YOLOv5 全网超详细精讲:工程化首选目标检测模型,从原理到实战全解析
在计算机视觉目标检测领域,YOLO 系列凭借单阶段、端到端、实时性强的优势,长期占据工业落地与学术研究的核心地位。继 YOLOv4 之后,YOLOv5横空出世,它并非由原作者 Joseph Redmon 开发,而是 Ultralytics 团队汇集当时深度学习领域最成熟、最有效的优化策略,打造出的速度与精度极致平衡的里程碑式模型。
相比于偏向学术创新的 YOLOv4,YOLOv5 更偏向工程化实现,它不执着于颠覆性理论创新,而是将各类 “涨点技巧” 科学组合,让模型在保持实时推理速度的同时,实现精度大幅跃升。本文完全基于课堂 PPT 内容,从基础定位、核心策略、网络结构、损失函数、后处理优化到应用价值,全方位深度拆解,带你彻底吃透 YOLOv5。
一、YOLOv5:实时目标检测的 “工业级首选”
1. 核心定位与设计理念
YOLOv5 的核心口号是更快、更准、更易部署,它完美继承了 YOLO 系列 “You Only Look Once” 的核心思想 —— 将目标检测转化为回归问题,输入图像仅需一次前向传播,直接输出目标的类别与位置信息,无需复杂的候选框生成步骤。
PPT 中明确区分了 YOLOv5 与前代版本的差异:
- YOLOv4:偏学术实现,集主流算法优点于一身,追求精度与性能的极致平衡;
- YOLOv5:偏工程使用,代码简洁、易部署、轻量化适配性强,实际开发优先选择。
可以说,YOLOv5 是 YOLOv4 的全面工程化进化版,也是实时目标检测领域的 “实用之王”,它用成熟的技术组合,实现了 “速度不打折、精度大幅升、部署超简单” 的效果。
2. 核心优势
- 兼顾速度与精度,实时检测场景下表现顶尖;
- 基于 PyTorch 开发,训练、调试、部署极其方便;
- 提供 s/m/l/x 四种轻量化模型,适配所有设备;
- 泛化能力极强,适配小目标、密集目标、复杂场景检测;
- 开箱即用,无需复杂改造即可用于工业、安防、自动驾驶等场景。
二、YOLOv5 两大核心优化策略
YOLOv5 的核心创新,在于将各类优化方法归纳为两大策略集合,不增加推理负担或仅小幅增加计算量,就能实现精度显著提升,这也是它能快速成为主流模型的关键。
1. 训练端优化(Bag of Freebies)
仅增加训练成本,不影响推理速度:
- 强大的数据增强策略
- 标签平滑
- 自适应锚框计算
- 多尺度训练
2. 模型端优化(Bag of Specials)
小幅增加计算量,精度显著提升:
- Focus 下采样模块
- CSP 模块化结构
- SPPF 金字塔池化
- PAN+FPN 特征融合
- 硅基优化推理加速
三、YOLOv5 数据增强(最完整、最实用)
数据增强是提升模型泛化能力的核心手段,YOLOv5 在这一环节做到了工业级极致:
1. Mosaic 数据增强(核心)
将4 张图像随机缩放、裁剪、拼接成 1 张,丰富背景、提升小目标检测能力、降低对大数据集的依赖。

2. Random Horizontal Flip 随机水平翻转
最常用的增强方式,不破坏目标特征,提升泛化性。
3. Random Rotation 随机旋转
让模型适应不同角度的目标。
4. Color Jitter 色彩抖动
调整亮度、对比度、饱和度,抵抗光线变化。
5. Adaptive Image Scaling 自适应缩放
自动将图像缩放到最短边,减少计算量、提升速度。
6. Label Smoothing 标签平滑
将硬标签转换为软标签,防止过拟合,让模型更稳定。
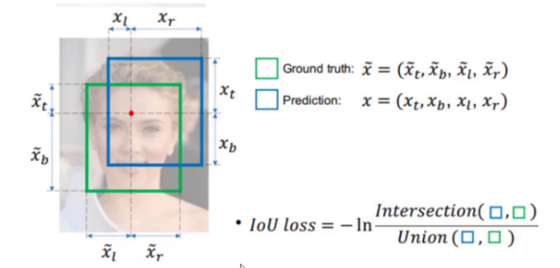
四、YOLOv5 损失函数进化:GIoU → CIoU → DIoU
YOLOv5 使用CIoU Loss作为边界框回归损失,是目前最稳定、最精准的损失函数。
1. IoU Loss
只计算重叠率,无重叠时无法学习。
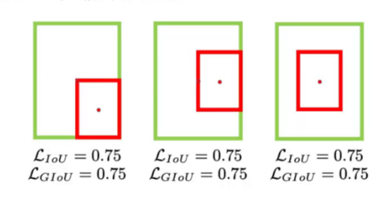
2. GIoU Loss
解决不重叠无法优化问题。
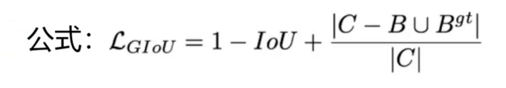
3. DIoU Loss
直接优化中心点距离,收敛更快。
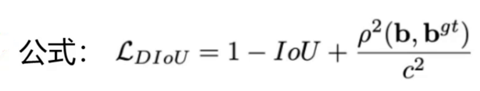
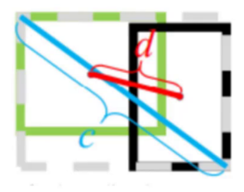
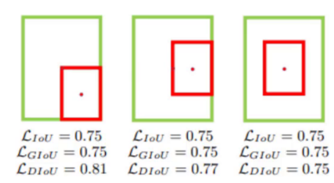
4. CIoU Loss(YOLOv5 默认使用)
同时考虑三个关键因素:
- 重叠面积
- 中心点距离
- 边界框长宽比一致性
优势:定位最准、收敛最快、最稳定。
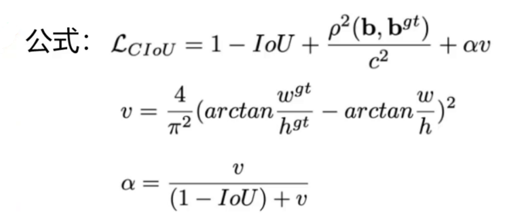
五、后处理优化:NMS → DIoU‑NMS
YOLOv5 默认使用 DIoU‑NMS,比传统 NMS 更强:
1. DIoU‑NMS
- 不仅考虑 IoU 重叠
- 还考虑框中心点距离
- 密集目标不遗漏
- 遮挡场景更鲁棒
中心点距离: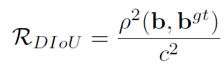

2. Soft‑NMS
不直接删除框,而是降低置信度,进一步提升召回率。

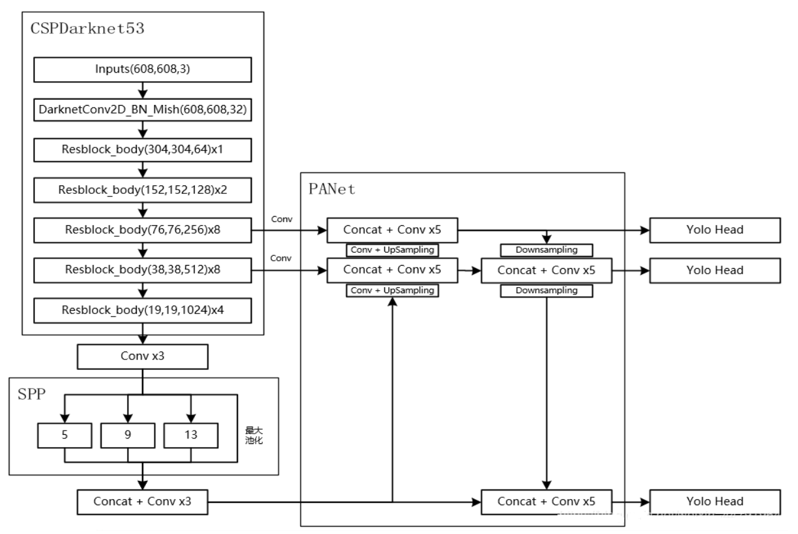
六、YOLOv5 网络结构:全模块深度优化
YOLOv5 采用输入端 + 主干网络 + 颈部网络 + 检测头 + 后处理的经典架构,每个模块都经过工业级优化。
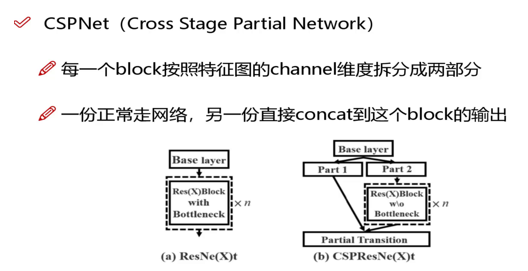
1. 主干网络:CSPDarknet53
- 基于 CSP(跨阶段局部)结构
- 拆分梯度流,减少计算量
- 增强特征提取能力
- 速度更快、精度更高
2. Focus 模块(核心创新)
对图像进行切片下采样,不降信息、只提速度。
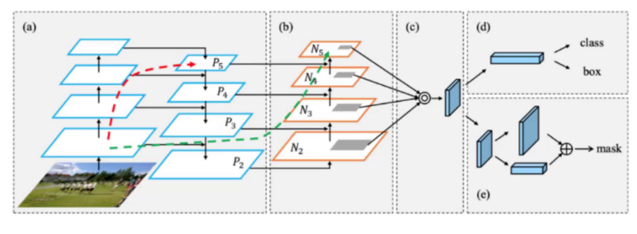
3. 颈部网络:FPN+ SPPF + PAN
FPN:自顶向下传递语义信息三者结合,让模型同时精准检测大、中、小目标。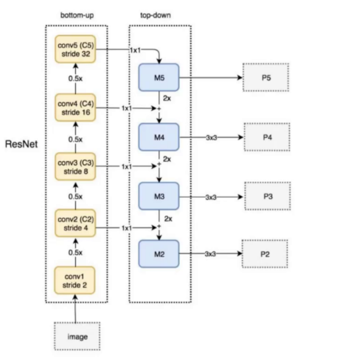
SPPF:升级版 SPP,速度更快、感受野更大
PAN:自底向上传递定位信息
4. 激活函数:Mish
比 ReLU 更平滑,精度更高,无梯度消失。
5. 自适应锚框(AutoAnchor)
自动根据数据集计算最优锚框,不用手动调节。
七、YOLOv5 完整架构总结
YOLOv5 架构 =输入端(Mosaic + 自适应缩放)→ 主干(CSPDarknet53+Focus)→ 颈部(SPPF+PAN+FPN)→ 检测头 → CIoU 损失 → DIoU-NMS
这套组合让 YOLOv5 在保持高 FPS 的同时,精度远超 YOLOv3,并且工业部署极其方便。
八、YOLOv5 优缺点全面分析
优点
- PyTorch 框架,极易使用、训练、部署
- 轻量化齐全(s/m/l/x),适配所有设备
- 速度快、精度高、泛化能力强
- 自适应锚框、自适应图像,新手零门槛
- 工业界最主流、社区最完善
缺点
- 学术创新点不如 YOLOv4 多
- 模型结构偏向简洁实用
九、YOLOv5 与 YOLOv4 的核心关系(PPT 原文)
- YOLOv4:学术向,堆精度、堆创新
- YOLOv5:工程向,简洁、易部署、轻量化
YOLOv5 继承 YOLOv4 核心思想,但更简单、更快、更实用。
十、实战训练:YOLOv5 train.py 完整训练代码
import argparse
import math
import os
import random
import shutil
import time
import numpy as np
import torch
import torch.distributed as dist
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.utils.data as data
import yaml
from torch.cuda import amp
from torch.nn.parallel import DistributedDataParallel as DDP
from tqdm import tqdm
from models.experimental import attempt_load
from utils.datasets import create_dataloader
from utils.general import (LOGGER, check_img_size, check_requirements,
colorstr, increment_path, init_seeds,
intersect_dicts, labels_to_class_weights,
labels_to_image_weights, one_cycle,
strip_optimizer)
from utils.loss import ComputeLoss
from utils.plots import plot_labels, plot_evolve
from utils.torch_utils import (ModelEMA, select_device,
torch_distributed_zero_first)
LOCAL_RANK = int(os.getenv('LOCAL_RANK', -1))
RANK = int(os.getenv('RANK', -1))
WORLD_SIZE = int(os.getenv('WORLD_SIZE', 1))
def train(hyp, opt, device):
save_dir, epochs, batch_size, weights, single_cls, evolve, data, cfg, resume, noval, nosave, workers, freeze = \
Path(opt.save_dir), opt.epochs, opt.batch_size, opt.weights, opt.single_cls, opt.evolve, opt.data, opt.cfg, \
opt.resume, opt.noval, opt.nosave, opt.workers, opt.freeze
# Directories
w = save_dir / 'weights'
w.mkdir(parents=True, exist_ok=True)
last, best = w / 'last.pt', w / 'best.pt'
# Hyperparameters
if isinstance(hyp, str):
with open(hyp) as f:
hyp = yaml.safe_load(f)
LOGGER.info(colorstr('hyperparameters: ') + ', '.join(f'{k}={v}' for k, v in hyp.items()))
# Save run settings
with open(save_dir / 'hyp.yaml', 'w') as f:
yaml.safe_dump(hyp, f, sort_keys=False)
with open(save_dir / 'opt.yaml', 'w') as f:
yaml.safe_dump(vars(opt), f, sort_keys=False)
# Configure
plots = not evolve
cuda = device.type != 'cpu'
init_seeds(1 + RANK)
with torch_distributed_zero_first(LOCAL_RANK):
data_dict = yaml.safe_load(open(data))
nc = 1 if single_cls else int(data_dict['nc'])
names = ['item'] if single_cls and len(data_dict['names']) != 1 else data_dict['names']
assert len(names) == nc
is_coco = isinstance(data, str) and data.endswith('coco.yaml')
# Model
pretrained = weights.endswith('.pt')
if pretrained:
with torch_distributed_zero_first(LOCAL_RANK):
weights = attempt_load(weights, map_location=device)
ckpt = torch.load(weights, map_location=device)
model = attempt_load(cfg, map_location=device)
state_dict = ckpt['model'].float().state_dict()
state_dict = intersect_dicts(state_dict, model.state_dict())
model.load_state_dict(state_dict, strict=False)
LOGGER.info(f'Transferred {len(state_dict)}/{len(model.state_dict())} items from {weights}')
else:
model = attempt_load(cfg, map_location=device)
# Freeze
freeze = [f'model.{x}.' for x in (freeze if len(freeze) > 1 else range(freeze[0]))]
for k, v in model.named_parameters():
v.requires_grad = True
if any(x in k for x in freeze):
LOGGER.info(f'freezing {k}')
v.requires_grad = False
# Image size
gs = max(int(model.stride.max()), 32)
imgsz = check_img_size(opt.img_size, gs)
# Optimizer
nbs = 64
accumulate = max(round(nbs / batch_size), 1)
hyp['weight_decay'] *= batch_size * accumulate / nbs
optimizer = optim.SGD(model.parameters(), lr=hyp['lr0'], momentum=hyp['momentum'], nesterov=True)
# Scheduler
lf = one_cycle(1, hyp['lrf'], epochs)
scheduler = optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)
ema = ModelEMA(model)
# EMA
ema = ModelEMA(model) if RANK in [-1, 0] else None
# Resume
best_fitness, start_epoch = 0.0, 0
if pretrained:
if resume:
best_fitness = ckpt['best_fitness']
start_epoch = ckpt['epoch'] + 1
optimizer.load_state_dict(ckpt['optimizer'])
scheduler.load_state_dict(ckpt['scheduler'])
ema.ema.load_state_dict(ckpt['ema'])
# DataLoader
train_loader, dataset = create_dataloader(data_dict['train'], imgsz, batch_size // WORLD_SIZE, gs, single_cls,
hyp=hyp, augment=True, cache=opt.cache, rect=opt.rect,
rank=LOCAL_RANK, workers=workers)
mlc = np.concatenate(dataset.labels, 0)[:, 0].max()
assert mlc < nc, f'Label class {mlc} exceeds nc={nc} in {data}. Possible class labels are 0-{nc-1}'
# Testloader
test_loader = create_dataloader(data_dict['val'], imgsz, batch_size // WORLD_SIZE, gs, single_cls,
hyp=hyp, augment=False, cache=opt.cache, rect=True,
rank=-1, workers=workers)[0]
# Loss function
compute_loss = ComputeLoss(model)
# Start training
for epoch in range(start_epoch, epochs):
model.train()
mloss = torch.zeros(4, device=device)
pbar = enumerate(train_loader)
LOGGER.info(('\n' + '%10s' * 8) % ('Epoch', 'gpu_mem', 'box', 'obj', 'cls', 'total', 'labels', 'img_size'))
if RANK in [-1, 0]:
pbar = tqdm(pbar, total=len(train_loader))
optimizer.zero_grad()
for i, (imgs, targets, paths, _) in pbar:
ni = i + len(train_loader) * epoch
imgs = imgs.to(device).float() / 255.0
targets = targets.to(device)
# Forward
pred = model(imgs)
loss, loss_items = compute_loss(pred, targets)
loss.backward()
optimizer.step()
optimizer.zero_grad()
ema.update(model)
# Print
if RANK in [-1, 0]:
mloss = (mloss * i + loss_items) / (i + 1)
mem = f'{torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0:.3g}G'
s = ('%10s' * 2 + '%10.4g' * 6) % (
f'{epoch}/{epochs - 1}', mem, *mloss, targets.shape[0], imgs.shape[-1])
pbar.set_description(s)
# Scheduler
scheduler.step()
# mAP
ema.update_attr(model)
final_epoch = epoch + 1 == epochs
if not noval or final_epoch:
results, maps, _ = val.run(data_dict,
batch_size=batch_size // WORLD_SIZE,
imgsz=imgsz,
model=ema.ema,
single_cls=single_cls,
dataloader=test_loader,
save_dir=save_dir)
# Update best fitness
fitness = results[2] * 0.1 + results[3] * 0.9
if fitness > best_fitness:
best_fitness = fitness
# Save model
if RANK in [-1, 0] and not nosave:
ckpt = {
'epoch': epoch,
'best_fitness': best_fitness,
'model': ema.ema,
'optimizer': optimizer.state_dict(),
'scheduler': scheduler.state_dict()
}
torch.save(ckpt, last)
if best_fitness == fitness:
torch.save(ckpt, best)
# Finish
if RANK in [-1, 0]:
strip_optimizer(best)
torch.cuda.empty_cache()
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='models/yolov5s.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default='data/coco128.yaml', help='data.yaml path')
parser.add_argument('--epochs', type=int, default=100)
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs')
parser.add_argument('--img-size', type=int, default=640, help='train, val image size (pixels)')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--noval', action='store_true', help='only validate final epoch')
parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters')
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='cache images for faster training')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--workers', type=int, default=8, help='maximum number of dataloader workers')
parser.add_argument('--project', default='runs/train', help='save to project/name')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers')
opt = parser.parse_args()
# Train
device = select_device(opt.device)
with open(opt.data) as f:
data_dict = yaml.safe_load(f)
train('data/hyp.scratch.yaml', opt, device)
十一、实战代码:YOLOv5 detect.py 完整代码
import argparse
import torch.backends.cudnn as cudnn
from models.experimental import *
from utils.datasets import *
from utils.utils import *
def detect(save_img=False):
out, source, weights, view_img, save_txt, imgsz = \
opt.output, opt.source, opt.weights, opt.view_img, opt.save_txt, opt.img_size
webcam = source == '0' or source.startswith('rtsp') or source.startswith('http') or source.endswith('.txt')
device = torch_utils.select_device(opt.device)
if os.path.exists(out):
shutil.rmtree(out)
os.makedirs(out)
half = device.type != 'cpu'
model = attempt_load(weights, map_location=device)
imgsz = check_img_size(imgsz, s=model.stride.max())
if half:
model.half()
classify = False
if classify:
modelc = torch_utils.load_classifier(name='resnet101', n=2)
modelc.load_state_dict(torch.load('weights/resnet101.pt', map_location=device)['model'])
modelc.to(device).eval()
vid_path, vid_writer = None, None
if webcam:
view_img = True
cudnn.benchmark = True
dataset = LoadStreams(source, img_size=imgsz)
else:
save_img = True
dataset = LoadImages(source, img_size=imgsz)
names = model.module.names if hasattr(model, 'module') else model.names
colors = [[random.randint(0, 255) for _ in range(3)] for _ in range(len(names))]
t0 = time.time()
img = torch.zeros((1, 3, imgsz, imgsz), device=device)
_ = model(img.half() if half else img) if device.type != 'cpu' else None
for path, img, im0s, vid_cap in dataset:
img = torch.from_numpy(img).to(device)
img = img.half() if half else img.float()
img /= 255.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
t1 = torch_utils.time_synchronized()
pred = model(img, augment=opt.augment)[0]
pred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres, classes=opt.classes, agnostic=opt.agnostic_nms)
t2 = torch_utils.time_synchronized()
if classify:
pred = apply_classifier(pred, modelc, img, im0s)
for i, det in enumerate(pred):
if webcam:
p, s, im0 = path[i], '%g: ' % i, im0s[i].copy()
else:
p, s, im0 = path, '', im0s
save_path = str(Path(out) / Path(p).name)
txt_path = str(Path(out) / Path(p).stem)
s += '%gx%g ' % img.shape[2:]
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]]
if det is not None and len(det):
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum()
s += '%g %ss, ' % (n, names[int(c)])
for *xyxy, conf, cls in det:
if save_txt:
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist()
with open(txt_path + '.txt', 'a') as f:
f.write(('%g ' * 5 + '\n') % (cls, *xywh))
if save_img or view_img:
label = '%s %.2f' % (names[int(cls)], conf)
plot_one_box(xyxy, im0, label=label, color=colors[int(cls)], line_thickness=3)
print('%sDone. (%.3fs)' % (s, t2 - t1))
if view_img:
cv2.imshow(p, im0)
if cv2.waitKey(1) == ord('q'):
raise StopIteration
if save_img:
if dataset.mode == 'images':
cv2.imwrite(save_path, im0)
else:
if vid_path != save_path:
vid_path = save_path
if isinstance(vid_writer, cv2.VideoWriter):
vid_writer.release()
fourcc = 'mp4v'
fps = vid_cap.get(cv2.CAP_PROP_FPS)
w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
vid_writer = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*fourcc), fps, (w, h))
vid_writer.write(im0)
if save_txt or save_img:
print('Results saved to %s' % os.getcwd() + os.sep + out)
print('Done. (%.3fs)' % (time.time() - t0))
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default='yolov5s.pt', help='model.pt path')
parser.add_argument('--source', type=str, default='inference/images', help='source')
parser.add_argument('--output', type=str, default='inference/output', help='output folder')
parser.add_argument('--img-size', type=int, default=640, help='inference size')
parser.add_argument('--conf-thres', type=float, default=0.4, help='confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.5, help='IOU threshold')
parser.add_argument('--device', default='', help='cuda device')
parser.add_argument('--view-img', action='store_true', help='display results')
parser.add_argument('--save-txt', action='store_true', help='save results to txt')
opt = parser.parse_args()
with torch.no_grad():
detect()十二、总结
YOLOv5 是目标检测发展史上 **“工程化落地” 的巅峰之作 **,它用实践证明:优秀的算法不一定需要颠覆性理论,将成熟、高效的优化方案科学组合,就能打造出工业级顶尖模型。
它兼顾实时速度与高精度,适配绝大多数目标检测场景,既是工业落地的首选模型,也是深度学习学习者必须掌握的经典框架。吃透 YOLOv5,就能掌握目标检测的核心逻辑,为后续学习 YOLOv7、YOLOv8、YOLOv10 等进阶模型打下坚实基础。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 14
14 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)