TPS:基于双分支专家融合记忆网络的大规模配电系统净负荷高效预测:
关于大规模配电网净负荷预测的论文
代码:https://github.com/lishijie15/DEFMN.
论文基本信息
| 项目 | 内容 |
|---|---|
| 标题 | Efficient Net Load Forecasting in Large-Scale Power Distribution Systems via Dual-Branch Experts Fusion Memory Network |
| 作者 | Shijie Li, Ruican Hu, Guanlin Chen, Lulu Chen, He Li, Huaiguang Jiang† (通讯), Ying Xue, Jiawen Kang, Jun Zhang, David Wenzhong Gao (IEEE Fellow) |
| 发表 | IEEE Transactions on Power Systems, Vol.41, No.1, January 2026 |
| 机构 | 华南理工大学、广东工业大学、武汉大学、美国丹佛大学 |
| 代码 | https://github.com/lishijie15/DEFMN |
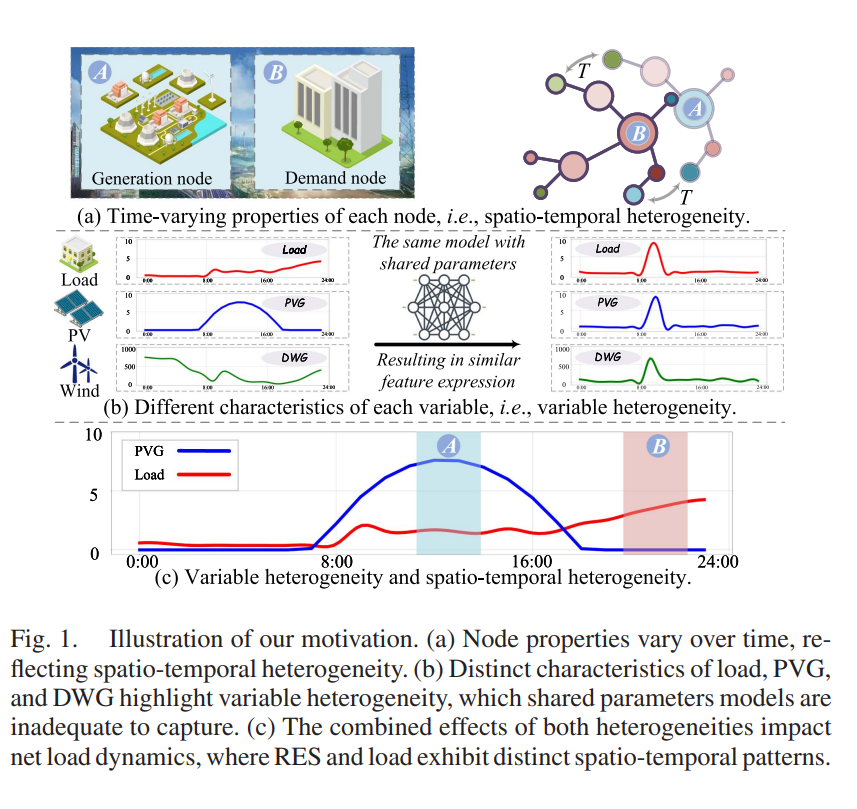
一、研究背景与核心挑战
1.1 什么是净负荷(Net Load)?
净负荷 = 总负荷需求 − 分布式发电(DG)出力
= Load − PV(光伏) − Wind(风电)
随着可再生能源渗透率提高,配电网从"单向供电"变为"双向互动",净负荷预测成为关键。
1.2 两大核心异质性(本文核心洞察)
| 异质性类型 | 具体表现 | 现有方法的问题 |
|---|---|---|
| 变量异质性 (Variable Heterogeneity) | 负荷、光伏、风电具有截然不同的时序特征(见图1(b)) | 用共享参数的同一模型处理所有变量,导致特征表达相似化 |
| 时空异质性 (Spatio-temporal Heterogeneity) | 节点净负荷变化导致节点属性(输入/输出)和图结构动态变化(见图1(a)) | 假设固定图结构,无法适应动态拓扑 |
图1©的直观解释:中午光伏大发时,某些节点从"负荷节点"变为"发电节点",图上的能量流向完全改变。
二、核心贡献:DEFMN模型
2.1 整体架构
输入: X_T^N ∈ R^(C×N×T) (C=3个变量:负荷/光伏/风电, N个节点, T个时间步)
│
├─→ [Series Embedding] ──→ X_emb ∈ R^(C×N×D) (共享参数)
│ │
└──────────────────────────────┘
↓
[Dual-Branch Experts]
│
├──────────┴──────────┐
↓ ↓
[Variable Branch] [Feature Branch]
(独立参数专家) (独立参数专家)
│ │
└──────────┬──────────┘
↓
S_ee ∈ R^(N×D×S_d)
│
[Meta Spatial Memory]
│
S_ma = [S_ee + S_M] (拼接)
│
[Decoder]
│
输出: X̂_t^n = Decoder(S_ma) + X_emb (残差连接)
│
净负荷: Ê = L̂ − P̂ − Ŵ (间接策略)
2.2 关键组件详解
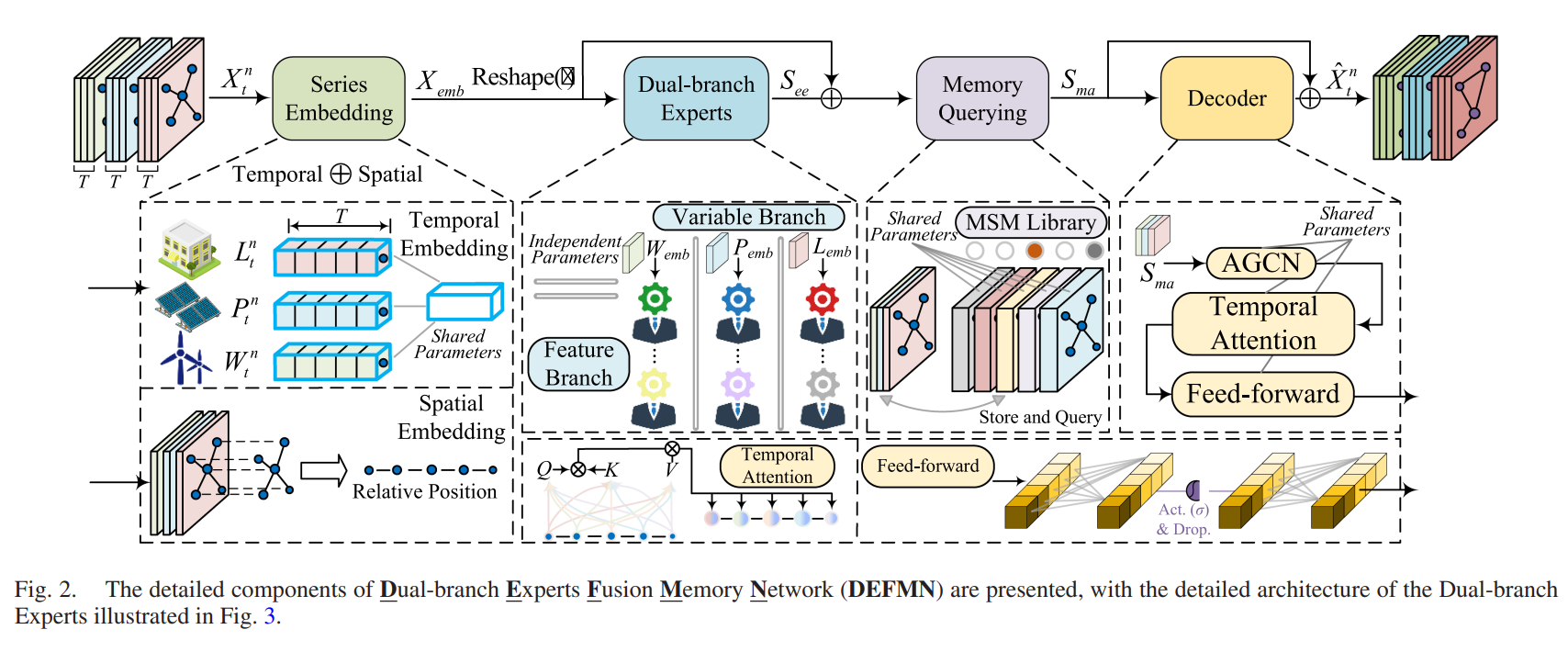
A. Series Embedding(序列嵌入,共享参数)
区别于Transformer的通道嵌入:
- 传统做法:将同一时刻的不同变量嵌入为"通道",导致时间不对齐
- 本文做法:沿时间维度投影,保留变量的时序独立性
数学表达:
Hse=XTNWse+bseH_{se} = X_T^N W_{se} + b_{se}Hse=XTNWse+bse
SE(sp,2n)=sin(sp100002n/D),SE(sp,2n+1)=cos(sp100002n+1/D)SE_{(sp, 2n)} = \sin\left(\frac{sp}{10000^{2n/D}}\right), \quad SE_{(sp, 2n+1)} = \cos\left(\frac{sp}{10000^{2n+1/D}}\right)SE(sp,2n)=sin(100002n/Dsp),SE(sp,2n+1)=cos(100002n+1/Dsp)
Xemb=Hse⊕(SE(sp,2n)+SE(sp,2n+1))X_{emb} = H_{se} \oplus (SE_{(sp,2n)} + SE_{(sp,2n+1)})Xemb=Hse⊕(SE(sp,2n)+SE(sp,2n+1))
- Wse∈RD×Cd×CdW_{se} \in \mathbb{R}^{D \times C_d \times C_d}Wse∈RD×Cd×Cd: 序列嵌入参数(三个变量共享)
- SESESE: 空间位置编码(正弦/余弦函数)
- ⊕\oplus⊕: 广播相加
关键设计:共享参数增强变量间隐式关联表达,同时保留各变量独立性。
B. Dual-Branch Experts(双分支专家,独立参数)
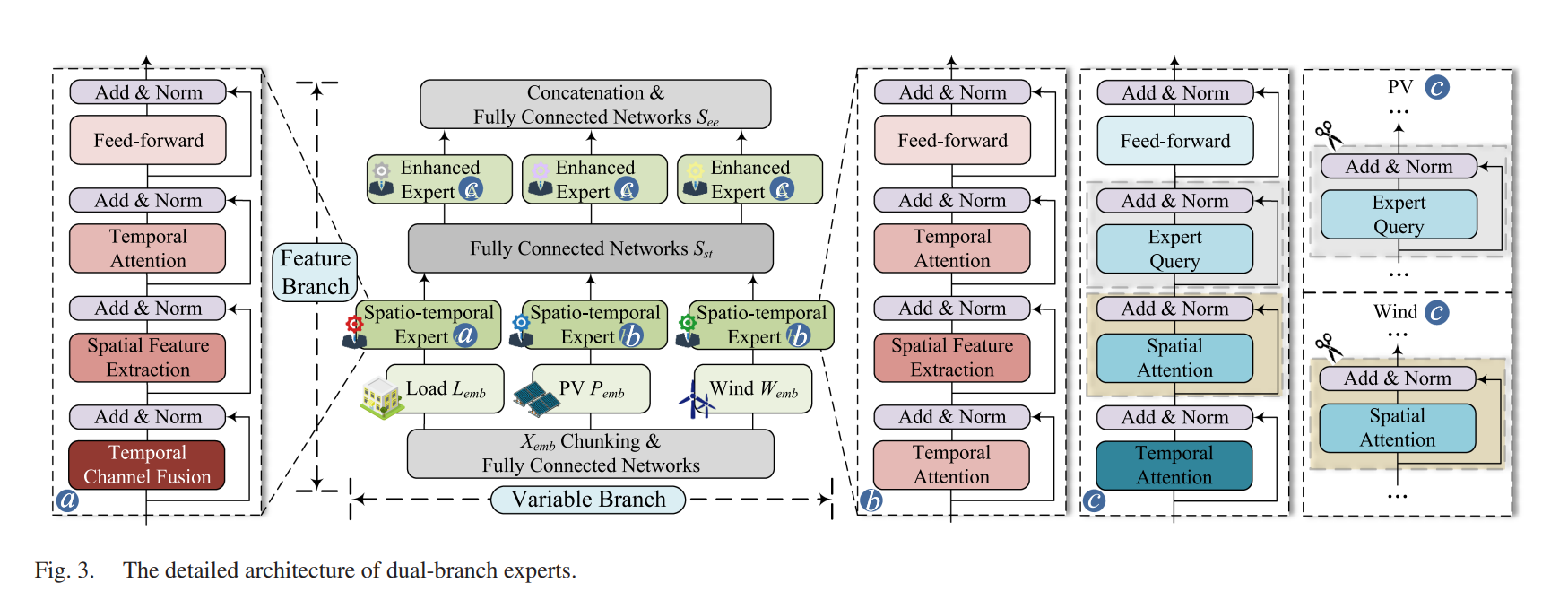
这是本文最核心创新——首次将Mixture of Experts(MoE)思想引入净负荷预测。
分支一:Variable Branch(变量分支)
为负荷、光伏、风电分别定制时空专家(STE):
| 专家类型 | 结构特点 | 设计理由 |
|---|---|---|
| 负荷专家 | TCF → 空间特征提取 → 时间注意力 → FFN | 负荷空间分布复杂,需要通道融合捕获多通道关联 |
| 光伏专家 | 时间注意力 → 空间特征提取 → FFN | 光伏强时间周期性(日出日落),优先时间建模 |
| 风电专家 | 同光伏专家 | 风电同样强时间依赖性,且空间分布相对稀疏 |
负荷专家详细结构:
Lcb=Lemb⊗Wcb+bcb(Temporal Channel Fusion)L_{cb} = L_{emb} \otimes W_{cb} + b_{cb} \quad \text{(Temporal Channel Fusion)}Lcb=Lemb⊗Wcb+bcb(Temporal Channel Fusion)
Lgc=σ(∑k=0KZ~kLcbWk)(Adaptive GCN)L_{gc} = \sigma\left(\sum_{k=0}^{K} \tilde{Z}^k L_{cb} W_k\right) \quad \text{(Adaptive GCN)}Lgc=σ(k=0∑KZ~kLcbWk)(Adaptive GCN)
Lsa=Softmax(QtaKta⊤dk)Vta(Temporal Attention)L_{sa} = \text{Softmax}\left(\frac{Q_{ta} K_{ta}^\top}{\sqrt{d_k}}\right) V_{ta} \quad \text{(Temporal Attention)}Lsa=Softmax(dkQtaKta⊤)Vta(Temporal Attention)
Lst=(σ(LsaWl1+bl1))Wl2+bl2(Feed-forward)L_{st} = (\sigma(L_{sa} W_{l1} + b_{l1})) W_{l2} + b_{l2} \quad \text{(Feed-forward)}Lst=(σ(LsaWl1+bl1))Wl2+bl2(Feed-forward)
- Wcb∈RD×Cd×CdW_{cb} \in \mathbb{R}^{D \times C_d \times C_d}Wcb∈RD×Cd×Cd: 通道融合参数
- Z~∈RN×N\tilde{Z} \in \mathbb{R}^{N \times N}Z~∈RN×N: 可学习动态拓扑表示
- Wk∈RK×Cd×GdW_k \in \mathbb{R}^{K \times C_d \times G_d}Wk∈RK×Cd×Gd: Chebyshev多项式图卷积核
分支二:Feature Branch(特征分支)
在STE输出基础上,进一步通过**增强专家(EE)**提取深层特征:
Qeh,i=Seh,iWqu,iQ_{eh,i} = S_{eh,i} W_{qu,i}Qeh,i=Seh,iWqu,i
Kst,i=Sst,iWke,i,Vst,i=Sst,iWva,iK_{st,i} = S_{st,i} W_{ke,i}, \quad V_{st,i} = S_{st,i} W_{va,i}Kst,i=Sst,iWke,i,Vst,i=Sst,iWva,i
Se,i=Softmax(Qeh,iKst,i⊤dk)Vst,iS_{e,i} = \text{Softmax}\left(\frac{Q_{eh,i} K_{st,i}^\top}{\sqrt{d_k}}\right) V_{st,i}Se,i=Softmax(dkQeh,iKst,i⊤)Vst,i
- Expert Query机制:用EE的查询去"检索"STE的键值,实现跨层特征交互
- 防止全连接网络导致的信息损失
融合输出:
Sst=Concat(Lst,Pst,Wst,Xemb)∈RN×D×4SdS_{st} = \text{Concat}(L_{st}, P_{st}, W_{st}, X_{emb}) \in \mathbb{R}^{N \times D \times 4S_d}Sst=Concat(Lst,Pst,Wst,Xemb)∈RN×D×4Sd
See=Concat(Le,Pe,We,Sst)∈RN×D×SdS_{ee} = \text{Concat}(L_e, P_e, W_e, S_{st}) \in \mathbb{R}^{N \times D \times S_d}See=Concat(Le,Pe,We,Sst)∈RN×D×Sd
C. Meta Spatial Memory(元空间记忆库)
动机:标准GCN使用固定邻接矩阵,但配电网拓扑随净负荷动态变化(节点可能从输入变输出)。
传统动态图方法:
Z~=Softmax(ReLU(ZZ⊤))\tilde{Z} = \text{Softmax}(\text{ReLU}(Z Z^\top))Z~=Softmax(ReLU(ZZ⊤))
局限:ZZZ作为可训练参数,不随时间变化。
本文MSM设计:
Ψ∈Rψ×N×Md(记忆库,存储历史图结构模式)\Psi \in \mathbb{R}^{\psi \times N \times M_d} \quad \text{(记忆库,存储历史图结构模式)}Ψ∈Rψ×N×Md(记忆库,存储历史图结构模式)
查询过程:
Qt=SeetWQ+bQ(当前状态生成查询)Q_t = S_{ee}^t W_Q + b_Q \quad \text{(当前状态生成查询)}Qt=SeetWQ+bQ(当前状态生成查询)
ajt=exp(QtΨ[j]⊤)∑j=1ψexp(QtΨ[j]⊤)(注意力权重)a_j^t = \frac{\exp(Q_t \Psi[j]^\top)}{\sum_{j=1}^{\psi} \exp(Q_t \Psi[j]^\top)} \quad \text{(注意力权重)}ajt=∑j=1ψexp(QtΨ[j]⊤)exp(QtΨ[j]⊤)(注意力权重)
SM=∑j=1ψajtΨ[j](记忆读取)S_M = \sum_{j=1}^{\psi} a_j^t \Psi[j] \quad \text{(记忆读取)}SM=j=1∑ψajtΨ[j](记忆读取)
Sma=[Seet+SM]∈RN×(Sd+Md)S_{ma} = [S_{ee}^t + S_M] \in \mathbb{R}^{N \times (S_d + M_d)}Sma=[Seet+SM]∈RN×(Sd+Md)
Hyper-Network增强:
H=HN(Ψ),Z~′=Softmax(ReLU(Z′Z′⊤))H = \text{HN}(\Psi), \quad \tilde{Z}' = \text{Softmax}(\text{ReLU}(Z' Z'^\top))H=HN(Ψ),Z~′=Softmax(ReLU(Z′Z′⊤))
- Z~′\tilde{Z}'Z~′反馈到AGCN和Decoder,实现记忆与专家的即时交互
2.3 损失函数设计
Ltask=ε1L1+ε2L2+ε3L3\mathcal{L}_{task} = \varepsilon_1 \mathcal{L}_1 + \varepsilon_2 \mathcal{L}_2 + \varepsilon_3 \mathcal{L}_3Ltask=ε1L1+ε2L2+ε3L3
| 损失项 | 公式 | 作用 |
|---|---|---|
| 预测损失 L1\mathcal{L}_1L1 | $\sum_n \sum_t \sum_\rho | \hat{X}{t+\rho}^n - X{t+\rho}^n |
| 一致性损失 L2\mathcal{L}_2L2 | ∑t∑n∣Qt−Ψ[p]∣2\sum_t \sum_n |Q_t - \Psi[p]|^2∑t∑n∣Qt−Ψ[p]∣2 | 查询与最相似记忆项靠近 |
| 对比损失 L3\mathcal{L}_3L3 | ∑t∑nmax{∣Qt−Ψ[p]∣2−∣Qt−Ψ[g]∣2+λ,0}\sum_t \sum_n \max\{|Q_t-\Psi[p]|^2 - |Q_t-\Psi[g]|^2 + \lambda, 0\}∑t∑nmax{∣Qt−Ψ[p]∣2−∣Qt−Ψ[g]∣2+λ,0} | 查询与正样本靠近、与负样本远离 |
- Ψ[p]\Psi[p]Ψ[p]: 最相似记忆项(正样本)
- Ψ[g]\Psi[g]Ψ[g]: 第二相似记忆项(负样本)
- λ\lambdaλ: 边际参数
三、数据集构建:LDCM(负荷-DG耦合模型)
3.1 现实挑战
真实大规模配电网数据难以获取(法律/隐私限制),现有研究通常:
- 仅使用负荷数据,忽略DG
- 或将不同区域数据简单拼接,不符合地理一致性
3.2 LDCM算法
核心思想:同一小区域内的负荷和DG数据耦合,再组合成大规模系统。
步骤:
-
计算光伏系数:
ηr=∑t=1TPtrPmaxT\eta_r = \frac{\sum_{t=1}^T P_t^r}{P_{max} T}ηr=PmaxT∑t=1TPtr -
Softmax分配PV节点数(引入修正因子):
Nrpv=exp[Nr(ηr−θco)]∑r=1Rexp[Nr(ηr−θco)]NPeN_r^{pv} = \frac{\exp[N_r(\eta_r - \theta_{co})]}{\sum_{r=1}^R \exp[N_r(\eta_r - \theta_{co})]} N \mathcal{P}_eNrpv=∑r=1Rexp[Nr(ηr−θco)]exp[Nr(ηr−θco)]NPe
θco=max(0,min(η∼)−12(max(η∼)−min(η∼)))\theta_{co} = \max\left(0, \min(\eta_\sim) - \frac{1}{2}(\max(\eta_\sim) - \min(\eta_\sim))\right)θco=max(0,min(η∼)−21(max(η∼)−min(η∼)))
- θco\theta_{co}θco作用:当区域间ηr\eta_rηr差异小时,放大相对差异,防止Softmax被节点数NrN_rNr主导
-
K-means聚类:
- 高ηr\eta_rηr区域 → 大社区 C(h)pvC_{(h)}^{pv}C(h)pv(密集DG)
- 低ηr\eta_rηr区域 → 小社区 C(b∼)pvC_{(b_\sim)}^{pv}C(b∼)pv(稀疏DG)
-
风电节点:选择远离社区、风资源好的郊区节点
3.3 构建的两个场景
| 场景 | PV渗透率 | 风电节点 | 基于 |
|---|---|---|---|
| PDS Scenario 1 | 10%节点有PV | 2个风电节点 | IEEE 8500节点测试馈线 |
| PDS Scenario 2 | 20%节点有PV | 3个风电节点 | 科罗拉多州22个相邻小区域真实数据 |
四、实验结果
4.1 主实验对比(Table II)
| 模型 | 策略 | MAE (kW) | RMSE (kW) | MAPE (%) |
|---|---|---|---|---|
| GRU | 间接 | 较高 | 较高 | ~50 |
| GCN | 间接 | 较高 | 较高 | ~50 |
| T-GCN | 间接 | 较高 | 较高 | ~48 |
| AGCRN | 间接 | 中等 | 中等 | ~50 |
| MTGNN | 间接 | 中等 | 中等 | ~45 |
| MegaCRN | 间接 | 较低 | 较低 | ~42 |
| MPGTN | 间接 | 较低 | 较低 | ~42 |
| DEFMN (Ours) | 间接 | 最低 | 最低 | ~40 |
关键发现:
- DEFMN在两种场景、所有指标上均达SOTA
- 相比MPGTN(当前SOTA),MAPE降低约2-3%
4.2 不同距离节点预测(Figure 5)
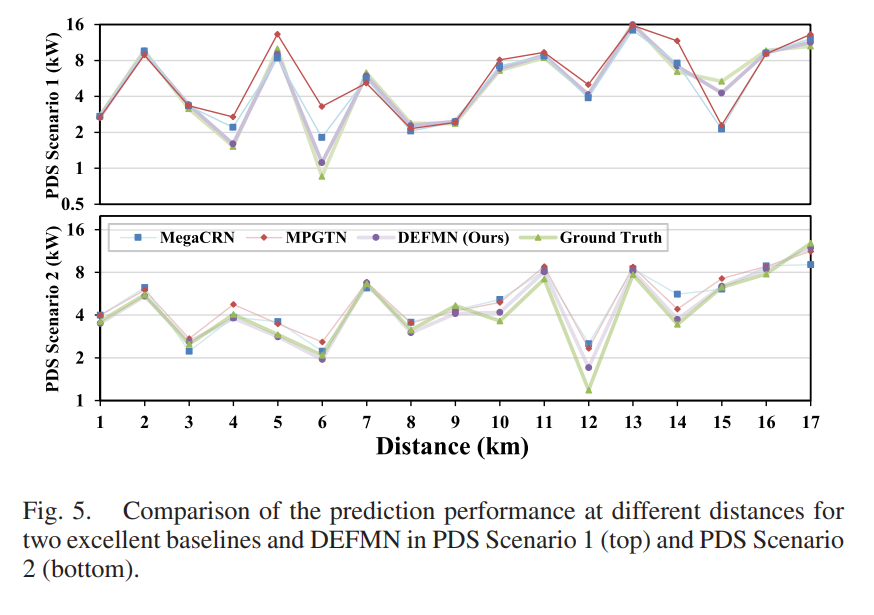
在距离变电站1-17km的节点上:
- DEFMN预测曲线最接近Ground Truth
- 尤其在远距离节点(配电网末端)优势明显
4.3 误差分布分析(Table III)
| 模型 | Skewness (偏度) | Kurtosis (峰度) |
|---|---|---|
| MPGTN | 较高 | 较高 |
| DEFMN | 较低 | 较低 |
含义:DEFMN误差更接近正态分布,异常值更少,预测更稳定。
五、消融实验与分析
5.1 模块消融(Figure 6)
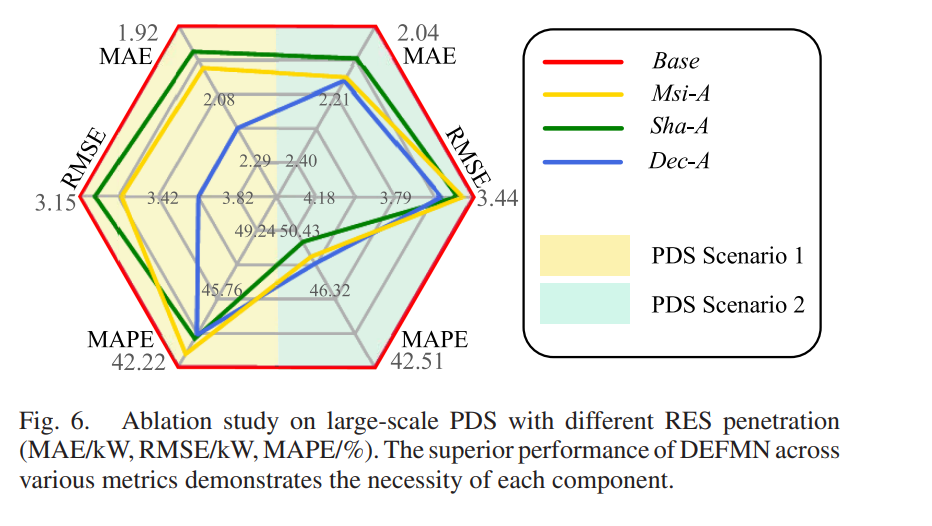
| 变体 | 修改 | MAE | RMSE | MAPE |
|---|---|---|---|---|
| Base (完整DEFMN) | - | 1.92 | 3.15 | 42.22 |
| Msi-A | 去掉MSM记忆库 | ↑ | ↑ | ↑ |
| Sha-A | 共享参数替代独立专家 | ↑↑ | ↑↑ | ↑↑ |
| Dec-A | 去掉Decoder | ↑ | ↑ | ↑ |
结论:
- 独立专家(Sha-A vs Base):影响最大,验证变量异质性必须独立建模
- 记忆库(Msi-A):对动态图结构学习至关重要
- Decoder(Dec-A):对特征投影和残差连接不可或缺
5.2 嵌入方式对比(Figure 7)
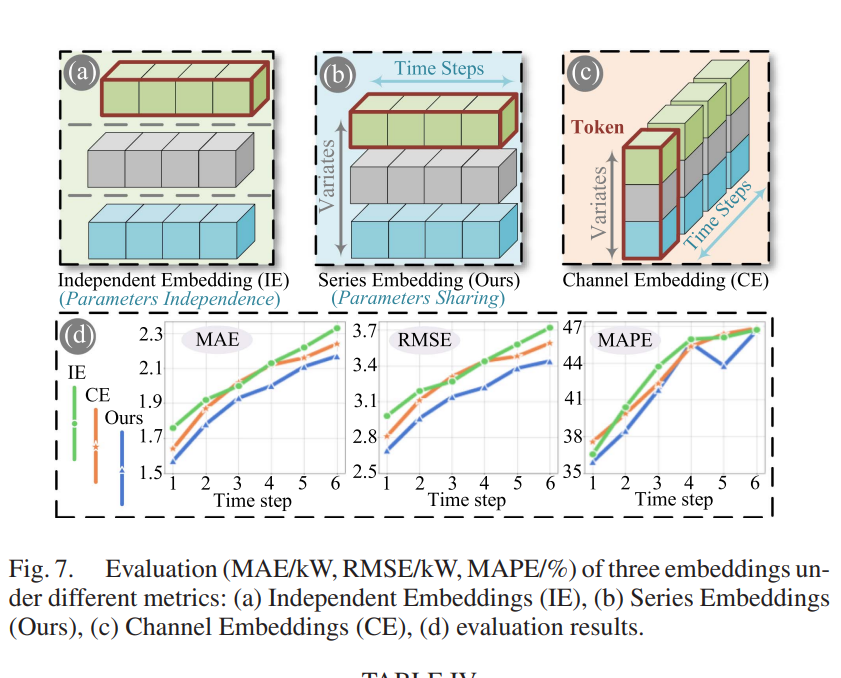
| 嵌入方式 | 参数共享 | 时间对齐 | 性能 |
|---|---|---|---|
| Independent Embedding (IE) | × | ✓ | 差(过度关注变量内在特性,忽略关联) |
| Series Embedding (Ours) | ✓ | ✓ | 最佳 |
| Channel Embedding (CE) | ✓ | × | 差(时间不对齐,变量关联弱化) |
关键洞察:共享参数+时间对齐的系列嵌入是最佳平衡点。
5.3 直接策略 vs 间接策略(Table IV)
| 策略 | 输入 | 输出 | MAE | RMSE | MAPE |
|---|---|---|---|---|---|
| 直接策略 | 历史净负荷 | 净负荷 | 较高 | 较高 | 较高 |
| 间接策略 (Ours) | 负荷+PV+风电 | 分别预测后相减 | 降低5.39% | 降低7.65% | 降低7.68% |
高RES渗透率时优势更大(Scenario 2):
- MAE降低8.13%,RMSE降低8.33%,MAPE降低11.32%
原因:直接策略隐藏了负荷与DG的关联,神经网络倾向于提取净负荷的显性特征;间接策略保留变量完整性,通过定制专家充分挖掘潜在关联。
六、效率分析(Figure 8)
| 指标 | DEFMN | MPGTN | AGCRN | MTGNN | MegaCRN |
|---|---|---|---|---|---|
| 参数量 | 0.98M | 7.49M | ~2M | ~2M | ~0.5M |
| MAdds | 低 | 高 | 中 | 中 | 低 |
| 推理时间 | 快 | 慢 | 中 | 中 | 较快 |
| MAPE | ~40% | ~42% | ~50% | ~45% | ~42% |
效率提升:
- 参数量减少86.9%(vs MPGTN)
- MAdds减少96.8%
- 推理时间比MPGTN快42.6%,比AGCRN快32.6%
秘诀:根据变量特性定制专家复杂度——风电只需简单时空模块,避免统一复杂架构的冗余计算。
七、核心贡献总结
| 贡献 | 具体内容 |
|---|---|
| 方法创新 | 首次将**定制专家(MoE)**引入净负荷预测,独立参数捕获变量异质性,共享参数捕获变量关联 |
| 机制创新 | Meta Spatial Memory动态记忆库,适应配电网时变拓扑 |
| 数据创新 | LDCM模型构建符合地理一致性的RES集成配电网场景 |
| 策略创新 | 间接预测策略(分别预测负荷/DG再相减),优于直接预测净负荷 |
| 效率创新 | 精度SOTA同时,参数量和计算量大幅降低 |
八、局限与展望
| 局限 | 未来方向 |
|---|---|
| 仅在IEEE 8500节点系统验证 | 更大规模(如10万节点)配电网测试 |
| RES类型限于PV和风电 | 纳入储能(ES)、电动汽车(EV)等新型元素 |
| 单时间分辨率(小时级) | 多时间尺度(分钟/小时/日)联合预测 |
| 确定性预测为主 | 结合概率预测,量化不确定性 |
核心思想一句话总结
“负荷、光伏、风电性格迥异,不能穿同一件衣服——给每个变量定制专属专家(独立参数)学习个性,用共享模块(序列嵌入、记忆库)学习共性,让动态记忆适应配电网的’七十二变’拓扑。”

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 26
26 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)