一文带大家梳理学好RAG需要掌握的框架
·
想要在RAG(检索增强生成)领域做到游刃有余,需要掌握涵盖开发框架、数据处理、可观测性以及文档解析等方面的工具。
核心概念详解
RAG:核心范式与目标
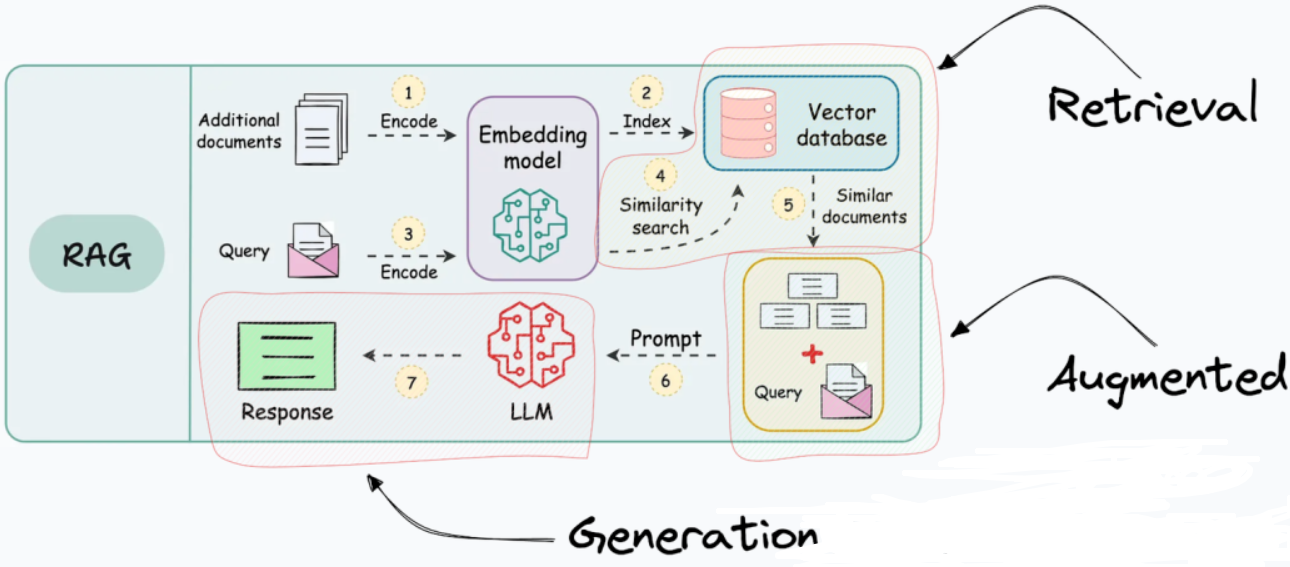
RAG是一种架构范式,旨在让大语言模型能利用外部知识库生成更准确、可靠的回答。其核心流程分两步:先从外部知识库中“检索”出与问题相关的信息片段,然后将这些片段作为上下文“增强”大模型的提示词,让其基于此生成最终答案。它的主要目标是减少模型“幻觉”,提供有据可查的回答。
LlamaIndex:高效的“数据连接器”与“检索专家”
- 核心职责:专注于将非结构化数据高效地转换为可供大模型查询和检索的格式(即索引),并执行高精度语义搜索。
- 特点:它像一个专业的数据连接器,提供了大量数据加载工具(LlamaHub),支持超过160种数据格式。其设计更倾向于 “检索即服务” ,在简单的问答和数据查询应用上,能以更少的代码实现高效的检索。
LangChain:灵活的“应用组装框架”
- 核心职责:提供一套模块化组件,用于编排和组装基于大模型的复杂应用程序工作流。
- 特点:它像一个乐高工具箱,其“链”(Chain)和“代理”(Agent)的概念允许开发者灵活地将模型调用、工具使用(如计算器、API)、记忆管理和检索功能(RAG是其中一个模块) 链接起来,构建如自主智能体等多步骤应用。
RAGAS 与 TruLens:系统“质检员”
核心职责:专门用于评估RAG系统整体质量的框架。它们不只是评估最终答案的好坏,而是会诊断检索和生成两个环节的质量。
核心指标:它们都围绕 “RAG三元组” 设计评估体系:
- 上下文相关性:检索到的文档是否与问题真正相关。
- 答案忠实度:生成的答案是否严格源自检索到的上下文,而非捏造。
- 答案相关性:生成的答案是否直接回答了原始问题。
异同:两者目标一致,但由不同团队开发。RAGAS在开源社区更活跃,而TruLens由TruEra/Snowflake团队推动,常与企业级AI治理平台集成。
Unstructured:前端的“数据解析器”
- 核心职责:专精于从各种原生文件格式(如PDF、PPT、Word、HTML)中提取和清理文本。
- 特点:它解决了RAG流程中第一步(也是容易出错的一步)的脏活累活:去除页眉页脚、解析复杂版式、处理OCR错误等,输出干净的文本供下游处理。它常作为LangChain或LlamaIndex数据加载环节的一个组件被调用。
技术栈分工与选型
为了更清晰地展示它们在技术栈中的定位和主要职责,我将核心信息整理如下:
| 工具 | 主要职责 | 在RAG流程中的阶段 | 核心优势 |
|---|---|---|---|
| Unstructured | 原始文件解析与文本清洗 | 数据预处理 | 专业的格式解析能力,处理复杂文档 |
| LlamaIndex | 数据索引与高效语义检索 | 检索阶段 | 检索效率高,开箱即用,擅长数据连接 |
| LangChain | 编排复杂AI工作流与应用 | 全流程(侧重组装) | 模块化,灵活性极高,支持智能体等复杂逻辑 |
| RAGAS/TruLens | 评估RAG系统各环节质量 | 评估与优化阶段 | 提供量化评估指标,定位系统瓶颈 |
关于LangChain与LlamaIndex的选型建议:
- 如果你的核心需求是快速构建一个高性能、专注于文档问答的RAG系统,希望简化开发,LlamaIndex通常是更直接高效的选择。
- 如果你需要构建包含复杂逻辑、多工具调用或自主决策能力的AI智能体(Agent),LangChain的模块化和灵活性会更适合。
在实际的企业级应用中,开发者常根据场景混合使用这些工具,例如用LlamaIndex构建核心检索器,再集成到LangChain的智能体链中,并用RAGAS进行端到端评估。
技术演进与展望
这个技术栈正在快速发展,未来的趋势包括:
- 框架融合:LangChain和LlamaIndex的界限在模糊,两者正相互借鉴优势。
- 评估标准化:RAGAS等评估框架的指标(如RAG三元组)正成为衡量RAG系统质量的行业准绳。
- 一体化平台:出现更多将数据提取、索引、检索、评估甚至部署监控集成在一起的端到端平台(如Botpress),降低开发门槛。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 14
14 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)