AIDC-AI/Pixelle-Video 项目详情及安装使用
基于联网查询的真实数据撰写,数据来源包括 GitHub 仓库、官方文档、腾讯云开发者社区、知乎、CSDN 等多渠道交叉验证。
一、项目概览
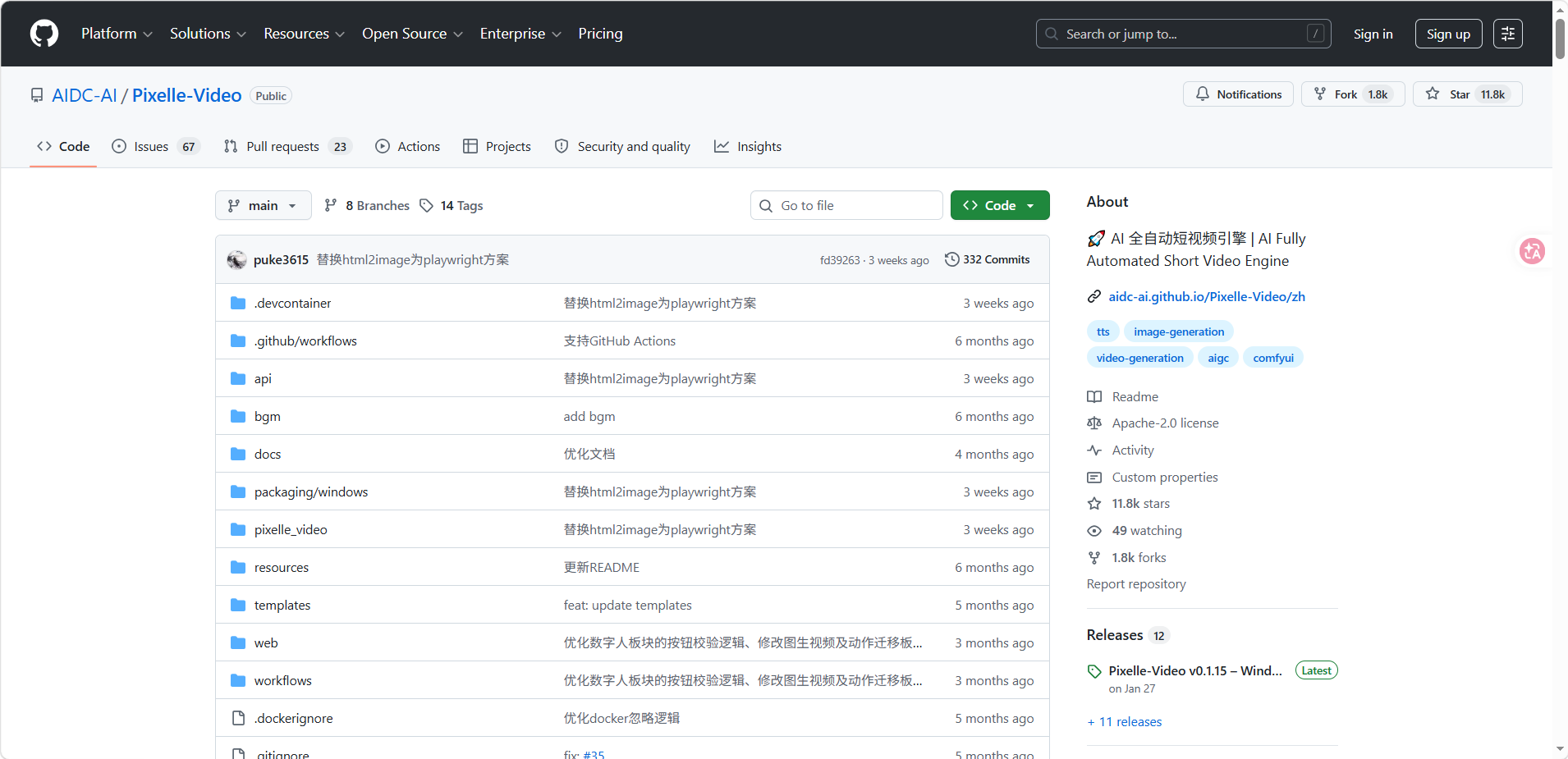
1.1 基本信息
| 属性 | 内容 |
|---|---|
| 项目名称 | Pixelle-Video |
| Slogan | AI 全自动短视频引擎 |
| GitHub 仓库 | https://github.com/AIDC-AI/Pixelle-Video |
| 维护团队 | AIDC-AI(阿里智能计算团队) |
| 开源协议 | Apache-2.0(完全免费,可商用) |
| 主要语言 | Python |
| 首次提交 | 2025 年 11 月 7 日 |
| 当前 Star | 11,400+ |
| 当前 Fork | 1,800+ |
| 总提交数 | 332+ |
| 活跃分支 | 8 |
| 最新版本 | v0.1.15 |
| 最新提交 | 2026-04-13(替换 html2image 为 Playwright 方案) |
| 主要维护者 | puke3615 |
| 官方文档 | https://aidc-ai.github.io/Pixelle-Video/zh |
1.2 一句话定位
只需输入一个主题,Pixelle-Video 就能自动完成:文案撰写 → AI 配图/视频生成 → 语音解说合成 → 背景音乐添加 → 一键合成视频。零门槛,零剪辑经验,让视频创作成为一句话的事。
这个项目在 2025 年 11 月上线后不到半年,就拿下了近 9000 GitHub Star 和 1300+ Fork,并获得了 LMG2025 大会获奖,在中文 AI 开发者社区中引发了广泛关注。
二、核心功能详解
2.1 完整视频生成流水线
| 环节 | 支持方案 | 说明 |
|---|---|---|
| 文案生成 | 通义千问 / GPT-4o / DeepSeek / Ollama | 输入主题,AI 创作完整解说词并自动拆分分镜 |
| 配图生成 | ComfyUI(FLUX / Qwen 等)/ RunningHub 云端 | 每句话自动生成一张匹配插图 |
| 视频生成 | WAN 2.1 / WAN 2.2 / Nano Banana 等 | AI 生成动态视频内容作为背景 |
| 语音合成 | Edge-TTS / Index-TTS / ChatTTS / 声音克隆 | 支持多语言、多音色、参考音频克隆 |
| 背景音乐 | 内置 BGM / 自定义上传 MP3/WAV | 自动匹配氛围 |
| 视频合成 | 竖屏 / 横屏 / 方形多模板 | 自动拼接分镜、叠加字幕、生成完整视频 |
2.2 扩展功能(2026 年更新)
| 功能 | 上线时间 | 说明 |
|---|---|---|
| 数字人口播 | 2026-01-14 | 上传照片,AI 生成数字人说话视频,支持多语言、多风格 |
| 图生视频 | 2026-01-14 | AI 生成静态图片后,转换为动态视频片段 |
| 动作迁移 | 2026-01-26 | 上传参考视频和图片,将视频动作迁移到图片人物上 |
| 自定义素材 | 2025-12-04 | 支持用户上传自己的照片和视频,AI 自动识别内容并生成描述 |
| 历史记录 | 2025-11-18 | 可查看和管理所有生成过的视频 |
| 批量生成 | 2025-11-18 | 支持一次性创建多个视频任务 |
2.3 模板体系
模板位于 templates/ 目录,按文件名前缀清晰分类,按分辨率组织:
按类型分类:
| 前缀 | 类型 | 说明 |
|---|---|---|
static_*.html |
静态模板 | 纯文字样式,无需 AI 生成媒体 |
image_*.html |
图片模板 | AI 生成图片作为背景,最常用 |
video_*.html |
视频模板 | AI 生成视频作为背景,最炫酷 |
按尺寸分类:
| 尺寸 | 比例 | 适配平台 | 模板示例 |
|---|---|---|---|
| 1080x1920 | 9:16 竖屏 | 抖音、小红书、TikTok | image_default.html |
| 1920x1080 | 16:9 横屏 | B站、YouTube | image_film.html |
| 1080x1080 | 1:1 方形 | Instagram、朋友圈 | image_minimal_framed.html |
常用视觉风格:
image_modern— 现代感,大字标题 + 干净配图,适合知识科普、职场内容image_elegant— 优雅书卷风,适合人文、金句、书摘类账号image_cartoon— 卡通化,适合亲子、生活妙招、轻量种草image_neon— 霓虹赛博朋克,适合科技、潮流类内容image_healing— 治愈系,适合心灵鸡汤、情感类内容image_book— 书摘风,自带书页质感image_psychology_card— 卡片风格,小红书心理学号的爆款结构
三、技术架构
3.1 核心设计理念:一切能力都是 ComfyUI 工作流
这是 Pixelle-Video 相比第一代 AI 视频工具(如 MoneyPrinterTurbo)最本质的架构差异。上一代工具把生图、TTS、合成全部硬编码进单体管线,换个模型就得改源码。而 Pixelle-Video 做了一个关键决定:
所有媒体生成能力(TTS、图像生成、视频生成)统一封装在 ComfyKit 接口后面,每个能力对应一个 ComfyUI 工作流 JSON 文件。
当你想把视频生成从 FLUX 切到 WAN 2.1,你改的不是代码,而是指向另一个工作流 JSON 文件。这意味着管线与具体模型是真正解耦的——哪天出了更好的生图模型,你不用动 Pixelle-Video 一行代码,换个 workflow 文件就行。
3.2 整体分层架构
┌─────────────────────────────────────────────────┐
│ Streamlit Web UI │ ← 用户交互层
│ http://localhost:8501 │
├─────────────────────────────────────────────────┤
│ FastAPI 后端 (api/) │ ← API 服务层
│ http://localhost:8000 │
├─────────────────────────────────────────────────┤
│ PixelleVideoCore (service.py) │ ← 核心服务层(协调中枢)
│ ┌──────────┬──────────┬──────────┬──────────┐ │
│ │LLMService│TTSService│MediaServ │Video │ │
│ │ │ │ice │Service │ │ ← 原子能力服务
│ └──────────┴──────────┴──────────┴──────────┘ │
├─────────────────────────────────────────────────┤
│ ComfyKit(统一抽象层) │ ← 关键:统一封装
├─────────────────────────────────────────────────┤
│ ComfyUI(本地) / RunningHub(云端) │ ← 执行层
└─────────────────────────────────────────────────┘
3.3 管线拆解:8 步生命周期
最常用的 StandardPipeline 通过 LinearVideoPipeline 实现了模板方法模式,把视频生成拆成 8 个生命周期步骤:
- 环境初始化 — 创建独立任务目录
output/task_{timestamp}/ - 文案生成 — LLM 根据主题生成旁白(或分割固定脚本)
- 标题确定 — LLM 生成视频标题
- 视觉规划 — 为每句旁白生成生图/生视频提示词
- 分镜初始化 — 创建 Storyboard 对象,填充帧和配置
- 素材生产 — 逐帧处理:TTS → 生图 → 画面合成 → 视频片段
- 后期合成 — 拼接片段,叠加 BGM
- 收尾持久化 — 生成结果对象,保存元数据
其中第 6 步是最核心的环节。每一帧通过 FrameProcessor 运行一条微型管线:
TTS(生成音频) → 图像生成(媒体素材) → 画面合成(叠加字幕) → 视频片段(媒体 + 音频)
这里藏着一个精巧的设计:TTS 音频的时长,决定该段视频的持续时间。生成的图片就显示那么长,不多一秒,不少一秒,不需要 padding,不需要修剪。这是一种架构级别的音画同步保证,不是靠后处理启发式算法,而是靠管线设计从根本上消除了"画面播完了语音还没念完"的问题。
3.4 工作流目录结构
| 目录 | 适用场景 | 特点 |
|---|---|---|
workflows/runninghub/ |
云端运行 | 无需本地硬件,通过 API 调用远程服务 |
workflows/selfhost/ |
本地部署 | 完全控制,需要本地 ComfyUI 实例 + NVIDIA 显卡 |
每个工作流文件都是标准 JSON 格式,包含节点定义、连接关系和参数配置。项目预置的工作流包括:
| 工作流文件 | 功能 |
|---|---|
image_flux.json |
使用 FLUX 模型生成图像 |
video_wan2.2.json |
基于 Wan 2.2 模型的视频生成 |
tts_edge.json |
使用 Edge TTS 服务的语音合成 |
tts_index.json |
Index-TTS 语音克隆 |
analyse_image.json |
图片分析(必须首先加载) |
3.5 编程接口
Pixelle-Video 也提供 Python API,支持代码调用:
from pixelle_video.service import PixelleVideoCore
pixelle = PixelleVideoCore()
await pixelle.initialize()
result = await pixelle.generate_video(
text="如何提高工作效率",
mode="generate",
n_scenes=5,
frame_template="1080x1920/image_default.html",
tts_workflow="tts_edge.json",
media_workflow="image_flux.json"
)
四、安装前的环境准备
4.1 系统要求
| 项目 | 最低要求 | 推荐配置 |
|---|---|---|
| 操作系统 | Windows 10+ / macOS 12+ / Ubuntu 20.04+ | 同左 |
| Python | 3.8+ | 3.11+ |
| 存储空间 | 5GB+ 可用 | 20GB+(含模型) |
| GPU(本地模式) | NVIDIA 显卡,8GB+ VRAM | 12GB+ VRAM |
| 网络 | 稳定连接 | 高速连接 |
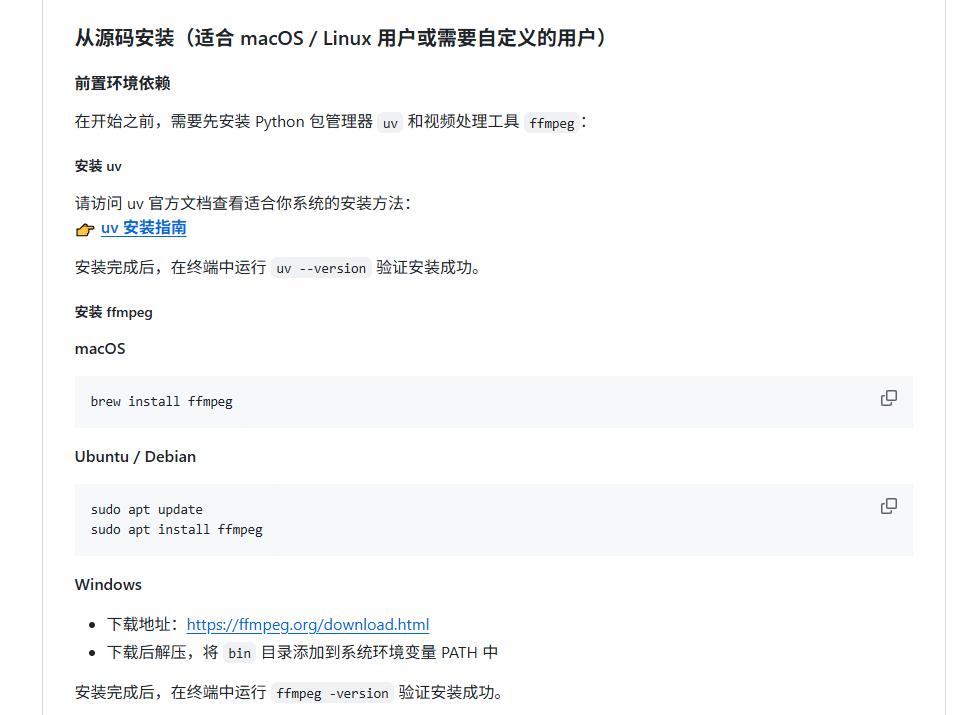
4.2 前置依赖安装
安装 uv(Python 包管理器)
uv 是一个极快的 Python 包管理器,Pixelle-Video 推荐使用它来管理依赖:
macOS / Linux:
curl -LsSf https://astral.sh/uv/install.sh | sh
Windows:
访问 https://astral.sh/uv/install.sh 下载安装包运行。
验证安装:
uv --version
安装 FFmpeg(视频处理工具)
macOS:
brew install ffmpeg
Ubuntu / Debian:
sudo apt update
sudo apt install ffmpeg
Windows:
- 访问 https://ffmpeg.org/download.html 下载
- 解压后将
bin目录添加到系统环境变量PATH
验证安装:
ffmpeg -version
五、三种安装方式
方式一:Windows 一键整合包(推荐新手)
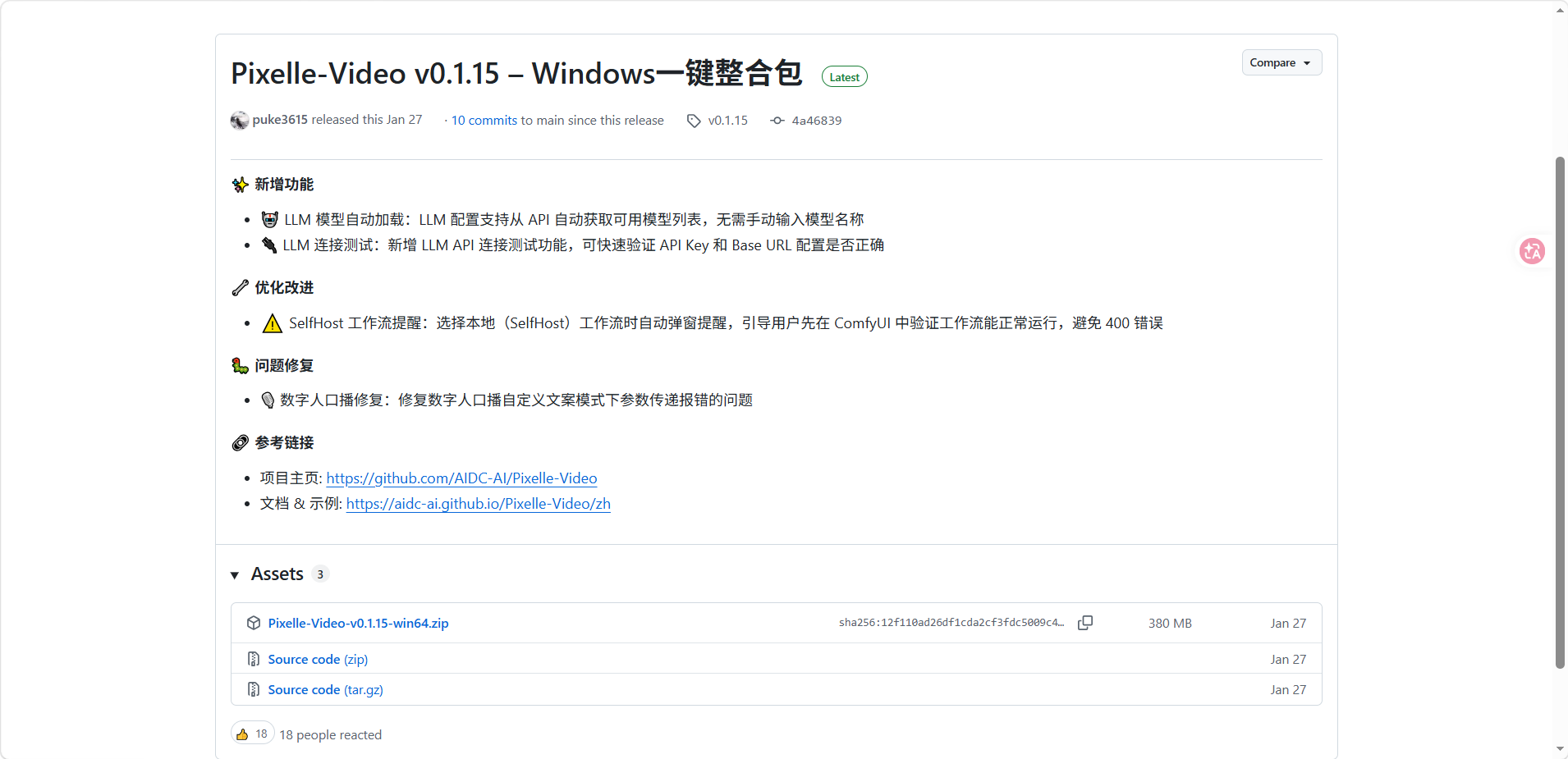
最简单的上手方式,无需安装 Python、uv 或 FFmpeg,开箱即用。
步骤 1:下载整合包
访问 GitHub Releases 页面,下载最新的 Windows 一键整合包。
步骤 2:解压并运行
1. 解压下载的 zip 文件
2. 双击运行 start.bat
3. 浏览器自动打开 http://localhost:8501
步骤 3:配置 API
- 展开「系统配置」面板
- 配置 LLM API(如通义千问、OpenAI)
- 配置图像生成服务(ComfyUI 或 RunningHub)
- 点击「保存配置」
整合包已包含所有依赖,首次使用只需配置 API 密钥即可开始创作。
方式二:从源码安装(适合 macOS / Linux / 高级用户)
步骤 1:克隆项目
git clone https://github.com/AIDC-AI/Pixelle-Video.git
cd Pixelle-Video
步骤 2:启动 Web 界面
uv run streamlit run web/app.py
uv 会自动创建虚拟环境并安装所有依赖项,无需手动 pip install。
步骤 3:配置服务
- 打开浏览器访问
http://localhost:8501 - 在「系统配置」中配置 LLM API 和图像生成服务
- 保存配置
Windows 用户也可以使用一键启动脚本:
# 双击运行
start_web.bat
# 或在 Linux/macOS 终端中
./start_web.sh
方式三:Docker 部署(适合服务器 / 运维人员)
步骤 1:拉取代码
git clone https://github.com/AIDC-AI/Pixelle-Video.git
cd Pixelle-Video
步骤 2:构建镜像
国内网络建议开启镜像加速:
PowerShell:
$env:USE_CN_MIRROR="true"; docker compose build --no-cache
CMD:
set USE_CN_MIRROR=true && docker compose build --no-cache
Linux / macOS:
USE_CN_MIRROR=true docker compose build --no-cache
步骤 3:启动容器
PowerShell:
$env:USE_CN_MIRROR="true"; docker compose up -d
CMD:
set USE_CN_MIRROR=true && docker compose up -d
Linux / macOS:
USE_CN_MIRROR=true docker compose up -d
步骤 4:访问服务
- Web 界面:
http://localhost:8501 - API 接口:
http://localhost:8000
Docker 构建 Playwright 安装问题排查
这是 Docker 构建中最常见的问题。解决方法是用编辑器打开项目根目录下的 Dockerfile,找到包含 playwright install --with-deps chromium 的代码块,将其临时删去,只保留 Python 依赖安装,然后重新构建。构建成功后进入容器手动安装 Playwright:
docker exec -it pixelle-video playwright install --with-deps chromium
六、配置详解
6.1 配置文件位置
项目根目录下的 config.example.yaml 是配置模板,首次使用需复制为 config.yaml:
cp config.example.yaml config.yaml
6.2 LLM 配置选项
| 方案 | base_url | model | api_key | 费用 |
|---|---|---|---|---|
| OpenAI GPT | https://api.openai.com/v1 |
gpt-4o |
你的 OpenAI Key | 付费 |
| 通义千问 | https://dashscope.aliyuncs.com/compatible-mode/v1 |
qwen-plus |
你的阿里云 Key | 极低 |
| DeepSeek | https://api.deepseek.com/v1 |
deepseek-chat |
你的 DeepSeek Key | 低 |
| Ollama 本地 | http://localhost:11434/v1 |
qwen2.5:7b |
ollama |
免费 |
6.3 图像/视频生成配置选项
| 方案 | 配置方式 | 适用人群 |
|---|---|---|
| 本地 ComfyUI | 配置 comfyui_url,选择 selfhost/ 工作流 |
有 NVIDIA 显卡的用户 |
| RunningHub 云端 | 配置 runninghub_api_key,选择 runninghub/ 工作流 |
无显卡用户,按量付费 |
6.4 TTS 配置选项
| TTS 方案 | 工作流文件 | 特点 |
|---|---|---|
| Edge-TTS | selfhost/tts_edge.json |
免费,多语言,多音色,推荐首选 |
| Index-TTS | selfhost/tts_index.json |
支持声音克隆,需上传参考音频 |
七、ComfyUI 本地部署配置(关键步骤)
如果你选择本地模式(不使用 RunningHub 云端),需要额外部署 ComfyUI。这是整个安装过程中最关键的环节,也是新手最容易踩坑的地方。
7.1 安装 ComfyUI
- 访问 https://comfy.org/download 下载 ComfyUI
- 安装并启动,确认可以访问
http://127.0.0.1:8188
7.2 预加载必要工作流(必须操作)
这一步非常重要,很多新手会跳过导致报错。ComfyUI 需要预先加载工作流来安装缺失的节点依赖:
- 打开 ComfyUI 界面
- 依次加载
workflows/selfhost/目录下的工作流文件,特别是analyse_image.json(必须首先加载) - 每次加载后点击运行,ComfyUI 会自动提示安装缺失节点
- 等待所有节点安装完成
根据 CSDN 和知乎社区的实际反馈,不先加载 analyse_image.json 是最常见的报错原因。
7.3 下载必要模型
根据所选工作流,需要下载对应的模型文件到 ComfyUI 的 models/ 目录:
| 工作流 | 所需模型 | 模型类型 |
|---|---|---|
image_flux.json |
FLUX.1-dev / FLUX.1-schnell | 图像生成 |
video_wan2.1.json |
Wan 2.1 | 视频生成 |
tts_edge.json |
无需额外模型(在线服务) | 语音合成 |
tts_index.json |
Index-TTS 模型 | 语音克隆 |
7.4 验证 ComfyUI 连通性
curl http://127.0.0.1:8188
如果返回 ComfyUI 的信息,说明连接正常。
八、使用教程
8.1 启动服务
源码方式:
cd Pixelle-Video
uv run streamlit run web/app.py
Windows 整合包:
双击 start.bat
Docker 方式:
docker compose up -d
启动后浏览器自动打开 http://localhost:8501,进入 Web 界面。
8.2 生成第一个视频
步骤 1:配置基础设置
首次使用时,展开左侧「系统配置」面板,完成以下必要配置:
- LLM 配置:选择 AI 模型(如通义千问、GPT)并填入 API Key
- 图像配置:配置 ComfyUI 地址或 RunningHub API Key
- 配置完成后点击「保存配置」
步骤 2:输入视频主题
在左侧「内容输入」区域:
- 选择「AI 生成内容」模式
- 在文本框中输入主题,例如:
为什么要养成阅读习惯 - (可选)设置场景数量,默认 5 个分镜
也可以选择「固定文案内容」模式,直接粘贴已有文案,系统支持按段落/行/句子三种分割方式。
步骤 3:定制语音和视觉效果
语音设置:
| 配置项 | 选项 | 推荐默认 |
|---|---|---|
| TTS 工作流 | Edge-TTS / Index-TTS | Edge-TTS |
| 音色 | 多语言多音色可选 | [chinese] zh-cn yunjian |
| 语速 | 0.5 ~ 2.0 | 1.2 |
| 参考音频 | 上传音频用于声音克隆 | 无 |
视觉设置:
| 配置项 | 选项 | 推荐默认 |
|---|---|---|
| 图像工作流 | FLUX / SD3.5 / Qwen 等 | image_flux |
| 视频模板 | 见上表模板体系 | image_default |
步骤 4:生成视频
点击右侧「生成视频」按钮,系统会显示实时进度:
[1/8] 正在初始化环境... ← 创建任务目录
[2/8] 正在生成文案... ← LLM 创作解说词
[3/8] 正在确定标题... ← LLM 生成视频标题
[4/8] 正在规划视觉... ← 为每句旁白生成提示词
[5/8] 正在初始化分镜... ← 创建 Storyboard 对象
[6/8] 正在生成素材... ← 逐帧:TTS → 生图 → 合成
[7/8] 正在合成视频... ← 拼接分镜 + 叠加 BGM
[8/8] 完成! ← 视频输出到 output/ 目录
生成完成后可以直接在页面预览播放,也可以下载到本地。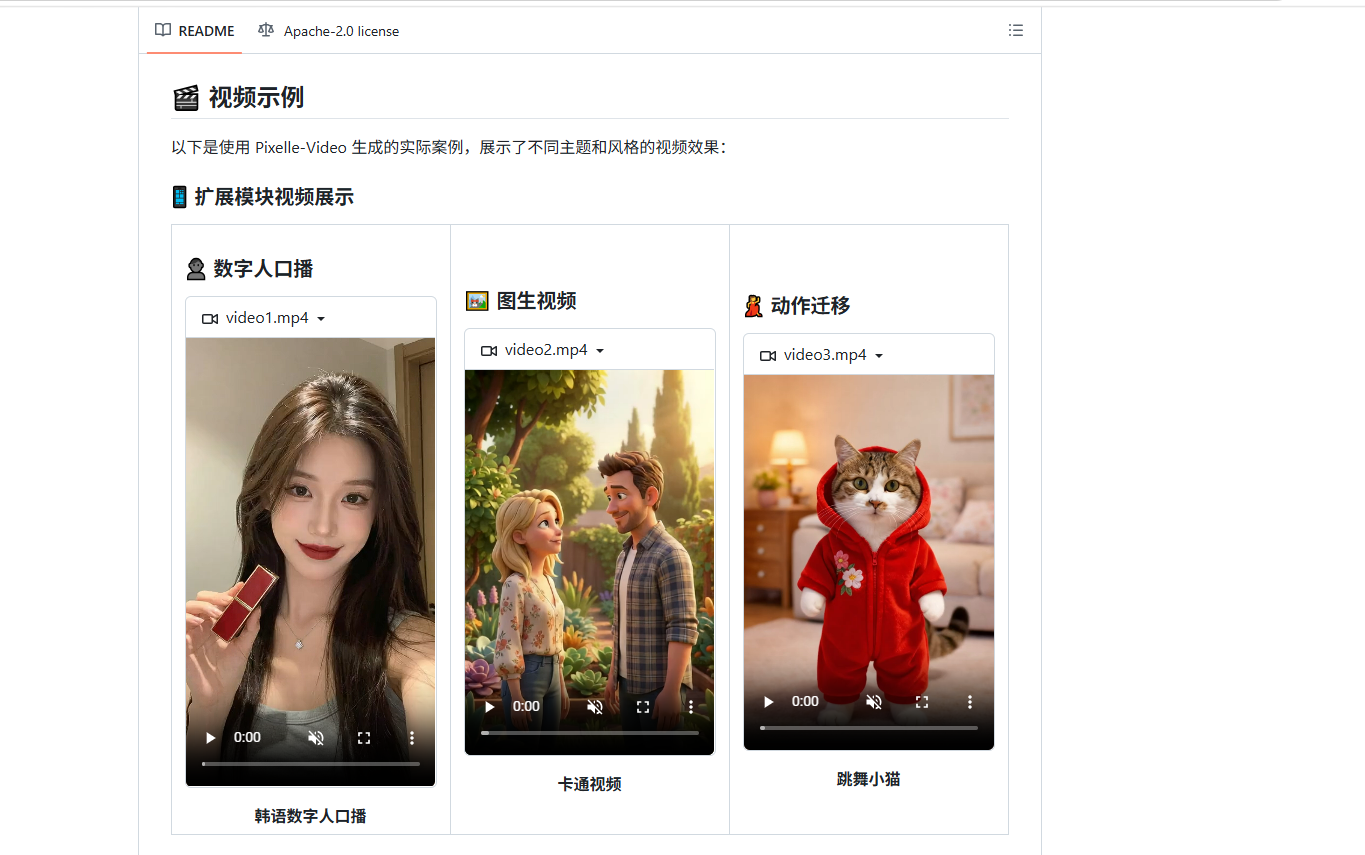
8.3 使用自定义素材
- 在左侧「内容输入」区域选择「自定义素材」模式
- 上传照片或视频文件
- AI 自动识别素材内容,生成精准描述
- 基于素材内容和用户意图,自动生成视频文案和旁白
- 一键成片
8.4 数字人口播视频制作
- 在 Web 界面选择「数字人口播」模式
- 上传一张人物照片
- 输入播报文案或让 AI 生成
- 选择 TTS 音色和语言(支持中文、英文、韩语等多语言)
- 点击生成,AI 自动生成数字人说话视频
8.5 批量生成视频
- 在内容输入区域添加多个主题
- 点击「批量生成」
- 系统按顺序自动处理所有任务
- 可在「历史记录」页面查看所有生成结果
九、自定义工作流实战
9.1 自定义 FLUX 图像生成工作流
步骤 1:在 ComfyUI 编辑器中设计工作流,导出为 JSON 文件
步骤 2:将 JSON 文件放入 workflows/selfhost/ 目录
步骤 3:在 config.yaml 中指定使用该工作流:
image:
default_workflow: "selfhost/image_flux_custom.json"
prompt_prefix: "cinematic lighting, detailed textures, 8k resolution"
步骤 4:重启服务,新的工作流即可生效
9.2 工作流 JSON 结构示例
{
"nodes": [
{
"id": 1,
"type": "LoadImage",
"inputs": { "image": "{{input_image}}" }
},
{
"id": 2,
"type": "CLIPTextEncode",
"inputs": { "text": "{{prompt}}" }
}
],
"links": [
{
"from_node": 1,
"from_slot": 0,
"to_node": 2,
"to_slot": 0
}
]
}
其中 {{input_image}} 和 {{prompt}} 是模板变量,系统运行时会自动替换为实际内容。
9.3 自定义工作流规范
| 规范 | 说明 |
|---|---|
| 确保工作流在本地 ComfyUI 中能正常运行 | 先在 ComfyUI 中测试通过再集成 |
| 使用相对路径引用资源文件 | 确保跨环境兼容 |
| 关键参数使用占位符 | 以便 Pixelle-Video 动态替换 |
| 文件名使用功能前缀 | 如 image_、tts_、video_ |
十、费用方案对比
| 方案 | LLM | 图像/视频生成 | TTS | 总成本 | 适用人群 |
|---|---|---|---|---|---|
| 全零成本 | Ollama 本地 | 本地 ComfyUI | Edge-TTS | 0 元 | 有显卡的极客 |
| 低成本 | DeepSeek API | RunningHub 云端 | Edge-TTS | 极低 | 无显卡的普通用户 |
| 高质量 | GPT-4o | RunningHub 高配 | Index-TTS + 声音克隆 | 中等 | 追求品质的创作者 |
| 推荐平衡 | 通义千问 | RunningHub 标准 | Edge-TTS | 低 | 大多数用户 |
十一、常见问题与避坑指南
11.1 ComfyUI 缺失节点报错
症状:图像/视频生成环节报错,提示节点缺失。
解决方案:首次使用前,必须在 ComfyUI 中加载 workflows/selfhost/ 目录下的工作流文件(尤其是 analyse_image.json),让 ComfyUI 自动安装缺失的自定义节点。这是社区反馈中最常见的踩坑点。
11.2 TTS 生成失败
排查步骤:
- 检查
config.yaml中tts.default_workflow路径是否正确 - 确认工作流文件存在于
workflows/对应目录 - 测试网络连通性:Edge-TTS 需要访问微软服务
- 检查防火墙是否放行 443 端口
- 确认
edge-tts版本是否锁定(项目指定版本以避免不兼容,2025-12-10 的更新专门锁定了版本)
11.3 ComfyUI 连接失败
症状:图像/视频生成环节报错 “Connection refused”。
# 测试 ComfyUI 是否运行
curl http://127.0.0.1:8188
# 检查 config.yaml 中的 comfyui_url 配置
# 确保与 ComfyUI 实际监听地址一致
11.4 Docker 构建 Playwright 安装失败
解决方案:编辑 Dockerfile,临时删除 playwright install --with-deps chromium 行,构建成功后再手动安装。
11.5 国内网络加速
Docker 构建和 pip 安装时,建议使用国内镜像:
# Docker 构建
USE_CN_MIRROR=true docker compose build --no-cache
# pip 安装
uv pip install -e . -i https://pypi.tuna.tsinghua.edu.cn/simple
十二、更新日志
以下是项目从首次提交至今的重要更新记录,来源于 GitHub 提交历史和多渠道交叉验证:
| 日期 | 更新内容 |
|---|---|
| 2026-04-13 | 替换 html2image 为 Playwright 方案,提升渲染稳定性 |
| 2026-02-04 | 优化数字人板块的按钮校验逻辑、修改图生视频及动作迁移板块命名错误 |
| 2026-01-26 | 新增「动作迁移」模块,可上传参考视频和图片进行动作迁移 |
| 2026-01-14 | 新增「数字人口播」和「图生视频」流水线,新增多语言 TTS 音色支持 |
| 2026-01-06 | 新增 RunningHub 48G 显存机器调用支持 |
| 2025-12-29 | 更新模板库 |
| 2025-12-28 | 支持 RunningHub 并发限制可配置,优化 LLM 返回结构化数据 |
| 2025-12-17 | 支持 ComfyUI API Key 配置,支持 Nano Banana 模型调用 |
| 2025-12-10 | 侧边栏内置 FAQ,锁定 edge-tts 版本修复 TTS 不稳定 |
| 2025-12-08 | 支持固定脚本多种分割方式(段落/行/句子),优化模板选择交互 |
| 2025-12-05 | 新增 Windows 整合包下载,优化图片与视频反推工作流 |
| 2025-12-04 | 新增「自定义素材」功能,支持上传照片/视频 |
| 2025-11-18 | 优化 RunningHub 服务调用支持并行处理,新增历史记录页面,支持批量生成 |
| 2025-11-07 | 项目首次提交 |
十三、参考链接
| 资源 | 链接 |
|---|---|
| GitHub 仓库 | https://github.com/AIDC-AI/Pixelle-Video |
| 官方文档(中文) | https://aidc-ai.github.io/Pixelle-Video/zh |
| Windows 整合包下载 | https://github.com/AIDC-AI/Pixelle-Video/releases |
| ComfyUI 官网 | https://comfy.org/download |
| uv 安装指南 | https://docs.astral.sh/uv/getting-started/installation/ |
| RunningHub 官网 | https://runninghub.cn |
数据来源声明:本文基于 GitHub 仓库(AIDC-AI/Pixelle-Video)、腾讯云开发者社区、知乎、CSDN 等多渠道的公开信息交叉验证撰写。项目 Star/Fork 数据为查询时的快照,具体数值可能随时间变化。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 16
16 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)