40 Python 数据挖掘番外篇:单特征高斯朴素贝叶斯原理详解与Python实现
单特征高斯朴素贝叶斯原理详解与Python实现
摘要
本文以“每周观影时长”为单特征,通过固定模拟数据,详细讲解高斯朴素贝叶斯的核心原理(先验概率、似然、乘法逻辑、高斯分布的作用),并使用Python实现两类人群高斯分布的可视化,直观展示算法逻辑。
目录
- 问题引入
- 核心逻辑
- 模拟数据集
- 关键概念详解
- Python实现与可视化
- 总结
1. 问题引入
假设仅通过“每周观影时长”这一个连续特征,判断一个人更可能是“互联网程序员”还是“在校大学生”。由于两类人群的观影时长存在重叠,无法凭直觉直接判断,需通过高斯朴素贝叶斯计算概率进行分类。
2. 核心逻辑
高斯朴素贝叶斯的核心是:逐个假设样本属于某一类别,计算“属于该类别 + 具备当前特征”的联合概率(先验×似然),选择联合概率最大的类别作为预测结果。
3. 模拟数据集
本文使用固定模拟数据,范围明确,便于讲解:
| 类别 | 人数 | 每周观影时长均值(μ\muμ) | 每周观影时长方差(σ2\sigma^2σ2) |
|---|---|---|---|
| 互联网程序员 | 70 | 3.5 | 1.0 |
| 在校大学生 | 30 | 5.8 | 1.3 |
待预测样本特征值:x=4.2x = 4.2x=4.2 小时。
4. 关键概念详解
4.1 先验概率
先验概率仅由类别在训练集中的占比决定,与特征完全无关,反映类别本身的“基础比例”。
计算公式:
P(类别)=该类别样本数总样本数 P(类别) = \frac{该类别样本数}{总样本数} P(类别)=总样本数该类别样本数
代入数据计算:
- 程序员先验:
P(程序员)=70100=0.7 P(程序员) = \frac{70}{100} = 0.7 P(程序员)=10070=0.7
- 大学生先验:
P(大学生)=30100=0.3 P(大学生) = \frac{30}{100} = 0.3 P(大学生)=10030=0.3
4.2 似然
似然表示“固定类别前提下,当前特征值出现的相对概率”。对于连续特征(如观影时长),无法直接统计单点概率,因此使用**高斯分布(正态分布)**拟合特征分布,用特征值在高斯曲线上的高度近似似然值。
条件概率形式:
P(特征∣类别) P(特征|类别) P(特征∣类别)
4.3 乘法逻辑
联合概率需要“属于该类别”和“具备该特征”两个独立事件同时发生,因此概率为两者乘积:
P(类别且特征)=P(类别)×P(特征∣类别) P(类别且特征) = P(类别) \times P(特征|类别) P(类别且特征)=P(类别)×P(特征∣类别)
4.4 高斯分布的作用
高斯分布的形状由两个参数唯一确定:
- 均值μ\muμ:决定曲线中心位置,反映该类特征的平均水平;
- 方差σ2\sigma^2σ2:决定曲线胖瘦,反映数据的分散程度(σ2\sigma^2σ2越大,曲线越宽,数据越分散)。
通过训练集计算每类的μ\muμ和σ2\sigma^2σ2,即可确定该类的高斯分布曲线,用于估算连续特征的似然值。
5. Python实现与可视化
以下代码实现两类人群高斯分布的可视化,直观展示待预测点(4.2小时)在两条曲线上的位置(即似然值)。
import numpy as np
import matplotlib.pyplot as plt
# 解决中文乱码
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 定义高斯分布概率密度函数
def gaussian(x, mu, sigma_sq):
return (1 / np.sqrt(2 * np.pi * sigma_sq)) * np.exp(-(x - mu)** 2 / (2 * sigma_sq))
# 模拟数据集参数
mu_programmer = 3.5 # 程序员观影时长均值
sigma_sq_programmer = 1.0 # 程序员观影时长方差
mu_student = 5.8 # 大学生观影时长均值
sigma_sq_student = 1.3 # 大学生观影时长方差
x_pred = 4.2 # 待预测样本特征值
# 生成x轴数据(观影时长范围)
x = np.linspace(0, 10, 500)
# 计算两类的高斯分布y值
y_programmer = gaussian(x, mu_programmer, sigma_sq_programmer)
y_student = gaussian(x, mu_student, sigma_sq_student)
# 计算待预测点的似然值(曲线高度)
y_pred_programmer = gaussian(x_pred, mu_programmer, sigma_sq_programmer)
y_pred_student = gaussian(x_pred, mu_student, sigma_sq_student)
# 绘图设置
plt.figure(figsize=(10, 6))
plt.plot(x, y_programmer, label='程序员 (μ=3.5, σ²=1.0)', color='#1f77b4', linewidth=2)
plt.plot(x, y_student, label='大学生 (μ=5.8, σ²=1.3)', color='#ff7f0e', linewidth=2)
# 标注待预测点
plt.scatter(x_pred, y_pred_programmer, color='#1f77b4', s=100, zorder=5)
plt.scatter(x_pred, y_pred_student, color='#ff7f0e', s=100, zorder=5)
plt.vlines(x_pred, 0, max(y_pred_programmer, y_pred_student), linestyles='--', color='gray', alpha=0.7)
plt.text(x_pred + 0.1, y_pred_programmer, f'似然(程序员)={y_pred_programmer:.3f}', color='#1f77b4')
plt.text(x_pred + 0.1, y_pred_student, f'似然(大学生)={y_pred_student:.3f}', color='#ff7f0e')
# 标注均值位置
plt.axvline(mu_programmer, color='#1f77b4', linestyle=':', alpha=0.5, label='程序员均值')
plt.axvline(mu_student, color='#ff7f0e', linestyle=':', alpha=0.5, label='大学生均值')
# 图表美化
plt.xlabel('每周观影时长(小时)', fontsize=12)
plt.ylabel('概率密度(似然近似值)', fontsize=12)
plt.title('单特征高斯朴素贝叶斯:两类人群观影时长分布', fontsize=14)
plt.legend(fontsize=10)
plt.grid(alpha=0.3)
plt.xlim(0, 10)
plt.ylim(0, 0.5)
plt.show()
可视化结果说明
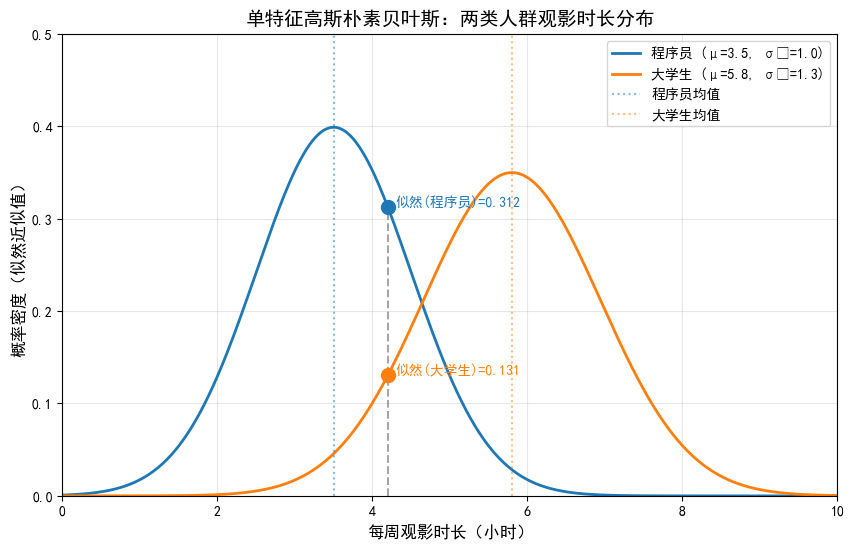
运行代码后将生成高斯分布曲线:
- 蓝色曲线:程序员观影时长分布(中心在3.5小时);
- 橙色曲线:大学生观影时长分布(中心在5.8小时);
- 灰色虚线:待预测点4.2小时的位置;
- 散点及文字:4.2小时在两条曲线上的高度(即似然值)。
结合先验概率(程序员0.7,大学生0.3),可计算联合概率:
- 程序员联合概率:
0.7×似然(程序员) 0.7 \times 似然(程序员) 0.7×似然(程序员)
- 大学生联合概率:
0.3×似然(大学生) 0.3 \times 似然(大学生) 0.3×似然(大学生)
最终选择联合概率更大的类别作为预测结果。
6. 总结
高斯朴素贝叶斯的核心逻辑可概括为:
- 先验概率:仅看类别基础占比,与特征无关;
- 似然:固定类别,用高斯分布拟合连续特征,估算特征出现的相对概率;
- 乘法逻辑:联合概率为“先验×似然”,反映“类别+特征”同时发生的可能性;
- 高斯作用:解决连续特征无法直接统计概率的问题,通过均值和方差确定分布曲线。
通过本文的原理讲解和Python可视化,可直观理解高斯朴素贝叶斯的工作流程。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 14
14 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)