企业知识库文档结构化整理指南
在大模型应用落地的过程中,很多企业会发现:明明已经把公司介绍、产品手册、培训文档等资料上传到了知识库,AI 的回答却依然不准确、不完整,甚至出现答非所问的情况。
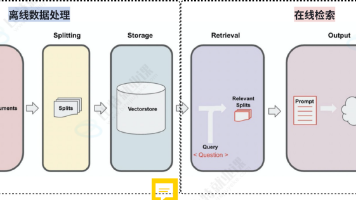
问题的根源往往不在于模型本身,而在于上传的资料没有经过结构化整理。对于 RAG(检索增强生成)系统而言,知识库不应是一个简单的文件仓库,而应是一套面向检索、理解和生成的内容基础设施。
以下将从企业知识库建设的角度,梳理在 RAG 场景下,企业文档应该如何进行结构化整理。
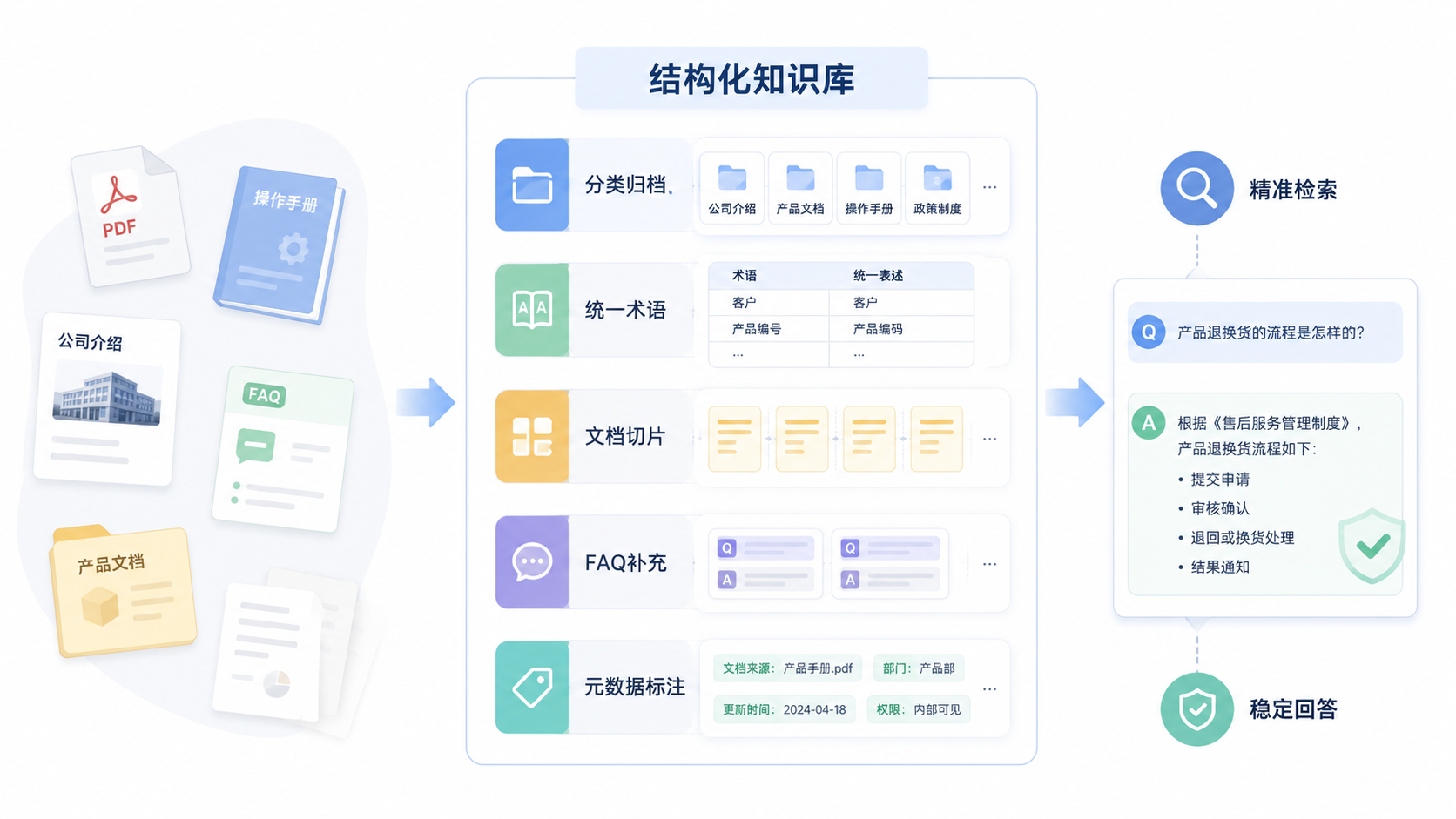
一、为什么不能直接上传原始资料
原始资料大多是为人类阅读设计的,而不是为机器检索和模型理解准备的。人类读者可以依靠上下文、经验和常识来补全信息,但大模型在检索时依赖的是文本片段、语义匹配和清晰的内容结构。
直接上传未经处理的原始资料,通常会遇到以下问题:
1.1 文档过长
一份几十页的 PDF 包含大量背景描述和重复信息,模型在检索时可能只命中局部内容,无法完整理解业务重点。
1.2 标题笼统
"产品介绍"、"解决方案"这类标题信息密度低,难以让检索系统判断内容对应的真实语义。
1.3 术语不统一
同一个产品在不同文档中有不同叫法,容易造成模型识别混乱。
1.4 缺少问答场景
企业资料多为陈述式,而用户提问是问题式。缺少对应的 FAQ 内容,模型就需要自行推理,稳定性会降低。
1.5 证据来源不明
缺少来源、时间和版本说明,一旦资料更新,模型可能仍在引用旧信息。
因此,知识库建设的重点不是"上传更多文件",而是将资料整理成更适合检索和生成的结构化内容。
二、RAG 知识库需要什么样的内容
RAG 的基本流程是:用户提问 → 系统检索相关知识 → 模型生成回答。这意味着知识库中的内容至少要满足三个要求:
2.1 容易被检索到
包含明确的主题、关键词和业务场景。
2.2 容易被理解
结构清晰,避免口号化和堆砌式表达。
2.3 容易被引用
重要信息有明确来源和更新时间,便于模型生成可验证的回答。
三、文档整理的四大基本原则
3.1 一个文档只解决一类问题
将所有信息堆砌在一个大文档中是 RAG 系统的大忌。应该按照主题拆分,例如:
- 企业基础信息文档
- 产品功能说明文档
- 服务流程说明文档
- 常见问题(FAQ)文档
每个文档围绕一个核心主题展开,标题直接说明内容用途,可以有效减少检索噪音,提高命中准确性。
3.2 标题要像问题,也要像答案
笼统的标题对检索系统不友好。更适合知识库的标题应该更具体,例如:
不佳标题: 产品说明
更佳标题: 智能客服系统的核心功能与适用场景有哪些
这样的标题既包含关键词,也接近用户真实提问方式,更容易被检索和匹配。
3.3 重要信息使用稳定表述
企业名称、产品名称、服务范围等"标准口径"内容,应在所有文档中保持统一表述。例如,避免在同一公司的不同资料中混用"智能问答系统"、"AI 客服"和"知识库助手"来指代同一产品。稳定表述能让模型在多次检索和生成中保持一致的理解。
3.4 尽量减少空泛宣传语
"行业领先"、"全面赋能"、"一站式解决"等宣传式表达对模型理解帮助有限。模型更需要的是具体、清晰、可判断的信息,例如:
- 解决什么问题
- 面向哪些对象
- 包含哪些模块
- 有哪些使用边界
知识库内容越具体,模型生成的回答越稳定。
四、建议包含的核心字段
将企业资料整理成半结构化格式,可以显著提升 RAG 系统的效果。以下是一组通用的字段设计:
4.1 主体信息字段
用于帮助模型识别"这段内容在讲谁"。
建议包含:
- 主体名称
- 主体简称
- 所属行业
- 业务类型
- 更新时间
4.2 产品/服务字段
用于说明具体提供什么。
建议包含:
- 产品/服务名称
- 核心功能
- 解决的问题
- 适用对象
- 适用场景
- 使用边界
4.3 问答(FAQ)字段
FAQ 是知识库建设中非常重要的一类内容。
建议结构:
- 问题
- 标准回答
- 补充说明
- 适用场景
- 相关资料来源
- 更新时间
4.4 证据字段
用于提高内容可信度和可追溯性。
建议包含:
- 信息来源
- 发布时间
- 更新时间
- 适用版本
- 相关链接或文件名
- 负责人或维护人
五、文档切片(Chunking)的关键策略
RAG 系统会将文档切分成多个片段(Chunk)进行向量化和检索。切片质量直接影响最终效果。
5.1 采用父子层级分块(Parent-Child Chunking)
这是解决 RAG 核心矛盾(检索需要小粒度,生成需要大上下文)的有效策略。
- 子块 (Child Chunk): 使用小块(如 256-512 tokens)进行精准检索。
- 父块 (Parent Chunk): 当子块被命中后,系统返回包含该子块的、更大的父块(如 1024-2048 tokens)给大模型,以提供完整的上下文。
5.2 按语义边界切分
避免简单地按固定字符数切分。应根据文档的逻辑结构进行切分,确保每个片段在语义上的完整性。
具体建议:
- FAQ 文档: 保持一问一答的完整性
- 技术文档: 按章节、操作步骤或"第X条"条款进行切分
- 表格数据: 应将表格整体作为一个单元处理,或将其转换为"字段: 值"的文本描述,避免行列关系被割裂
5.3 保留必要的上下文
切片不能过短,否则可能丢失主体名称和关键背景信息,导致模型无法理解片段指向的对象。重要片段中应保留必要的标题和上下文说明。
六、推荐的整理流程与常见误区
6.1 推荐流程
- 收集资料: 汇总官网、手册、FAQ、案例等所有相关材料
- 分类归档: 按企业信息、产品服务、业务场景、FAQ 等类别分类
- 统一口径: 检查并统一企业名称、产品名称、核心术语等
- 拆分文档: 将长文档拆分为多个主题明确的小文档
- 补充 FAQ: 围绕真实用户问题,整理标准问答
- 添加元数据: 为文档增加来源、更新时间、版本等信息
- 测试与迭代: 基于真实问题测试问答效果,并持续优化
6.2 常见误区
误区一:资料越多越好
结构混乱的资料越多,检索噪音越大。应优先整理核心资料。
误区二:只上传 PDF
PDF 排版复杂,可能影响解析效果。建议将重要内容转为 Markdown 或结构化文本。
误区三:只有介绍,没有问答
介绍型内容不等于问答型内容。必须围绕用户真实问题补充 FAQ。
误区四:缺少更新机制
企业信息会变化,必须为文档设置更新时间并定期复查,避免模型引用过时信息。
七、总结
在 RAG 场景下,企业知识库建设不是简单地把文件上传给系统,而是要把企业资料整理成更适合检索、理解和生成的结构化内容。
高质量的企业知识库通常具备以下特征:
- 主题清晰
- 标题明确
- 术语统一
- 问答充分
- 字段完整
- 来源可追溯
- 版本可维护
- 内容不过度宣传
- 回答边界清楚
通过系统性的结构化整理,企业可以显著提升知识库问答系统的准确性和稳定性,真正发挥 AI 技术在企业内部信息管理和客户服务中的价值。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)