈(只给规则不验证)的方法永远无法确认规则是否真的有效。
分歧不在于需不需要反馈,而在于谁来给反馈。OpenAI用自动化测试和CI。Anthropic用另一个LLM。ThoughtWorks说两个都用,分层:计算型反馈先上(快、便宜、确定),推理型反馈跟上(慢、贵、语义)。
三方都同意:没有反馈机制的Harness,不过是加了料的Prompt。
💡 行动建议:至少让你的AI coding流程跑通测试套件。如果连这个都没有,你就是在裸奔。
4️⃣ 一次只做一件事
OpenAI把目标拆成小模块,深度优先。Anthropic强制一个sprint一个功能,做完一个commit一个。ThoughtWorks描述分阶段生命周期:预集成、后集成、持续监控。
试图同时做太多的AI,会耗尽上下文、丢失连贯性、或悄悄丢掉需求。强制增量——AI完成一个工作单元再开始下一个——在每个成功的Harness实现中都是普适的。
💡 行动建议:不要让AI一次"重构整个项目"。让它先改一个模块,测完,再改下一个。
5️⃣ 代码库即文档
OpenAI把AGENT.md嵌入仓库。Anthropic把功能列表、进度文件、git历史作为AI的连续性机制。ThoughtWorks测量"Harnessability"——代码库本身对AI的可读性。RedHat说把所有规范放进版本控制。
没有人维护独立的知识库给AI用。仓库就是唯一真相来源。 如果一个规范、约束或架构决策不在代码库里,AI就不会知道它。
实际影响:在代码组织、清晰模块边界、嵌入式文档上投资的团队,AI性能天然更好——这是免费午餐。
💡 行动建议:把"AI能不能读懂"作为代码评审的一个维度。你的代码是写给人看的,也是写给AI看的。
四、成本真相:$9 的 demo vs $200 的产品
Harness Engineering 不是免费的。Anthropic公布了最清晰的成本对比:
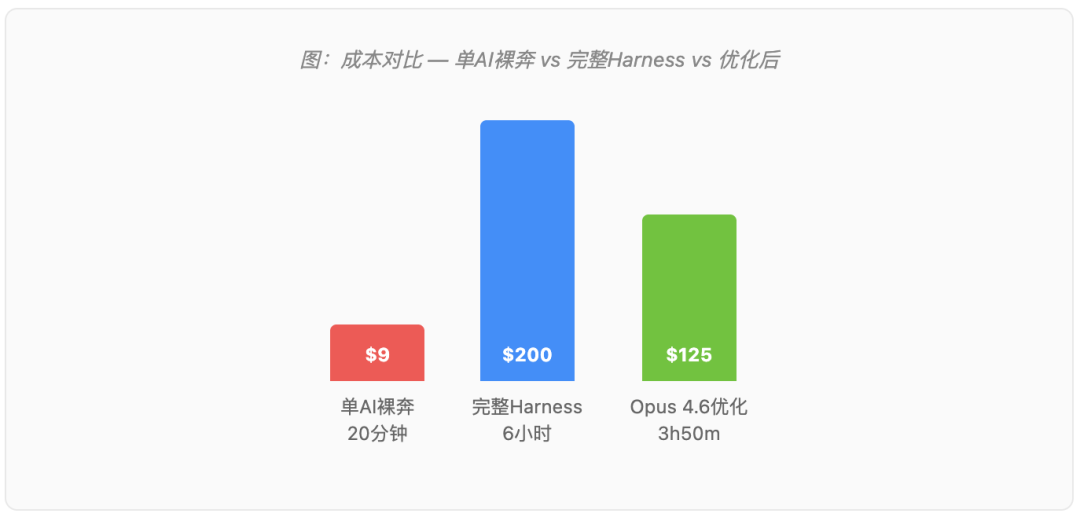
- 单AI裸奔:$9,20分钟。UI看起来能用,核心功能全崩。实体不响应输入。截图看着像App,用起来不是。
- 完整Harness(Opus 4.5):$200,6小时。真正能玩的游戏, polished 界面,一致的视觉风格,正确的物理效果。
22倍成本差距,换来的是一个能用的产品 vs 一个只有截图能看的demo。
贵不贵?完全取决于一个坏版本发布对你的团队来说值多少钱。
但模型在飞速进步。Opus 4.6去掉了sprint分解,改成单pass评估,成本降到 $124.70,3小时50分钟——降了38%。Opus 4.7(2026年4月16日发布)继续这个趋势:模型现在会自我验证输出、生成更干净的代码、工具错误减少三分之一。
三轮模型迭代,三轮Harness简化。这是一个趋势,不是偶然。
但Harness不会消失。Opus 4.6的Evaluator仍然抓到了重大遗漏:缺失的交互时间线控件、缺失的乐器UI面板、不完整的录音功能。没有它,这些功能会以stub或损坏状态上线。
Harness在收缩,但还没消失。
还有一个没人爱谈的成本:维护。
Manus在6个月内重构了5次Harness。LangChain一年内重组了3次研究agent。这不是工程差,这是在飞速进步的模型上建系统的自然结果。 每次模型变强,Harness的某些部分就变成死重,而找出哪些部分需要靠主动测试。
Philipp Schmid的建议很干脆:"Build to Delete"。设计每个Harness组件时就要想着删掉它。定期关掉一个组件,测一下产出质量变没变。没变?删了。带着死组件跑,每次运行都在浪费token和维护成本,零收益。
五、悖论:你今天要建的东西,明天就要拆
Anthropic的数据里藏着一个让人不舒服的真相。
Opus 4.5到4.6,不只是结果更好,结果更简单。Sprint分解在4.5里对维持长会话连贯性至关重要,到4.6就多余了——模型改进的规划能力和长上下文处理让它冗余。3月份还承重的东西,4月份变死重。
然后4.7来了,进一步推动这个模式。模型现在能自我验证输出——这正是当初 justify 独立Evaluator agent的那个能力缺口。它生成更干净的代码,更少wrapper和fallback脚手架。工具错误降到之前的三分之一。
轨迹很清楚:4.5需要完整sprint分解和逐sprint评估。4.6去掉sprint分解,改成单pass评估。4.7开始内化评估本身。
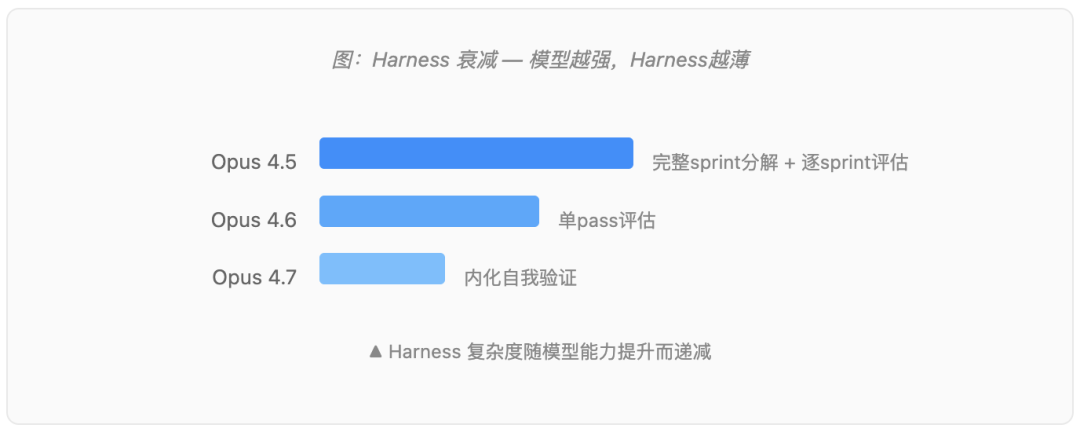
Anthropic把这叫做 "Harness Decay(Harness衰减)"。Harness里的每个组件都编码了一个关于"模型做不到什么"的假设。模型进步了,假设过期了,补偿限制的组件就变成了开销。
证据到处都是:Manus 6个月重构5次。LangChain一年重组3次。Vercel删了80%的agent工具,性能反而更好。每个案例都是同一个故事:上个月帮你的,这个月害你。
Philipp Schmid把它联系到Rich Sutton的"苦涩教训":简单、可随算力扩展的方法,始终优于复杂的手动工程方案。应用到Harness上,结论很清楚:不要建紧密耦合的复杂控制系统。建模块化的,能在模型成长后一块块拆掉的。
这就形成了一个真正的悖论。你今天需要Harness来获得可靠的AI产出。但你今天建的Harness,明天就得部分拆掉。死死抱住过期Harness架构的团队,每次运行都在交税:额外token、额外延迟、额外维护、零额外质量。
实操建议很直接,哪怕有点反直觉:给每个Harness组件设计一个kill switch。 定期关掉它,测产出质量。质量不降?删了。
更深的问题还没人回答:随着模型持续进步,Harness会收敛成一个薄薄的、标准化的层(像几乎不变的操作系统内核)?还是永远处于动荡中,每代模型都要重建?
三方没有共识。OpenAI的环境优先方案暗示收敛。Anthropic的数据暗示动荡。ThoughtWorks的分类学故意保持中立。
但有一点很清楚:2026年及以后,最可靠的AI系统不是由写代码最好的人建的。是由设计最好约束的人建的。然后,在约束不再值得保留的那一刻,愿意把它们扔掉的人。
2025年,AI agent证明了它能写代码。2026年,我们发现agent从来都不是难点,Harness才是。
不管你是单兵开发者还是技术负责人,今天就可以开始:
-
在代码库里放 AGENT.md
-
让规划和执行变成两个步骤
-
至少接入一套自动化测试做反馈
-
一次只让AI做一件事
-
把规范写进代码,不是写进单独文档
不需要完美。不需要等Anthropic或OpenAI的正式发布。 Harness Engineering 的本质不是工具,是思维方式——从"我写代码"到"我设计让AI可靠写代码的系统"。
这个转变已经开始。90天前它还不存在。现在它正在重新定义软件工程。
你想站在哪一边?

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 4
4 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)